3.2 KNN算法(k-近邻算法)
1.什么是k-近邻算法
例如:
如果你不知道你现在在哪,你可以通过你和你的邻居的距离推算出你的位置
你的“邻居”来推断出你的类别
2.原理
2.1 定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
就是看看样本中离我最近的那个样本属于那个类别,我就属于那个类别
k取1的话,万一跟异常值最相似,所以不准确容易收到异常值的影响
2.2 距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
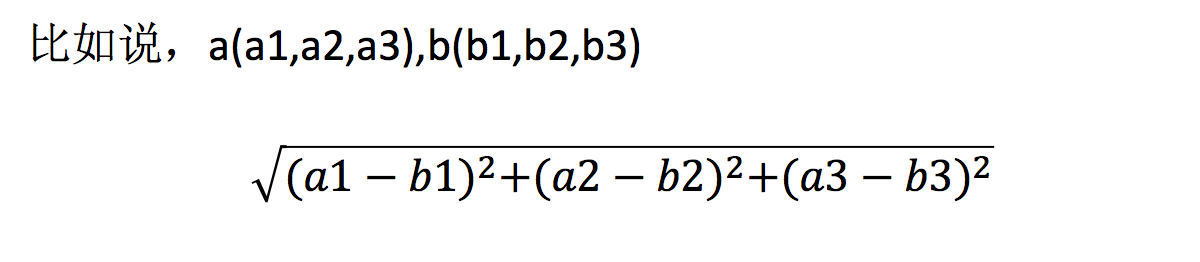
2.3 例子
例如:电影类型分析
假设我们有现在几部电影
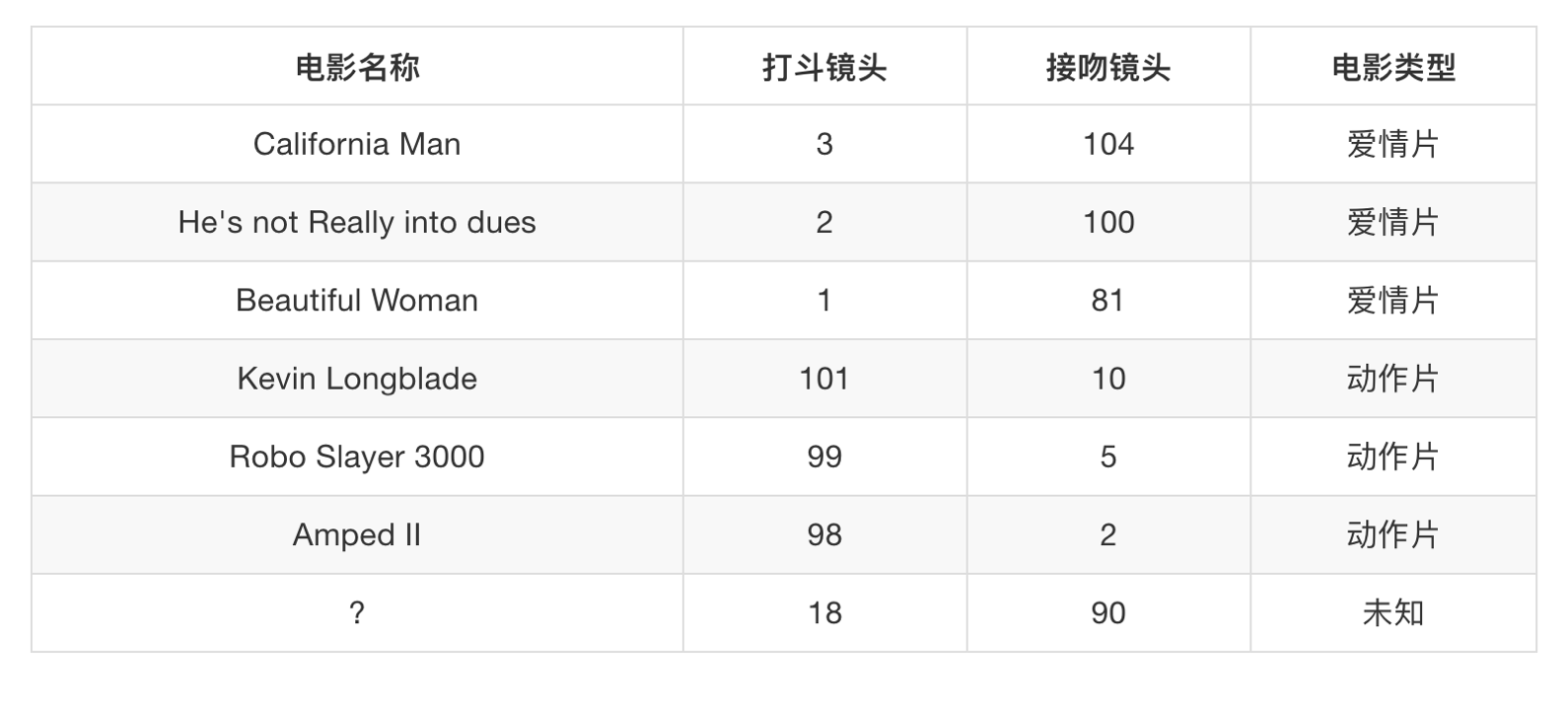
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想
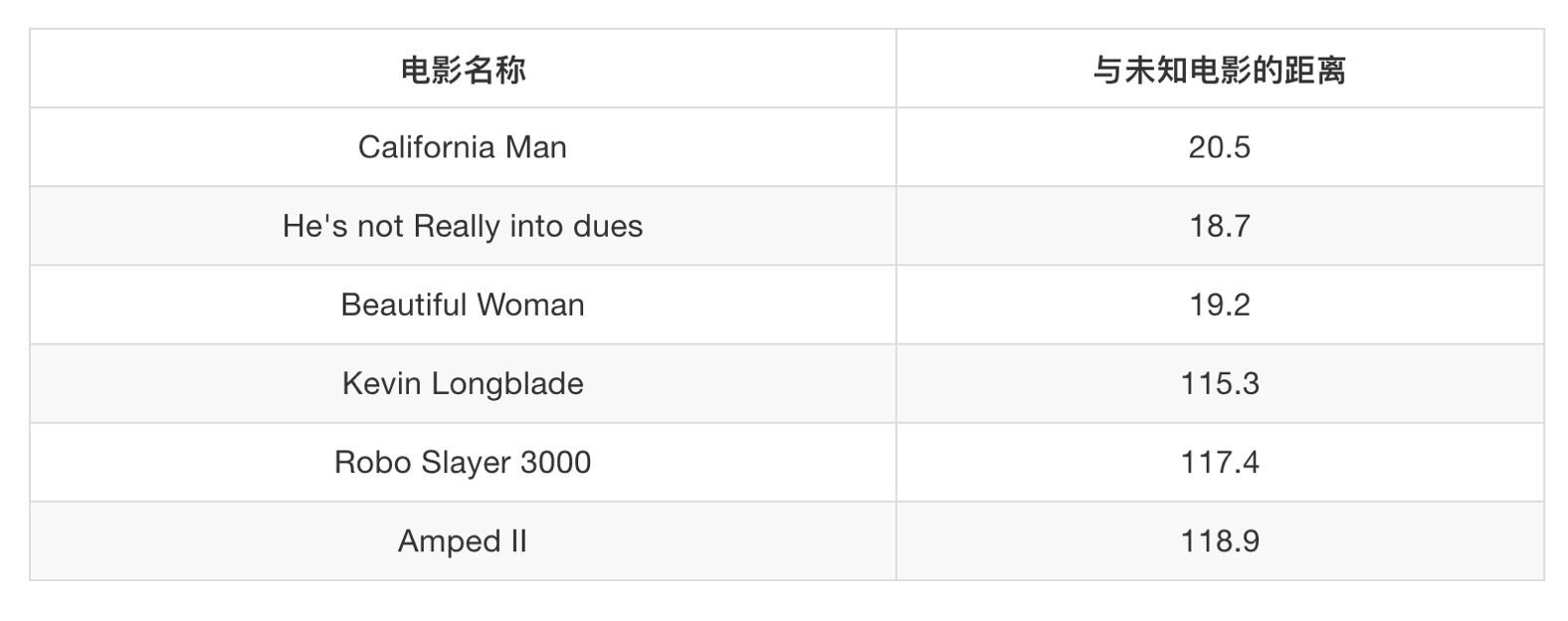
假如说k=1时,找一个最相近的是He's not Really into dues 是爱情片
假如说k=2时,找两个最相近的时He's not Really into dues和Beautiful Woman 也是爱情片
。。。。。。。。。。
k=6 无法确定
如果说k=7,三个爱情片,四个动作片,把他变成了动作片,很明显不是,所以k不能太大
k值取得太大样本不均衡的话会受到影响
k值取得过小,容易受到异常点的影响k值取得过大,样本不均衡的影响
2.4KNN算法步骤和API
1.k值取得过小,容易受到异常点的影响k值取得过大,样本不均衡的影响
2.结合前面的约会对象数据,在进行KNN算法之前需要对数据进行无量纲化处理和标准化处理
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数,就是k值
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},
可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
#初始化一个转换器类
estimate=KNeighborsClassifier(n_neighbors=3)
#模型计算
estimate.fit(x_train,y_train)
#5) 模型评估
#方法1:直接对比真实值和预测值
y_predict=estimate.predict(x_test)
2.5案例

步骤:
(1)获取数据
(2)数据集的划分
(3)特征工程: 标准化
(4)KNN预估器流程
(5)模型评估
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
def knn_iris():
"""
用KNN算法对鸢尾花进行分类
:return:
"""
#1) 获取数据
iris = load_iris()
#2) 划分数据集
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=6)##数据集,目标集
##训练集特征值,测试集特征值,训练集目标集,测试集目标集
#3) 特征工程:标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)#这时候只需要让测试集转化就行,没有必要计算,fit时计算过程,transform是转化
#4) knn算法预估器
estimate=KNeighborsClassifier(n_neighbors=3)
estimate.fit(x_train,y_train)
#5) 模型评估
#方法1:直接对比真实值和预测值
y_predict=estimate.predict(x_test)
print("y_perdict:\n",y_predict)
print("直接比对真实值和预测值:\n",y_test==y_predict)
#方法2:计算准确率
score=estimate.score(x_test,y_test)
print("准确率:\n",score)
return None
if __name__ == "__main__":
#代码1 KNN
knn_iris()
注意一点就是标准化的时候
fit_transform(x_train)
transform(x_test)#这个测试值不需要计算,只需要转化就行
至于为什么是因为博客
因为这个
如果fit_transfrom(trainData)后,使用fit_transform(testData)而不transform(testData),虽然也能归一化,但是两个结果不是在同一个“标准”下的,具有明显差异。(一定要避免这种情况)
因为先fit_transfrom像是定下了某种算法或者标准,如果在测试集上再进行fit(),由于两次的数据不一样,导致得到不同的指标,会使预测发生偏差,因为模型是针对之前的数据fit()出来的标准来训练的,而现在的数据是新的标准,会导致预测的不准确。
fit_transform()干了两件事:fit找到数据转换规则,并将数据标准化。transform:是将数据进行转换,比如数据的归一化和标准化,训练集和测试集必须要在一个规则下进行比较才有效。
这里有个例子例子
3 KNN总结
K-近邻总结
优点:
简单,易于理解,易于实现,无需训练
缺点:
懒惰算法,对测试样本分类时的计算量大,内存开销大
必须指定K值,K值选择不当则分类精度不能保证
使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号