pytorch-GPU
要想时使用GPU,首先要先安装CUDA和GPU版的torch
计算设备
我们可以指定用于存储和计算的设备,如CPU和GPU。默认情况下,张量是在内存中创建的,然后使⽤CPU计算它。在PyTorch中,CPU和GPU可以用torch.device('cpu') 和torch.device('cuda')表示。应该注意的是,cpu设备意味着所有物理CPU和内存,这意味着PyTorch的计算将尝试使所有CPU核心。然而,gpu设备只代表⼀个卡和相应的显存。如果有多个GPU,我们使用torch.device(f'cuda:{i}') 来表示第i块GPU(i从0开始)。
另外,cuda:0和cuda是等价的。
import torch
from torch import nn
torch.device('cpu'), torch.cuda.device('cuda')
# (device(type='cpu'), <torch.cuda.device at 0x258fa175370>)
以查询可用gpu的数量。
torch.cuda.device_count()
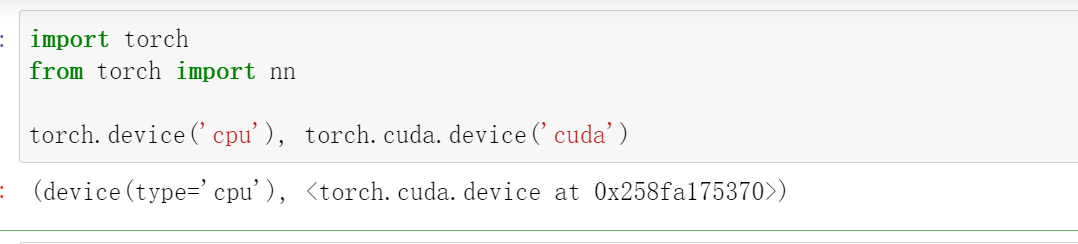
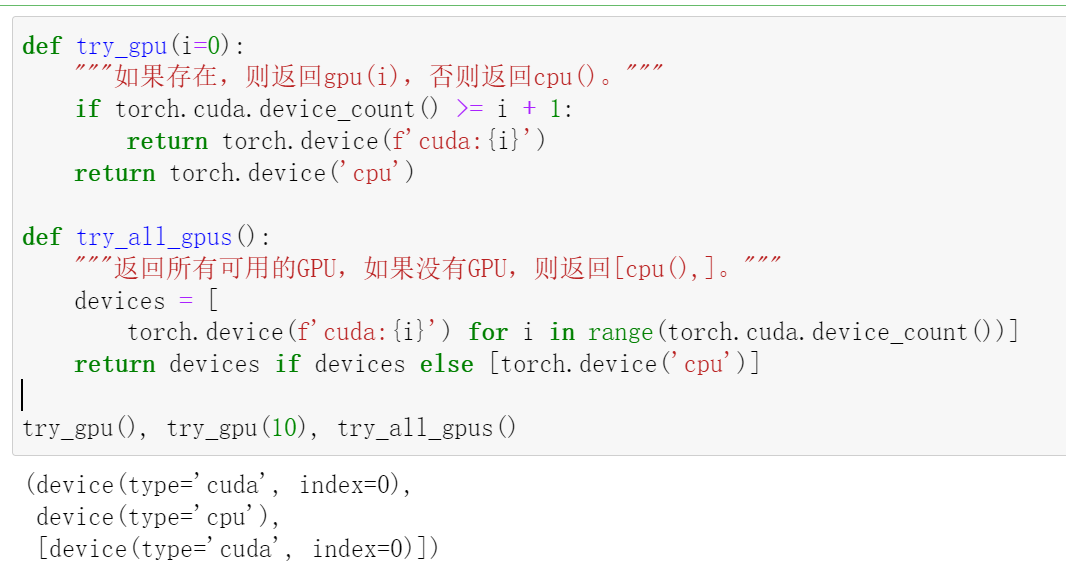
现在我们定义了两个方便的函数,这两个函数允许我们在不存在所需所有GPU的情况下运行代码。
def try_gpu(i=0):
"""如果存在,则返回gpu(i),否则返回cpu()。"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus():
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]。"""
devices = [
torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()
张量与GPU
我们可以查询张量所在的设备。默认情况下,张量是在CPU上创建的。
x = torch.tensor([1, 2, 3])
x.device
# device(type='cpu')
需要注意的是,无论何时我们要对多个项进行操作,它们都必须在同⼀个设备上。例如,如果我们对两个张量求和,我们需要确保两个张量都位于同一个设备上,否则框架将不知道在哪里存储结果,甚至不知道在哪里执行计算。
有几种方法可以在GPU上存储张量。例如,我们可以在创建张量时指定存储设备。
X = torch.ones(2, 3, device=try_gpu())
X
# tensor([[1., 1., 1.],
# [1., 1., 1.]], device='cuda:0')

Y = torch.rand(2, 3, device=try_gpu(0))
Y
# tensor([[0.6095, 0.4079, 0.4855],
# [0.8362, 0.2311, 0.1071]], device='cuda:0')
X+Y
# tensor([[1.6095, 1.4079, 1.4855],
# [1.8362, 1.2311, 1.1071]], device='cuda:0')
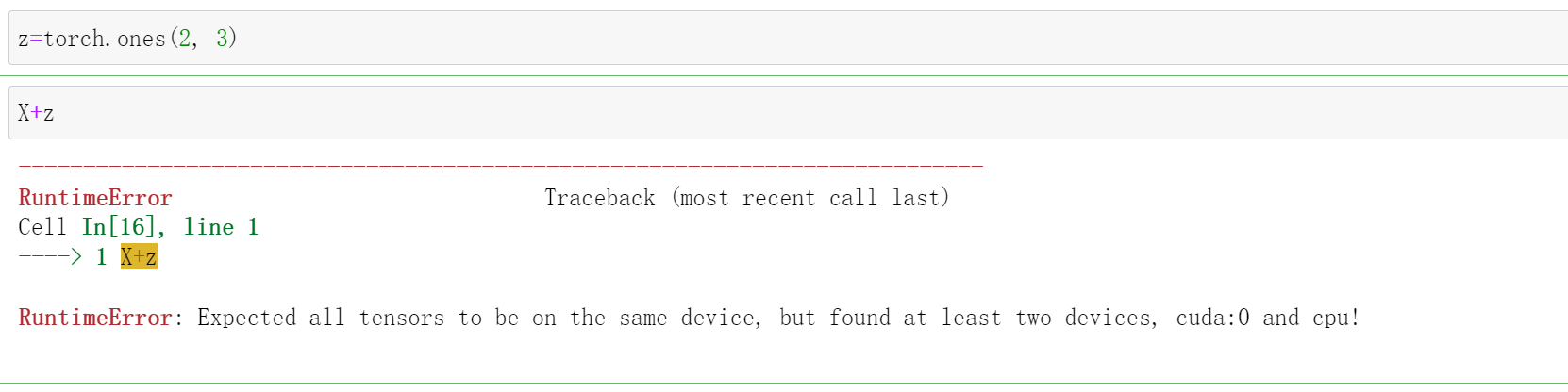
注意:只有两个在同一个设备上才能进行运算:
例如:我们创造一个z在CPU上,X在GPU上,我们进行加法
z=torch.ones(2, 3)
X+z
# RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
注意:
人们使用GPU来进行机器学习,因为单个GPU相对运行速度快。但是在设备(CPU、GPU和其他机器)之间传输数据比计算慢得多。这也使得并行化变得更加困难,因为我们必须等待数据被发送(或者接收),然后才能继续进行更多的操作。
所以,一般都是先在CPU上准备、处理数据,然后再net之前一起把数据转移到GPU上。
神经网络与GPU
类似地,神经网络模型可以指定设备。下⾯的代码将模型参数放在GPU上。
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())
net(X)
# tensor([[-0.5573],
# [-0.5573]], device='cuda:0', grad_fn=<AddmmBackward0>)
当输入为GPU上的张量时,模型将在同⼀GPU上计算结果。
net[0].weight.data.device
# device(type='cuda', index=0)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号