4.5 模型保存和加载
1 简介
当训练或者计算好一个模型之后,那么如果别人需要我们提供结果预测,就需要保存模型(主要是保存算法的参数)
2 sklearn模型的保存和加载API
from sklearn.externals import joblib
- 保存:joblib.dump(rf, 'test.pkl')
- 加载:estimator = joblib.load('test.pkl')
注:这个test.pkl是路径加上后缀
用的时候直接joblib.load就行直接返回一个我们之前调参好的estimator
3 例如
保存时
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor,Ridge
from sklearn.metrics import mean_squared_error
from sklearn.externals import joblib
def linear3():
"""
岭回归的优化方法对波士顿房价进行预测
:return:
"""
#1)获取数据
bosten = load_boston()
#2)划分数据集
x_train,x_test,y_train,y_test=train_test_split(bosten.data,bosten.target,random_state=22)
#3)标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#4)预估器
estimator=Ridge(alpha=0.5,max_iter=10000)
estimator.fit(x_train,y_train)
#保存模型
joblib.dump(estimator,"my_ridge.pkl")
# 加载模型
#estimator=joblib.load("my_ridge.pkl")
#5)得出模型
print("岭回归-权重系数为:\n",estimator.coef_)
print("岭回归-偏置为:\n",estimator.intercept_)
#6)模型评估
y_predict=estimator.predict(x_test)
print("岭回归:\n",y_predict)
error =mean_squared_error(y_test,y_predict)
print("岭回归-均方误差:\n",error)
return None
运行之后:
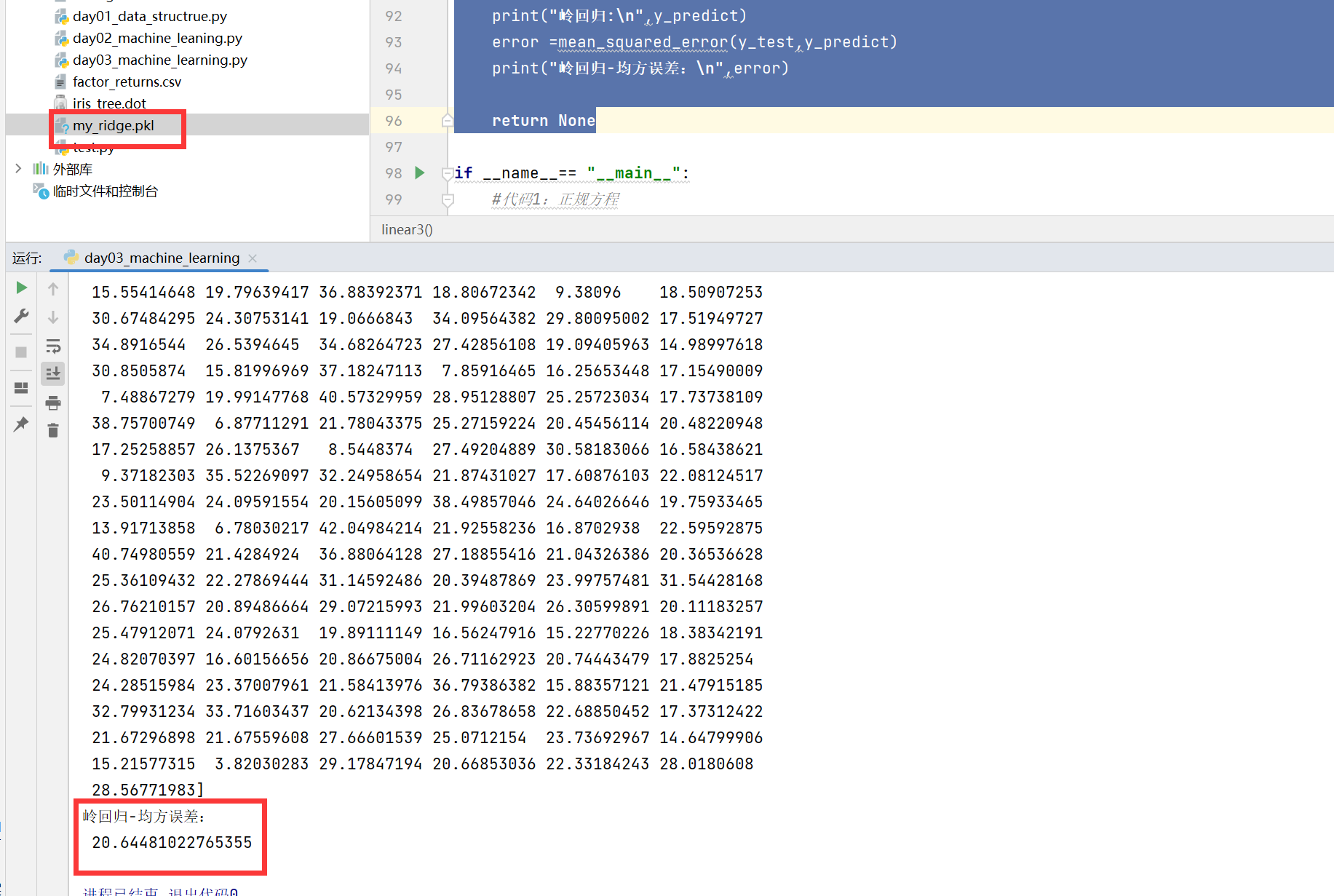
加载时:
这是就不需要要在预测一遍了
def linear3():
"""
岭回归的优化方法对波士顿房价进行预测
:return:
"""
#1)获取数据
bosten = load_boston()
#2)划分数据集
x_train,x_test,y_train,y_test=train_test_split(bosten.data,bosten.target,random_state=22)
#3)标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
# 加载模型
estimator=joblib.load("my_ridge.pkl")
#5)得出模型
print("岭回归-权重系数为:\n",estimator.coef_)
print("岭回归-偏置为:\n",estimator.intercept_)
#6)模型评估
y_predict=estimator.predict(x_test)
print("岭回归:\n",y_predict)
error =mean_squared_error(y_test,y_predict)
print("岭回归-均方误差:\n",error)
return None
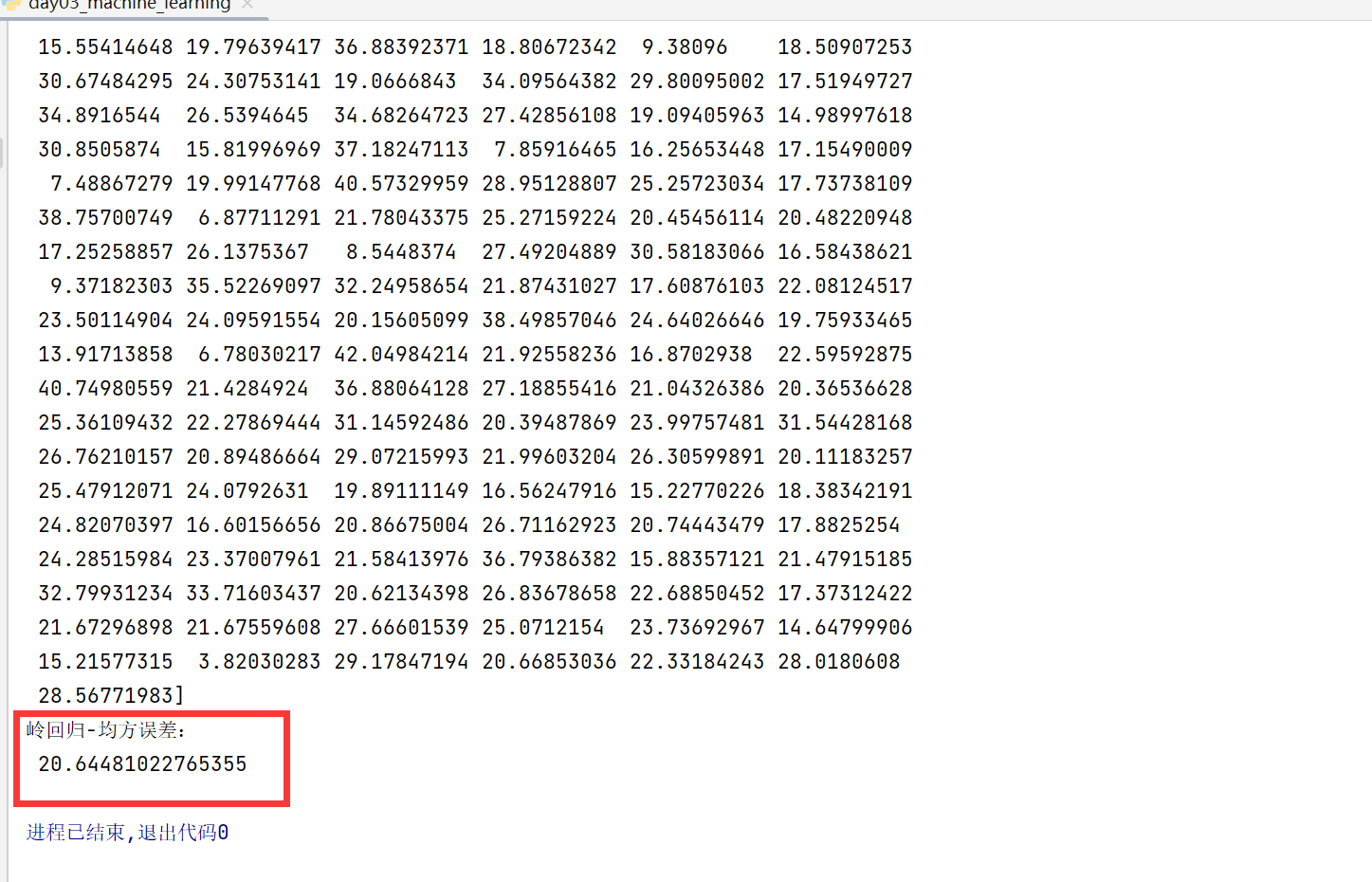
运行出来时一致的
