pytorch-线性回归模型(李沐)
线性回归
- 一个简化模型
假设1:影响房价的关键因素是卧室个数,卫生间个数和居住面积,记为
假设2:成交价是关键因素的加权和
线性模型
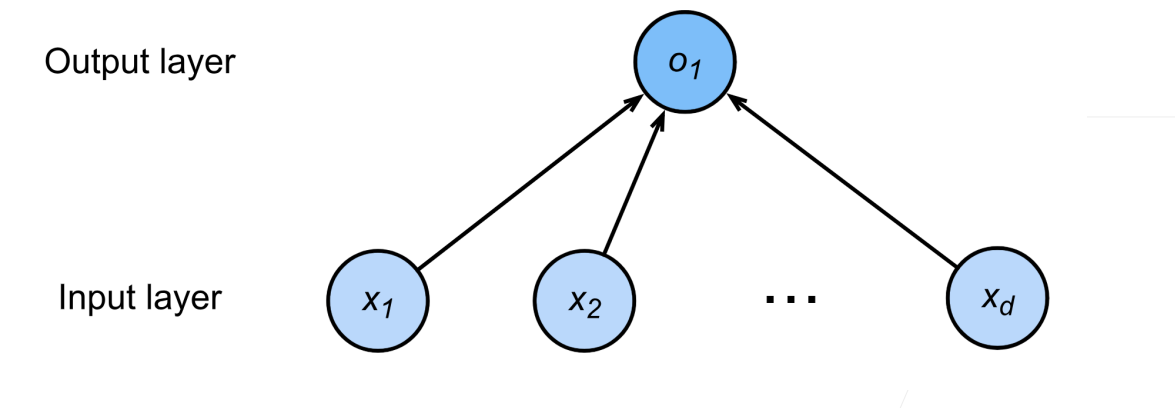
- 给定n维输入
- 线性模型有一个n维权重和一个标量偏差
- 输出是输入的加权和
向量版本就是:
线性模型可以看成单层的神经网络
衡量预估模型
衡量预估模型,就是比较真实值和预估值,例如房价的售价和股价
假设是真实值,是估计值,我们可以比较
这个叫做平方损失
参数学习
- 训练损失
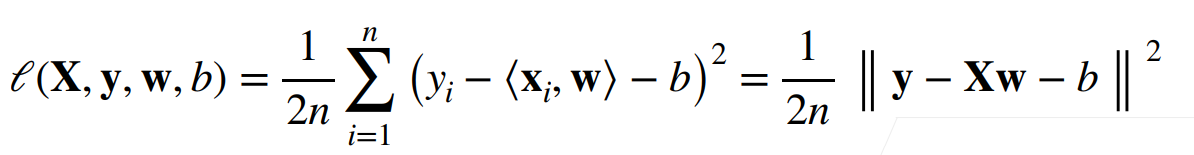
- 最小化参数损失来学习参数
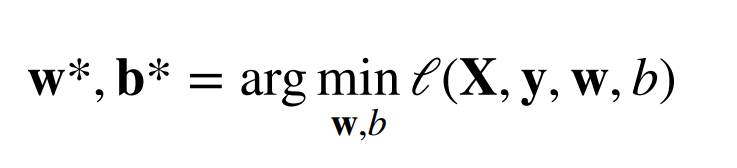
显示解
- 将偏差加入权重 ,
- 其损失函数是凸函数,所以最优解满足
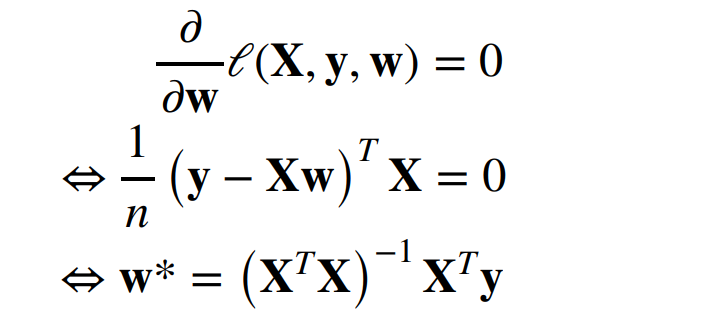
总结
·线性回归是对n维输入的加权,外加偏差
·使用平方损失来衡量预测值和真实值的差异
·线性回归有显示解
·线性回归可以看做是单层神经网络
基础优化方法
梯度下降
- 挑选一个初始值
- 重复迭代参数t=1,2,3
- 沿梯度的方向将增加损失函数值
- 学习率η:步长的超参数
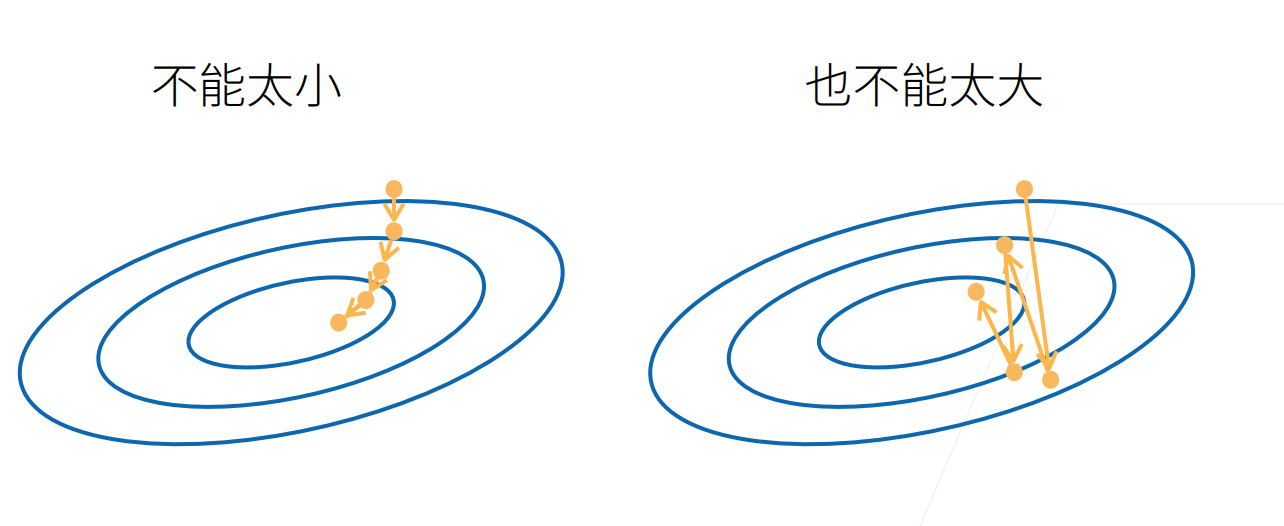
选择学习率η
不能太大,也不能太小
小批量随机梯度下降
-
在整个训练集上算梯度太贵
一个深度神经网络模型可能需要数分钟至数小时 -
我们可以随机采样b个样本,来近似损失
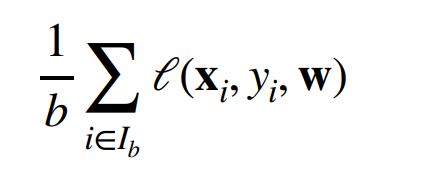
-
b是批量大小,另一个重要的超参数(batch)
选择批量大小
| 不能太大 | 不能太小 |
|---|---|
| 每次计算量太小,不适合并行来最大利用计算资源 | 内存消耗增加浪费计算,例如如果所有样本都是相同的 |
总结
·梯度下降通过不断沿着反梯度方向更新参数求解
·小批量随机梯度下降是深度学习默认的求解算法
·两个重要的超参数是批量大小和学习率
线性回归的从零开始实现
%matplotlib inline
import random
import torch
from d2l import torch as d2l
- ⽣成数据集
为了简单起见,我们根据带有噪声的线性模型构造一个人造数据集。
我们的任务是使⽤这个有限样本的数据集来恢复这个模型的参数。我们将使⽤低维数据,这样可以很容易地将其可视化。在下⾯的代码中,我们⽣成⼀个包含1000个样本的数据集,每个样本包含从标准正态分布中采样的2个特征。
我们使⽤线性模型参数、和噪声项ϵ⽣成数据集及其标签:
也就是说我们最后目标是求w=[2, −3.4],b = 4.2,我们根据这个加一些噪声项来生成一个数据集。
ϵ可以视为模型预测和标签时的潜在观测误差。在这⾥我们认为标准假设成⽴,即ϵ服从均值为0的正态分布。
为了简化问题,我们将标准差设为0.01。下⾯的代码⽣成合成数据集。
def synthetic_data(w, b, num_examples):
"""生成 y = Xw + b + 噪声。X是生成的,根据X,求出y,然后在加上一些噪音"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
注意,features中的每⼀⾏都包含⼀个⼆维数据样本,labels中的每⼀⾏都包含⼀维标签值(⼀个标量)。
print('features:', features[0], '\nlabel:', labels[0])

通过⽣成第⼆个特征features[:, 1]和labels的散点图,可以直观观察到两者之间的线性关系。
d2l.set_figsize()
d2l.plt.scatter(features[:, (1)].detach().numpy(),
labels.detach().numpy(), 1);
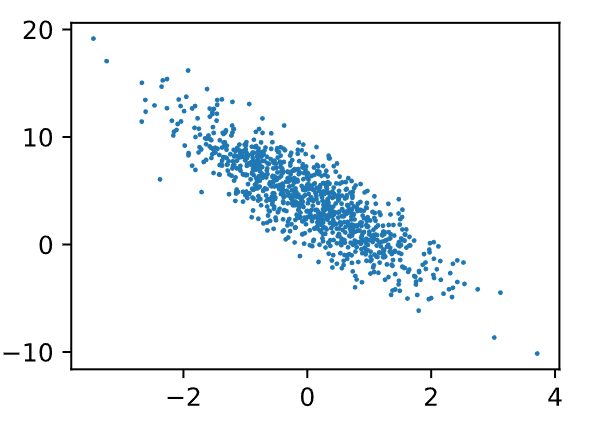
这里labels.detach()中的.detach()和.data作用是一样的.就是.detach()比较安全一点。
- 读取数据集
训练模型时要对数据集进行遍历,每次抽取一小批量样本,并使用它们来更新我们的模型。由于这个过程是训练机器学习算法的基础,所以有必要定义⼀个函数,该函数能打乱数据集中的样本并以小批量方式获取数据。
在下面的代码中,我们定义⼀个data_iter函数,该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。每个小批量包含⼀组特征和签。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) #打散
# print(indices[0:10])
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i:min(i +
batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
1.这个random.shuffle(indices)是将[0,99]这个下标打散,我们可以看一下打散的结果
2.就是这里我们用的是yield返回的,而不是用的return返回的。
ps:yield是暂停函数,return是结束函数; 即yield返回值后继续执行函数体内代码,return返回值后不再执行函数体内代码
yield返回的是一个迭代器(yield本身是生成器-生成器是用来生成迭代器的);return返回的是正常可迭代对象(list,set,dict等具有实际内存地址的存储对象)
- 初始化模型参数
在我们开始用小批量随机梯度下降优化我们的模型参数之前,我们需要先有⼀些参数。在下⾯的代码中,我们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重,并将偏置初始化为0。
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
在初始化参数之后,我们的任务是更新这些参数,直到这些参数足够拟合我们的数据。每次更新都需要计算损失函数关于模型参数的梯度。 有了这个梯度,我们就可以向减小损失的方向更新每个参数。因为手动计算梯度很枯燥而且容易出错,所以没有人会手动计算梯度。
requires_grad: 如果需要为张量计算梯度,则为True,否则为False。我们使用pytorch创建tensor时,可以指定requires_grad为True(默认为False),创建一个Tensor并设置requires_grad=True,requires_grad=True说明该变量需要计算梯度。
grad:当执行完了backward()之后,通过x.grad查看x的梯度值。
- 定义模型
接下来,我们必须定义模型,将模型的输⼊和参数同模型的输出关联起来。回想⼀下,要计算线性模型的输出,我们只需计算输⼊特征和模型权重的矩阵-向量乘法后加上偏置。注意,上⾯的是⼀个向量,而b是⼀个标量。这时候就用到了我们的广播机制:当我们用⼀个向量加⼀个标量时,标量会被加到向量的每个分量上。
def linreg(X, w, b):
"""线性回归模型。"""
return torch.matmul(X, w) + b
- 定义损失函数
因为需要计算损失函数的梯度,所以我们应该先定义损失函数。这⾥我们使平⽅损失函数。在实现中,我们需要将真实值y的形状转换为和预测值y_hat的形状相同。
def squared_loss(y_hat, y):
"""均方损失。"""
return (y_hat - y.reshape(y_hat.shape))**2 / 2
- 定义优化算法
在每⼀步中,使用从数据集中随机抽取的⼀个小批量,然后根据参数计算损失的梯度。接下来,朝着减少损失的方向更新我们的参数。下面的函数实现小批量随机梯度下降更新。该函数接受模型参数集合、学习速率和批量大小作为输入。每⼀步更新的大小由学习速率决定。因为我们计算的损失是⼀个批量样本的总和,所以我们用批量大小(batch_size)来规范化步长,这样步长大小就不会取决于我们对批量大小的选择。
def sgd(params, lr, batch_size):
"""小批量随机梯度下降。"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
对于这个with torch.no_grad()::
我们先说一下requires_grad,在pytorch中,tensor有一个requires_grad参数,如果设置为True,则反向传播时,该tensor就会自动求导。tensor的requires_grad的属性默认为False,若一个节点(叶子变量:自己创建的tensor)requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True(即使其他相依赖的tensor的requires_grad = False)。
当requires_grad设置为False时,反向传播时就不会自动求导了,因此大大节约了显存或者说内存。
with torch.no_grad的作用
在该模块下,所有计算得出的tensor的requires_grad都自动设置为False。
即使一个tensor(命名为x)的requires_grad = True,在with torch.no_grad计算,由x得到的新tensor(命名为w-标量)requires_grad也为False,且grad_fn也为None,即不会对w求导。
- 训练
现在我们已经准备好了模型训练所有需要的要素,可以实现主要的训练过程部分了。理解这段代码⾄关重要,
因为从事深度学习后,相同的训练过程⼏乎⼀遍⼜⼀遍地出现。在每次迭代中,我们读取⼀⼩批量训练样本,
并通过我们的模型来获得⼀组预测。计算完损失后,我们开始反向传播,存储每个参数的梯度。最后,我们
调⽤优化算法sgd来更新模型参数。
概括⼀下,我们将执行以下循环:

在每个迭代周期(epoch)中,我们使⽤data_iter函数遍历整个数据集,并将训练数据集中所有样本都使⽤
⼀次(假设样本数能够被批量⼤⼩整除)。这⾥的迭代周期个数num_epochs和学习率lr都是超参数,分别设
为3和0.03。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) #X和y的⼩批量损失
# 因为l形状是(batch_size,1),⽽不是⼀个标量。l中的所有元素被加到⼀起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size)
with torch.no_grad(): # 表示张量的计算过程中无需计算梯度
train_l = loss(net(features, w, b), labels)
print("w {0} \nb {1} \nloss {2:f}".format(w, b, float(train_l.mean())))
下面这个torch.no_grad()表示张量的计算过程中无需计算梯度,因为它只是想再验证一下loss,并不需要求梯度,反向传播。

比较真实参数和通过训练学到的参数来评估训练的成功程度
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')

总结:
• 我们学习了深度网络是如何实现和优化的。在这⼀过程中只使用张量和自动微分,不需要定义层或复杂的优化器。
• 这⼀节只触及到了表面知识。在下面的部分中,我们将基于刚刚介绍的概念描述其他模型,并学习如何
更简洁地实现其他模型。
线性回归的简洁实现
- 生成数据集
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
- 读取数据集
我们可以调用框架中现有的API来读取数据。我们将features和labels作为API的参数传递,并通过数据迭代器指定batch_size。此外,布尔值is_train表示是否希望数据迭代器对象在每个迭代周期内打乱数据。
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器。"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
data.TensorDataset(data_tensor, target_tensor)
data.TensorDataset可以用来对数据和目标张量(类似Python中的zip()函数)进行包装,包装成dataset。可通过第一维度索引两个张量恢复数据。故要保证两个tensor的第一维度是一致的。
data.DataLoader
下面这个是API的用法解释
torch.utils.data.DataLoader(dataset, batch_size=1,
shuffle=False, sampler=None,
batch_sampler=None, num_workers=0,
collate_fn=None, pin_memory=False,
drop_last=False, timeout=0,
worker_init_fn=None,
multiprocessing_context=None)
dataset (Dataset) – 加载数据的数据集。
batch_size (int, optional) – 每个batch加载多少个样本(默认: 1)。
shuffle (bool, optional) – 设置为True时会在每个epoch重新打乱数据(默认: False).
sampler (Sampler, optional) – 定义从数据集中提取样本的策略。如果指定,则shuffle必须设置成False。
num_workers (int, optional) – 用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
pin_memory:内存寄存,默认为False。在数据返回前,是否将数据复制到CUDA内存中。
drop_last (bool, optional) – 如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False)
timeout:是用来设置数据读取的超时时间的,如果超过这个时间还没读取到数据的话就会报错。 所以,数值必须大于等于0。
batch_size = 10
data_iter = load_array((features, labels), batch_size)
next(iter(data_iter)) # # 使用next得出第一个小批次
使用data_iter的方式与我们在上面使用data_iter函数的方式相同。为了验证是否正常工作,让我们读取并打印第⼀个小批量样本。与上面不同的是,这里我们使用iter构造Python迭代器,并使用next从迭代器中
获取第⼀项。
- 定义模型
当我们想实现线性回归时,我们明确定义了模型参数变量,并编写了计算的代码,这样通过基本的线性代数运算得到输出。但是,如果模型变得更加复杂,且当我们⼏乎每天都需要实现模型时,自然会想简化这个过程。
对于标准深度学习模型,我们可以使用框架的预定义好的层。这使我们只需关注使用哪些层来构造模型,而不必关注层的实现细节。我们首先定义⼀个模型变量net,它是⼀个Sequential类的实例。Sequential类将多个层串联在⼀起。当给定输入数据时,Sequential实例将数据传入到第⼀层,然后将第一层的输出作为第二层的输入,以此类推。在下面的例子中,我们的模型只包含⼀个层,因此实际上不需要Sequential。但是由于以后⼏乎所有的模型都是多层的,在这⾥使用Sequential会让你熟悉“标准的流水线”。
回顾单层网络架构,这⼀单层被称为全连接层(fully-connected layer),因为它的每⼀个输入都通过矩阵-向量乘法得到它的每个输出。在PyTorch中,全连接层在Linear类中定义。值得注意的是,我们将两个参数传递到nn.Linear中。第一个指
定输入特征形状,即2,第二个指定输出特征形状,输出特征形状为单个标量,因此为1。
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))
#搭建一个单层神经网络,并且神经元使用的是线性结构,且有两个输入,一个输出
- 初始化模型参数
在使用net之前,我们需要初始化模型参数。如在线性回归模型中的权重和偏置。深度学习框架通常有预定义的方法来初始化参数。在这里,我们指定每个权重参数应该从均值为0、标准差为0.01的正态分布中随机采样,偏置参数将初始化为零。正如我们在构造nn.Linear时指定输入和输出尺寸⼀样,现在我们能直接访问参数以设定它们的初始值。我们通过net[0]选择网络中的第一个图层,然后使用weight.data和bias.data方法访问参数。我们还可以使用替换方法normal_和fill_来重写参数值。
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
当然这一部分也可以不写
- 定义损失函数
计算均方误差使用的是MSELoss类,也称为平方L2范数。默认情况下,它返回所有样本损失的平均值。
loss = nn.MSELoss()
- 定义优化函数
小批量随机梯度下降算法是⼀种优化神经网络的标准工具,PyTorch在optim模块中实现了该算法的许多变种。当我们实例化⼀个SGD实例时,我们要指定优化的参数(可通过net.parameters()从我们的模型中获得)以及优化算法所需的超参数字典。小批量随机梯度下降只需要设置lr值,这⾥设置为0.03。
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
- 训练
通过深度学习框架的高级API来实现我们的模型只需要相对较少的代码。我们不必单独分配参数、不必定义我们的损失函数,也不必手动实现小批量随机梯度下降。当我们需要更复杂的模型时,高级API的优势将大大增加。当我们有了所有的基本组件,训练过程代码与我们从零开始实现时所做的非常相似。
回顾⼀下:在每个迭代周期⾥,我们将完整遍历⼀次数据集(train_data),不停地从中获取⼀个小批量的输入和相应的标签。对于每⼀个小批量,我们会进行以下步骤:
• 通过调用net(X)生成预测并计算损失l(前向传播)。
• 通过进行反向传播来计算梯度。
• 通过调用优化器来更新模型参数
为了更好的衡量训练效果,我们计算每个迭代周期后的损失,并打印它来监控训练过程。
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y) ##比较计算出的yhat和真实的y的RMSE
trainer.zero_grad() ##用来清除模型的累计梯度
l.backward() ##反向传递,回调
trainer.step() ##更新模型参数
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
w = net[0].weight.data
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估计误差:', true_b - b)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)