3.5 集成学习方法之随机森林
因为决策树会出现那种过拟合的情况,这时候我们就会用到随机森林
1 什么是集成学习方法
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
说白了,就是三个臭皮匠顶一个诸葛亮,就是让很多人进行预测,然后取众数
其中随机森林就是集成学习方法中的一种
2 随机森林算法
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
森林:包含多个决策树的分类器
随机:两个随机:训练集随机,特征随机
训练集随机:---随机有放回的抽取
bootstrap 随机又放回抽样[1,2,3,4,5] ,新的树的训练集[2,2,3,1,5]。
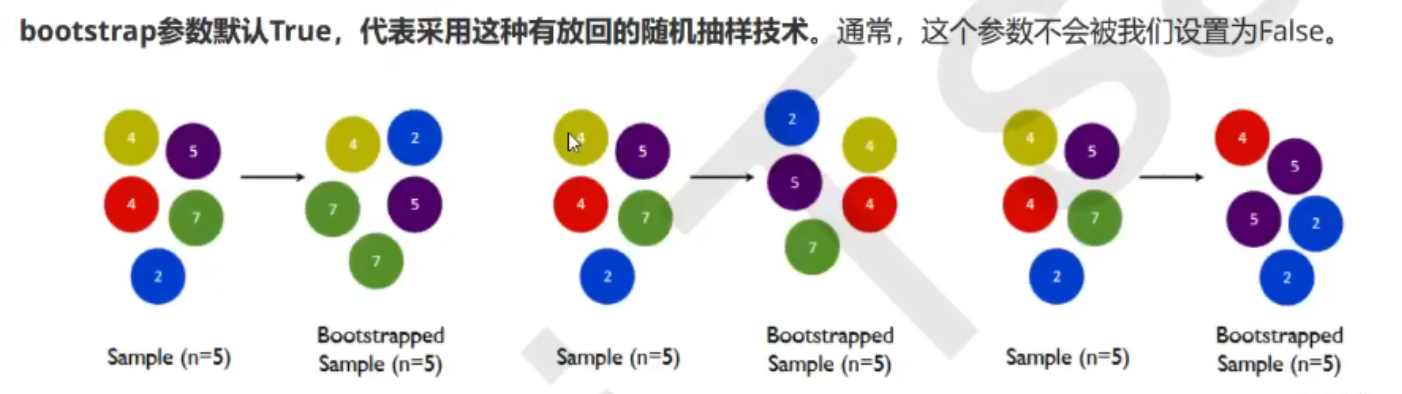
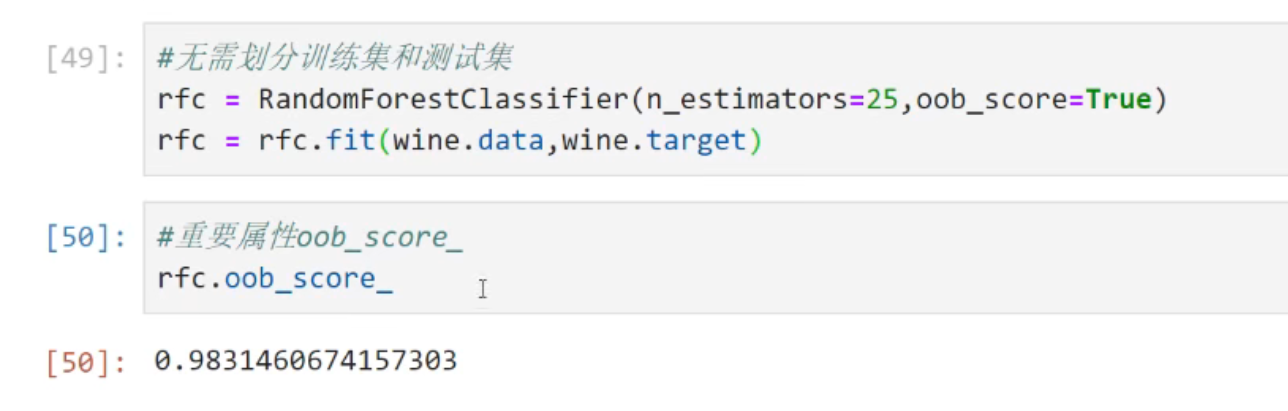
因此,会有约37%的训练数据浪费掉,没有参与建模,这些数据被称为袋外数据(out of bag data,简称oob)。所以这些袋外数据可以当成集成算法的测试集。也就是说,在使用随机森林时,我们可以不划分测试集和训练集,只需要用袋外数据进行测试我们的模型就行。如果我们需要用袋外数据来测试,则需要在实例化时将oob_score这个参数调为True,训练完毕之后,我们就可以用随机随机森林中的另一个重要属性:oob_score_来查看我们的在袋外数据上的测试的结果。
#无需划分训练集和测试集
rfc=RandomForestClassifier(n_estimators=25,obb_score=True)
rfc=rfc.fit(win.data,win.target)
#重要属性oob_score_
rfc.oob_score_
特征随机----从M个特征中随机抽取m个特征
M>>m
有降维的效果
3.原理
随机森林原理过程
学习算法根据下列算法而建造每棵树:
用N来表示训练用例(样本)的个数,M表示特征数目。
1、一次随机选出一个样本,重复N次, (有可能出现重复的样本)
2、随机去选出m个特征, m <<M,建立决策树
采取bootstrap抽样
为什么采用BootStrap抽样
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
4.API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
随机森林分类器
n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200
criteria:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30
max_features="auto”,每个决策树的最大特征数量
If "auto", then max_features=sqrt(n_features).(M>>m)
If "sqrt", then max_features=sqrt(n_features) (same as "auto").
If "log2", then max_features=log2(n_features).
If None, then max_features=n_features.
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
min_samples_split:节点划分最少样本数
min_samples_leaf:叶子节点的最小样本数
超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
5.随机森林对泰坦尼克号生存的影响
# 随机森林去进行预测
rf = RandomForestClassifier()
param = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}
# 超参数调优
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("随机森林预测的准确率为:", gc.score(x_test, y_test))
6 例子
%matplotlib inline
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
加载数据
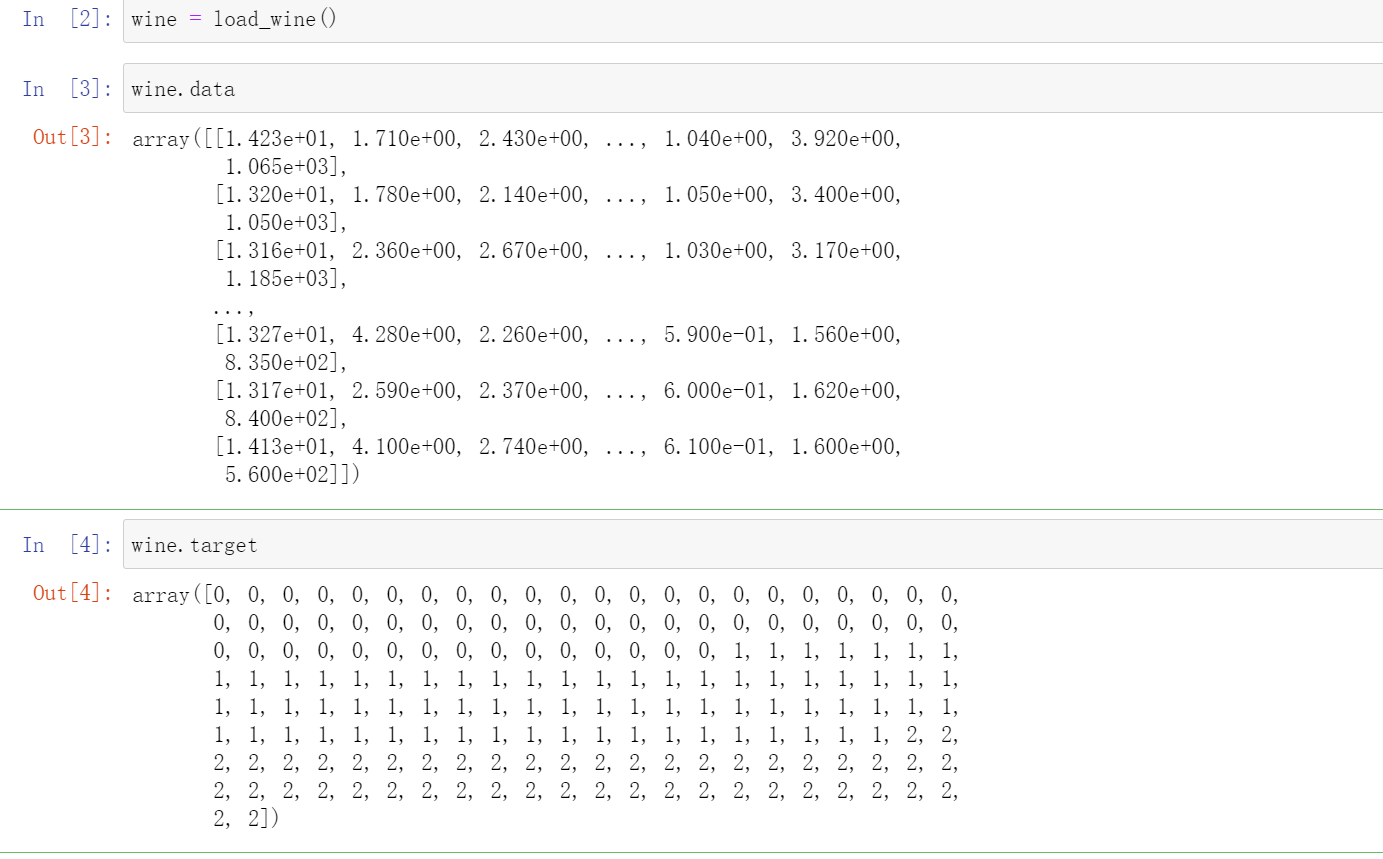
wine = load_wine()
wine.data
wine.target
划分数据集
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
定义模型
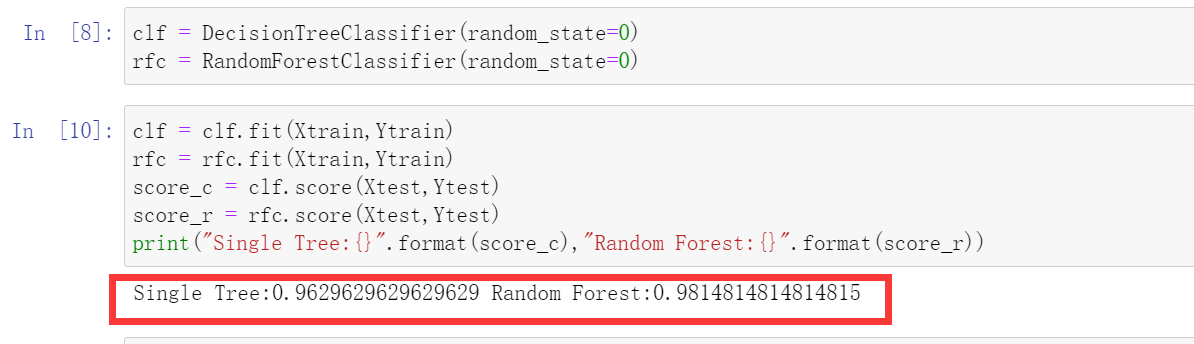
clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest)
print("Single Tree:{}".format(score_c),"Random Forest:{}".format(score_r))
交叉验证:交叉验证就是我们每次将数据集分成n份,然后每次随机的将n-1份变成训练集,然后剩余的1份进行测试。
#交叉验证
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
rfc=RandomForestClassifier(n_estimators=25)
rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=10)
#这里cv=10是进行10次交叉验证
clf=DecisionTreeClassifier()
clf_s=cross_val_score(clf,wine.data,wine.target,cv=10)
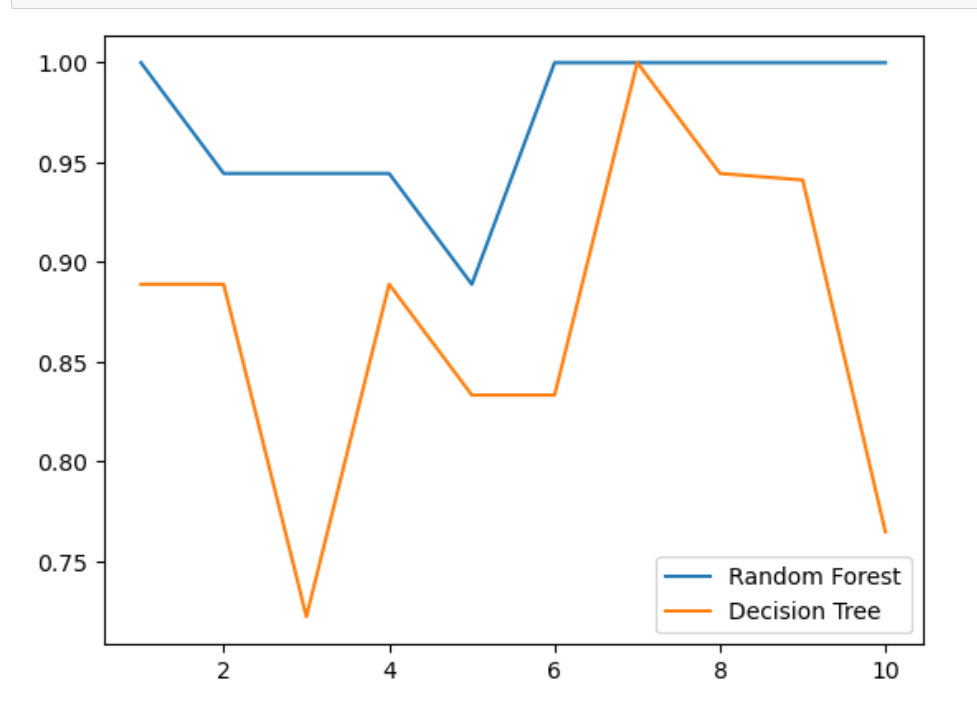
plt.plot(range(1,11),rfc_s,label = "Random Forest")
plt.plot(range(1,11),clf_s,label = "Decision Tree")
plt.legend()
plt.show()
我们发现这个的随机森林比决策树好
7 重要属性和接口
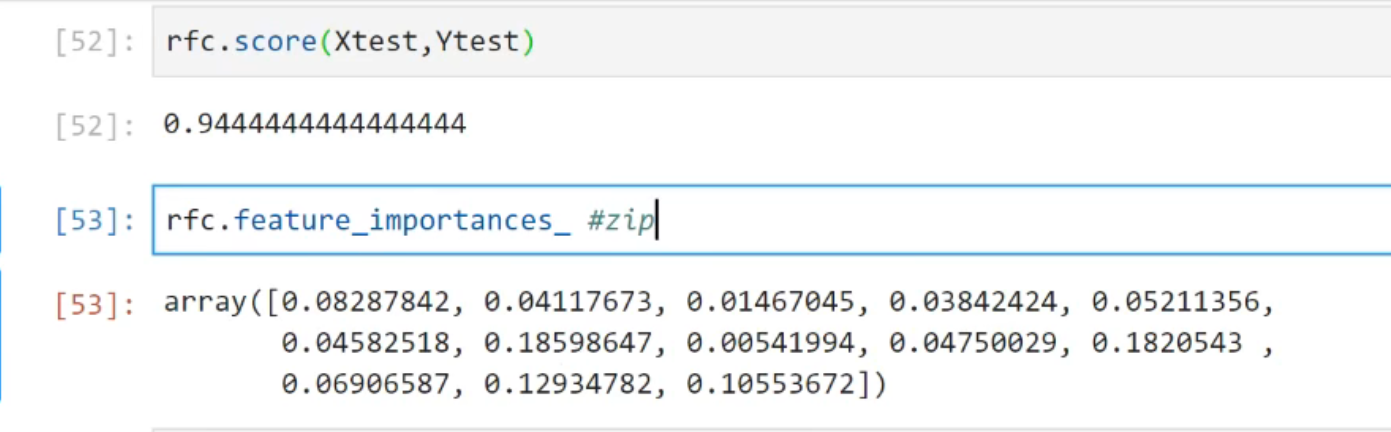
随机森林中有三个非常重要的属性:.estimators_,.oob_score_以及.feature_importances_。
.estimators_是用来查看随机森林中所有树的列表的。
oob_score_指的是袋外得分。随机森林为了确保林中的每棵树都不尽相同,所以采用了对训练集进行有放回抽样的
方式来不断组成信的训练集,在这个过程中,会有一些数据从来没有被随机挑选到,他们就被叫做“袋外数据”。这
些袋外数据,没有被模型用来进行训练,sklearn可以帮助我们用他们来测试模型,测试的结果就由这个属性
.oob_score_来导出,本质还是模型的精确度。
而.feature_importances_和决策树中的.feature_importances_用法和含义都一致,是返回特征的重要性。
随机森林的接口与决策树完全一致,因此依然有四个常用接口:apply, fit, predict和score。除此之外,还需要注
意随机森林的predict_proba接口,这个接口返回每个测试样本对应的被分到每一类标签的概率,标签有几个分类
就返回几个概率。如果是二分类问题,则predict_proba返回的数值大于0.5的,被分为1,小于0.5的,被分为0。
传统的随机森林是利用袋装法中的规则,平均或少数服从多数来决定集成的结果,而sklearn中的随机森林是平均
每个样本对应的predict_proba返回的概率,得到一个平均概率,从而决定测试样本的分类。

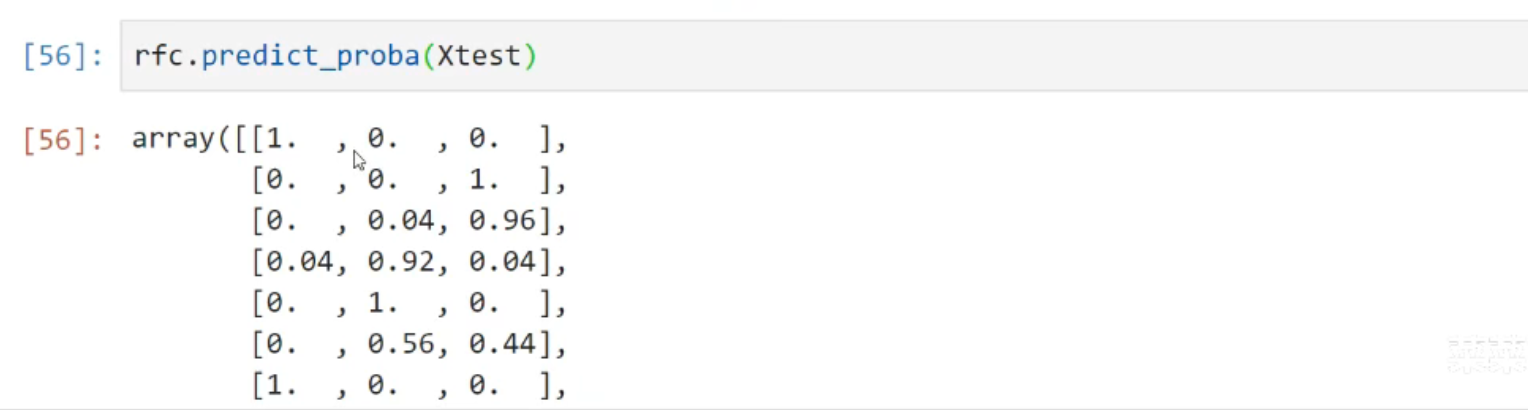
rfc.predict(Xtest)预测

rfc.predict_proba(Xtest),被分到每一个标签的概率
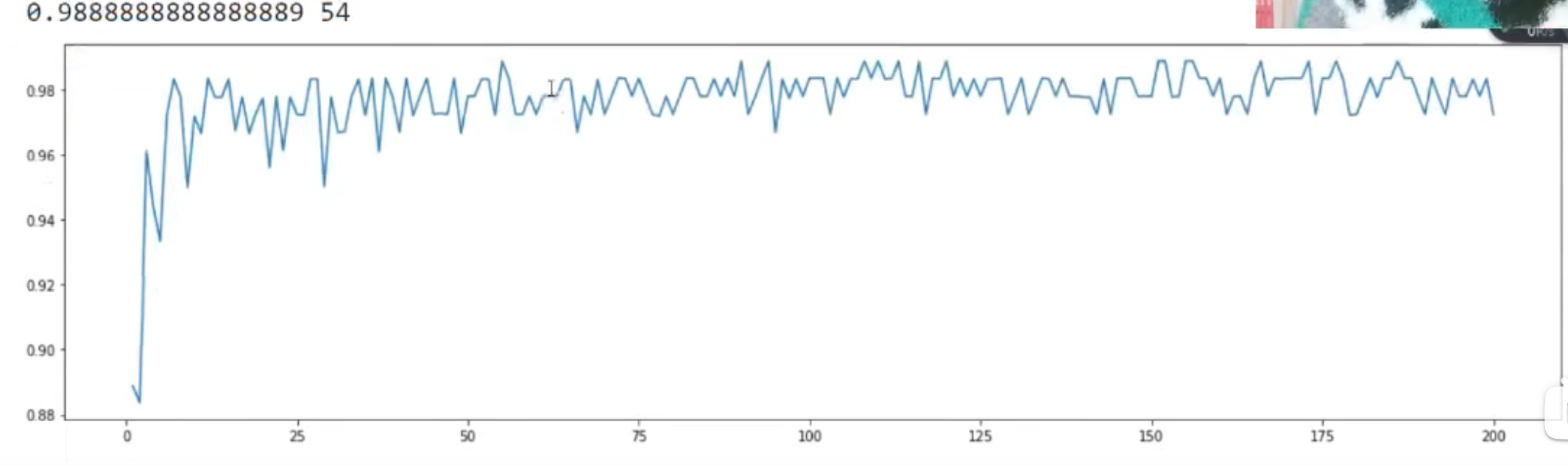
n_estimators学习曲线
我们在调参的时候如果有很长的时间的话,我们可以画学习曲线,这个比较慢。
superpa = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
print(max(superpa),superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()
这个就是把每一个参数n_estimators都画出来了。
总结
在当前所有算法中,具有极好的准确率
能够有效地运行在大数据集上,处理具有高维特征的输入样本,而且不需要降维(其实从M个特征中抽取m个就相当于降维)
能够评估各个特征在分类问题上的重要性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号