pytorch-AlexNet
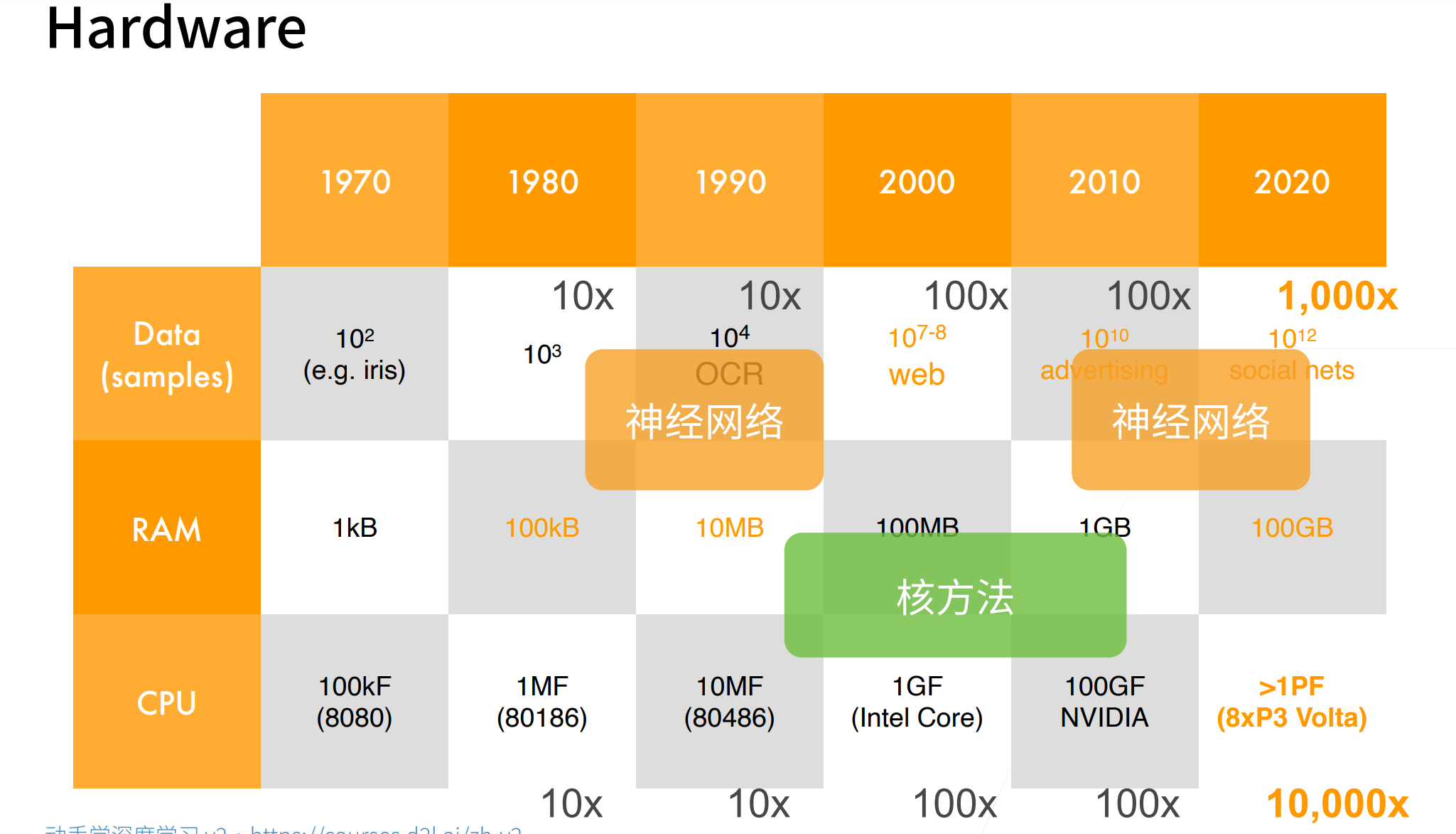
在上世纪90年代初到2012年之间的大部分时间里,神经网络往往被其他机器学习方法超越。深度卷积神经网络的突破出现在2012年。突破可归因于两个关键因素。
- 数据
- 硬件(GPU)
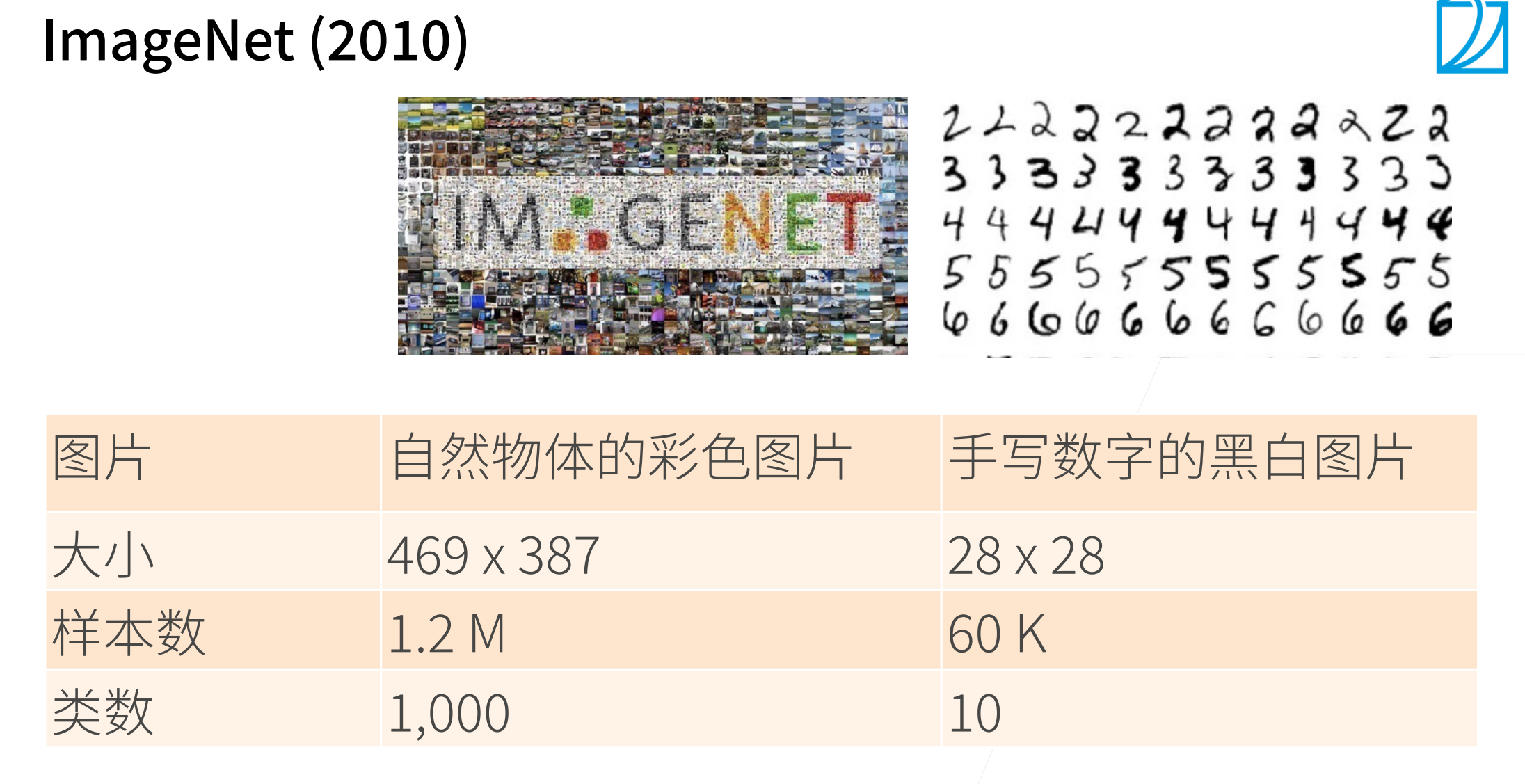
ImageNet (2010)
AlexNet
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
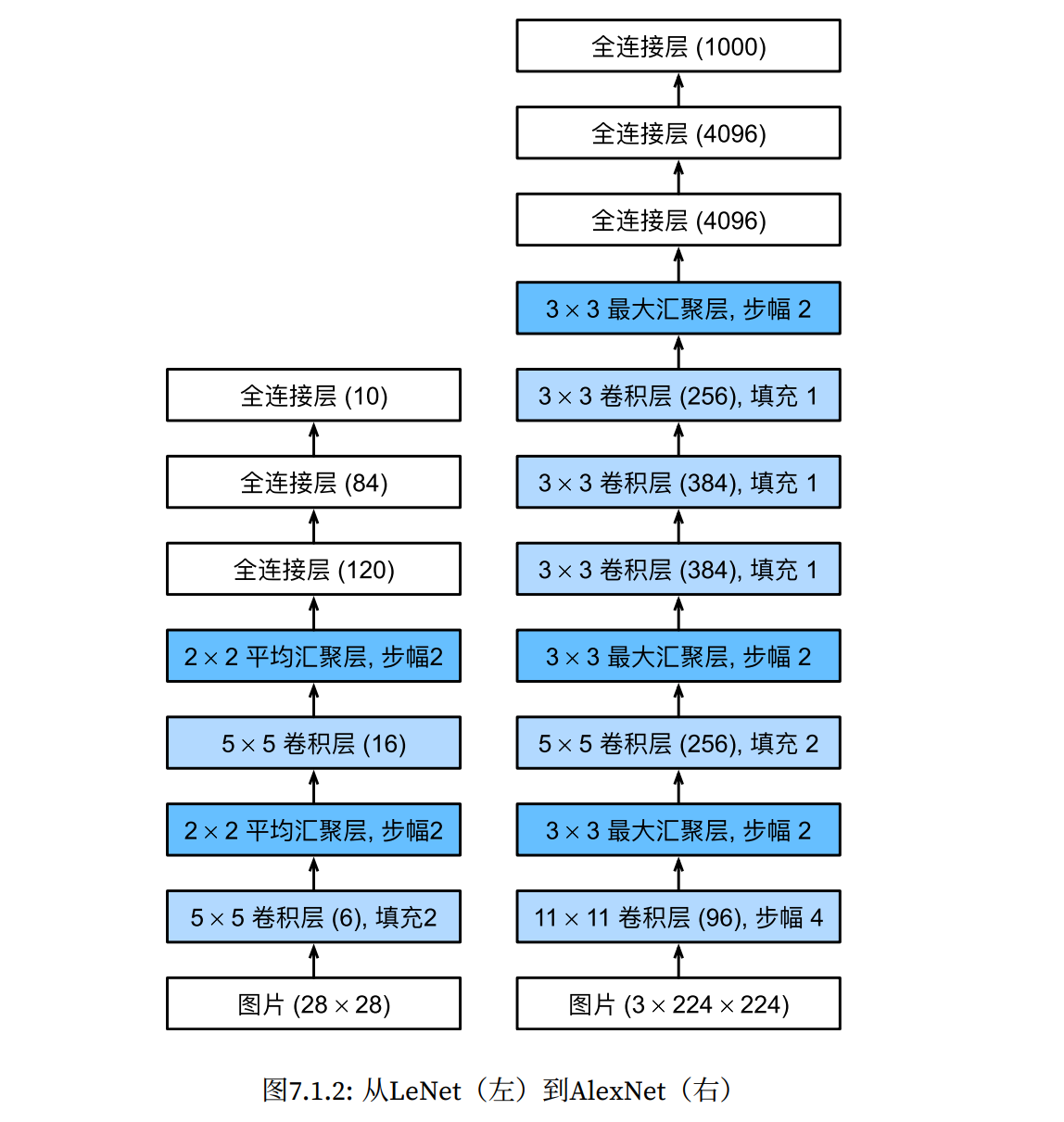
AlexNet和LeNet的架构非常相似,AlexNet更像是一个更深更大的LeNet。
它的主要改进就是:
- 全连接层使用丢弃法
- 使用ReLu而不是sigmoid作为激活函数
- MaxPooling
模型设计
在AlexNet的第一层,卷积窗口的形状是\(11×11\)。由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。第二层中的卷积窗口形状被缩减为\(5×5\),然后是\(3×3\)。
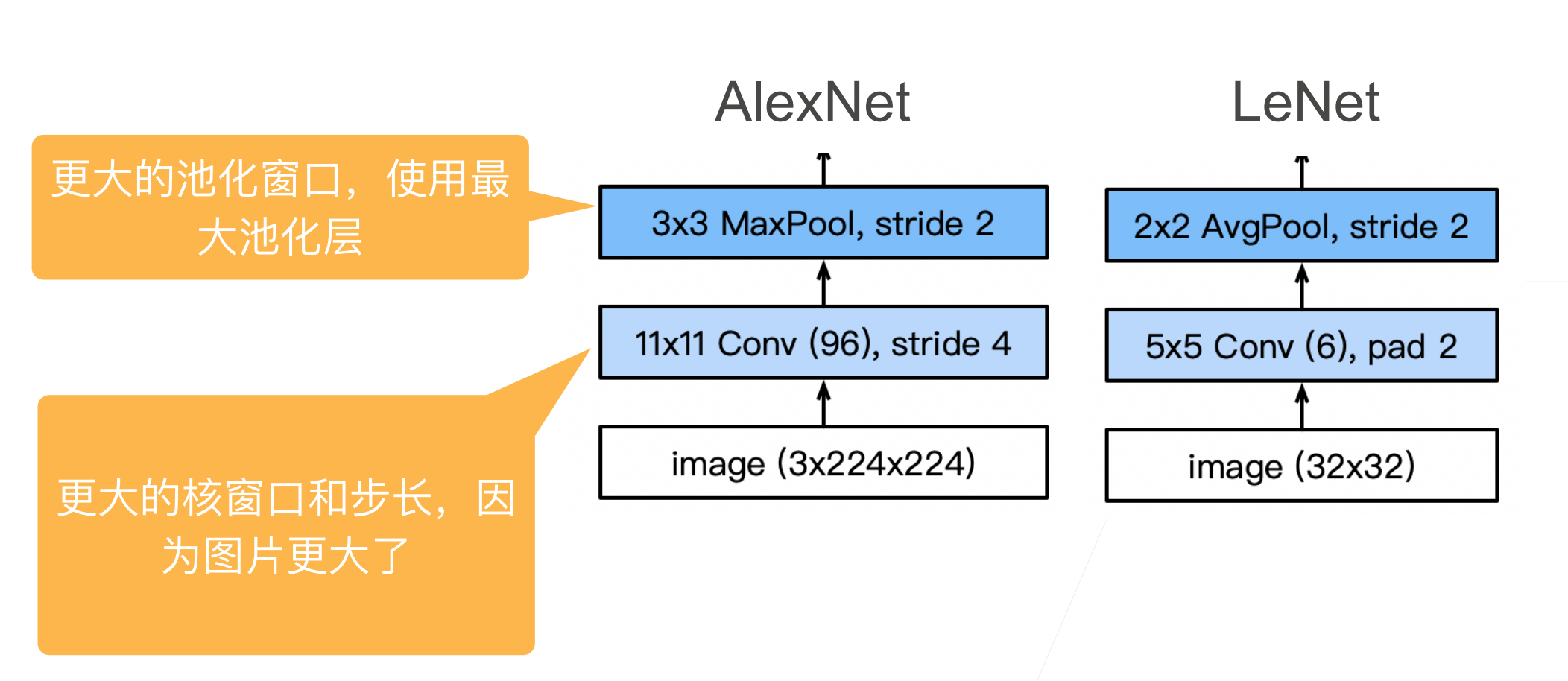
此外,在第⼀层、第二层和第五层卷积层之后,加入窗口形状为\(3 × 3\)、步幅为2的最大汇聚层。而且,AlexNet的卷积通道数目是LeNet的10倍。
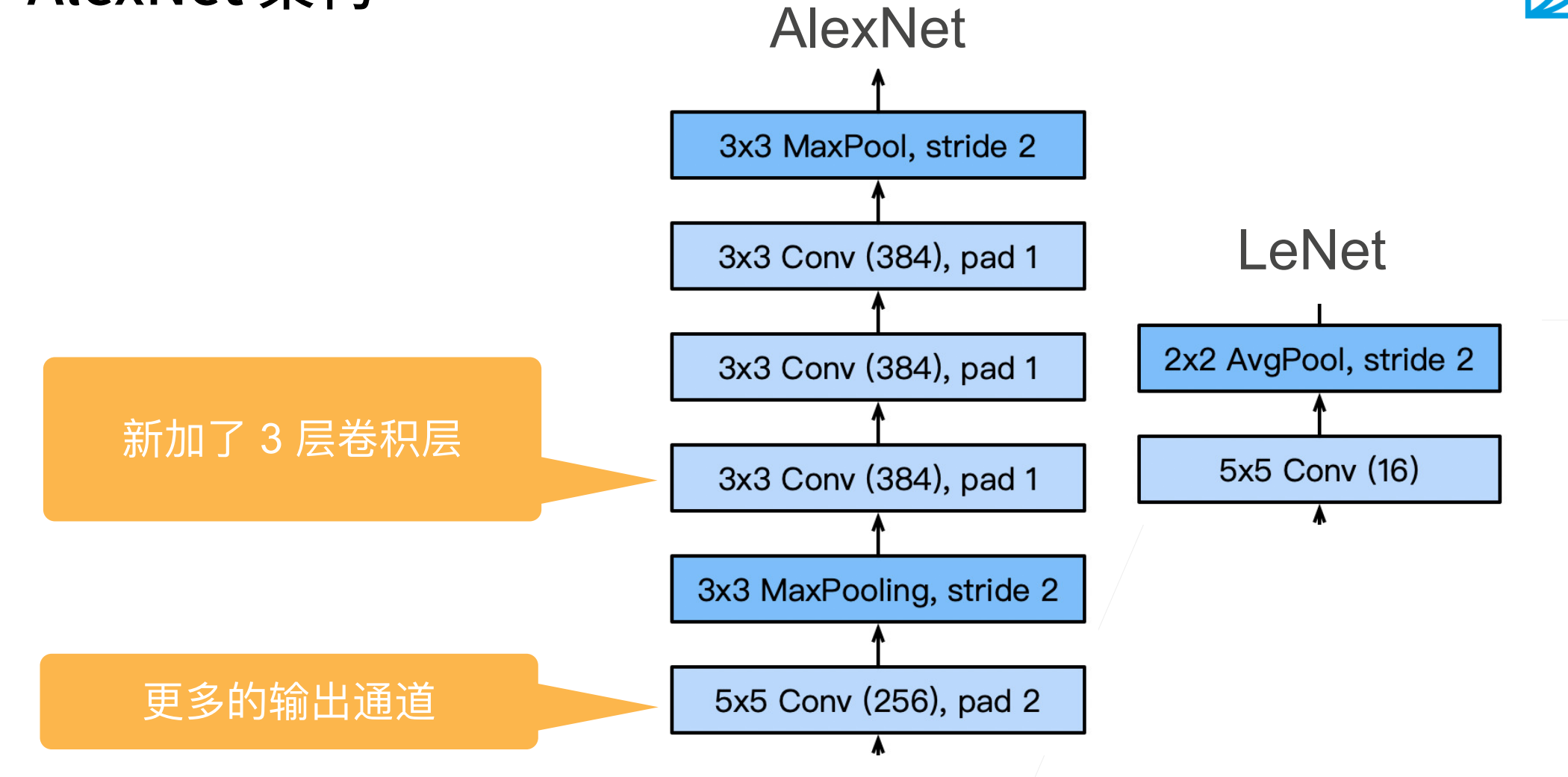
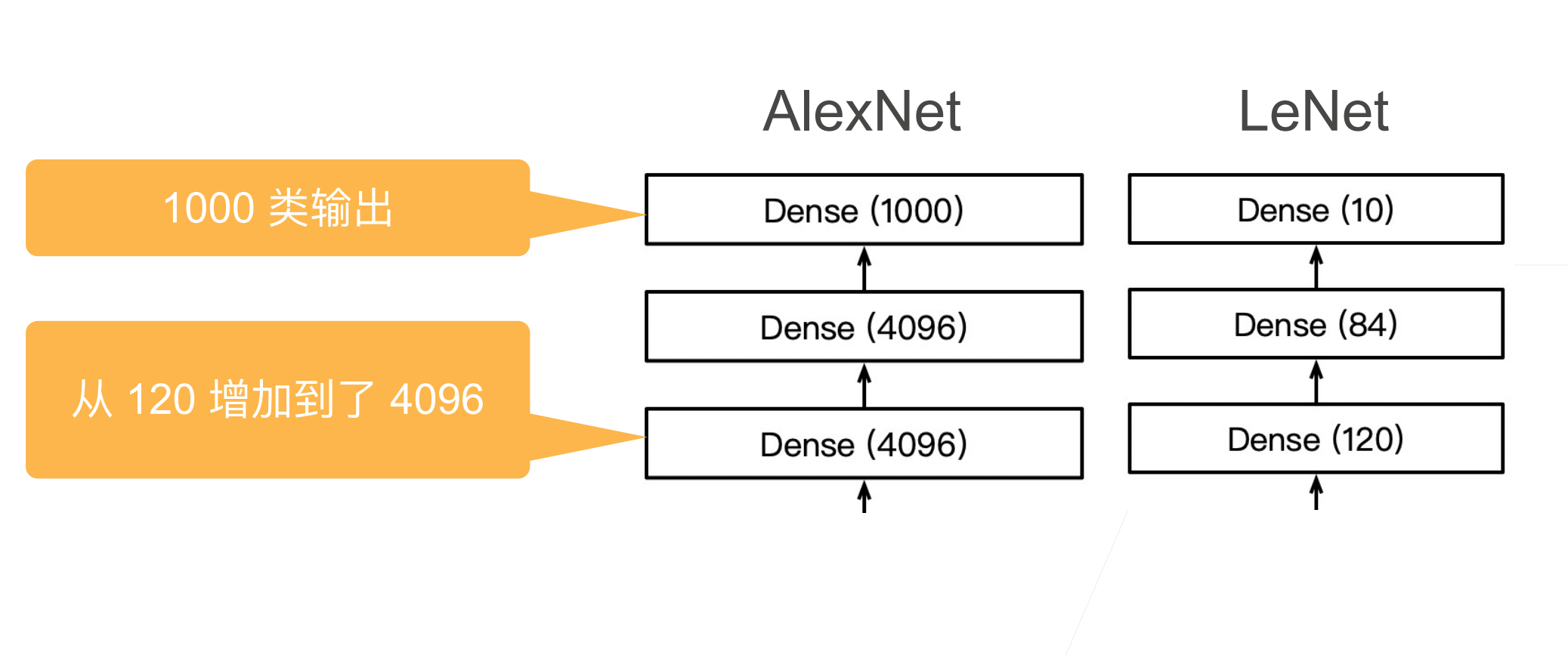
在最后⼀个卷积层后有两个全连接层,分别有4096个输出。
激活函数
此外,AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新⼀些模型参数。相反,ReLU激活函数在正区间的梯度总是1。因此,如果模型参数没有正
确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 这⾥使⽤⼀个11*11的更⼤窗⼝来捕捉对象。
# 同时,步幅为4,以减少输出的⾼度和宽度。
# 另外,输出通道的数⽬远⼤于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减⼩卷积窗⼝,使⽤填充为2来使得输⼊与输出的⾼和宽⼀致,且增⼤输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使⽤三个连续的卷积层和较⼩的卷积窗⼝。
# 除了最后的卷积层,输出通道的数量进⼀步增加。
# 在前两个卷积层之后,汇聚层不⽤于减少输⼊的⾼度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(),
# 这⾥,全连接层的输出数量是LeNet中的好⼏倍。使⽤dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5),
# 最后是输出层。由于这⾥使⽤Fashion-MNIST,所以⽤类别数为10,⽽⾮论⽂中的1000
nn.Linear(4096, 10))
查看参数
X = torch.randn(1, 1, 224, 224)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'Output shape:\t', X.shape)
Conv2d Output shape: torch.Size([1, 96, 54, 54])
ReLU Output shape: torch.Size([1, 96, 54, 54])
MaxPool2d Output shape: torch.Size([1, 96, 26, 26])
Conv2d Output shape: torch.Size([1, 256, 26, 26])
ReLU Output shape: torch.Size([1, 256, 26, 26])
MaxPool2d Output shape: torch.Size([1, 256, 12, 12])
Conv2d Output shape: torch.Size([1, 384, 12, 12])
ReLU Output shape: torch.Size([1, 384, 12, 12])
Conv2d Output shape: torch.Size([1, 384, 12, 12])
ReLU Output shape: torch.Size([1, 384, 12, 12])
Conv2d Output shape: torch.Size([1, 256, 12, 12])
ReLU Output shape: torch.Size([1, 256, 12, 12])
MaxPool2d Output shape: torch.Size([1, 256, 5, 5])
Flatten Output shape: torch.Size([1, 6400])
Linear Output shape: torch.Size([1, 4096])
ReLU Output shape: torch.Size([1, 4096])
Dropout Output shape: torch.Size([1, 4096])
Linear Output shape: torch.Size([1, 4096])
ReLU Output shape: torch.Size([1, 4096])
Dropout Output shape: torch.Size([1, 4096])
Linear Output shape: torch.Size([1, 10])
本文使用的是Fashion-MNIST,Fashion-MNIST图像的分辨率(28 × 28像素)低于ImageNet图像。为了解决这个问题,我们将它们增加到224 × 224(通常来讲这不是⼀个明智的做法,但在这⾥这样做是为了有效使⽤AlexNet架构)。这里需要用d2l.load_data_fashion_mnist函数中的resize参数执行此调整。
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.01, 10
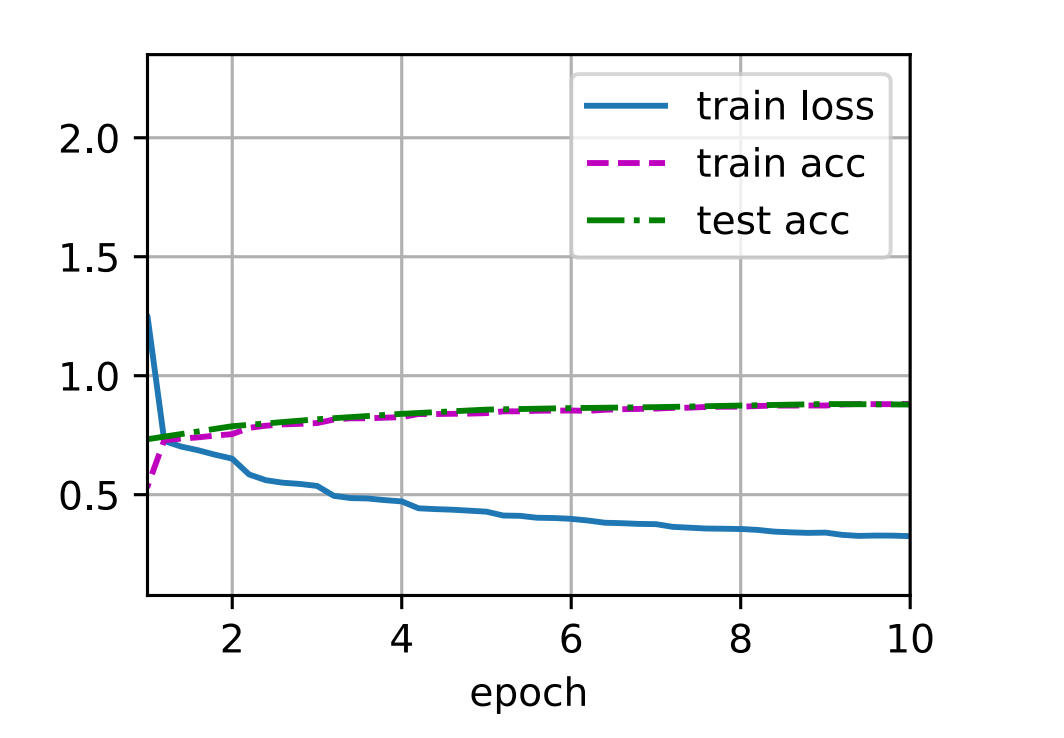
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.327, train acc 0.881, test acc 0.879
1417.6 examples/sec on cuda:0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号