1.枚举网格搜索&随机网格搜索&Halving网格搜索
1 枚举网格搜索(Exhaustive Grid Search)
1.1 基本原理
在所有超参数优化的算法当中,枚举网格搜索是最为基础和经典的方法。在搜索开始之前,我们需要人工将每个超参数的备选值一一列出,多个不同超参数的不同取值之间排列组合,最终将组成一个参数空间(parameter space)。枚举网格搜索算法会将这个参数空间当中所有的参数组合带入模型进行训练,最终选出泛化能力最强的组合作为模型的最终超参数。
当衡量模型的“泛化能力”时,我们往往会使用交叉验证输出指标的均值和方差,因此超参数优化算法总是与网格搜索密不可分。
在进行网格搜索之前,我们需要先确认进行搜索的参数空间。所谓参数空间,就是备选参数所构成的空间。以随机森林算法为例,假设我们要调整n_estimators与max_depth,且n_estimators的备选范围是[50,100,150,200,250,300],max_depth的备选范围是[2,3,4,5,6],则两个参数可以构成如下二维空间。
import matplotlib
import matplotlib.pyplot as plt
n_e_list = [*range(50,350,50)]
m_d_list = [*range(2,7)]
comb = pd.DataFrame([(n_estimators, max_depth) for n_estimators in n_e_list for max_depth in m_d_list])
plt.figure(dpi=300)
plt.scatter(comb.iloc[:,0],comb.iloc[:,1],cmap="Blues")
plt.xticks([*range(50,350,50)])
plt.yticks([*range(2,7)])
plt.xlabel("n_estimators")
plt.ylabel("max_depth");

假设我们要调整n_estimators,max_depth与min_sample_split,且min_sample_split的备选参数为[2,3,4,5],则三个参数可以构成如下三维空间:
m_s_s_list = [2,3,4,5]
X,Y,Z = np.meshgrid(n_e_list,m_d_list,m_s_s_list)
plt.figure(dpi=300)
ax = plt.axes(projection="3d")
ax.view_init(2, -15)
#ax.view_init(90, -30)
ax.scatter(X,Y,Z,c=Z,cmap="Blues",edgecolor="k",linewidth=0.3,s=20,alpha=1);
ax.set_xticks([*range(50,350,50)])
ax.set_yticks([*range(2,7)])
ax.set_zticks([2,3,4,5])
plt.xlabel("n_estimators",fontsize=7)
plt.ylabel("max_depth",fontsize=7)
ax.set_zlabel("min_sample_split",fontsize=7)
ax.zaxis.set_tick_params(labelsize=7)
ax.xaxis.set_tick_params(labelsize=7)
ax.yaxis.set_tick_params(labelsize=7);
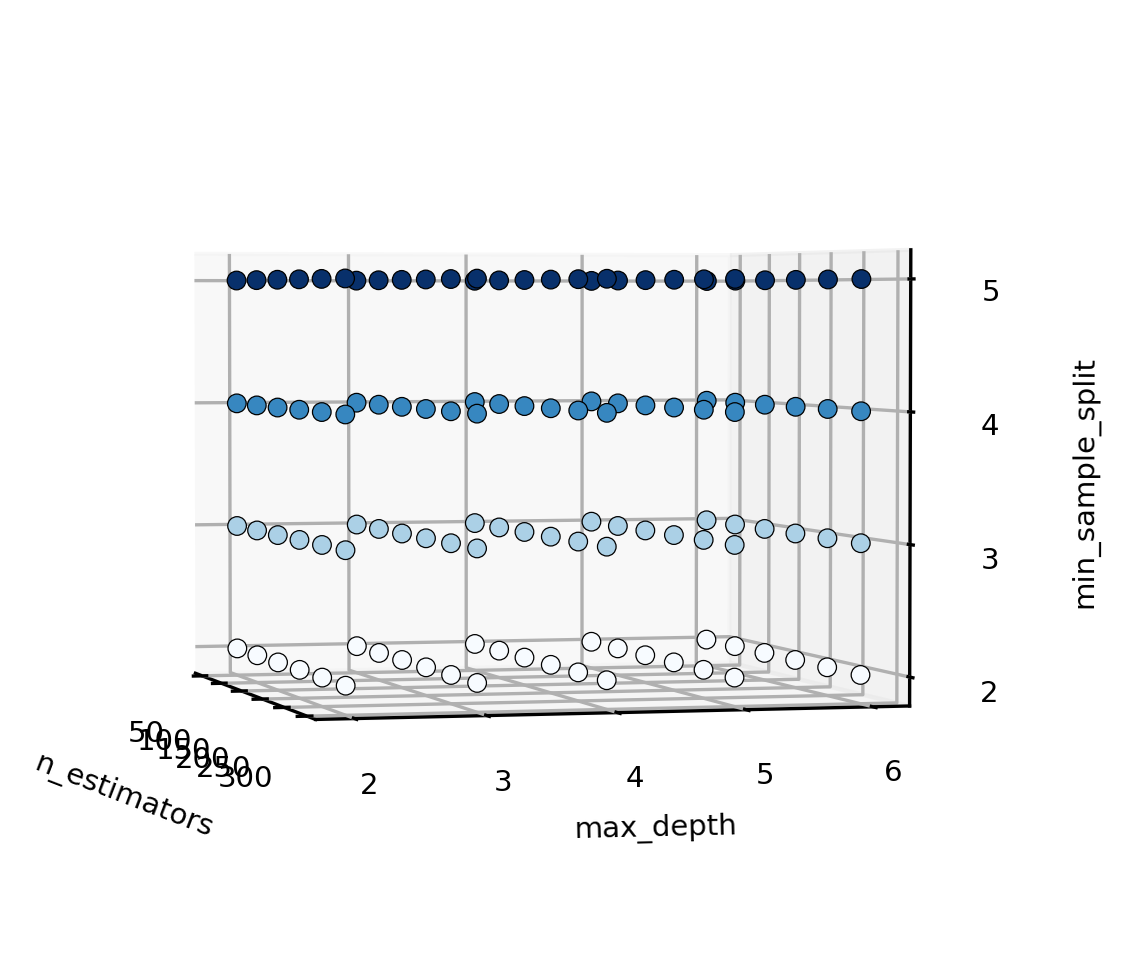
在参数空间中,每一个点就是一组参数的组合,枚举网格搜索的目标就是从空间中挑选出最好的参数组合。因此,枚举网格搜索会对空间中每一个点进行建模,以找出令模型整体损失函数最小、泛化能力最强的组合。
1.2 实现
在sklearn当中,我们可以很容易地实现网格搜索,以随机森林回归器为例:
classsklearn.model_selection.GridSearchCV(estimator, param_grid, , scoring=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch='2n_jobs', error_score=nan, return_train_score=False)
全部参数如下所示,其中加粗的是需要高度关注的参数:
| Name | Description |
|---|---|
| estimator | 调参对象,某评估器 |
| param_grid | 参数空间,可以是字典或者字典构成的列表,稍后介绍参数空间的创建方法 |
| scoring | 评估指标,支持同时输出多个参数 |
| n_jobs | 设置工作时参与计算的线程数 |
| refit | 挑选评估指标和最佳参数,在完整数据集上进行训练 |
| cv | 交叉验证的折数 |
| verbose | 输出工作日志形式 |
| pre_dispatch | 多任务并行时任务划分数量 |
| error_score | 当网格搜索报错时返回结果,选择'raise'时将直接报错并中断训练过程,其他情况会显示警告信息后继续完成训练 |
| return_train_score | 在交叉验证中是否显示训练集中参数得分 |
1、导入数据
import time #计时模块time
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.model_selection import KFold, GridSearchCV
def RMSE(cvresult,key):
return (abs(cvresult[key])**0.5).mean()
data = pd.read_csv(r"D:\Pythonwork\2021ML\PART 2 Ensembles\datasets\House Price\train_encode.csv",index_col=0)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
X.shape
X.columns.tolist()
y.describe() #MSE,RMSE
X.head()
2、创建参数空间
param_grid_simple = {'n_estimators': [*range(5,100,5)]
, 'max_depth': [*range(25,36,2)]
, "max_features": ["log2","sqrt","auto"]
}
3、实例化用于搜索的评估器、交叉验证评估器与网格搜索评估器
reg = RFR(random_state=1412,verbose=True,n_jobs=12)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
search = GridSearchCV(estimator=reg
,param_grid=param_grid_simple
,scoring = "neg_mean_squared_error" #MSE
,verbose = True
,cv = cv
,n_jobs=12)
4、训练网格搜索评估器
#=====【TIME WARNING: 5~10min】=====#
start = time.time()
search.fit(X,y)
print(time.time() - start)
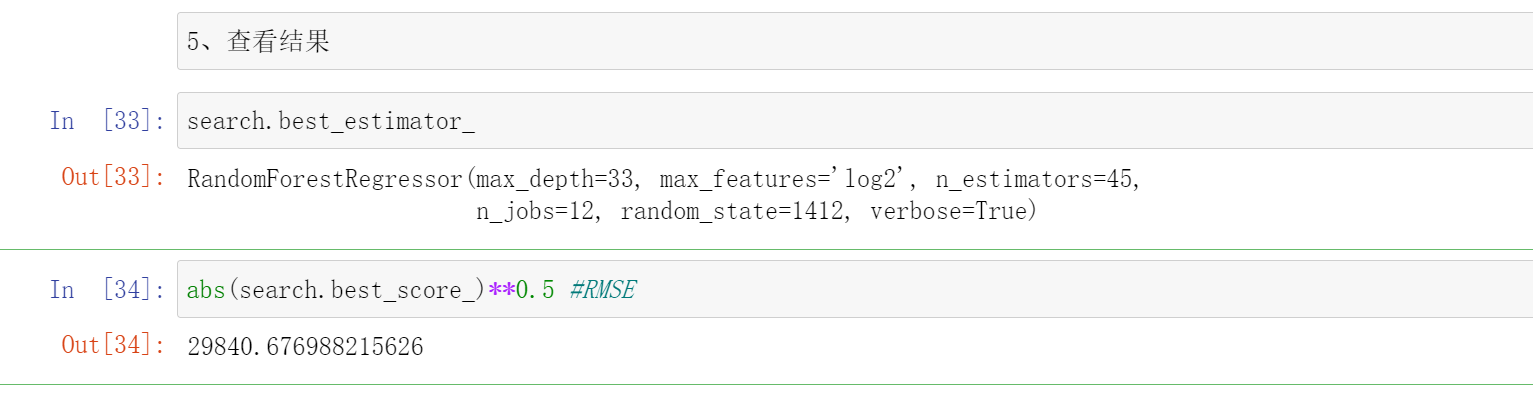
5、查看结果
search.best_estimator_
abs(search.best_score_)**0.5 #RMSE
""
RandomForestRegressor(max_depth=33, max_features='log2', n_estimators=45,n_jobs=12, random_state=1412, verbose=True)
""
1.3 枚举网格搜索的理论极限
如果参数空间中的某一个点指向了损失函数真正的最小值,那枚举网格搜索时一定能够捕捉到该最小值以及对应的参数(相对的,假如参数空间中没有任意一点指向损失函数真正的最小值,那网格搜索就一定无法找到最小值对应的参数组合)
而参数空间越大、越密,参数空间中的组合刚好覆盖损失函数最小值点的可能性就会越大。这是说,极端情况下,当参数空间穷尽了所有可能的取值时,网格搜索一定能够找到损失函数的最小值所对应的最优参数组合,且该参数组合的泛化能力一定是强于人工调参的。
1.4 枚举网格搜索的限制:算力与时间
但是,参数空间越大,网格搜索所需的算力和时间也会越大,当参数维度上升时,网格搜索所需的计算量更是程指数级上升的:
只有1个参数n_estimators,备选范围是[50,100,150,200,250,300],需要建模6次。
增加参数max_depth,且备选范围是[2,3,4,5,6],需要建模30次。
增加参数min_sample_split,且备选范围为[2,3,4,5],需要建模120次。
同时,参数优化的目标是找出令模型泛化能力最强的组合,因此需要交叉验证来体现模型的泛化能力,假设交叉验证次数为5,则三个参数就需要建模600次。在面对超参数众多、且超参数取值可能无限的人工神经网络、融合模型、集成模型时,伴随着数据和模型的复杂度提升,网格搜索所需要的时间会急剧增加,完成一次枚举网格搜索可能需要耗费几天几夜。因此当我们使用网格搜索时,要尽量精简参数空间,以节约计算资源。
2 随机网格搜索(Random Grid Search)
2.1 基本原理
网格搜索伴随着数据和模型的复杂度提升,网格搜索所需要的时间急剧增加。对于刚才尝试的随机森林算法,如果使用过w的数据,搜索时间则会立刻上升好几个小时。考虑到后续实践过程中,算法和数据都将更加复杂,而建模过程中超参数调优是模型训练的必备环节,因此,我们急需寻找到一种更加高效的超参数搜索方法。
首先,当所使用的算法确定时,决定枚举网格搜索运算速度的因子一共有两个:
1 参数空间的大小:参数空间越大,需要建模的次数越多
2 数据量的大小:数据量越大,每次建模时需要的算力和时间越多
因此,sklearn中的网格搜索优化方法主要包括两类,其一是调整搜索空间,其二是调整每次训练的数据。其中,调整参数空间的具体方法,是放弃原本的搜索中必须使用的全域超参数空间,改为挑选出部分参数组合,构造超参数子空间,并只在子空间中进行搜索。以下图的二维空间为例,枚举网格搜索必须对30种参数组合都进行搜索,而调整搜索空间之后,我们只抽样出橙色的参数组合作为“子空间”,并只对橙色参数组合进行搜索。如此一来,整体搜索所需的计算量就大大下降了,原本需要30次建模,现在只需要8次建模。
n_e_list = [*range(50,350,50)]
m_d_list = [*range(2,7)]
comb = pd.DataFrame([(n_estimators, max_depth) for n_estimators in n_e_list for max_depth in m_d_list])
plt.figure(dpi=300)
plt.scatter(comb.iloc[:,0],comb.iloc[:,1],cmap="Blues")
plt.scatter([50,250,200,200,300,100,150,150],[4,2,6,3,2,3,2,5],cmap="red",s=20,linewidths=5)
plt.xticks([*range(50,350,50)])
plt.yticks([*range(2,7)])
plt.xlabel("n_estimators")
plt.ylabel("max_depth");

在sklearn中,随机抽取参数子空间并在子空间中进行搜索的方法叫做随机网格搜索RandomizedSearchCV。由于搜索空间的缩小,需要枚举和对比的参数组的数量也对应减少,整体搜索耗时也将随之减少,因此随机网格搜索的速度比枚举网格搜索快很多。
不过,需要注意的是,随机网格搜索在实际运行时,并不是先抽样出子空间,再对子空间进行搜索,而是仿佛“循环迭代”一般,在一次次迭代随机抽取1组参数进行建模,下一次迭代再随机抽取1组参数进行建模,这种随机抽样是不放回的。我们可以控制随机网格搜索的迭代次数,来控制整体被抽出的参数子空间的大小。
2.2 随机网格搜索的实现
from sklearn.model_selection import RandomizedSearchCV
class sklearn.model_selection.RandomizedSearchCV(estimator, param_distributions, *, n_iter=10, scoring=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', random_state=None, error_score=nan, return_train_score=False)
全部参数解读如下,其中加粗的是随机网格搜索独有的参数:
| Name | Description |
|---|---|
| estimator | 调参对象,某评估器 |
| param_distributions | 全域参数空间,可以是字典或者字典构成的列表 |
| n_iter | 迭代次数,迭代次数越多,抽取的子参数空间越大 |
| scoring | 评估指标,支持同时输出多个参数 |
| n_jobs | 设置工作时参与计算的线程数 |
| refit | 挑选评估指标和最佳参数,在完整数据集上进行训练 |
| cv | 交叉验证的折数 |
| verbose | 输出工作日志形式 |
| pre_dispatch | 多任务并行时任务划分数量 |
| random_state | 随机数种子 |
| error_score | 当网格搜索报错时返回结果,选择'raise'时将直接报错并中断训练过程,其他情况会显示警告信息后继续完成训练 |
| return_train_score | 在交叉验证中是否显示训练集中参数得分 |
一定要加上这个random_state,否则有可能你运行了很久,但是不能把代码复现
我们依然借用之前已经建立好的数据X与y,以及随机森林回归器,来实现随机网格搜索:
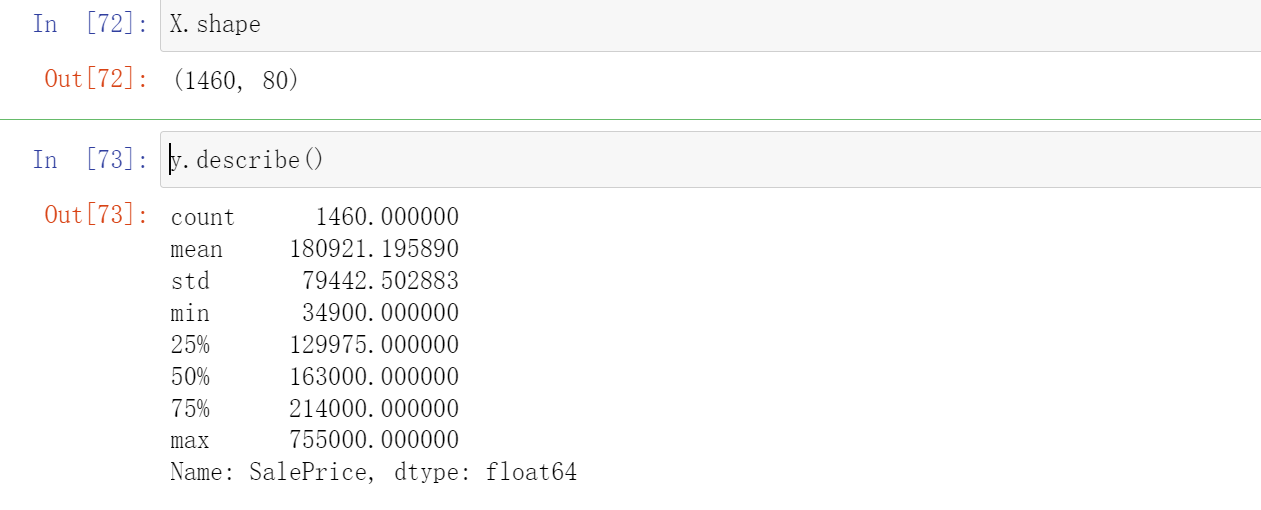
X.shape
y.describe()
#创造参数空间 - 使用与网格搜索时完全一致的空间
param_grid_simple = {'n_estimators': [*range(5,100,5)]
, 'max_depth': [*range(25,36,2)]
, "max_features": ["log2","sqrt","auto"]
}
#建立回归器、交叉验证
reg = RFR(random_state=1412,verbose=True,n_jobs=12)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
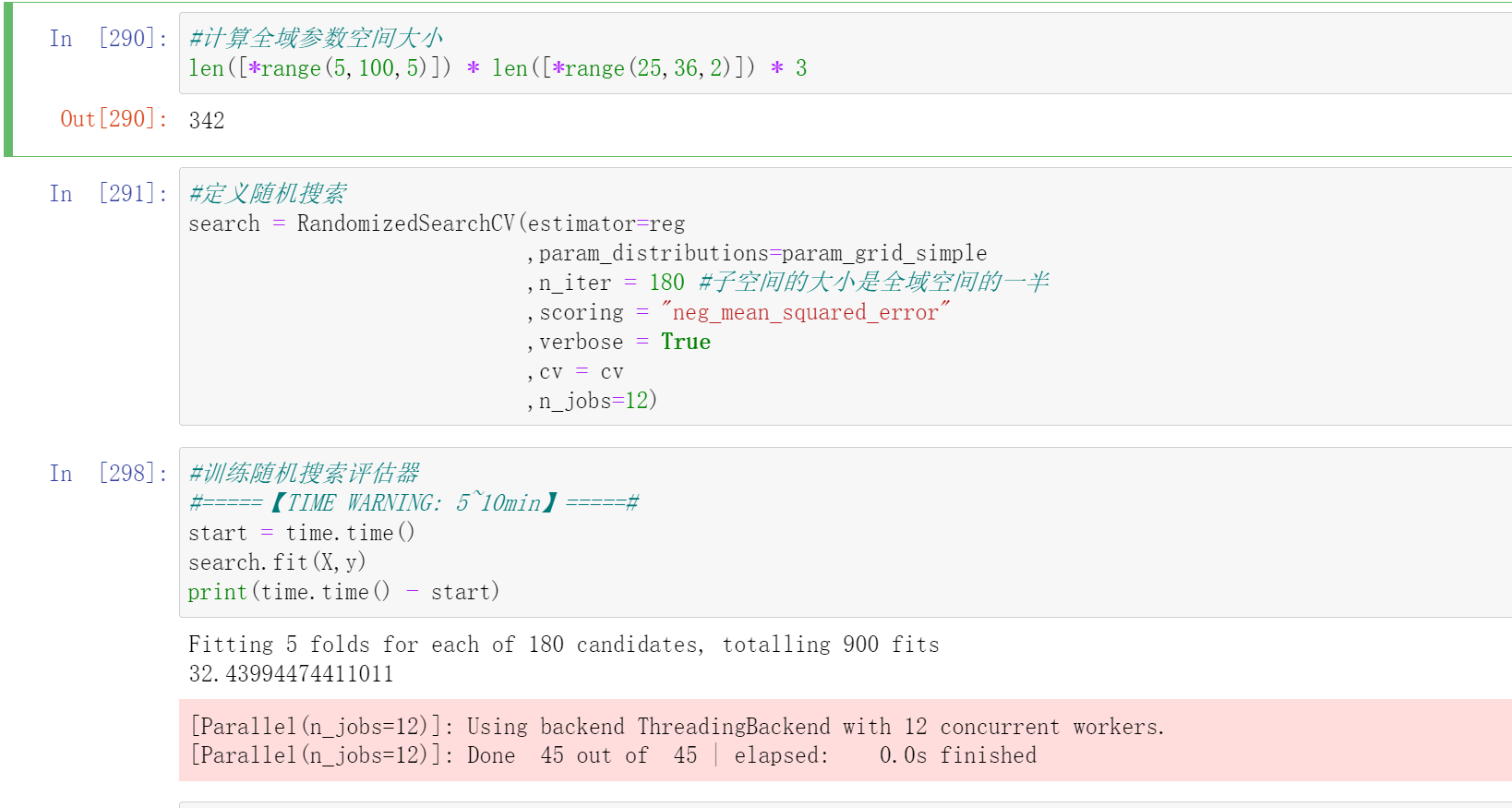
#计算全域参数空间大小
len([*range(5,100,5)]) * len([*range(25,36,2)]) * 3
#342
#定义随机搜索
search = RandomizedSearchCV(estimator=reg
,param_distributions=param_grid_simple
,n_iter = 180 #子空间的大小是全域空间的一半
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv
,n_jobs=12)
注意这里的n_iter很重要,我们可以根据全域参数空间的大小进行选择
#训练随机搜索评估器
#=====【TIME WARNING: 5~10min】=====#
start = time.time()
search.fit(X,y)
print(time.time() - start)
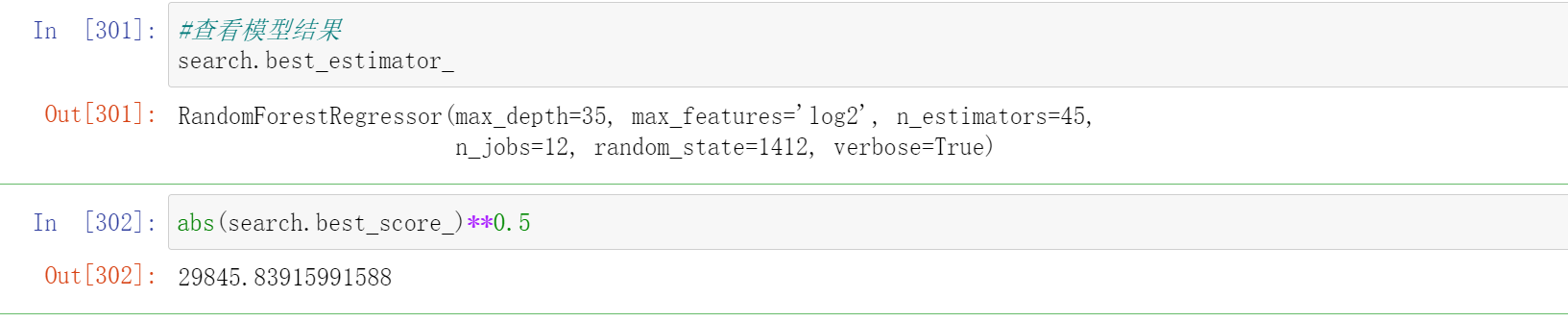
#查看模型结果
search.best_estimator_
abs(search.best_score_)**0.5
""
RandomForestRegressor(max_depth=35, max_features='log2', n_estimators=45,n_jobs=12, random_state=1412, verbose=True)
""
| HPO方法 | 网格搜索 | 随机搜索 |
|---|---|---|
| 全域空间/实际空间 | 342/342 | 180/342 |
| 搜索时间 | 53.385 | 32.439(↓) |
| 最优分数(RMSE) | 29840.676 | 29845.839 |
很明显,在相同参数空间、相同模型的情况下,随机网格搜索的运算速度是普通网格搜索的一半,当然,这与子空间是全域空间的一半有很大的联系。由于随机搜索只是降低搜索的次数,并非影响搜索过程本身,因此其运行时间基本就等于n_iter/全域空间组合数 * 网格搜索的运行时间。
2.3 随机网格搜索的理论极限
虽然通过缩小子空间可以提升搜索的速度,但是随机网格搜索的精度看起来并没有削减太多,随机网格搜索可以得到和网格搜索一样好的结果吗?它也像网格搜索一样,可以得到最优的参数组合吗?为什么缩小参数空间之后,随机网格搜索的结果还与网格搜索一致?
从直觉上来说,我们很难回答这些问题,但我们可以从数学的随机过程的角度来理解这个问题。在机器学习算法当中,有非常多通过随机来降低运算速度(比如Kmeans,随机挑选样本构建簇心)、或通过随机来提升模型效果的操作(比如随机森林,比如小批量随机梯度下降)。随机网格搜索属于前者,而它能够有效的根本原因在于:
- 抽样出的子空间反馈出与全域空间相似的分布
- 子空间越大,子空间与全域空间越相似
- 在与全域空间相似的空间中,随机搜索即便不能找到真正的最小值,也能找到与最小值高度接近的某一个次小值
如果全域空间包括了理论上的损失函数最小值,那一个与全域空间分布高度相似的子空间很可能也包括损失函数的最小值,或包括非常接近最小值的一系列值。
我们可以绘图进行查看:
from mpl_toolkits.mplot3d import axes3d
p1, p2, MSE = axes3d.get_test_data(0.05)
#假设现在有两个参数,p1与p2,两个参数组成的参数组合对应着损失函数值MSE
#参数0.05是指参数空间中,点与点之间的距离
#因此该数字越小,取出来的样本越多
len(p1) #参数1有120个取值
len(p2) #Y也有120个取值
MSE.shape #排列组合,则有120*120 = 14400个取值结果
#参数空间
plt.figure(dpi=300)
plt.scatter(p1,p2,s=0.2)
plt.xticks(fontsize=9)
plt.yticks(fontsize=9);

#参数与损失共同构建的函数
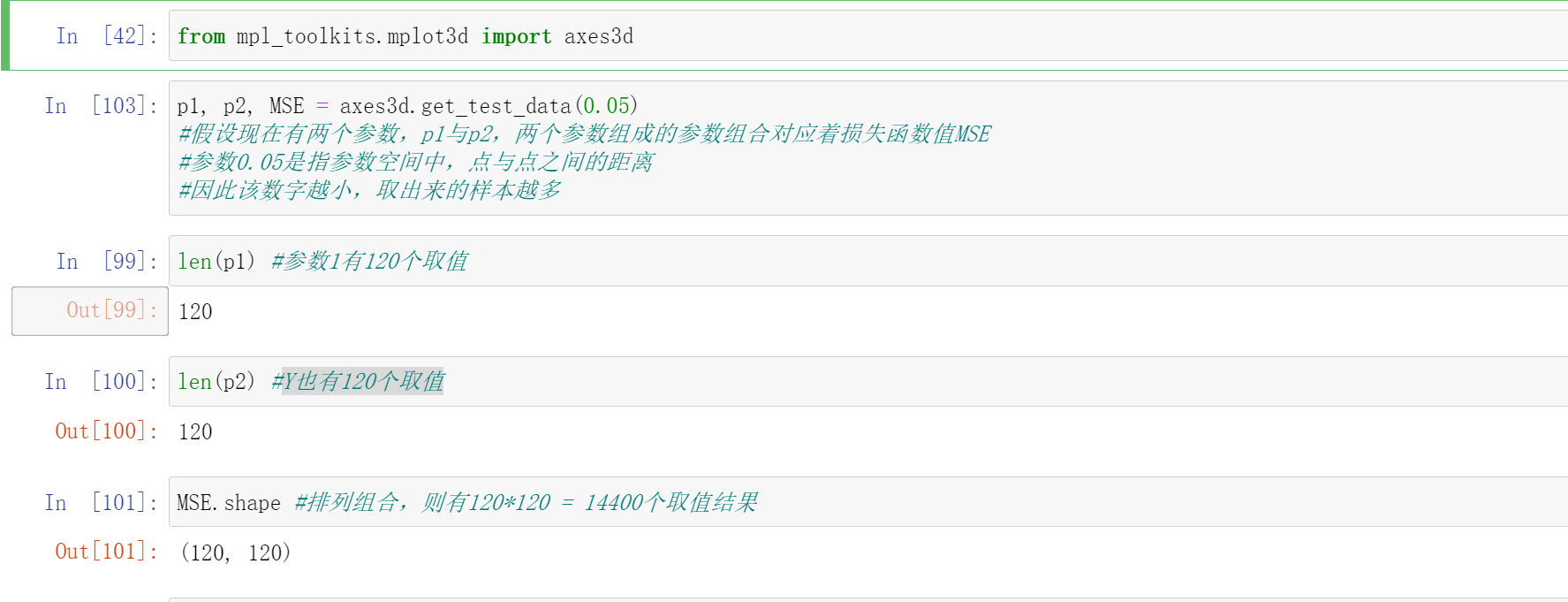
plt.figure(dpi=300)
ax = plt.axes(projection="3d")
ax.plot_wireframe(p1,p2,MSE,rstride=2,cstride=2,linewidth=0.5)
ax.zaxis.set_tick_params(labelsize=7)
ax.xaxis.set_tick_params(labelsize=7)
ax.yaxis.set_tick_params(labelsize=7);
np.min(MSE) #整个参数中,可获得的MSE最小值是-73.39
# -73.39620971601681

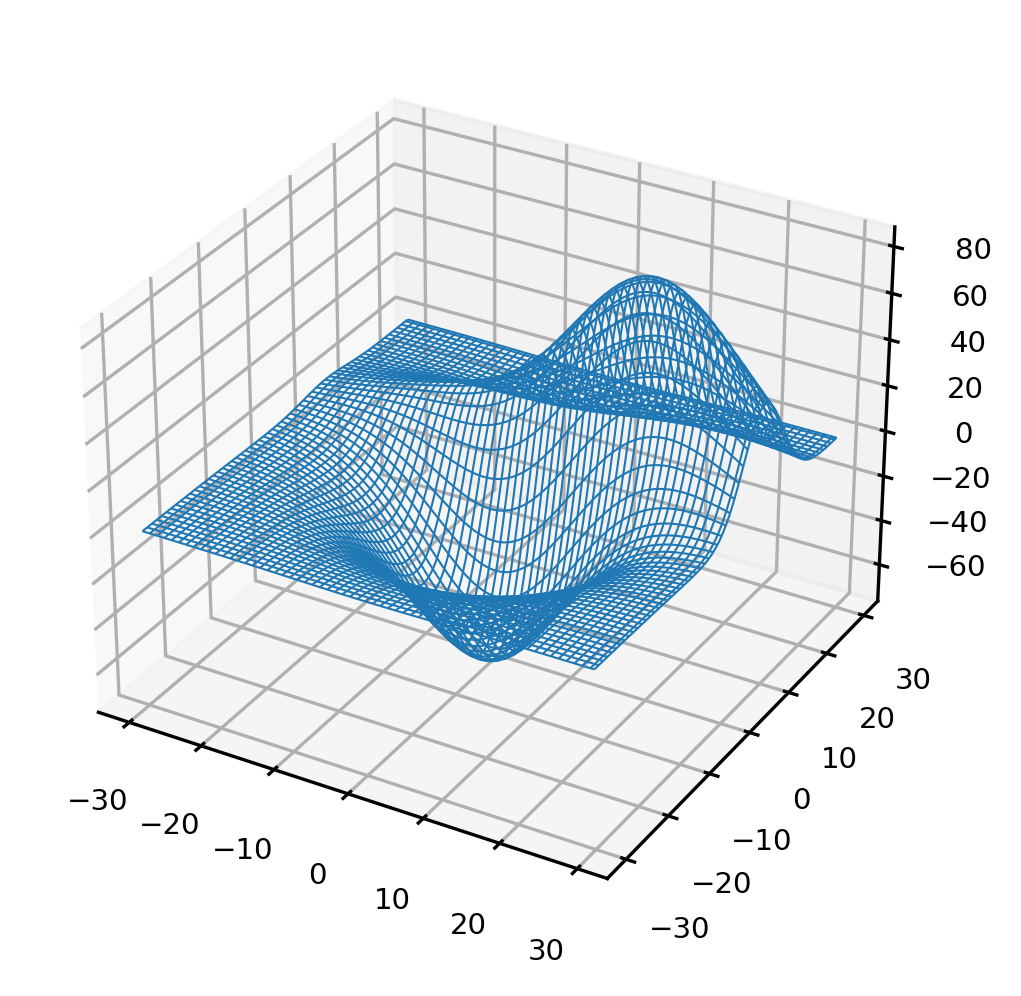
#现在,我们从该空间上抽取子空间
import numpy as np
#我们从空间中抽取n个组合,n越大子空间越大
#现在总共有14400个组合
n = 10000
unsampled = np.random.randint(0,14400,14400-n)
p1, p2, MSE = axes3d.get_test_data(0.05)
MSE = MSE.ravel()
MSE[unsampled] = np.nan #没有被抽出的样本,我们让损失函数值为空
MSE = MSE.reshape((120,120))
#参数与损失共同构建的函数
plt.figure(dpi=300)
ax = plt.axes(projection="3d")
ax.plot_wireframe(p1,p2,MSE,rstride=2,cstride=2,linewidth=0.5)
ax.zaxis.set_tick_params(labelsize=7)
ax.xaxis.set_tick_params(labelsize=7)
ax.yaxis.set_tick_params(labelsize=7);
#求出当前损失函数上的最小值
MSE = MSE.ravel().tolist()
MSE = [x for x in MSE if str(x) != 'nan']
print(np.min(MSE))
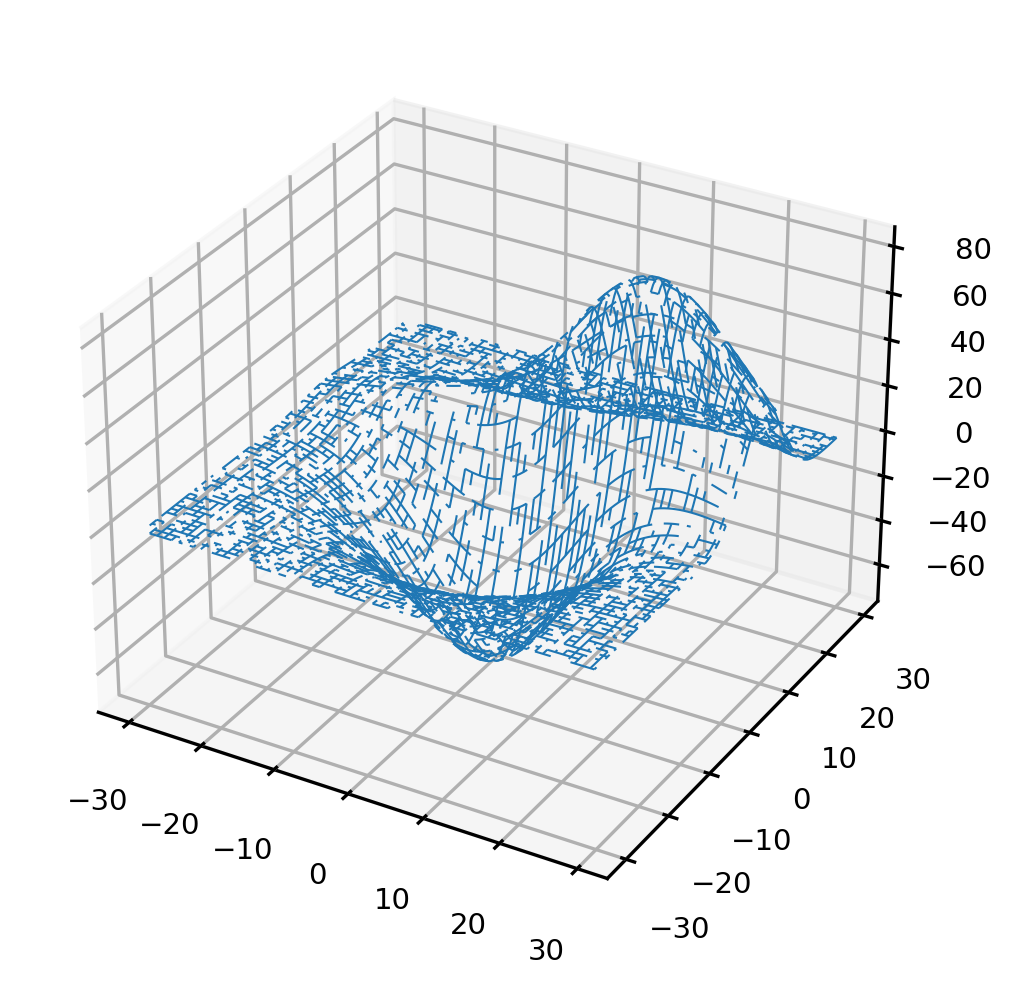
很容易发现,当抽取的子空间越大时,子空间的分布会与全域空间越来越相似。同时,即便抽取的子空间非常小,子空间中的分布还是很大程度上与全域空间相似,并且函数的最小值、或与最小值高度接近的某个值,一定会被包括在子空间当中。
当然了,这是基于全域空间非常大的情况,如果全域空间本来就比较小(点分布比较稀疏),在抽样时抽出损失函数最小值的可能性就会比较小,随机搜索结果相应的也会较差。
我们可以在图像上验证如下事实:
- 抽样出的子空间可以一定程度上反馈出全域空间的分布
- 子空间相对越大(含有的参数组合数越多),子空间的分布越接近全域空间的分布
- 当全域空间本身足够密集时,很小的子空间也能获得与全域空间相似的分布
- 如果全域空间包括了理论上的损失函数最小值,那一个与全域空间分布高度相似的子空间很可能也包括损失函数的最小值,或包括非常接近最小值的一系列次小值
- 在与全域空间分布相似的子空间中,随机搜索即便不能找到真正的最小值,也有很高的概率找到与最小值高度接近的某一个次小值
因此,只要子空间足够大,随机网格搜索的效果一定是高度逼近枚举网格搜索的。在全域参数空间固定时,随机网格搜索可以在效率与精度之间做权衡。子空间越大,精度越高,子空间越小,效率越高。
- 更大的全域空间
不过,由于随机网格搜索计算更快,所以在相同计算资源的前提下,我们可以对随机网格搜索使用更大的全域空间,因此随机搜索可能得到比网格搜索更好的效果:
#创造参数空间 - 比网格搜索大一倍的全域空间
param_grid_simple = {'n_estimators': [*range(5,100,5)]
, 'max_depth': [*range(25,36,2)]
, "max_features": ["log2","sqrt",16,32,64,"auto"]
}
#计算全域参数空间大小,这是我们能够抽样的最大值
len([*range(5,100,5)]) * len([*range(25,36,2)]) * 6
# 684

#建立回归器、交叉验证
reg = RFR(random_state=1412,verbose=True,n_jobs=12)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
#定义随机搜索
search = RandomizedSearchCV(estimator=reg
,param_distributions=param_grid_simple
,n_iter = 360 #使用与枚举网格搜索类似的拟合次数
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv
,n_jobs=12)
#训练随机搜索评估器
#=====【TIME WARNING: 5~10min】=====#
start = time.time()
search.fit(X,y)
print(time.time() - start)

#查看最佳评估器
search.best_estimator_
""
RandomForestRegressor(max_depth=31, max_features=16, n_estimators=85, n_jobs=12,random_state=1412, verbose=True)
""
#查看最终评估指标
abs(search.best_score_)**0.5
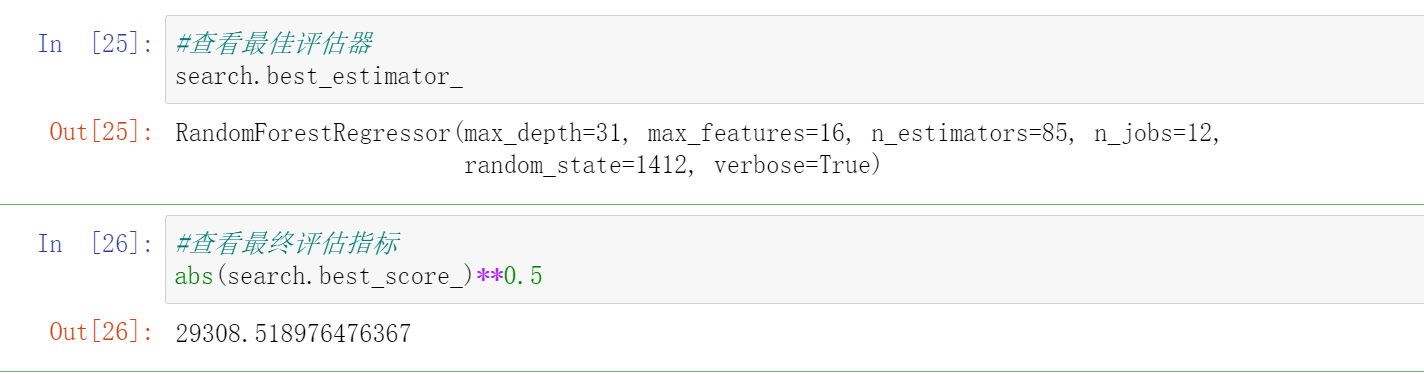
| HPO方法 | 网格搜索 | 随机搜索 | 随机搜索 |
|---|---|---|---|
| 搜索空间/全域空间 | 342/342 | 180/342 | 360/684 |
| 搜索时间 | 53.385 | 32.439(↓) | 64.656 |
| 最优分数(RMSE) | 29840.676 | 29845.839 | 29307.518(↓) |
可以发现,当全域参数空间增大之后,随即网格搜索可以使用与小空间上的网格搜索相似的时间,来求得更好的结果。除了可以容忍更大的参数空间之外,随机网格搜索还可以接受连续性变量作为参数空间的输入。
3 对半网格搜索(Halving Grid Search)
3.1 基本原理
在讲解随机网格搜索之前,我们梳理了决定枚举网格搜索运算速度的因子:
1 参数空间的大小:参数空间越大,需要建模的次数越多
2 数据量的大小:数据量越大,每次建模时需要的算力和时间越多
面对枚举网格搜索过慢的问题,sklearn中呈现了两种优化方式:其一是调整搜索空间,其二是调整每次训练的数据。调整搜索空间的方法就是随机网格搜索,而调整每次训练数据的方法就是对半网格搜索。
假设现在存在数据集\(D\),我们从数据集\(D\)中随机抽样出一个子集\(d\)。如果一组参数在整个数据集\(D\)上表现较差,那大概率这组参数在数据集的子集\(d\)上表现也不会太好。反之,如果一组参数在子集\(d\)上表现不好,我们也不会信任这组参数在全数据集\(D\)上的表现。参数在子集与全数据集上反馈出的表现一致,如果这一假设成立,那在网格搜索中,比起每次都使用全部数据来验证一组参数,或许我们可以考虑只带入训练数据的子集来对超参数进行筛选,这样可以极大程度地加速我们的运算。
但在现实数据中,这一假设要成立是有条件的,即任意子集的分布都与全数据集D的分布类似。当子集的分布越接近全数据集的分布,同一组参数在子集与全数据集上的表现越有可能一致。根据之前在随机网格搜索中得出的结论,我们知道子集越大、其分布越接近全数据集的分布,但是大子集又会导致更长的训练时间,因此为了整体训练效率,我们不可能无限地增大子集。这就出现了一个矛盾:大子集上的结果更可靠,但大子集计算更缓慢。对半网格搜索算法设计了一个精妙的流程,可以很好的权衡子集的大小与计算效率问题,我们来看具体的流程:
1、首先从全数据集中无放回随机抽样出一个很小的子集\(d_0\),并在\(d_0\)上验证全部参数组合的性能。根据\(d_0\)上的验证结果,淘汰评分排在后1/2的那一半参数组合
2、然后,从全数据集中再无放回抽样出一个比\(d_0\)大一倍的子集\(d_1\),并在\(d_1\)上验证剩下的那一半参数组合的性能。根据\(d_1\)上的验证结果,淘汰评分排在后1/2的参数组合
3、再从全数据集中无放回抽样出一个比\(d_1\)大一倍的子集\(d_2\),并在\(d_2\)上验证剩下1/4的参数组合的性能。根据\(d_2\)上的验证结果,淘汰评分排在后1/2的参数组合……
持续循环。如果使用S代表首次迭代时子集的样本量,C代表全部参数组合数,则在迭代过程中,用于验证参数的数据子集是越来越大的,而需要被验证的参数组合数量是越来越少的:
| 迭代次数 | 子集样本量 | 参数组合数 |
|---|---|---|
| 1 | S | C |
| 2 | 2S | \(\frac{1}{2}\)C |
| 3 | 4S | \(\frac{1}{4}\)C |
| 4 | 8S | \(\frac{1}{8}\)C |
| …… |
当备选参数组合只剩下一组,或剩余可用的数据不足,循环就会停下,具体地来说,当\(\frac{1}{n}\)C <= 1或者nS > 总体样本量,搜索就会停止。在实际应用时,哪一种停止条件会先被触发,需要看实际样本量及参数空间地大小。同时,每次迭代时增加的样本量、以及每次迭代时不断减少的参数组合都是可以自由设定的。
在这种模式下,只有在不同的子集上不断获得优秀结果的参数组合能够被留存到迭代的后期,最终选择出的参数组合一定是在所有子集上都表现优秀的参数组合。这样一个参数组合在全数据上表现优异的可能性是非常大的,同时也可能展现出比网格/随机搜索得出的参数更大的泛化能力。
3. 2 对半网格搜索的局限性
然而这个过程当中会存在一个问题:子集越大时,子集与全数据集D的分布会越相似,但整个对半搜索算法在开头的时候,就用最小的子集筛掉了最多的参数组合。如果最初的子集与全数据集的分布差异巨大的化,在对半搜索开头的前几次迭代中,就可能筛掉许多对全数据集D有效的参数,因此对半网格搜索最初的子集一定不能太小。
在对半网格搜索过程中,子集的样本量时呈指数级增长:
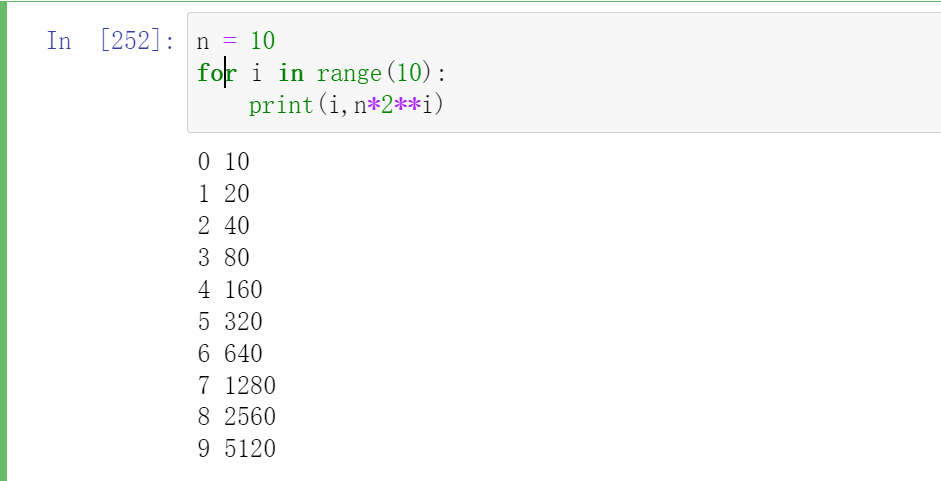
在初始子集样本量为10的前提下,7、8次迭代就会消耗掉2500+数据资源。在初始子集一定不能太小、且对半搜索的抽样是不放回抽样的大前提下,整体数据的样本量必须要很大。从经验来看,对半网格搜索在小型数据集上的表现往往不如随机网格搜索与普通网格搜索,但在大型数据集上(比如,样本量过w的数据集上),对半网格搜索展现出运算速度上的巨大优势。
因此在对半网格搜索实现时,我们使用一组拓展的房价数据集,有2w9条样本。
data2 = pd.read_csv(r"D:\Pythonwork\2021ML\PART 2 Ensembles\datasets\House Price\big_train.csv",index_col=0)
X = data2.iloc[:,:-1]
y = data2.iloc[:,-1]
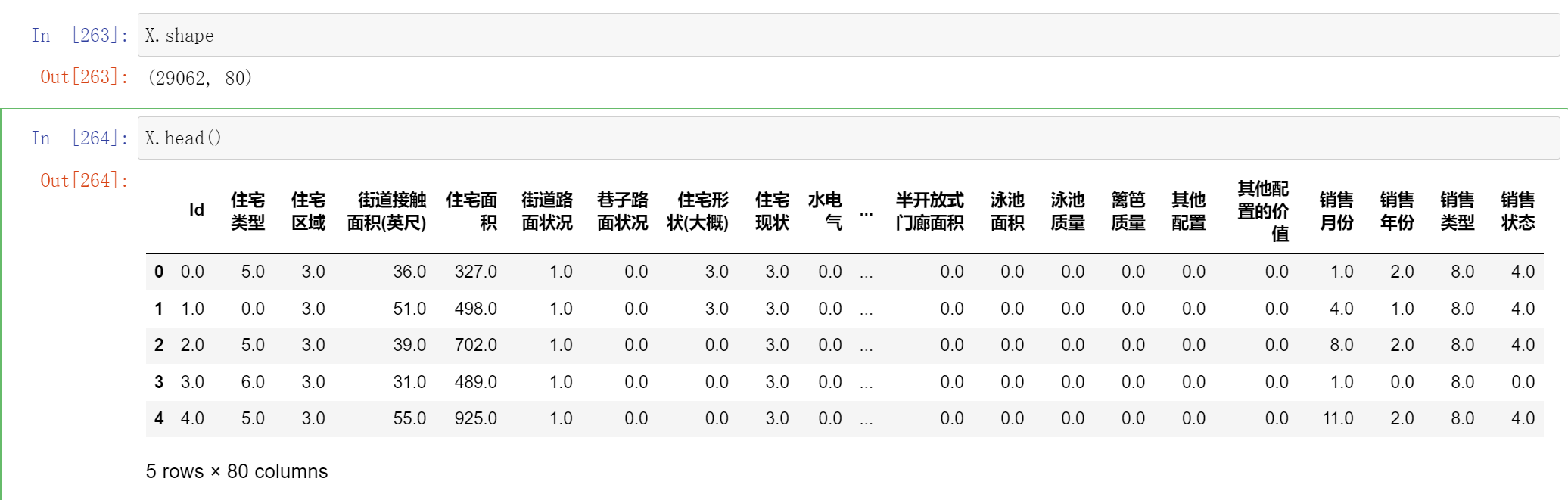
X.shape
X.head()
3.3 对半网格搜索的实现
import re
import sklearn
import numpy as np
import pandas as pd
import matplotlib as mlp
import matplotlib.pyplot as plt
import time
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.experimental import enable_halving_search_cv
from sklearn.model_selection import KFold, HalvingGridSearchCV
对半网格搜索的类如下所示:
class sklearn.model_selection.HalvingGridSearchCV(estimator, param_grid, *, factor=3, resource='n_samples', max_resources='auto', min_resources='exhaust', aggressive_elimination=False, cv=5, scoring=None, refit=True, error_score=nan, return_train_score=True, random_state=None, n_jobs=None, verbose=0)
全部参数如下所示:
| Name | Description |
|---|---|
| estimator | 调参对象,某评估器 |
| param_grid | 参数空间,可以是字典或者字典构成的列表 |
| factor | 每轮迭代中新增的样本量的比例,同时也是每轮迭代后留下的参数组合的比例 |
| resource | 设置每轮迭代中增加的验证资源的类型 |
| max_resources | 在一次迭代中,允许被用来验证任意参数组合的最大样本量 |
| min_resources | 首次迭代时,用于验证参数组合的样本量r0 |
| aggressive_elimination | 是否以全部数被使用完成作为停止搜索的指标,如果不是,则采取措施 |
| cv | 交叉验证的折数 |
| scoring | 评估指标,支持同时输出多个参数 |
| refit | 挑选评估指标和最佳参数,在完整数据集上进行训练 |
| error_score | 当网格搜索报错时返回结果,选择'raise'时将直接报错并中断训练过程 其他情况会显示警告信息后继续完成训练 |
| return_train_score | 在交叉验证中是否显示训练集中参数得分 |
| random_state | 控制随机抽样数据集的随机性 |
| n_jobs | 设置工作时参与计算的线程数 |
| verbose | 输出工作日志形式 |
- factor
每轮迭代中新增的样本量的比例,同时也是每轮迭代后留下的参数组合的比例。例如,当factor=2时,下一轮迭代的样本量会是上一轮的2倍,每次迭代后有1/2的参数组合被留下。如果factor=3时,下一轮迭代的样本量会是上一轮的3倍,每次迭代后有1/3的参数组合被留下。该参数通常取3时效果比较好。
- resource
设置每轮迭代中增加的验证资源的类型,输入为字符串。默认是样本量,输入为"n_samples",也可以是任意集成算法当中输入正整数的弱分类器,例如"n_estimators"或者"n_iteration"。
- min_resource
首次迭代时,用于验证参数组合的样本量r0。可以输入正整数,或两种字符串"smallest","exhaust"。
输入正整数n,表示首次迭代时使用n个样本。
输入"smallest",则根据规则计算r0:
当资源类型是样本量时,对回归类算法,r0 = 交叉验证折数n_splits * 2
当资源类型是样本量时,对分类算法,r0 = 类别数量n_classes_ * 交叉验证折数n_splits * 2
当资源类型不是样本量时,等于1
输入"exhaust",则根据迭代最后一轮的最大可用资源倒退r0。例如,factor=2, 样本量为1000时,一共迭代3次时,则最后一轮迭代的最大可用资源为1000,倒数第二轮为500,倒数第三轮(第一轮)为250。此时r0 = 250。"exhaust"模式下最有可能得到好的结果,不过计算量会略大,计算时间会略长。
现在,我们依然使用原来的参数空间:
param_grid_simple = {'n_estimators': [*range(5,100,5)]
, 'max_depth': [*range(25,36,2)]
, "max_features": ["log2","sqrt",16,32,64,"auto"]
}
#计算全域参数空间大小
len([*range(5,100,5)]) * len([*range(25,36,2)]) * 6
684
#建立回归器、交叉验证
reg = RFR(random_state=1412,verbose=True,n_jobs=12)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
#定义随机搜索
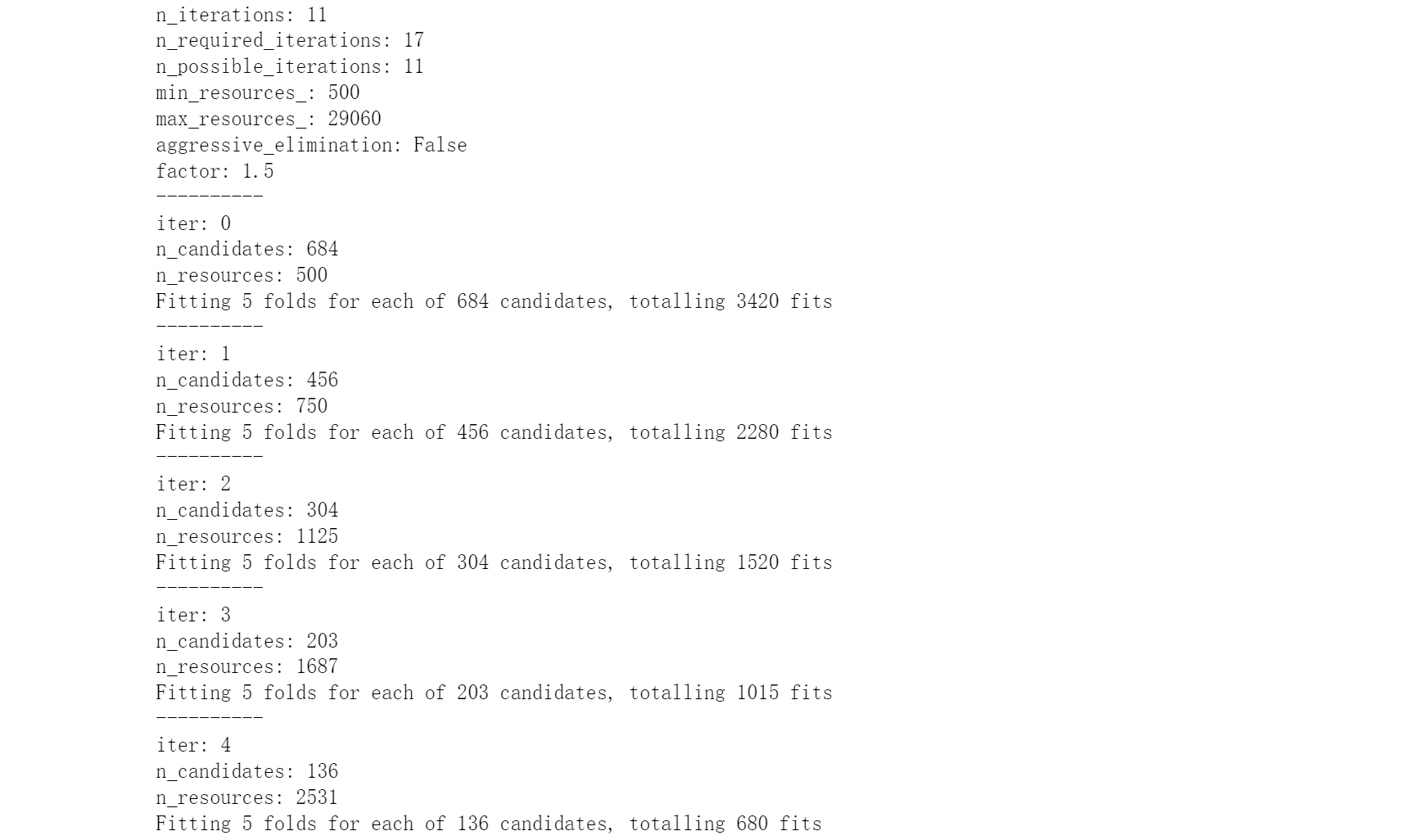
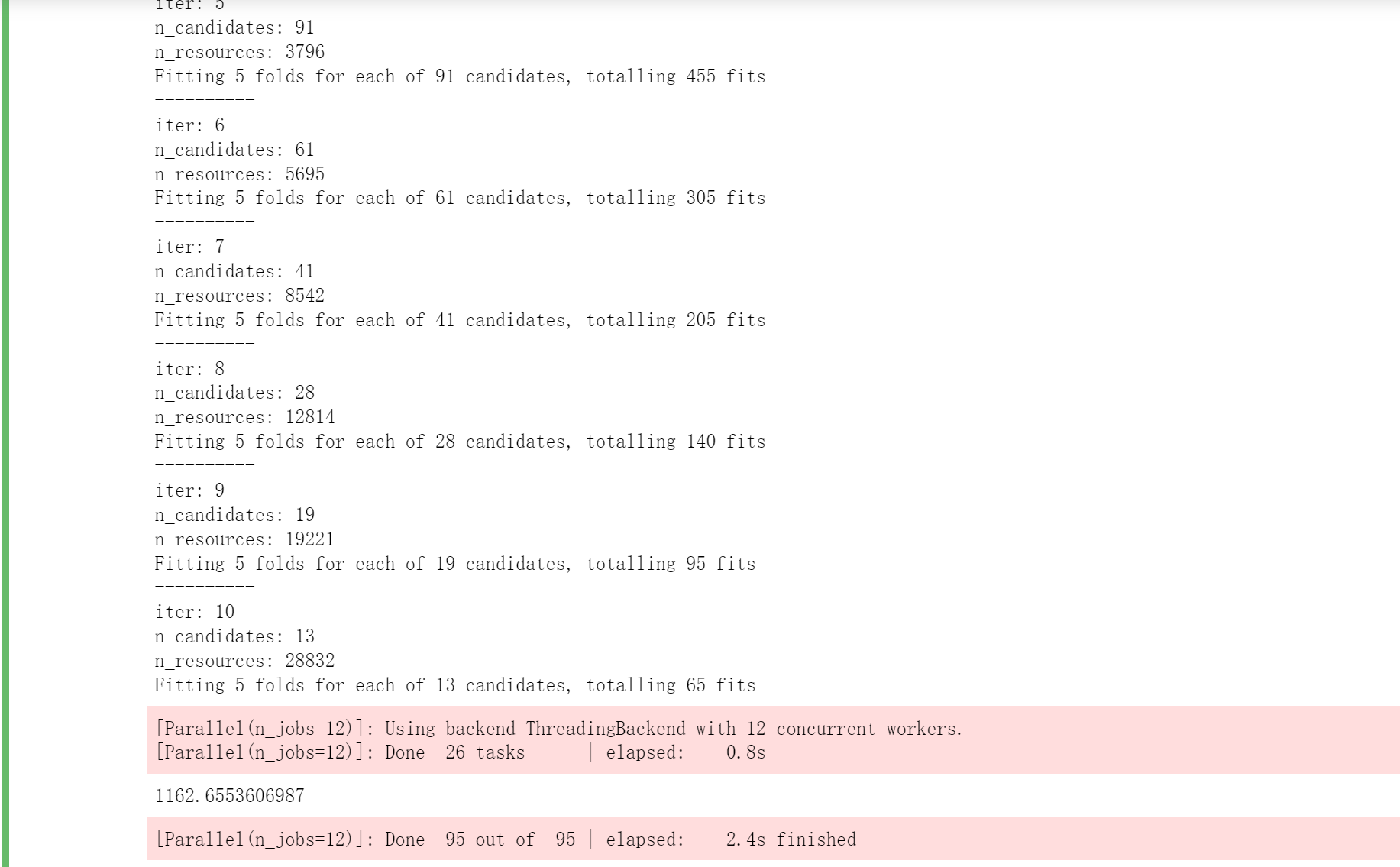
search = HalvingGridSearchCV(estimator=reg
,param_grid=param_grid_simple
,factor=1.5
,min_resources=500
,scoring = "neg_mean_squared_error"
,verbose = True
,random_state=1412
,cv = cv
,n_jobs=12)
#训练随机搜索评估器
#=====【TIME WARNING: 5~10min】=====#
start = time.time()
search.fit(X,y)
print(time.time() - start)
#查看最佳评估器
search.best_estimator_
""
RandomForestRegressor(max_depth=27, max_features=32, n_estimators=95, n_jobs=12,random_state=1412, verbose=True)
""
#查看最佳评估器
abs(search.best_score_)**0.5
750.4062902073151
以随机网格搜索作为对比,我们来看看随机网格搜索的结果:
param_grid_simple = {'n_estimators': [*range(5,100,5)]
, 'max_depth': [*range(25,36,2)]
, "max_features": ["log2","sqrt",16,32,64,"auto"]
}
reg = RFR(random_state=1412,verbose=True,n_jobs=12)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
#定义随机搜索
search = RandomizedSearchCV(estimator=reg
,param_distributions=param_grid_simple
,n_iter = 360 #还是使用360这个搜索次数
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv
,n_jobs=12)
#训练随机搜索评估器
#=====【TIME WARNING: 5~10min】=====#
start = time.time()
search.fit(X,y)
print(time.time() - start)
#查看最佳评估器
search.best_estimator_
"""
RandomForestRegressor(max_depth=31, max_features=16, n_estimators=95, n_jobs=12,random_state=1412, verbose=True)
"""
#查看最终评估指标
abs(search.best_score_)**0.5
| HPO方法 | 随机搜索 | Halving搜索 |
|---|---|---|
| 搜索空间/全域空间 | 360/684 | 684/684 |
| 搜索时间 | 25.3mins | 19mins |
| 最优分数(RMSE) | 751.988 | 750.406 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号