沐神深度学习04-数据操作+数据预处理
1 常用的数据结构

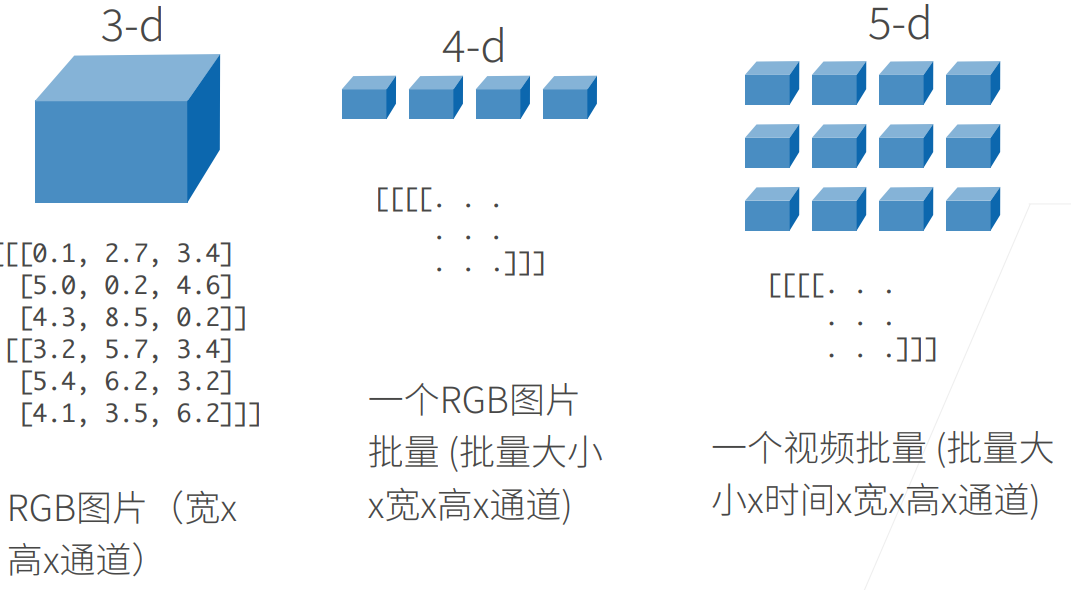
2 创建数组
创建数组需要
- 形状:例如3x4矩阵
- 每个元素的数据类型:例如32位浮点数
- 每个元素的值,例如全是0,或者随机数
3 数组的访问
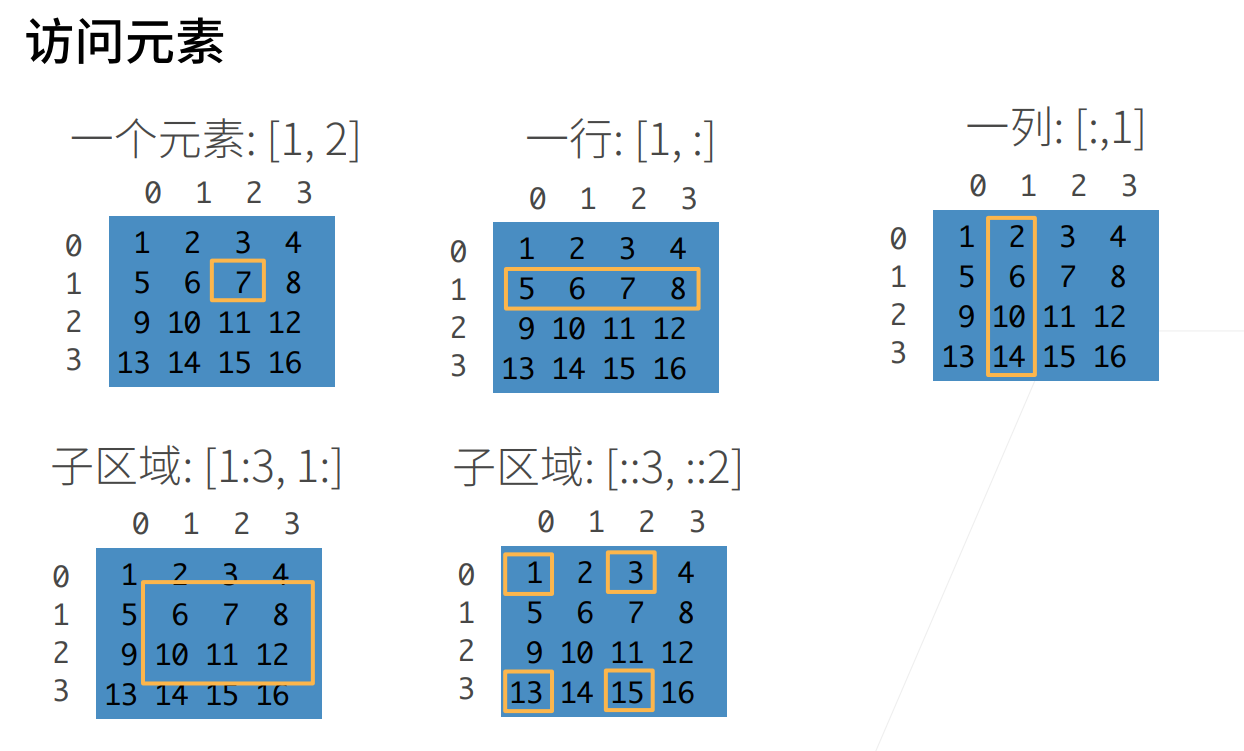
这里注意时开区间[1:3,1:],这里后面一个数是开区间
然后这里[::3,::2]这个是带跳转的子区域,就是每三列,每两行取一个元素
加载数据、缺失值处理
import pandas as pd
data = pd.read_csv(data_file)
print(data)
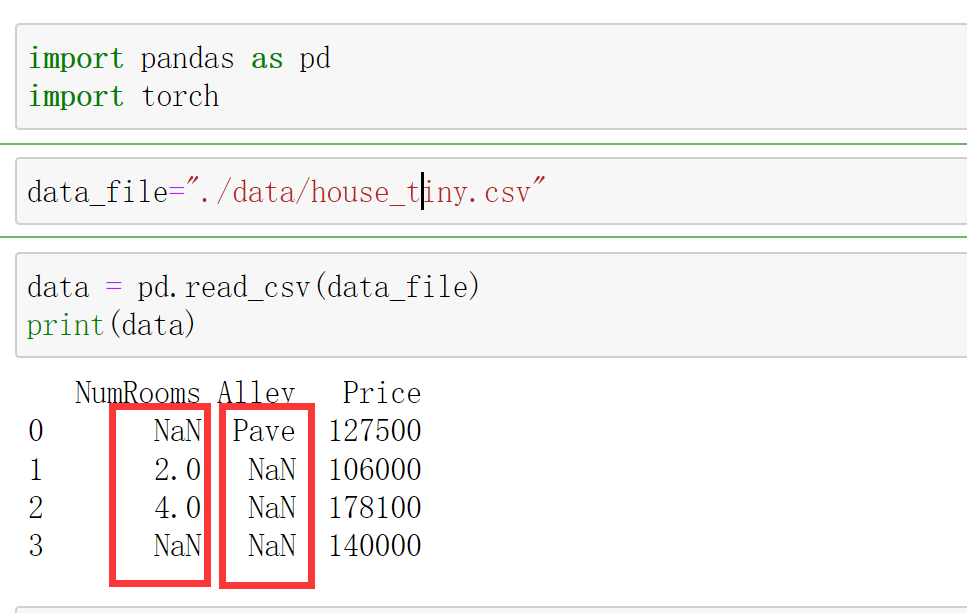
注意,“NaN”项代表缺失值。为了处理缺失的数据,典型的⽅法包括插值法和删除法。
- 其中删除法是忽略缺失值或者删除缺失值所在行
- 插值法用⼀个替代值弥补缺失值,比如说该列的均值
我们将考虑插值法。
通过位置索引iloc,我们将data分成inputs和outputs,其中前者为data的前两列,⽽后者为data的最后⼀列。
对于inputs中缺少的数值,我们⽤同⼀列的均值替换"NaN"项。
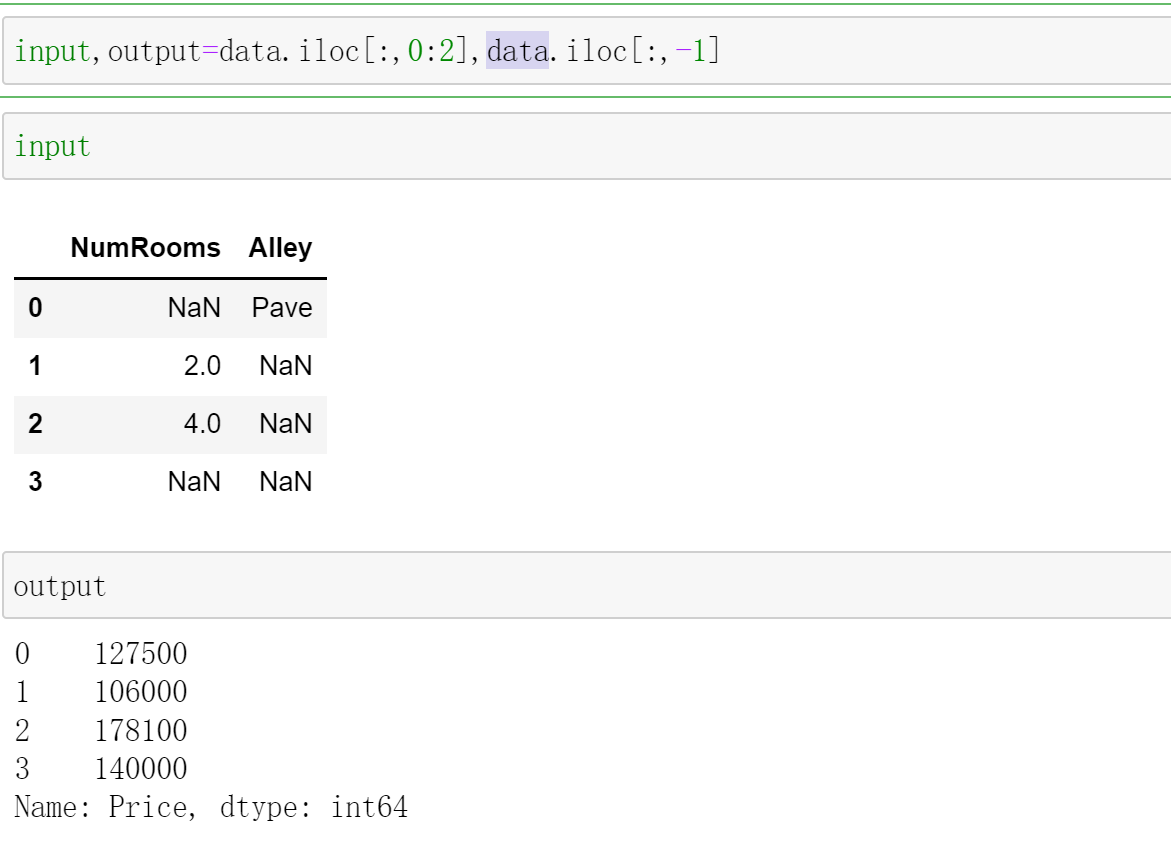
inputs["NumRooms"] = inputs["NumRooms"].fillna(inputs["NumRooms"].mean())
inputs
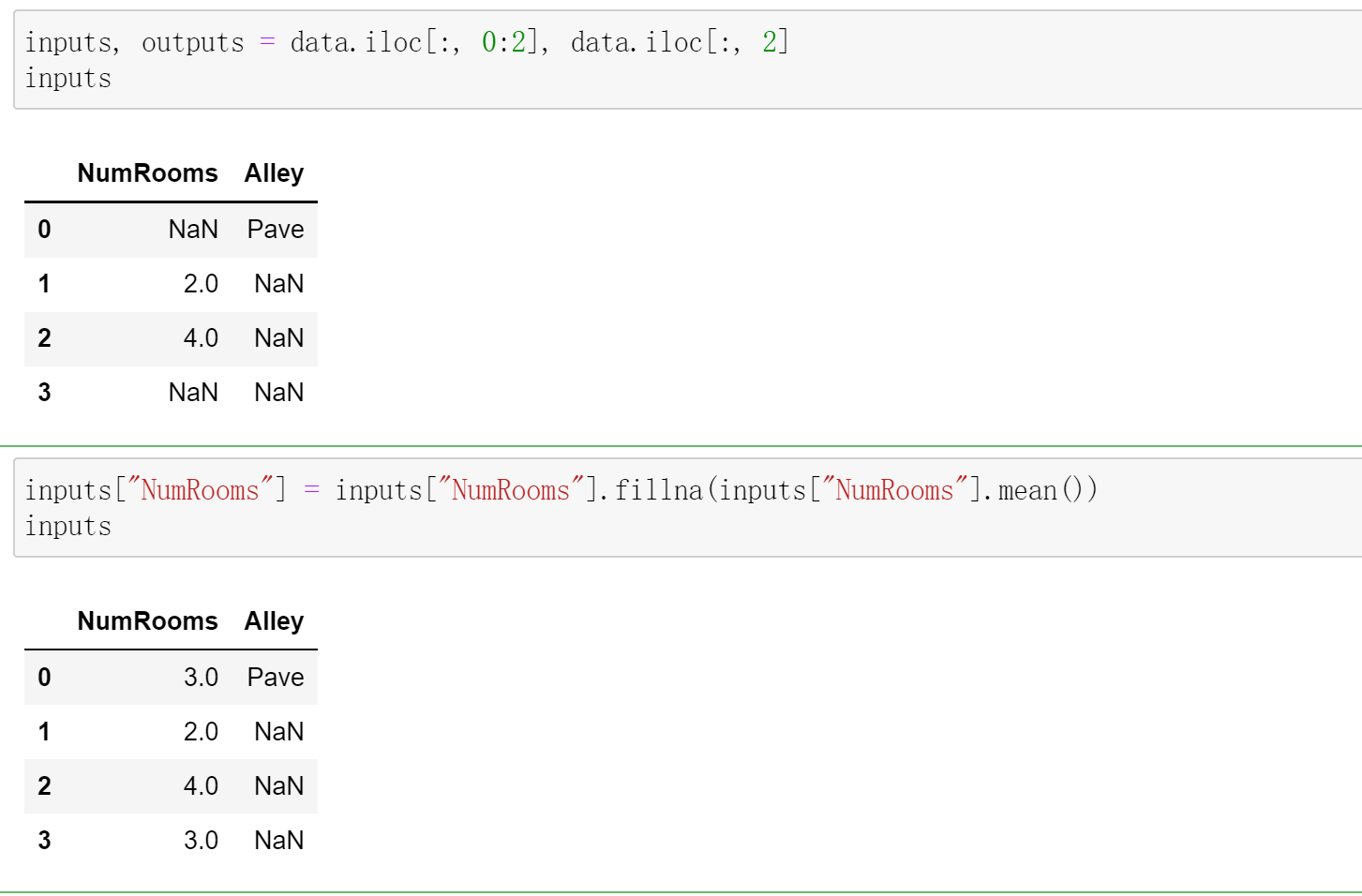
对于inputs中的类别值或离散值,我们将“NaN”视为⼀个类别。由于“巷⼦类型”(“Alley”)列只接受两
种类型的类别值“Pave”和“NaN”,pandas可以⾃动将此列转换为两列“Alley_Pave”和“Alley_nan”。巷
⼦类型为“Pave”的⾏会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。缺少巷⼦类型的⾏会
将“Alley_Pave”和“Alley_nan”分别设置为0和1。
pandas.get_dummies(data, prefix=None, prefix_sep=’_’, dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)
pandas 中的 get_dummies 方法主要用于对类别型特征做 One-Hot 编码(独热编码)。
1、Series里的整数会按照one-hot进行编码,但是在DataFrame里面不会
2、特征的维度数量会有所增加
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
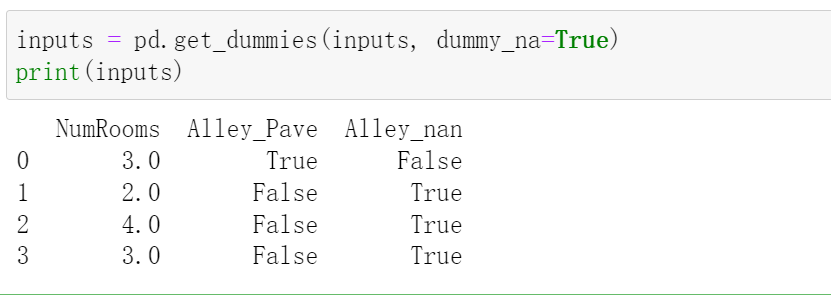
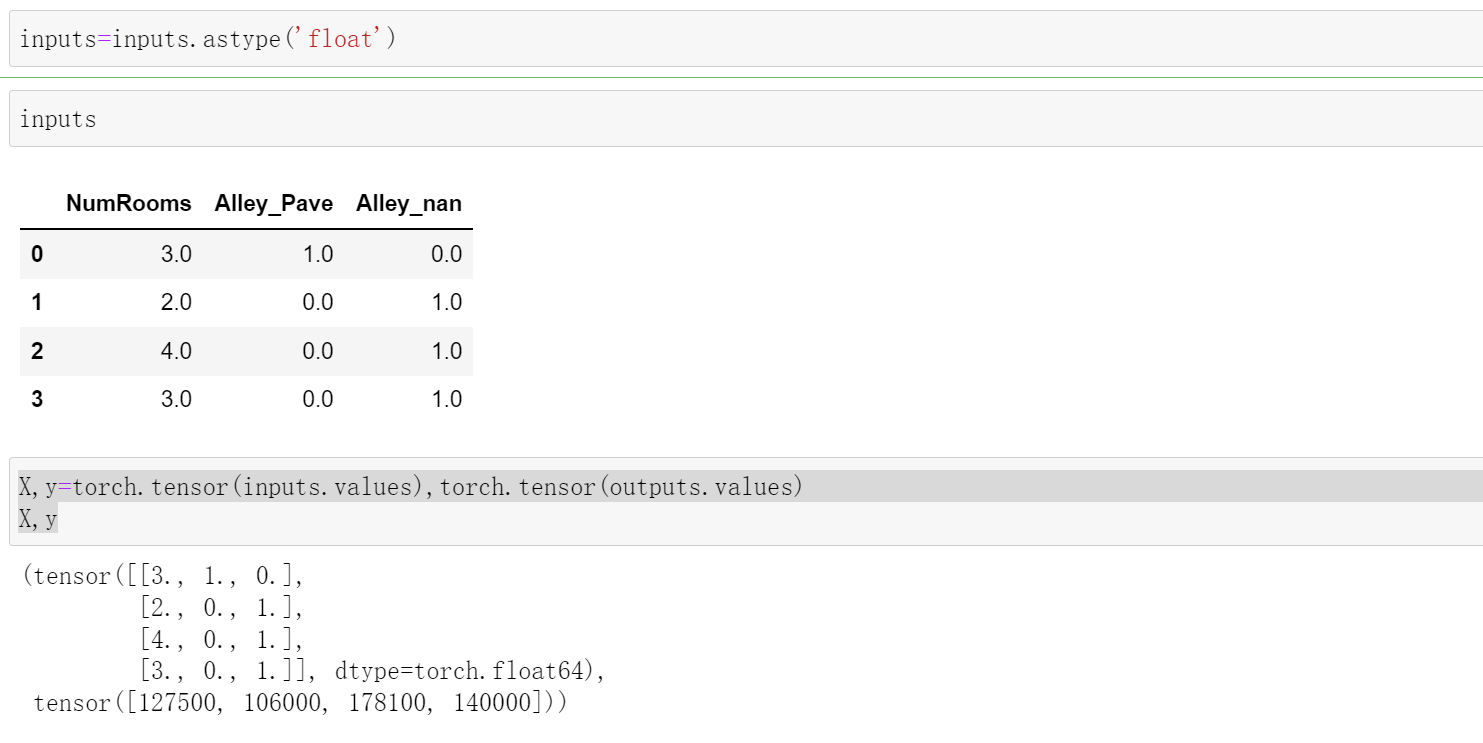
然后再将其转化成tensor,我们发现这个"Alley_Pave"和"Alley_nan"是True和False类型,所以我们需要转化成Float类型之后才能转化成tensor
inputs=inputs.astype('float')
inputs
X,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
X,y