5.2 随机森林在巨量数据中的增量学习
集成学习是工业领域中应用最广泛的机器学习算法。实际工业环境下的数据量往往十分巨大,一个训练好的集成算法的复杂程度与训练数据量高度相关,因此企业在应用机器学习时通常会提供强大的计算资源作为支持,也因此当代的大部分集成算法都是支持GPU运算的(相对的,如果你发现一个算法在任何机器学习库中,都没有接入GPU运算的选项,这可能说明该算法在工业应用中基本不会被使用)。
sklearn作为早期开源的机器学习算法库,难以预料到如今人工智能技术走进千家万户的应用状况,因此并未开放接入GPU进行运算的接口,即sklearn中的所有算法都不支持接入更多计算资源。因此当我们想要使用随机森林在巨量数据上进行运算时,很可能会遭遇计算资源短缺的情况。幸运的是,我们有两种方式解决这个问题:
- 使用其他可以接入GPU的机器学习算法库实现随机森林,比如xgboost。
- 继续使用sklearn进行训练,但使用增量学习(incremental learning)。
增量学习是机器学习中非常常见的方法,在有监督和无监督学习当中都普遍存在。增量学习允许算法不断接入新数据来拓展当前的模型,即允许巨量数据被分成若干个子集,分别输入模型进行训练。
1 普通学习 vs 增量学习
- 普通学习
通常来说,当一个模型经过一次训练之后,如果再使用新数据对模型进行训练,原始数据训练出的模型会被替代掉,它不会记得它之前的模型。举个例子,我们原本的数据集X与y是kaggle房价数据集,结构为:

现在,我们导入sklearn中非常常用的另一个数据集,加利福尼亚房价数据集:
from sklearn.datasets import fetch_california_housing
from sklearn.metrics import mean_squared_error
X_fc = fetch_california_housing().data
y_fc = fetch_california_housing().target
X_fc.shape #可以看到,加利福尼亚房价数据集的特征量为8
#建模
model = RFR(n_estimators=3, warm_start=False) #不支持增量学习的
model1 = model.fit(X_fc,y_fc)
#RMSE
(mean_squared_error(y_fc,model1.predict(X_fc)))**0.5
#使用.estimators_查看森林中所有树的情况,可以看到每一棵树的随机数种子
model1.estimators_

然后此时我们让model1继续在Kaggle房价数据集X,y上进行训练。
model1 = model1.fit(X.iloc[:,:8],y)
#注意,X有80个特征,X_fc只有8个特征,输入同一个模型的数据必须结构一致
model1.estimators_ #你发现了吗?model1中原始的树消失了,新的树替代了原始的树
再让model1对加利福尼亚房价数据集进行训练,会发生什么呢?别忘了model1之前训练过加利福尼亚房价数据集:
#RMSE
(mean_squared_error(y_fc,model1.predict(X_fc)))**0.5
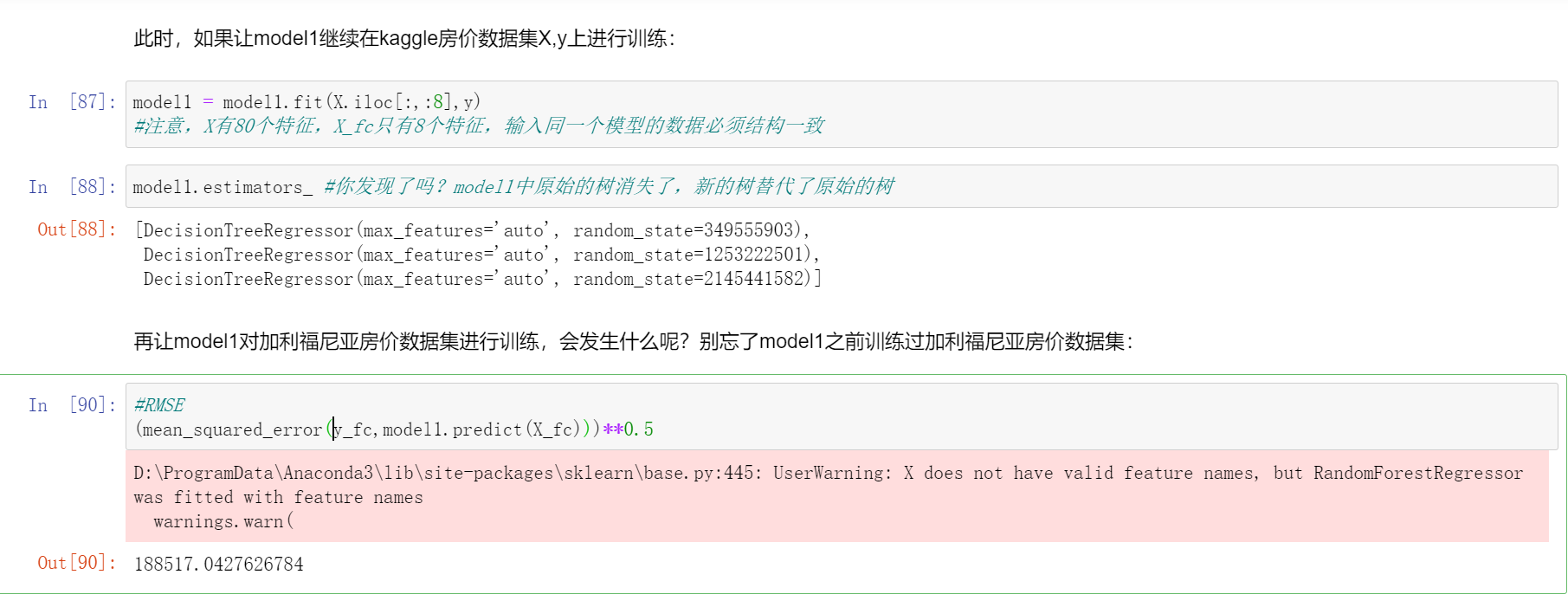
RMSE异常巨大,模型现在已经不具备任何预测y_fc的能力了。非常明显,model1中原始的树消失了,基于kaggle数据集训练的树覆盖了原始的树,因此model1不再对本来见过的加利福尼亚房价数据报有记忆。
sklearn的这一覆盖规则是交叉验证可以进行的基础,正因为每次训练都不会受到上次训练的影响,我们才可以使用模型进行交叉验证,否则就会存在数据泄露的情况。但在增量学习中,原始数据训练的树不会被替代掉,模型会一致记得之前训练过的数据,我们来看看详细情况:
- 增量学习
我们还是可以使用X,y以及X_fc,y_fc作为例子,这一次,我们让warm_start参数取值为True,允许随机森林进行增量学习:
model = RFR(n_estimators=3, warm_start=True) #支持增量学习
model2 = model.fit(X_fc,y_fc) #训练
(mean_squared_error(y_fc,model2.predict(X_fc)))**0.5
model2.estimators_

然后我们在导入加利福尼亚州的房价预测:
#这里我们的变量的数量只能和前面fit的一个一样
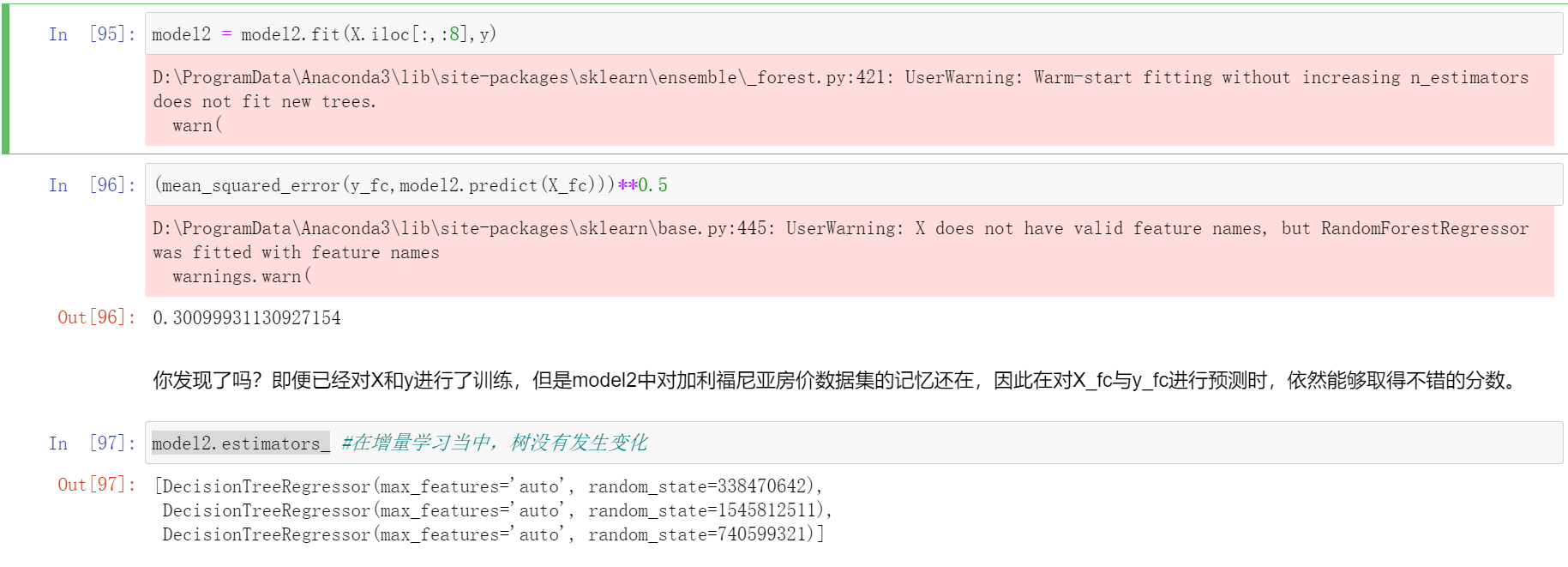
model2 = model2.fit(X.iloc[:,:8],y)
(mean_squared_error(y_fc,model2.predict(X_fc)))**0.5
model2.estimators_
你发现了吗?即便已经对X和y进行了训练,但是model2中对加利福尼亚房价数据集的记忆还在,因此在对X_fc与y_fc进行预测时,依然能够取得不错的分数。
所以在增量学习当中,已经训练过的结果会被保留。对于随机森林这样的Bagging模型来说,这意味着之前的数据训练出的树会被保留,新数据会训练出新的树,新旧树互不影响。对于逻辑回归、神经网络这样不断迭代以求解权重\(w\)的算法来说,新数据训练时w的起点是之前的数据训练完毕之后的w。
不过,这里存在一个问题:虽然原来的树没有变化,但增量学习看起来并没有增加新的树——事实上,对于随机森林而言,我们需要手动增加新的树:
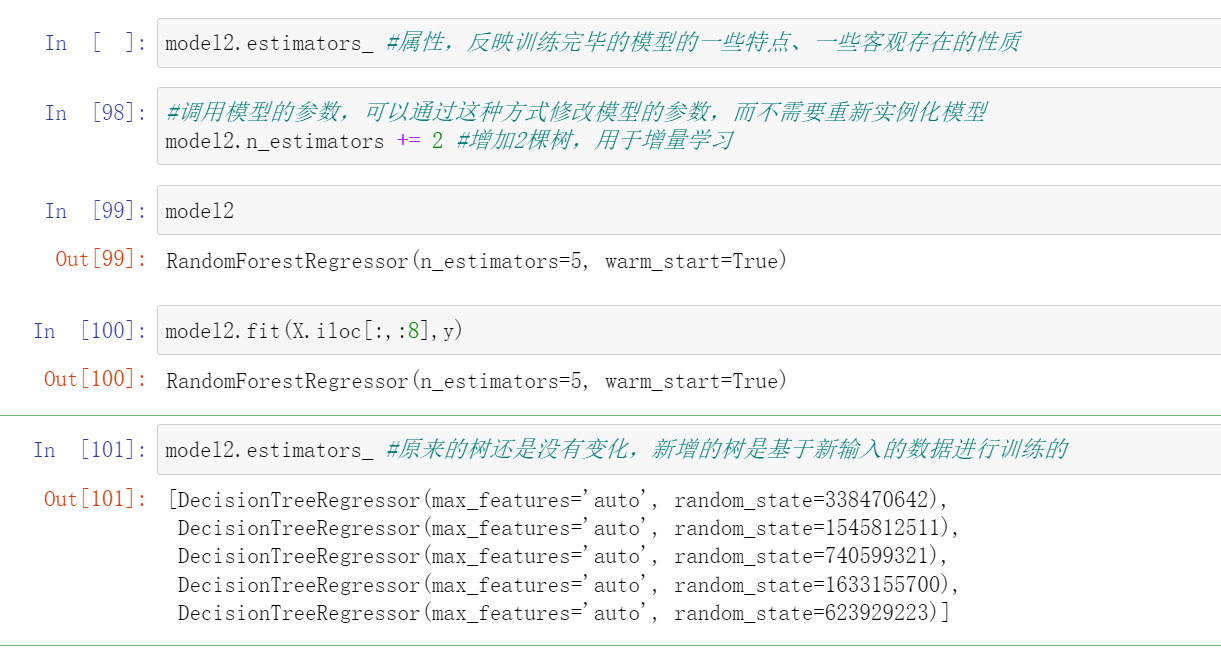
#调用模型的参数,可以通过这种方式修改模型的参数,而不需要重新实例化模型
model2.n_estimators += 2 #增加2棵树,用于增量学习
#这里不要混了,就是model2.estimators_ #属性,反映训练完毕的模型的一些特点、一些客观存在的性质,一般属性都会有个下划线
model2
model2.fit(X.iloc[:,:8],y)
model2.estimators_ #原来的树还是没有变化,新增的树是基于新输入的数据进行训练的
对于一个大文件怎么判断他有多少行
1.定义训练和测试集的地址
trainpath=r"../集成学习公开课数据集/Big data/bigdata_train.csv"
testpath=r"../集成学习公开课数据集/Big data/bigdata_test.csv"
2.设法找到csv中总数据量
当我们决定使用增量学习时,数据应该是巨大到不可能直接打开查看、不可能直接训练、甚至不可能直接导入的(比如,超过20个G)。但如果我们需要对数据进行循环导入,就必须知道真实的数据量大概有多少,因此我们可以从以下途径获得无法打开的csv中的数据量:
- 如果是比赛数据集,一般可以在比赛页面找到相应的说明
- 如果是数据库数据集,则可以在数据库中进行统计
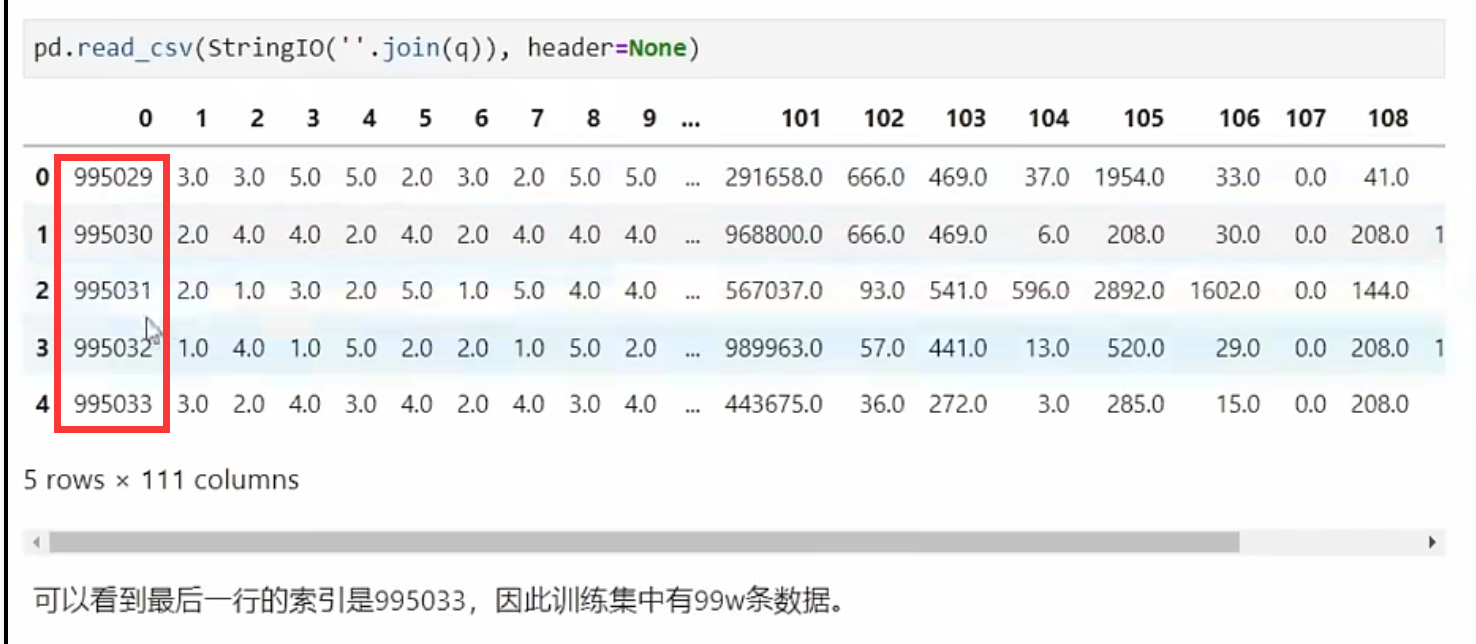
- 如果无法找到相应的说明,可以使用deque库导入csv文件的最后几行,查看索引
- 如果数据没有索引,就只能够靠pandas尝试找出大致的数据范围了
from collections import deque
from io import StringIO
with open(trainpath,'r') as data:
q=deque(data,5)
q
pd.read_csv(StringIO(''.join(q)),head=None)
2.如果数据没有索引,则使用pandas中的skiprows与nrows进行尝试:
skiprows:本次导入跳过前skiprows行
nrows:本次导入只导入nrows行
例如,当skiprows=1000,nrows=1000时,pandas会导入1001-2000行
当skiprows超出数据量的时候,就会报空值错误EmptyDataError。
for i in range(0,10**7,100000):
df=pd.read_csv(trainpath,skiprow=10,nrows=1)
print(i)
这里我们并不是真正的导入,只是想导入看看哪一行报错,从而找出哪一个点
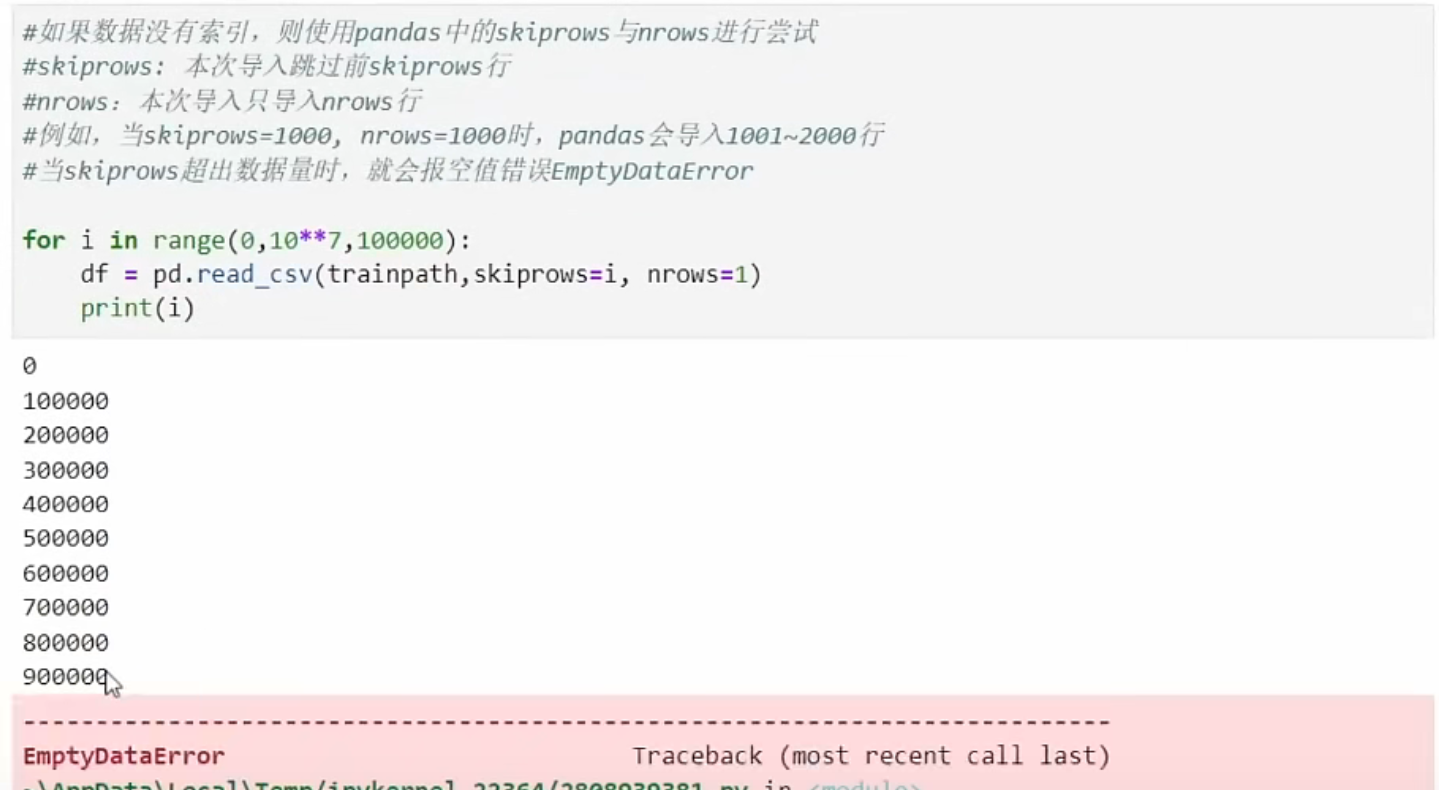
可以看到90w顺利导入了,但是100w报错了,所以数据量在90-100w之间。如果我们想,我们可以继续精确数据量的具体范围,但通常来说我们只要确认10w以内的区域就可以了。
1.定义模型:
reg=RFR(n_estimators=10,random_state=1412
,warm_start=True#增量学习的过程很漫长,你可以选择展示学习过程
,verbose=True#调用你的全部的资源进行训练
,n_jobs=8)
2.定义测试集,因为我们的训练集需要循环导入,进行训练
#定义测试集
test=pd.read_csv(testpath,header="infer",index_col=0)
Xtest=test.iloc[:,:-1]
Ytest=test.iloc[:,-1]
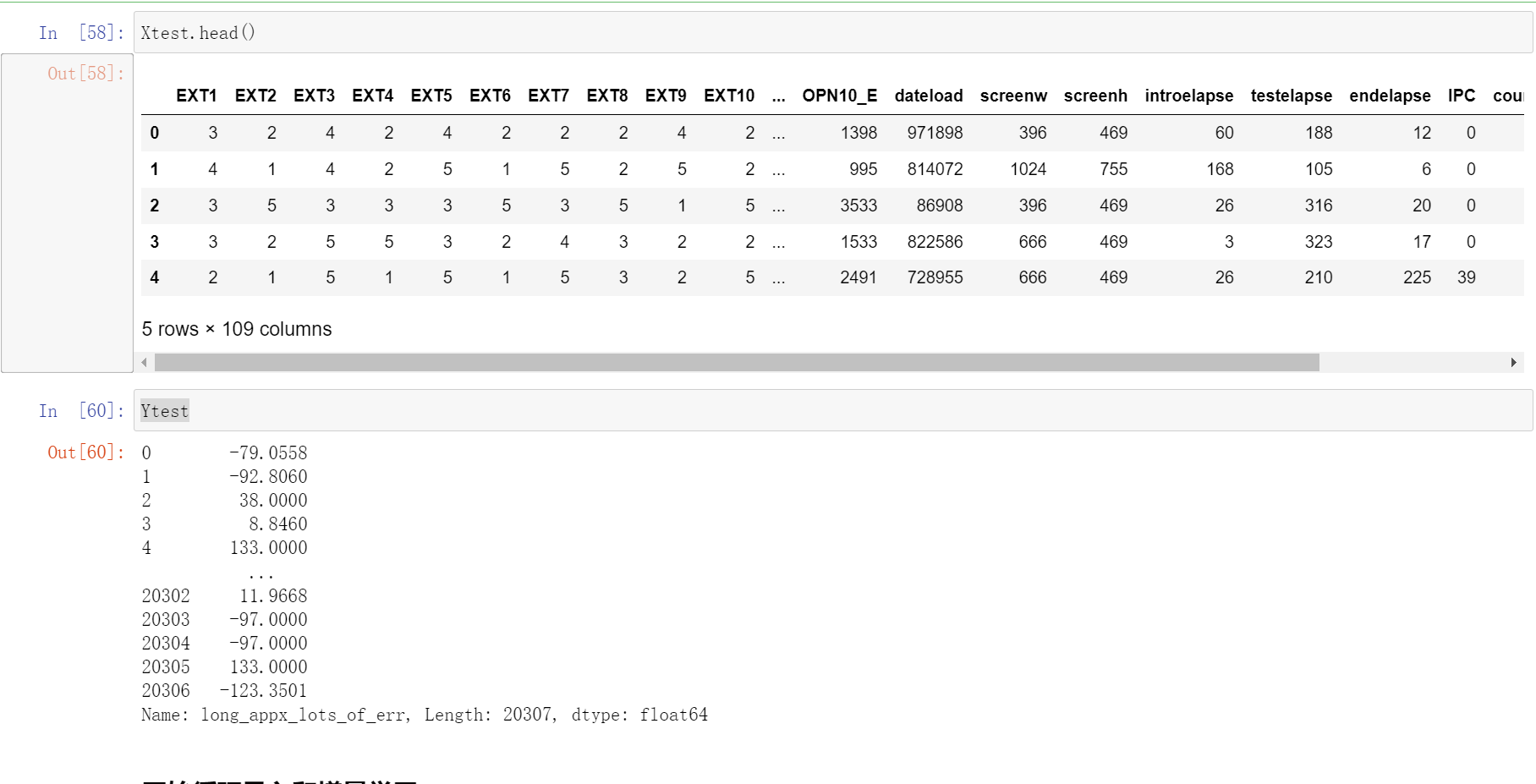
Xtest.head()
Ytest
开始循环导入和增量学习
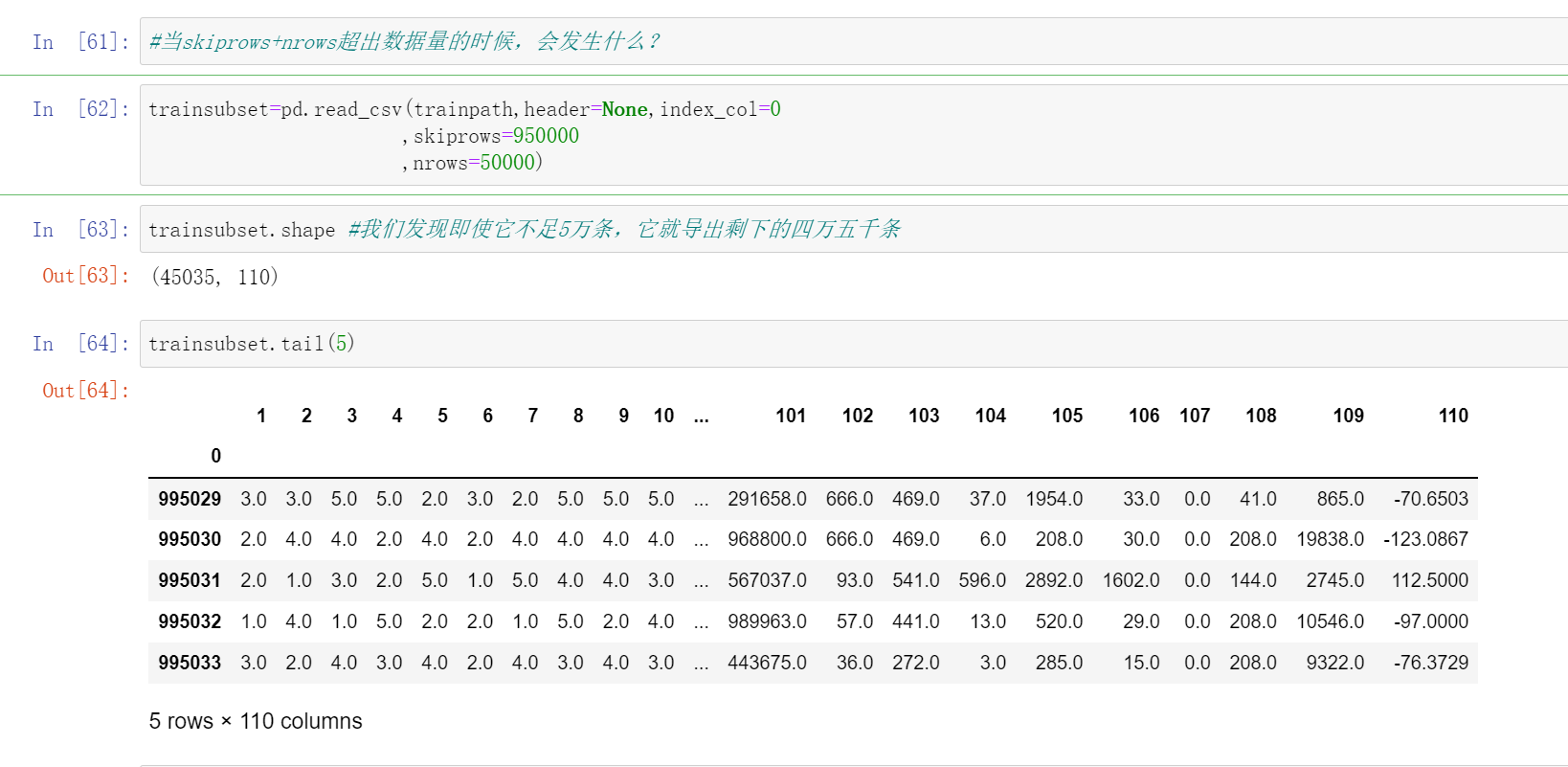
这里我们需要思考一件事情就是如果skiprows+nrows超出了数据量的时候会发生什么?
trainsubset=pd.read_csv(trainpath,header=None,index_col=0
,skiprows=950000
,nrows=50000)
trainsubset.shape #我们发现即使它不足5万条,它就导出剩下的四万五千条
trainsubset.tail(5)
这里我们可以得到如果不足5万条的话,他就会导出剩下的四万五千条
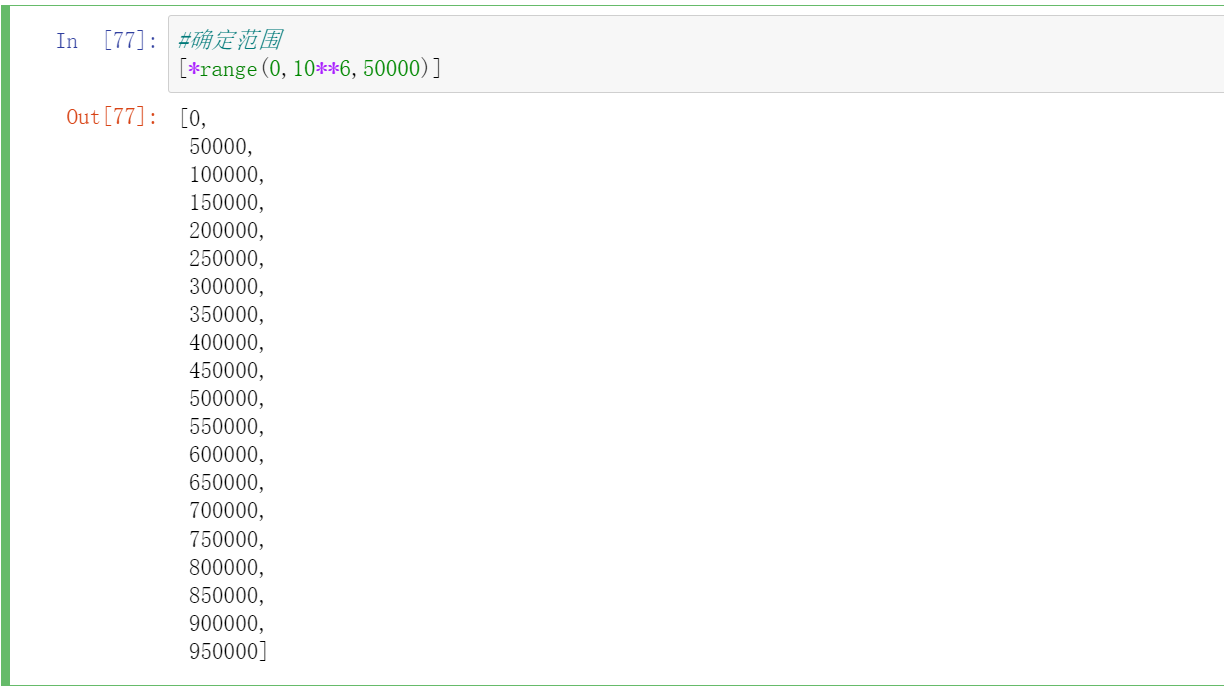
#确定范围
[*range(0,10**6,50000)]
大概九万五千条数据
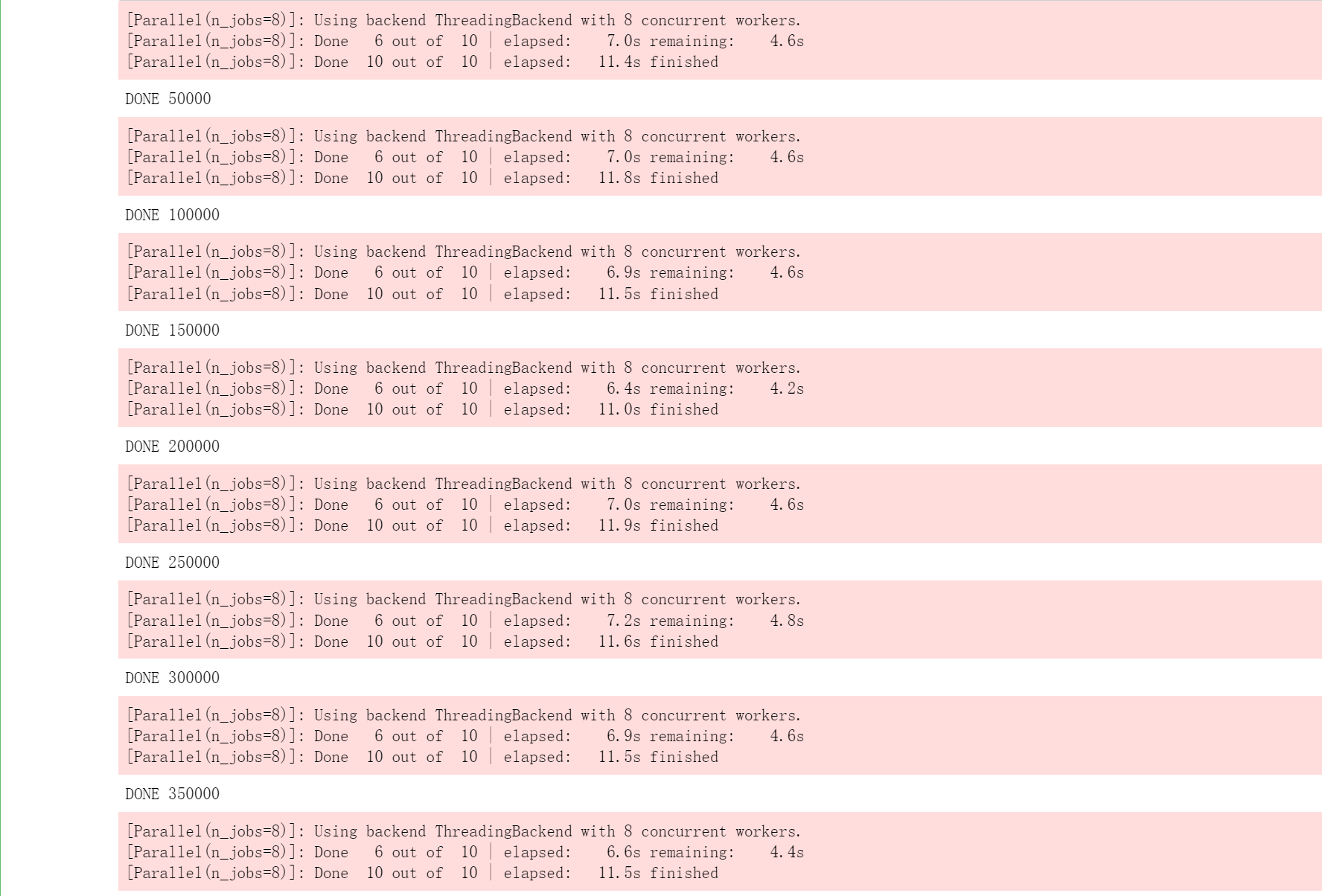
looprange=range(0,10**6,50000)
for line in looprange:
if line == 0:
#首次读取时,保留列名,并且不增加树的数量
header="infer"
newtree=0
else:
header=None
newtree=10
trainsubset=pd.read_csv(trainpath,header=header,index_col=0,skiprows=
line,nrows=50000)
Xtrain=trainsubset.iloc[:,:-1]
Ytrain=trainsubset.iloc[:,-1]
reg.n_estimators+=newtree
reg=reg.fit(Xtrain,Ytrain)
print("DONE",line+50000)
#当数据集的数据量小与50000时,打断循环
if Xtrain.shape[0]<50000:
break

在测试集上测试:
reg.score(Xtest,Ytest) #可能与测试集上的数据太少有关

当使用增量学习时,如果需要调参,我们则需要将增量学习循环打包成一个评估器或函数,以便在调参过程中不断调用,这个过程所需的计算量是异常大的,不过至少我们拥有了在CPU上训练巨大数据的方法。在后续的课程当中,我们将会讲解如何将随机森林或其他集成算法接入GPU进行训练,进一步提升我们可以训练的数据体量、进—步减少我们所需的训练时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号