TensorFlow11.1 循环神经网络RNN01-序列表达方法
在自然界中除了位置相关的信息(图片)以外,还用一种存在非常广泛的类型,就是时间轴上的数据,比如说序列信号,语音信号,聊天文字。就是有先后顺序。
对于下面这个:
不如说我们输入有10个句子,每个句子都有4个单词,然后我们怎么把这些句子转化为具体的数值呢。如果一个表示方法能够很好的表示这个单词的特性的话,我们后续可能会很好处理。
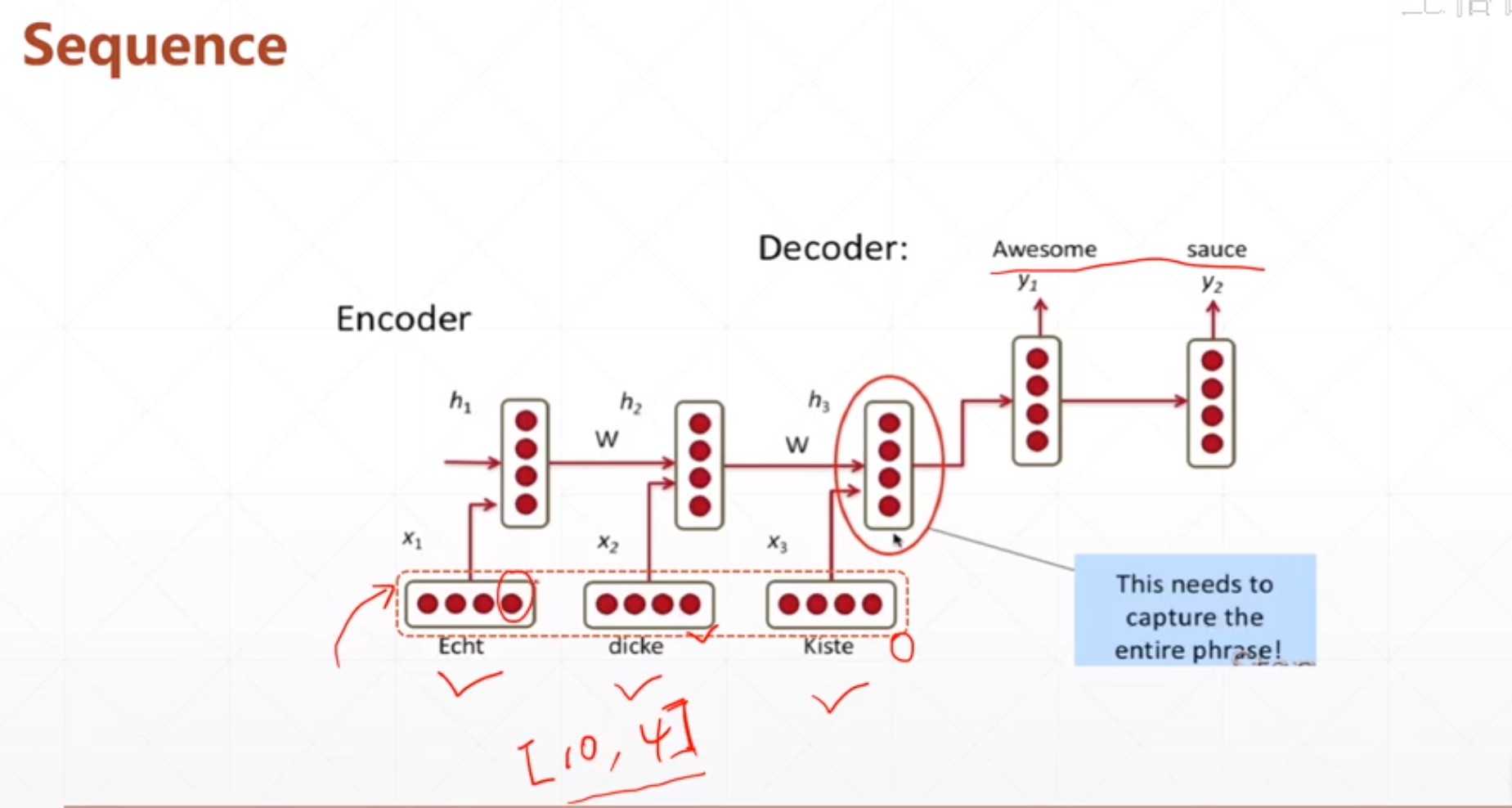
然后一个很好的方法就是embedding:

对于一个股市的表达方法:
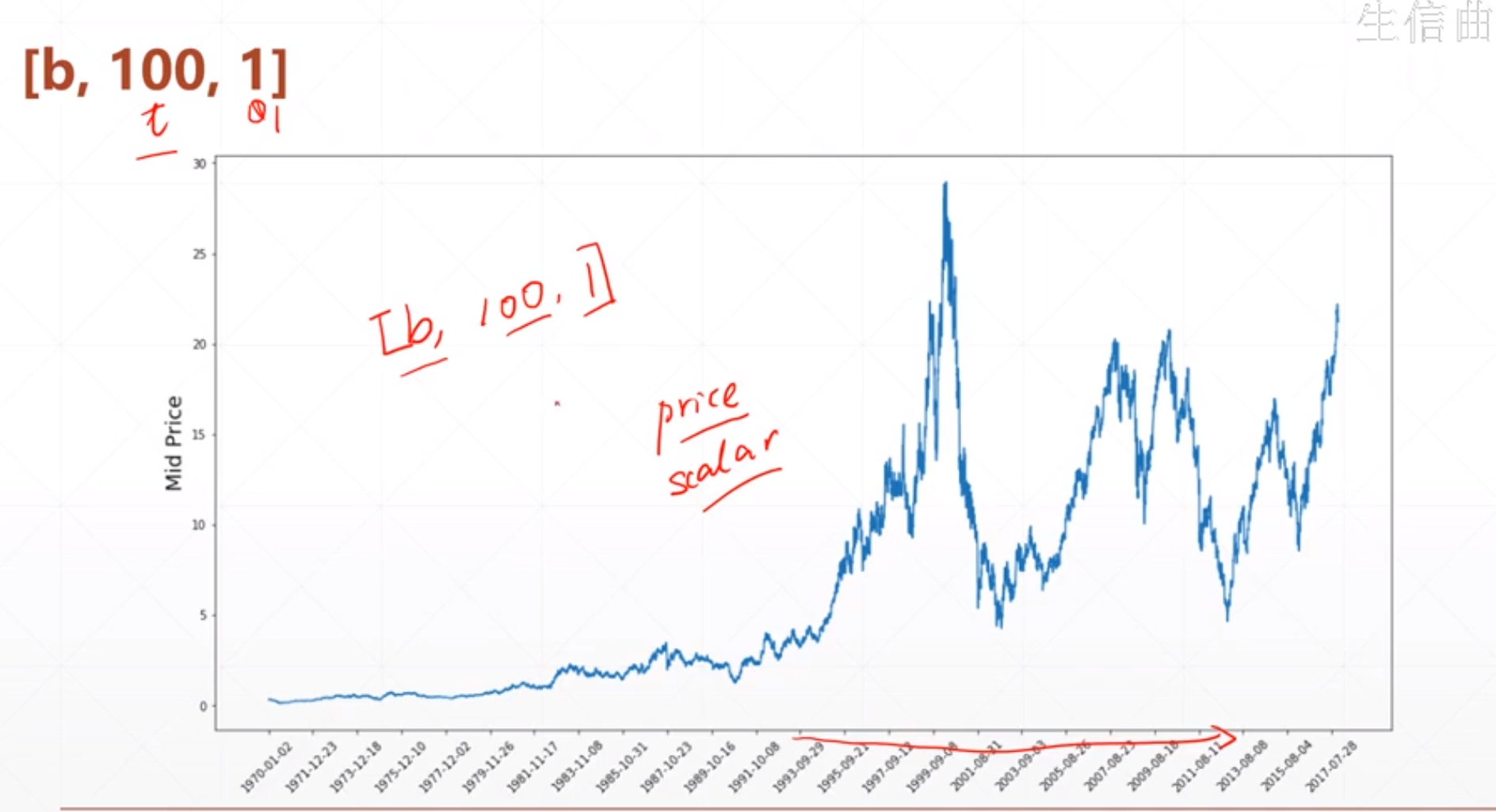
就是用一个三维的[b,100,1],这个b是有几个股市,100是时间戳。
对于一个图片我们按照Sequence的方式来理解的话:

就是我们要扫描28次,每次扫描的时候我们可以拿到一个feature。如果我们按照这个方式给循环神经网络去处理的话,也是可以的,在一些小的图片上也是取得了很好的预测结果。
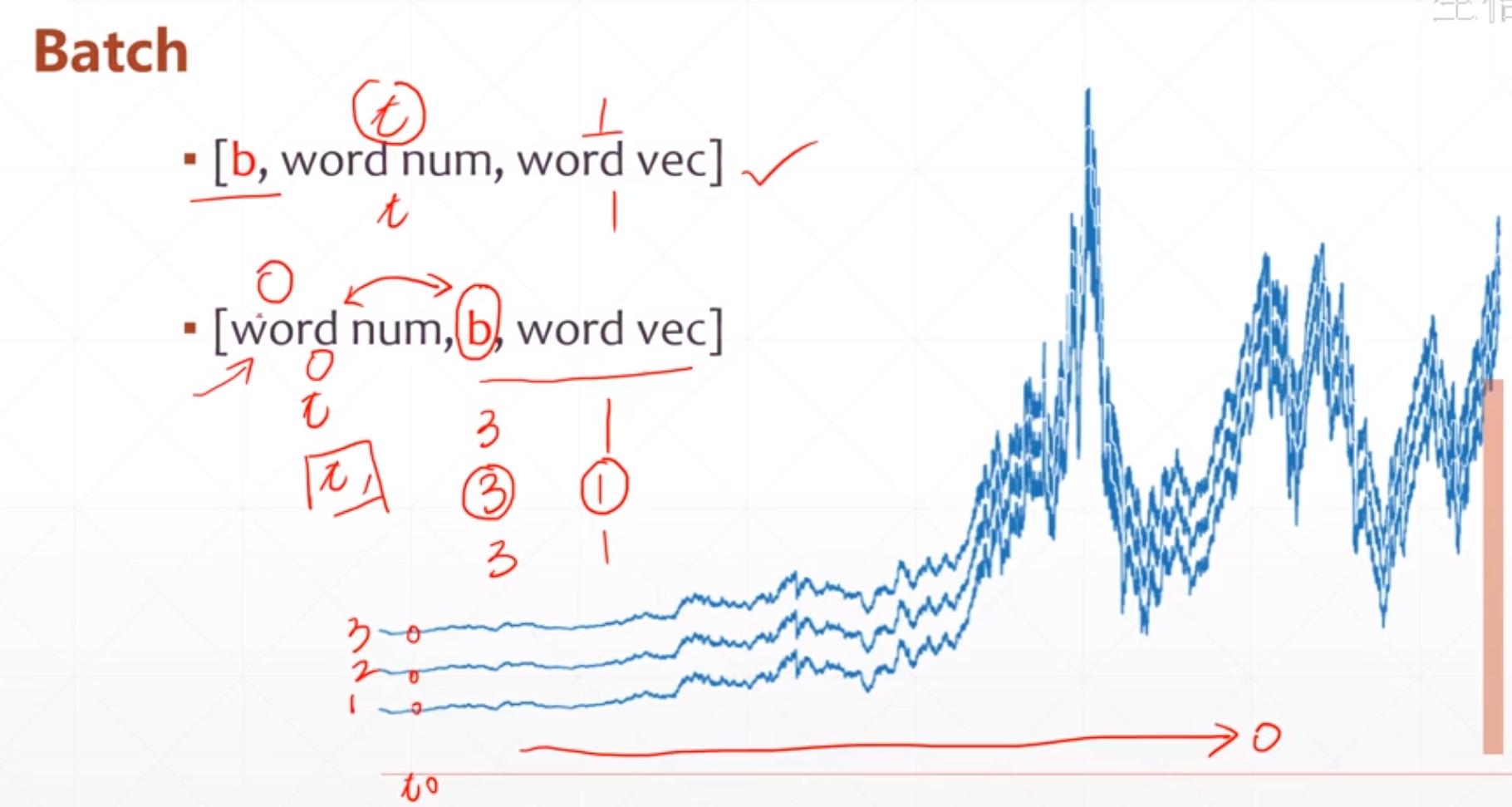
对于一个batch,我们有两种表达方式,就是
▪ [b, word num, word vec]
▪ [word num, b, word vec]
这个word num是时间戳,这个b是有几个曲线。如果我们按照第一种的表达的话,我们得按照第二维展开,如果我们按照第二种表达方式的话我们要按照第一维展开,
我们如果将一个语句转化为计算机可以识别的数字呢?
最简单的一种表达方式就是这个one-hot:

但是这个需要很大的空间,这个空间浪费的也很严重。
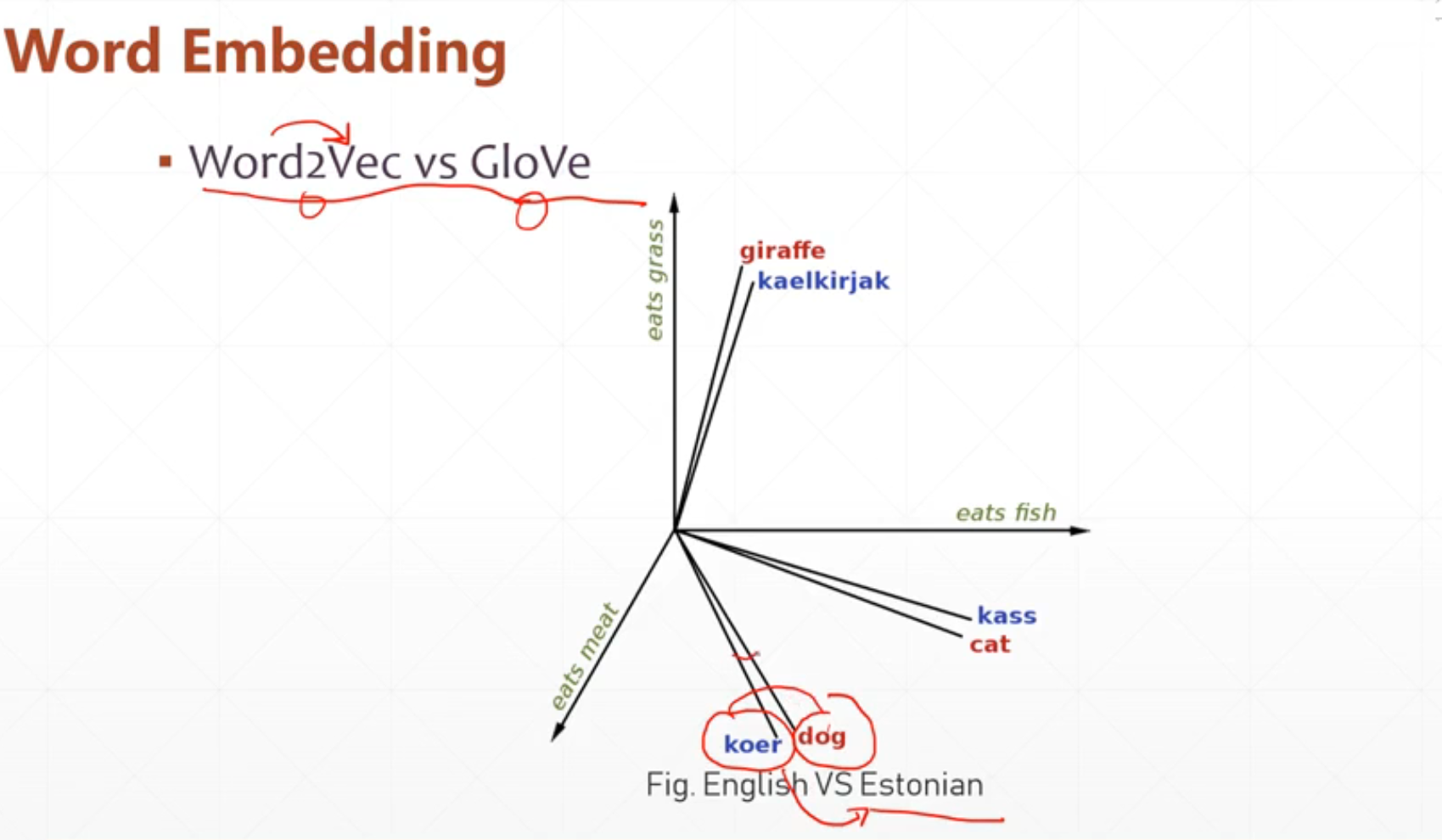
我们在表达的时候还要能表示它的semantic similarity
就是要看他的语句相似度,并且表示的这个方法可以trainable。

Word embedding方法
1.比较常用的方法(word2Vec):
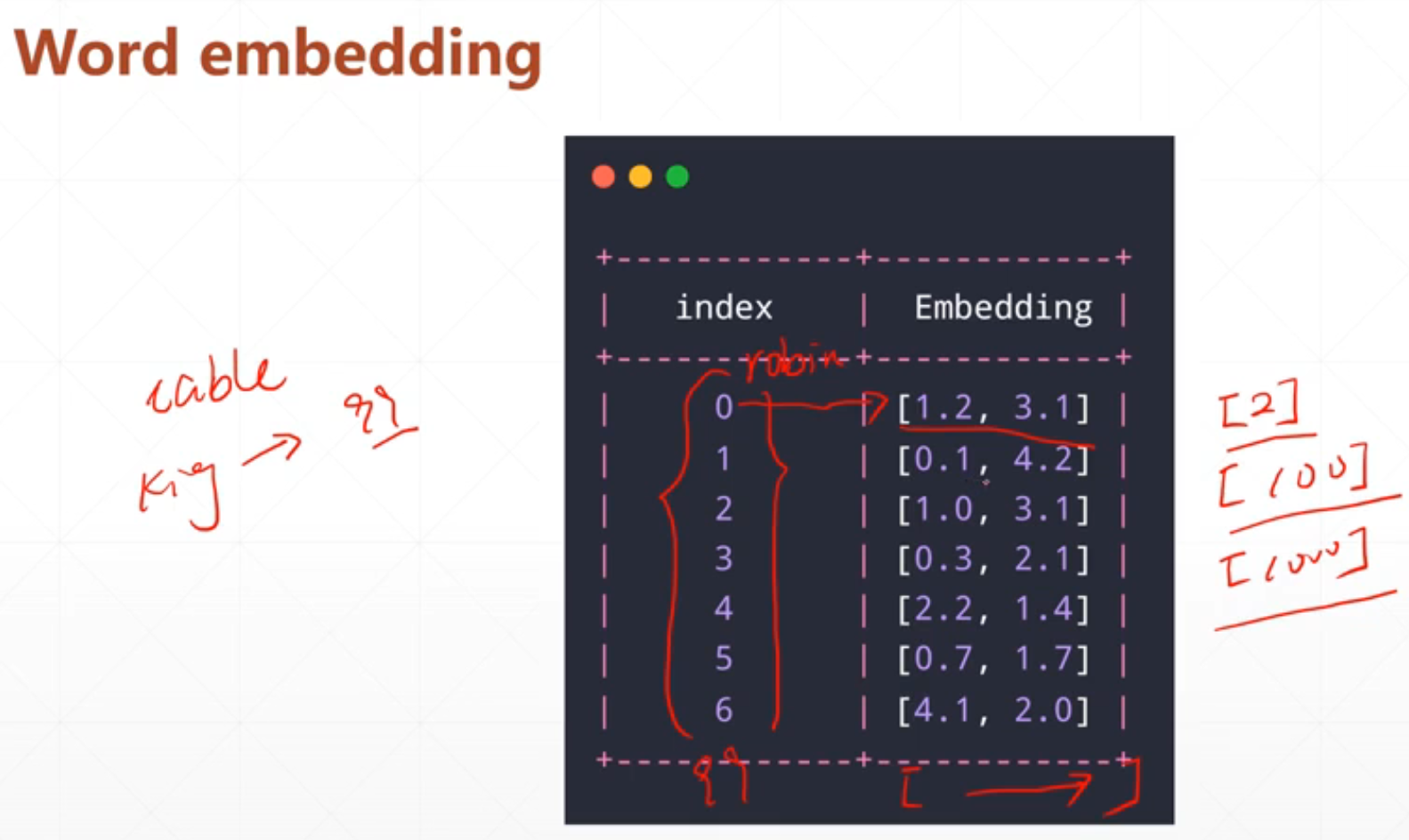
我们可以根据一个多维向量来表示这个这个单词,比如说一个二维向量来表示一个单词。这个就是把一个单词变成一个向量。
2.Embedding层
我们如果想自己写一个表示方法,不用之前的表示方法
这里有一个API:
layers.Embedding(a,b)
词汇量为a,要处理的有b个
Embedding层本质也是一个映射,不过不是映射为on-hot编码,而是映射为一个指定维度的向量,该向量是一个变量,通过学习寻找到最优值;此过程类似word2vec的原理。
其实这个embedding的作用可以看成是降维,就是用one-hot的时候维度太多了,然后用这个可以减少维度
例如:参考博客
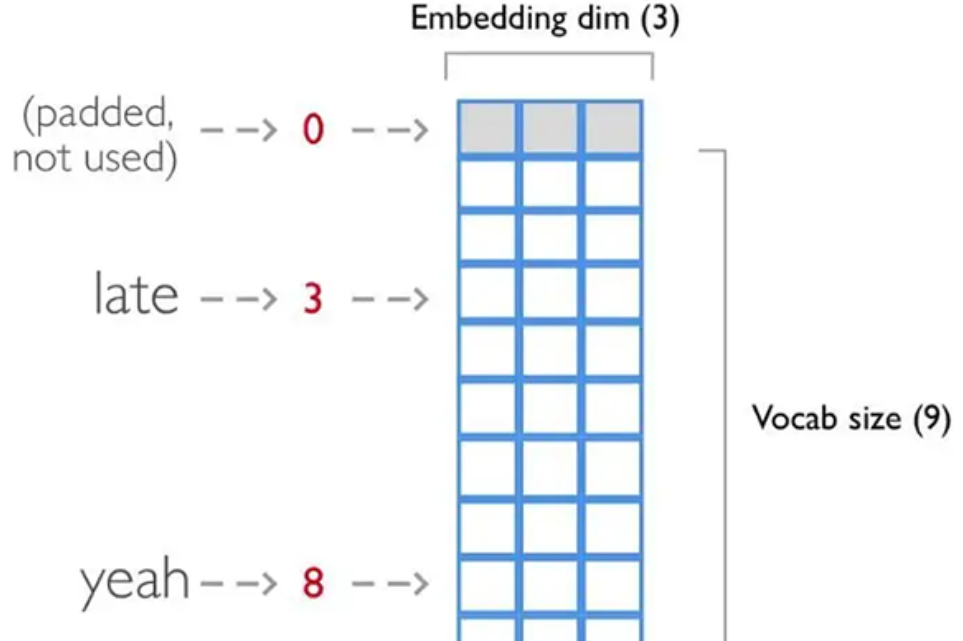
如上图所示,每一个单词对应一个标签,比如“late”对应3、“yeah”对应8,这样可以将单词序列转化成一个向量,便于数据的处理。该Embedding层的作用就是把向量中每一个标签值映射为一个3维向量,这样就可以用一个三维向量来表示一个单词。
Embedding函数实现了嵌入层的功能。参数input_dim表示词汇量的大小,比如需要处理的单词序列共有100行,每一行有50个单词,那么总共有5000个单词,假设这5000个单词中不相同的单词有2000个,那么此时输入数据的词汇量就为2000。
参数output_dim表示每一个单词映射的向量维数,如果需要用20维向量表示一个单词,那么output_dim就为20。还有一个常用的参数input_length,这个参数用来规定输入的单词序列的长度,如果单词序列长度为30个,那么这个参数的值就应该设置为30。如果没有设置参数input_length,那么输入序列的长度可以改变。
注意,Embedding层输入是一个二维张量,形状为(batch_size, input_length),输出形状为(batch_size, input_length, output_dim),是一个三维张量。
就是如何将一个句子把他变成一个数值,方便后续的神经网络的处理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号