模型选择、过拟合和欠拟合
训练误差和泛化误差
- 训练误差:模型在训练数据上的误差
- 泛化误差:模型在新数据上的误差
例子:根据摸考成绩来预测未来考试分数
- 在过去的考试中表现很好(训练误差)不代表未来考试一定会好(泛化误差)
- 学生A通过背书在摸考中拿到很好成绩
- 学生B知道答案后面的原因
类似地,考虑⼀个简单地使用查表法来回答问题的模型。如果允许的输入集合是离散的并且相当小,那么也许在查看许多训练样本后,该方法将执行得很好。但当这个模型面对从未见过的例子时,它表现的可能比随机猜测好不到哪去。这是因为输入空间太大了,远远不可能记住每⼀个可能的输入所对应的答案。例如,考虑28 × 28的灰度图像。如果每个像素可以取256个灰度值中的⼀个,则有个可能的图像。这意味着指甲大小的低分辨率灰度图像的数量比宇宙中的原子要多得多。即使我们可能遇到这样的数据,我们也不可能存储整个查找表。
验证数据集和测试数据集
原则上,在我们确定所有的超参数之前,我们不希望用到测试集。如果我们在模型选择过程中使用测试数据,可能会有过拟合测试数据的风险。因此,我们决不能依靠测试数据进行模型选择。然而,我们也不能仅仅依靠训练数据来选择模型,因为我们无法估计训练数据的泛化误差。
解决此问题的常见做法是将我们的数据分成三份,除了训练和测试数据集之外,还增加⼀个验证数据集(validation dataset),也叫验证集(validation set)
所以,综上所述:
- 验证数据集:一个用来评估模型好坏的数据集
· 例如拿出50%的训练数据
· 不要跟训练数据混在一起(常犯错误) - 测试数据集:只用一次的数据集。例如
· 未来的考试
· 我出价的房子的实际成交价
· 用在Kaggle私有排行榜中的数据集
K折交叉验证
当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成⼀个合适的验证集。这个问题的一个流行的解决方案是采用K折交叉验证。 这里,原始训练数据被分成K个不重叠的子集。然后执行K次模型训练和验证,每次在K−1个子集上进行训练,并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。最后,通过对K次实验的结果取平均来估计训练和验证误差。
K-则交叉验证主要使用在没有足够多的数据时,

过拟合和欠拟合
欠拟合:当模型训练误差和验证误差都很严重,但是它们之间仅有一点差距,也就是模型在训练集和验证集上表现都不好但是训练误差和测试误差差距很小的时候。
过拟合:当训练集误差明显低于测试集误差的时候,也就是模型在训练集表现的明显比测试集上好的多。 注意,过拟合并不总是一件坏事。特别是在深度学习领域,众所周知,最好的预测模型在训练数据上的表现往往比在保留(验证)数据上好得多。是否过拟合或欠拟合可能取决于模型复杂性和可用训练数据集的大小。

我们看这个图,当数据比较简单,我们模型也比较简单的时候它是正常的,但是当模型比较简单,我们的数据比较复杂的时候就会欠拟合。当数据和模型都比较复杂的时候比较正常,但是当数据比较简单,我们的模型比较复杂的时候很容易过拟合。正如下面这张图:
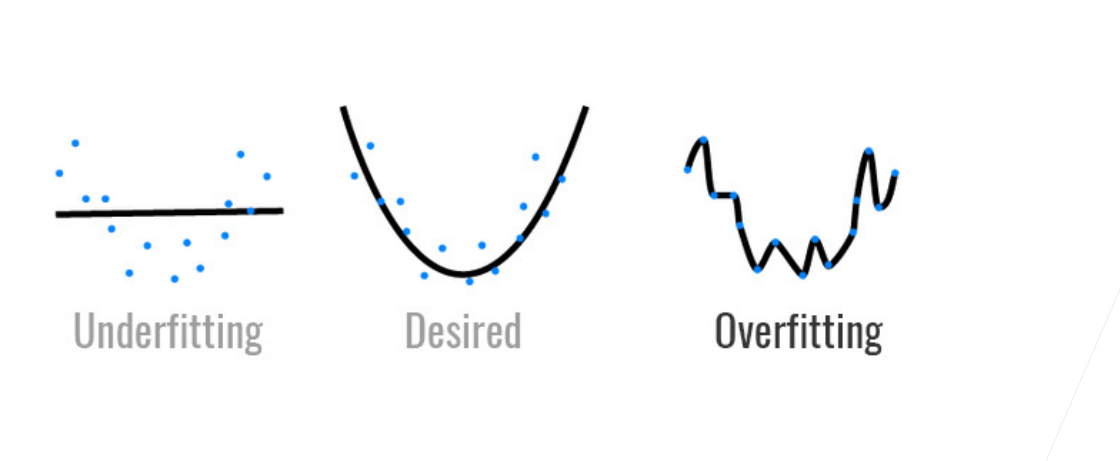
模型容量
·拟合各种函数的能力
·低容量的模型难以拟合训练数据
·高容量的模型可以记住所有的训练数据
下面是模型复杂度对欠拟合和过拟合的影响:
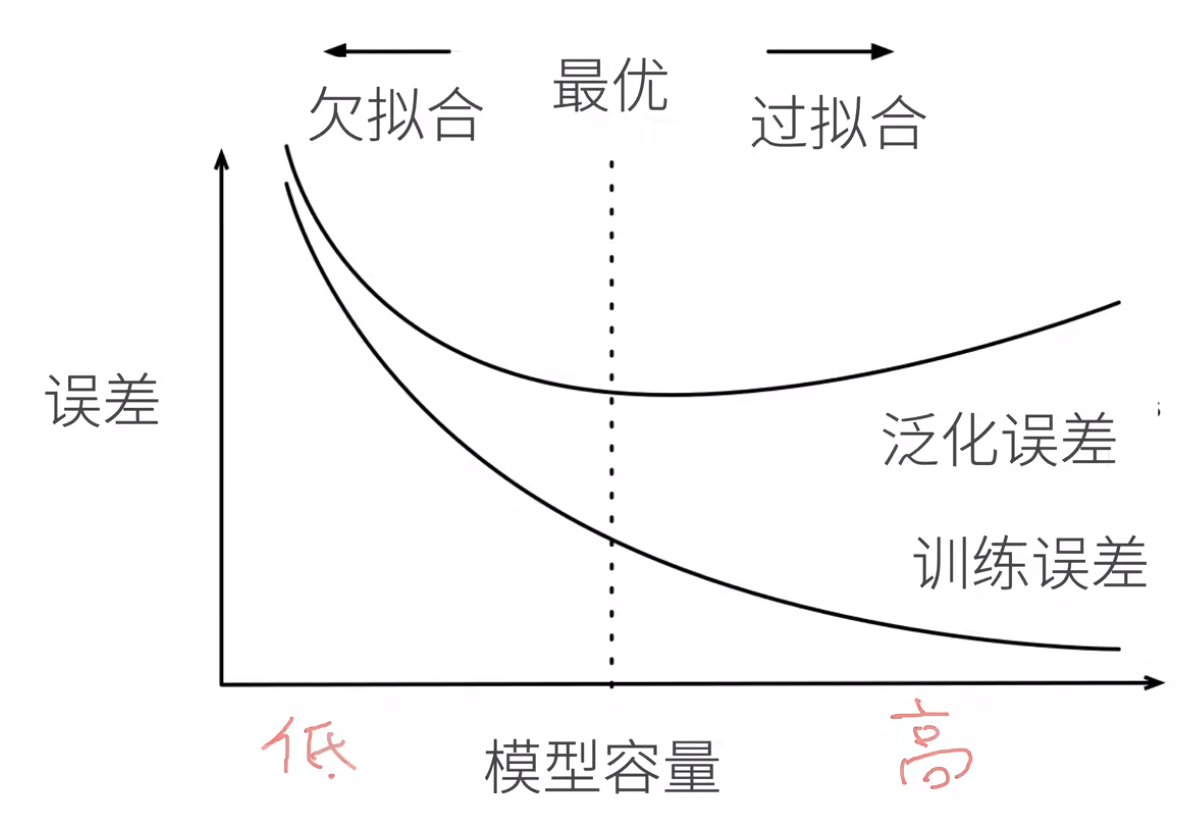
估计模型容量
- 难以在不同的种类算法之间比较
· 例如数模型和神经网络 - 给定一个模型种类,将有两个主要因素
· 参数的个数(就是W,B个数)
· 参数值的选择范围
另⼀个重要因素是数据集的大小。训练数据集中的样本越少,我们就越有可能(且更严重地)过拟合。随着训练数据量的增加,泛化误差通常会减小。
多项式回归
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
- 生成数据集
给定x,我们将使用以下三阶多项式来生成训练和测试数据的标签:

噪声项ϵ服从均值为0且标准差为0.1的正态分布。在优化的过程中,我们通常希望避免⾮常⼤的梯度值或损失值。这就是我们将特征从调整为的原因,这样可以避免很大的i带来的特别大的指数值。我们将为训练集和测试集各生成100个样本。
max_degree = 20
n_train, n_test = 100, 100
true_w = np.zeros(max_degree)
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])
features = np.random.normal(size=(n_train + n_test, 1))
np.random.shuffle(features)
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)
其中中国poly_features就是样本,labels就是要预测的值.
同样,存储在poly_features中的单项式由gamma函数重新缩放,其中Γ(n) = (n − 1)!。从⽣成的数据集中查
看⼀下前2个样本,第⼀个值是与偏置相对应的常量特征。
# NumPy ndarray转换为tensor
true_w, features, poly_features, labels = [torch.tensor(x, dtype=
torch.float32) for x in [true_w, features, poly_features, labels]]
features[:2], poly_features[:2, :], labels[:2]

- 对模型进行训练和测试
首先让我们实现⼀个函数来评估模型在给定数据集上的损失。
def evaluate_loss(net, data_iter, loss):
"""评估给定数据集上模型的损失。"""
metric = d2l.Accumulator(2)
for X, y in data_iter:
out = net(X)
y = y.reshape(out.shape)
l = loss(out, y)
metric.add(l.sum(), l.numel())
return metric[0] / metric[1]
- 训练函数
def train(train_features, test_features, train_labels, test_labels,
num_epochs=400):
loss = nn.MSELoss()
input_shape = train_features.shape[-1]
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1, 1)),
batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1, 1)),
batch_size, is_train=False)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(
net, train_iter, loss), evaluate_loss(net, test_iter, loss)))
print('weight:', net[0].weight.data.numpy())
在这个里我们只有前4个维度是正常的,后面都是0.
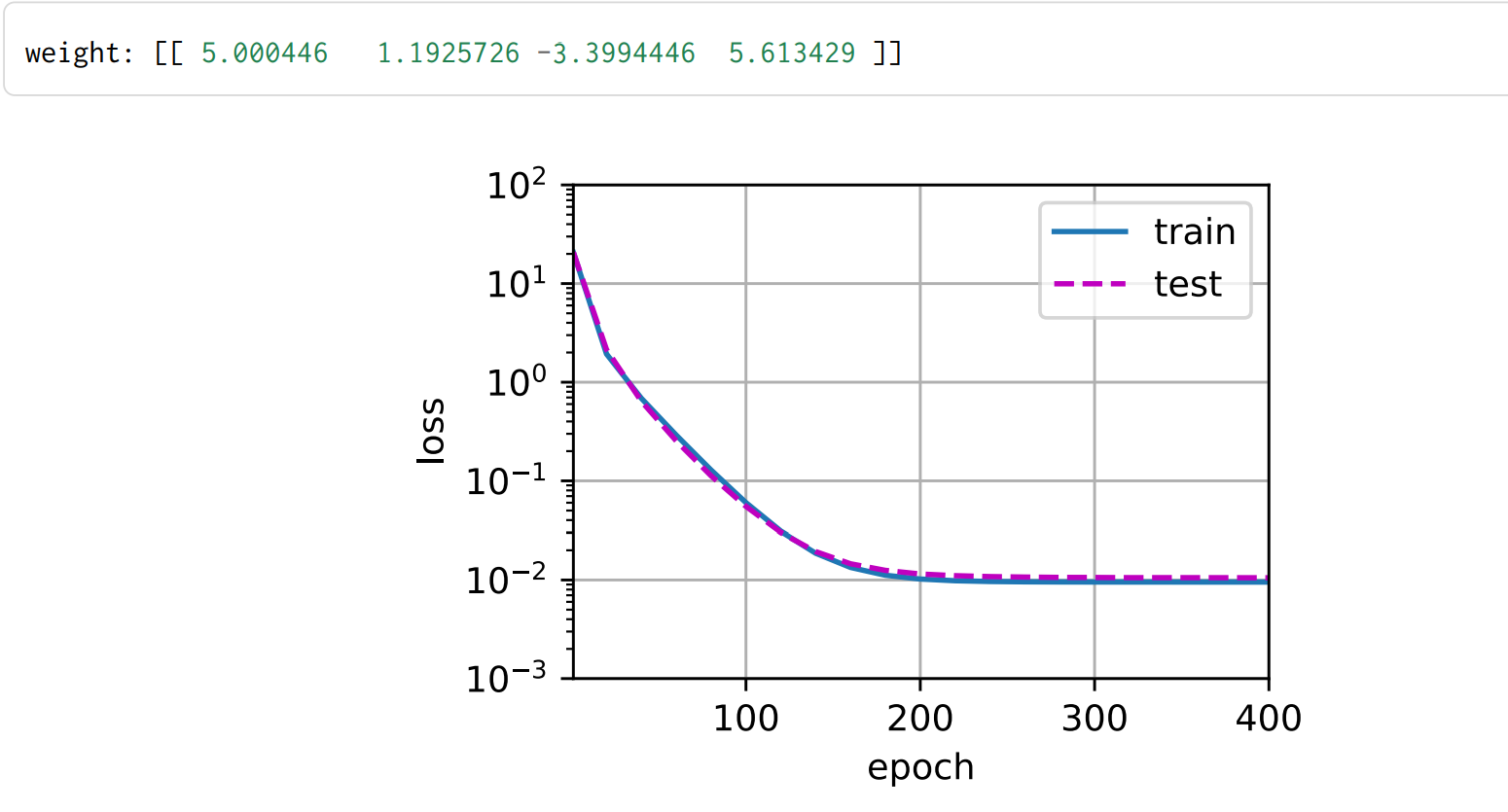
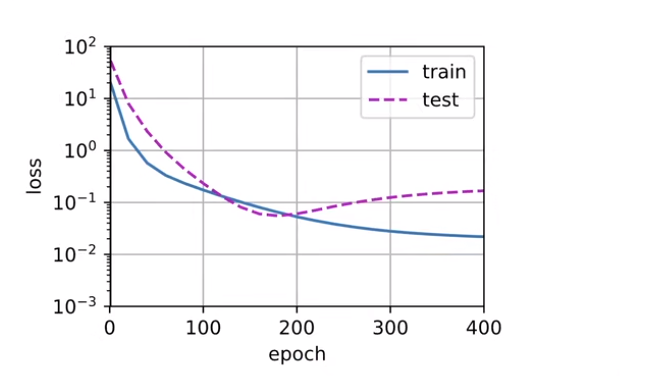
- 1.三阶多项式函数拟合(正常)
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
train(poly_features[:n_train, :4], poly_features[n_train:, :4],
labels[:n_train], labels[n_train:])
学习到的模型参数也接近真实值w = [5, 1.2, −3.4, 5.6]。
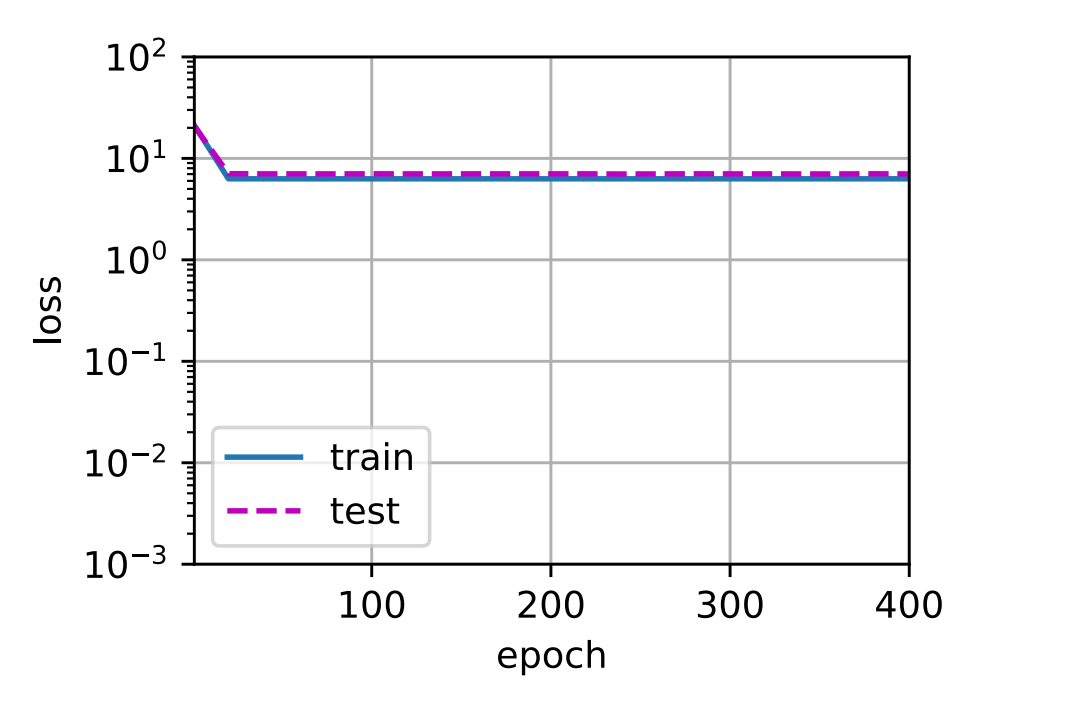
- 2.线性函数拟合(欠拟合)
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2],poly_features[n_train:, :2],labels[:n_train], labels[n_train:])

- 高阶多项式函数拟合(过拟合)
# 从多项式特征中选取所有维度
train(poly_features[:n_train, :],poly_features[n_train:, :],labels[:n_train],labels[n_train:], num_epochs=1500)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)