pandas文件的读取和存储和缺失值处理
numpy读取不了字符串,pandas比较方便
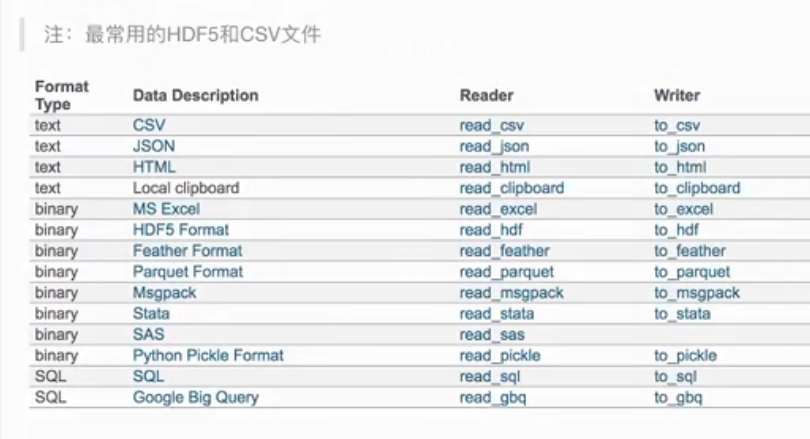
常用
csv 通常读取文本文件
hdf5 通常读取二进制
Json
1.读取CSV
read_csv()
1.读取CSV文件-read_csv()
pandas.read_csv(filepath_or_buffer, sep =',' ,usecols=[], delimiter = None)
filepath_or_buffer:文件路径
usecols:指定读取的列名,列表形式,就是只读取我们需要的字段
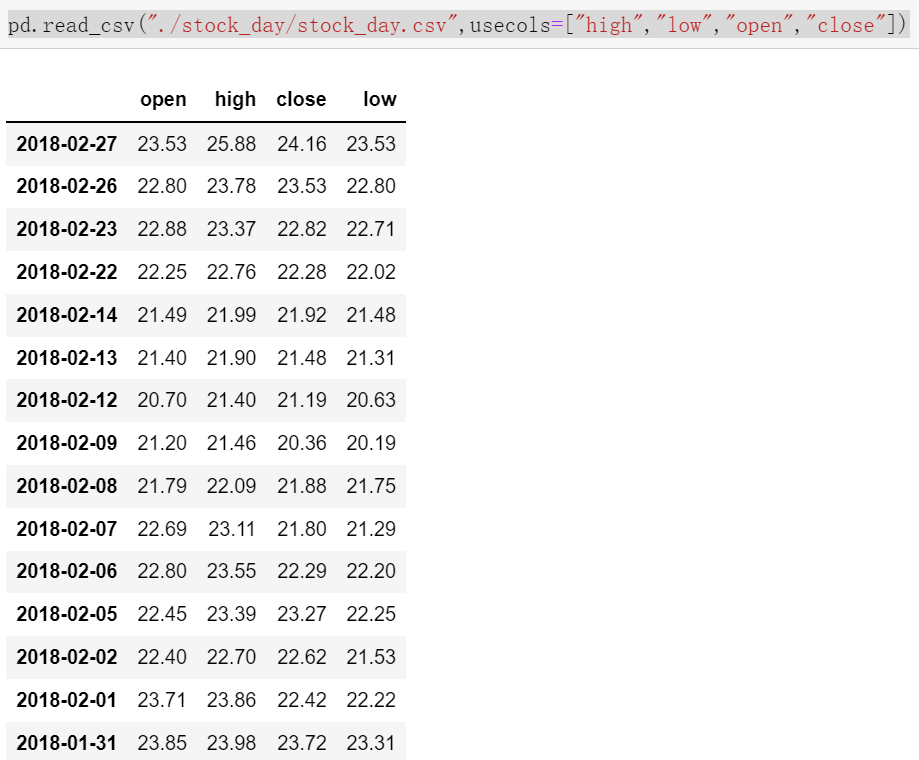
pd.read_csv("./stock_day/stock_day.csv",usecols=["high","low","open","close"])
如果读取的文件没有字段的话,就是没有open,high.....直接是数据,这样需要names字段
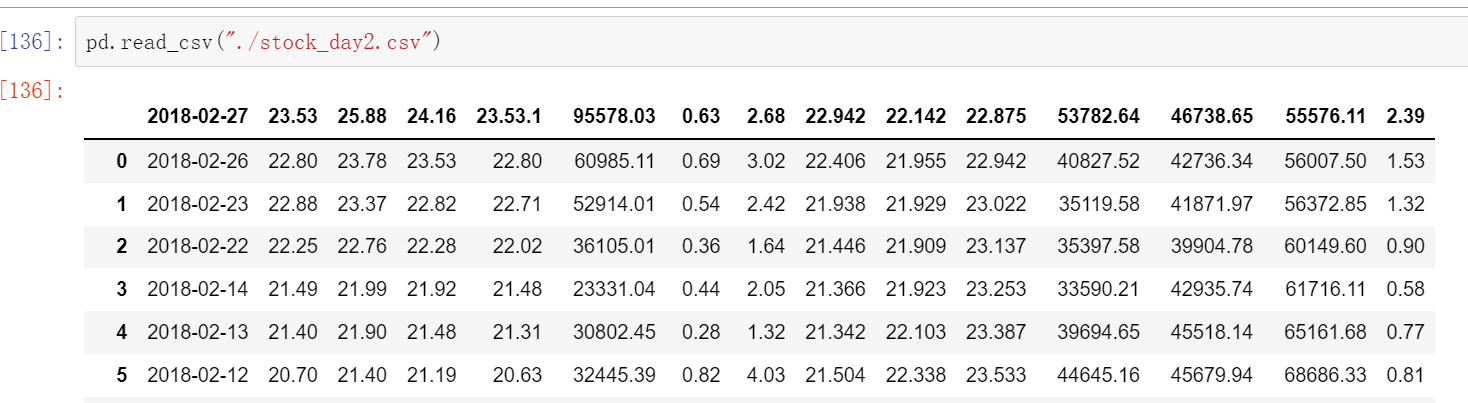
pd.read_csv("stock_day2.csv", names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"])

2.写入CSV文件:datafram.tocsv()
DataFrame.to_csv(path_or_buf=None,sep=',',columns=None,header=True,index=True,index_label=None,mode='w',encoding=None)
o path_or_buf:string or file handle, default None
o sep:character,default','
o columns :sequence, optionalo mode:'w':重o, 'a'追加
o index:是否保存行索引
o header:boolean or list of string, default True,是否写进列索引值
Series.to_csv(path=None,index=True,sep=',',na_rep=",float_format=None,header=False,index_label=None,mode='w',encoding=None,compression=None,date_format=None, decimal='.')
Write Series to a comma-separated values (csv) file
案例保存'open'列的数据
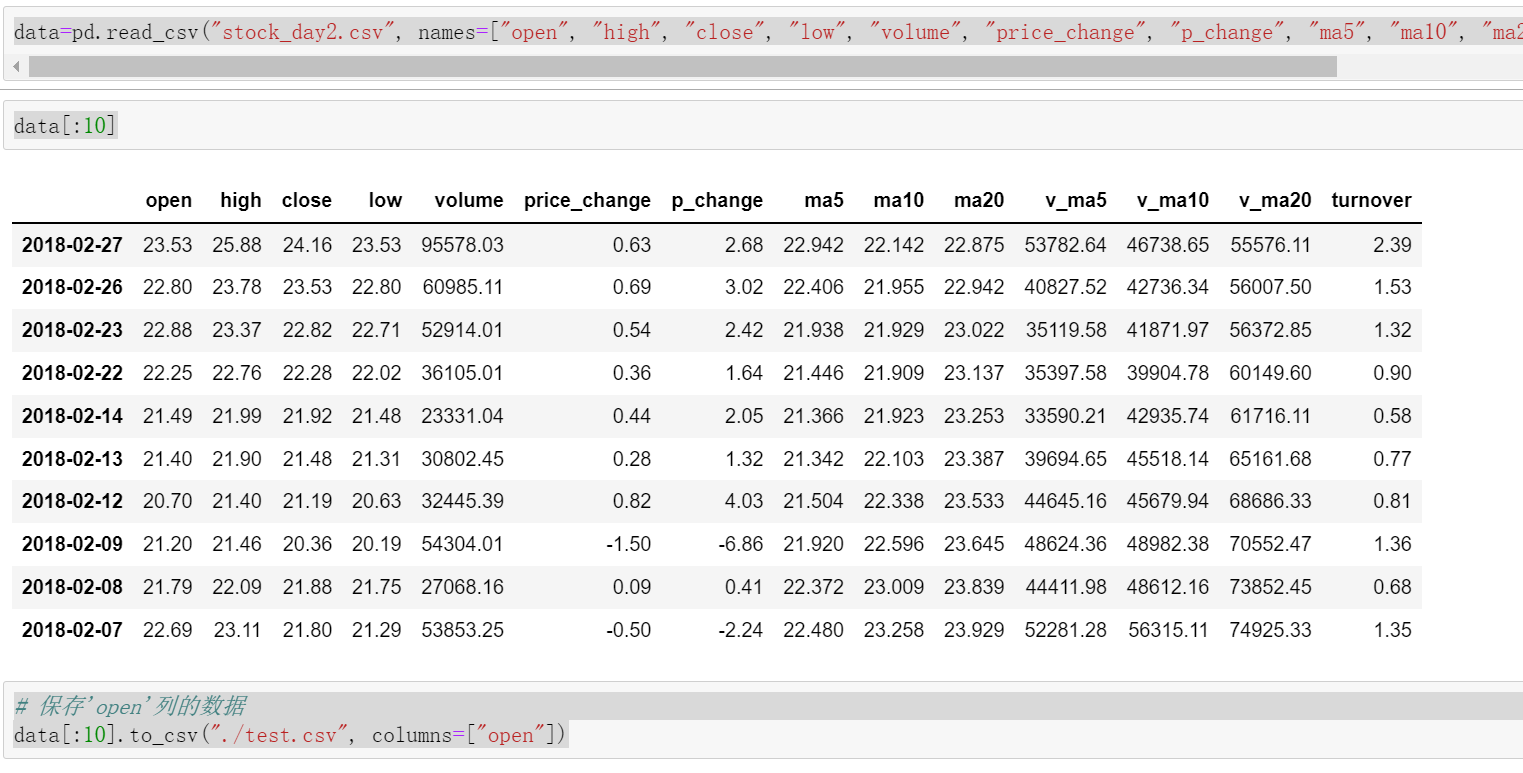
data=pd.read_csv("stock_day2.csv", names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"])
# 保存'open'列的数据
data[:10].to_csv("./test.csv", columns=["open"])
2.读取HDF5
read_hdf()
hdf5 存储 3维数据的文件
key1 dataframe1二维文件
key2 dataframe2二维文件
2.1 read_hdf()
read_hdf()与 to_hdf()
HDF5 文件的读取和存储需要指定一个键,值为要存储的 DataFrame
pandas.read_hdf(path_or_buf, key=None, **kwargs)
从 h5 文件当中读取数据
path_or_buffer: 文件路径
key: 读取的键
mode: 打开文件的模式
reurn: The Selected object
DataFrame.to_hdf(path_or_buf, key, **kwargs)
读入
day_close = pd.read_hdf("./stock_data/day/day_close.h5")
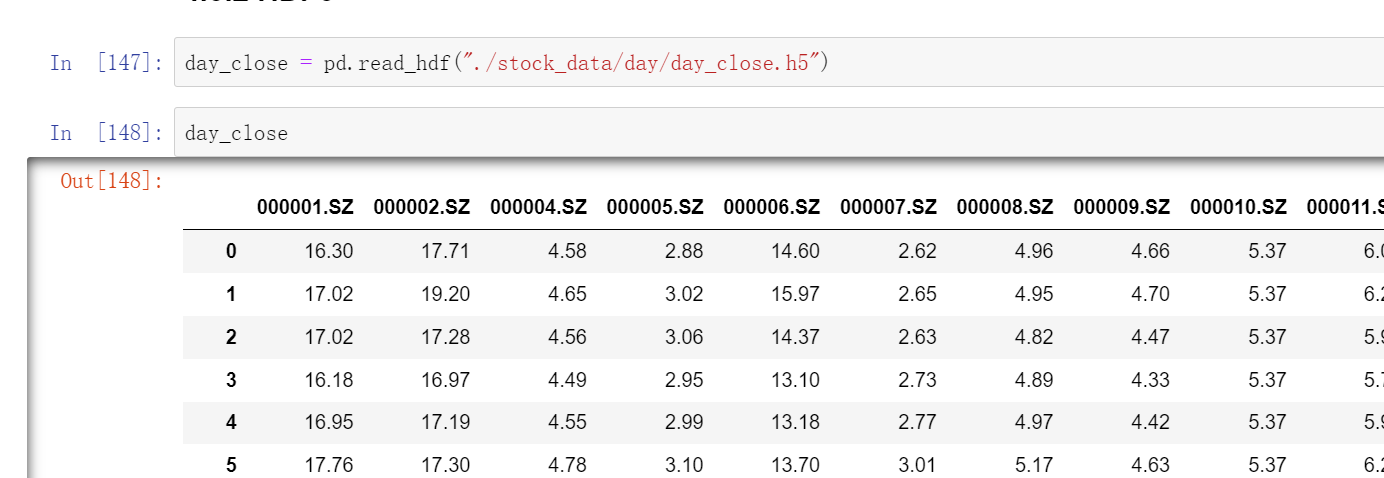
如果读取完再写入的话(多个key时)
day_close.to_hdf("test.h5", key="close")
#这个时候key只设置了一个,所以再读的时候可以不用加key,加上也可以
pd.read_hdf("test.h5", key="close").head()
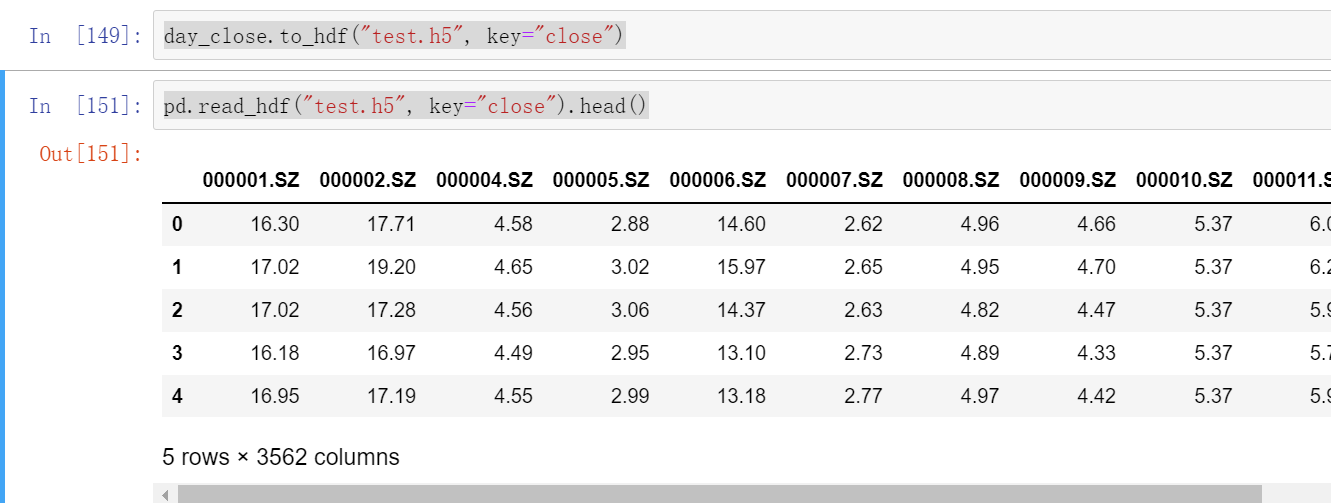
#我们再读取一个然后再保存到test.h5中,这是换一个key
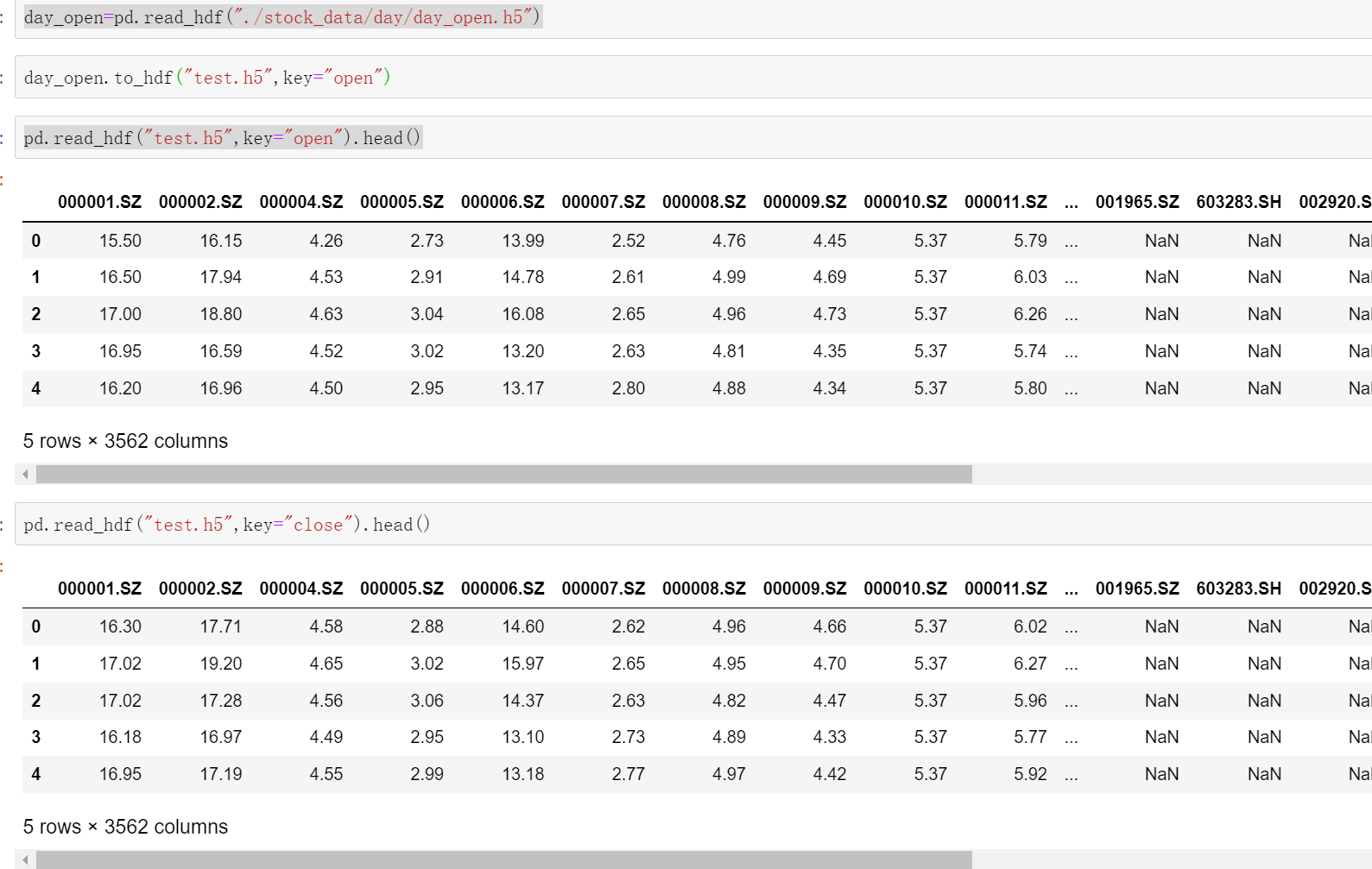
day_open=pd.read_hdf("./stock_data/day/day_open.h5")
day_open.to_hdf("test.h5",key="open")
#然后test.h5中就有了"close"和"open"这两个key,如果我们再次读这个test.h5时不加key会报错
pd.read_hdf("test.h5",key="open").head()
pd.read_hdf("test.h5",key="close").head()
3.读取Json
read_json()
pandas.read_json(path_or_buf=None,orient="records",typ="frame",lines=True)
将 JSON 格式转换成默认的Pandas DataFrame格式
orient: string,Indication of expected JSON string format.写="records"
'split': dict like {index -> [index], columns -> [columns], data -> [values]}
'records': list like [{column -> value}, ..., {column -> value}]
'index': dict like {index -> {column -> value}}
'columns': dict like {column -> {index -> value}}, 默认该格式
'values': just the values array
lines: boolean, default False,一般写True
按照每行读取 json 对象
typ: default 'frame',指定转换成的对象类型 series 或者 dataframe
读出
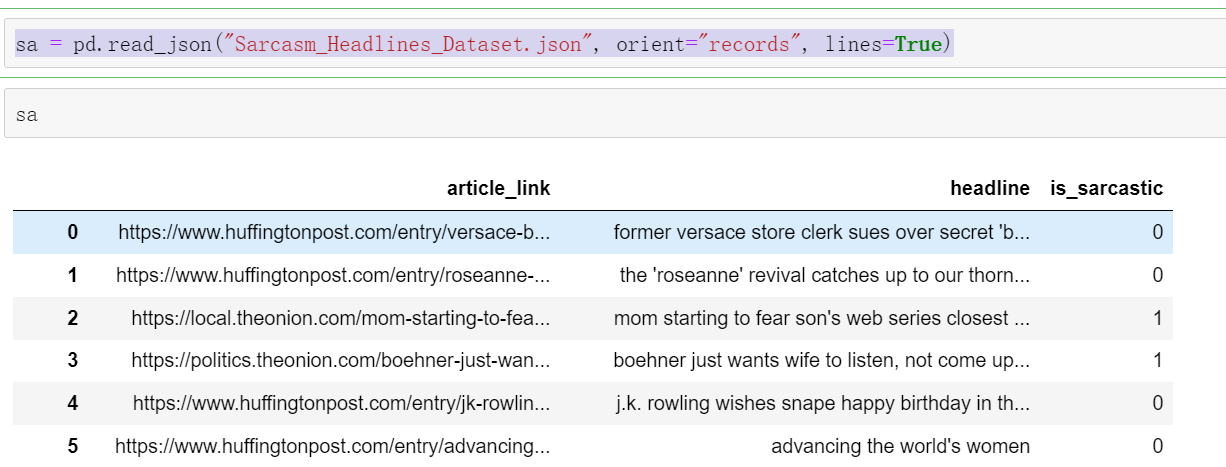
sa = pd.read_json("Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
sa
#读取完之后是一个Datafram类型的文件
写入
sa.to_json("test.json",orient="records",lines=True)
补充:
这个文件./是当前路径
4.缺失值处理
4.1如何进行缺失值的处理
两个思路:
(1)删除含有缺失值的样本
(2)替换/插补
4.1.1缺失值会解读为NaN
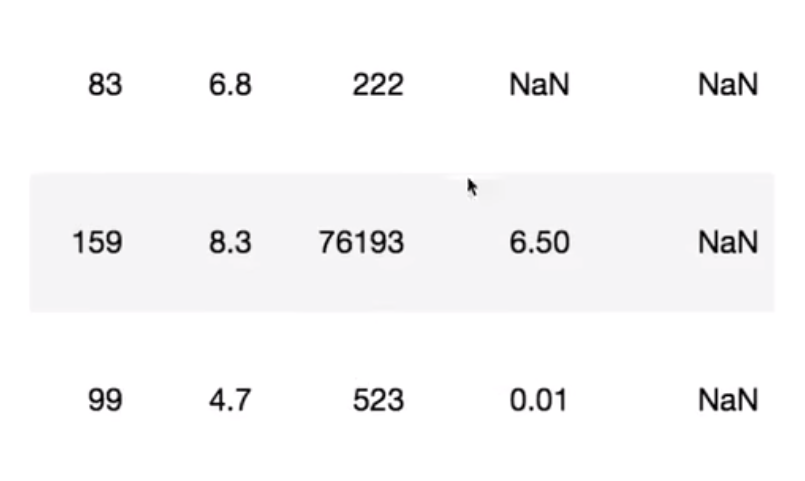
处理方式:
存在缺失值nan,并且是np.nan:
1.删除含有缺失值的样本df.dropna(inplace=True,axis='rows')
默认按行删除 inplace:True 修改原数据,False 返回新数据,默认 False
2.替换/插补数据df.fillna(value,inplace=True)
value 替换的值,inplace:True 修改原数据,False 返回新数据,默认 False
一般这个value取这一列的平均值
1.导入数据
import pandas as pd
movie=pd.read_csv("./IMDB/IMDB-Movie-Data.csv")

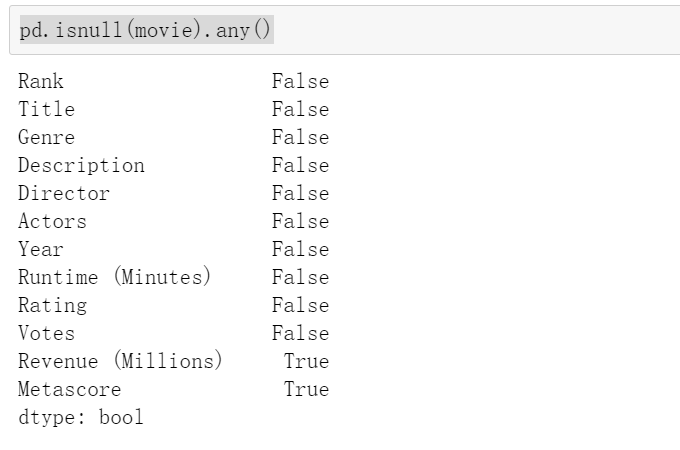
2.判断是否存在缺失值
这个用np里面的np.any()或者pd里面的pd.isnull(movie).any()
import numpy as np
np.any(pd.isnull(movie))#返回Ture说明数据中存在缺失值

或者是:
pd.isnull(movie).any()
3.缺失值处理
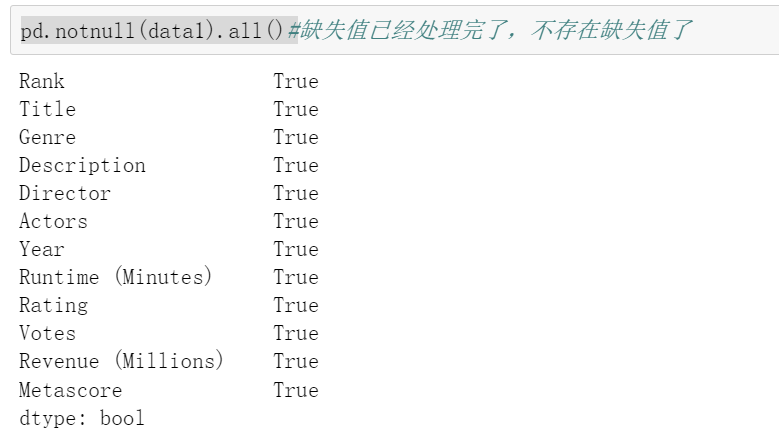
方法1.删除含有缺失值的样本
#2)缺失值处理
#方法1:删除还有缺失值的样本
data1=movie.dropna()
pd.notnull(data1).all()#缺失值已经处理完了,不存在缺失值了
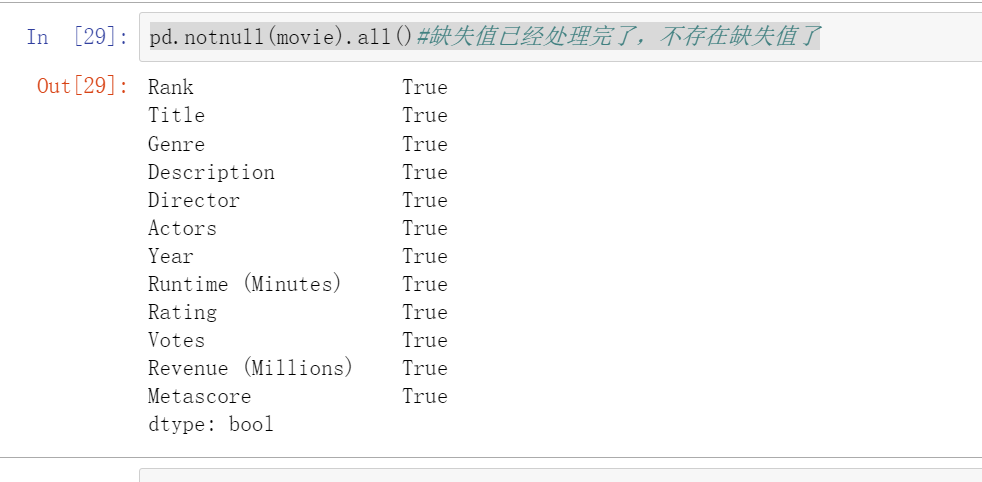
方法二.替换含有缺失值的字段,一般用这一列的平均值来替换
# 替换含有缺失值的字段
# Revenue (Millions)
# Metascore
movie["Revenue (Millions)"].fillna(movie["Revenue (Millions)"].mean(), inplace=True)
movie["Metascore"].fillna(movie["Metascore"].mean(), inplace=True)
#inplace=Ture说明再原数组修改的
pd.notnull(movie).all()#缺失值已经处理完了,不存在缺失值了
4.1.2 缺失值不会解读为NaN,有默认标记的
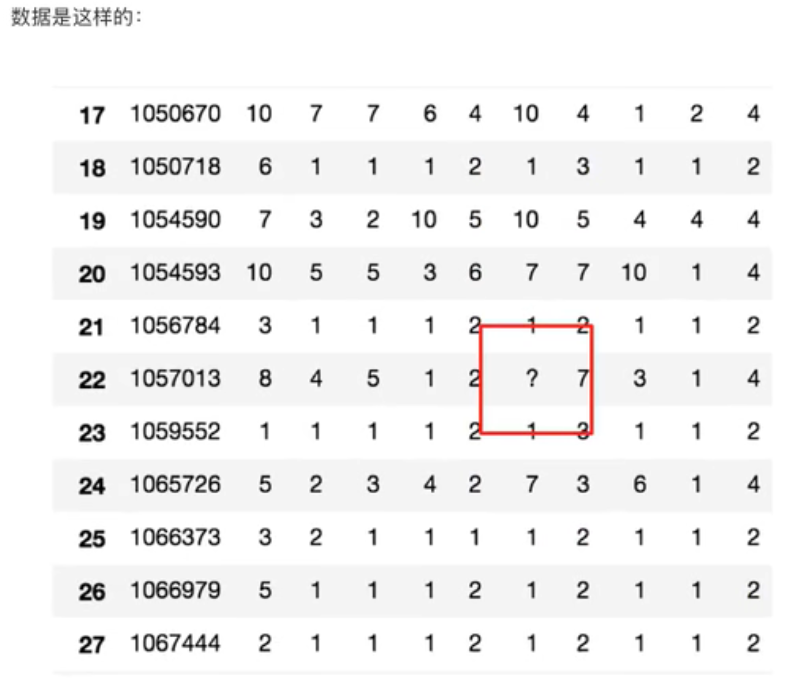
替换:将?->np.nan
df.replace(to_replace="?",value=np.nan)
1.读取数据
2.替换
# 1)替换
data_new = data.replace(to_replace="?", value=np.nan)
按照前面的处理(删除缺失值)
# 2)删除缺失值
data_new.dropna(inplace=True)
5.数据离散化
例如:

表示类别的时候要平等,一个是1,一个是0,这样会误以为1再某种程度上比0厉害。所以把他弄成二维的
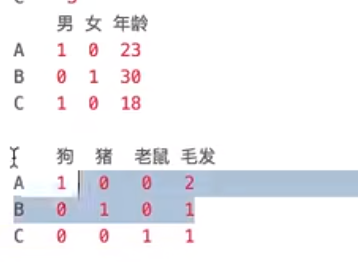
什么是数据的离散化
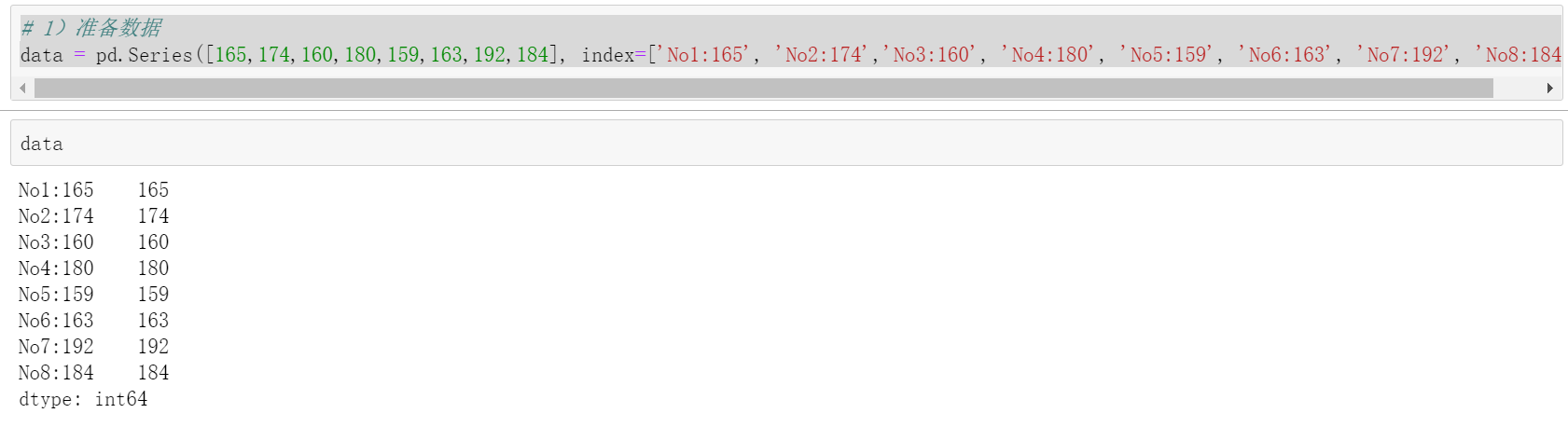
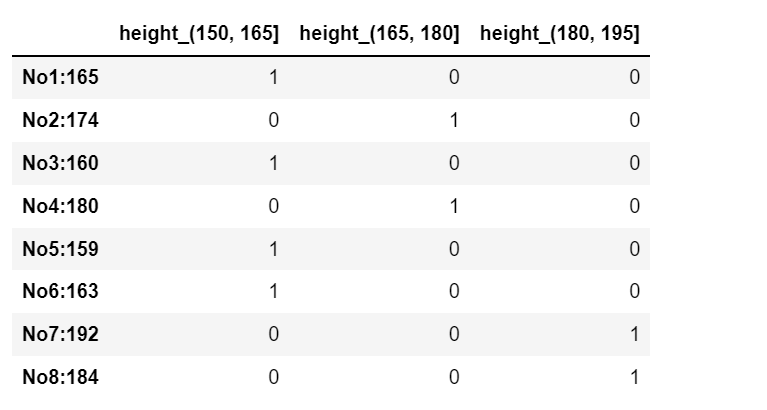
原始的身高数据:165,174,160,180,159,163,192,184
分成三组
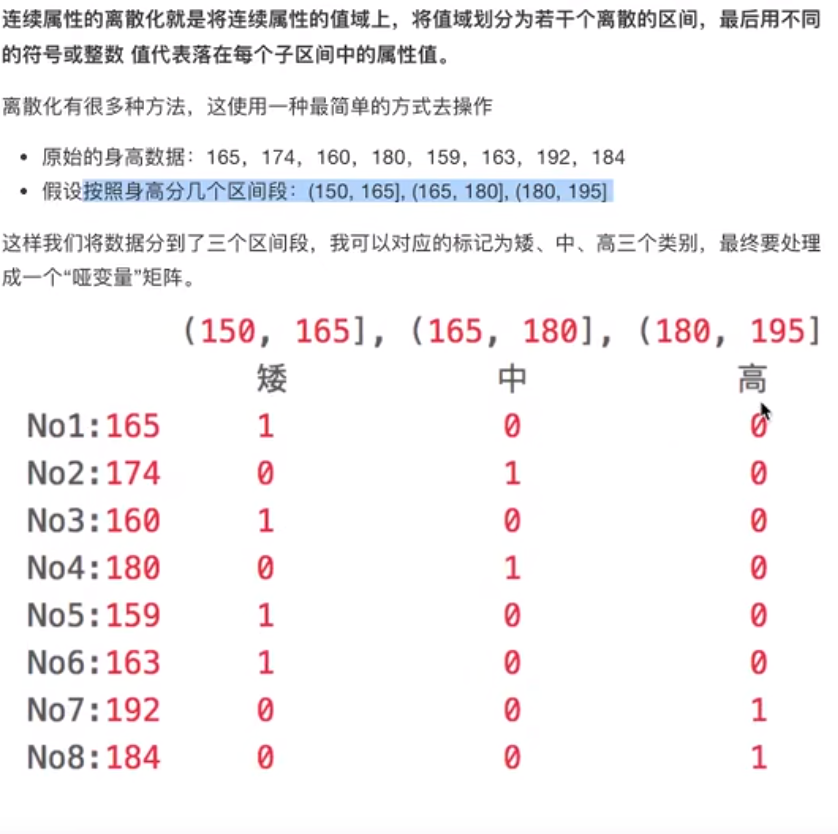
(1)分组
自动分组 sr = pd.qcut(data, bins)#bins代表的是分成的组数
自定义分组 sr = pd.cut(data, [])
(2)将分组好的结果转换成 one-hot 编码(哑变量)
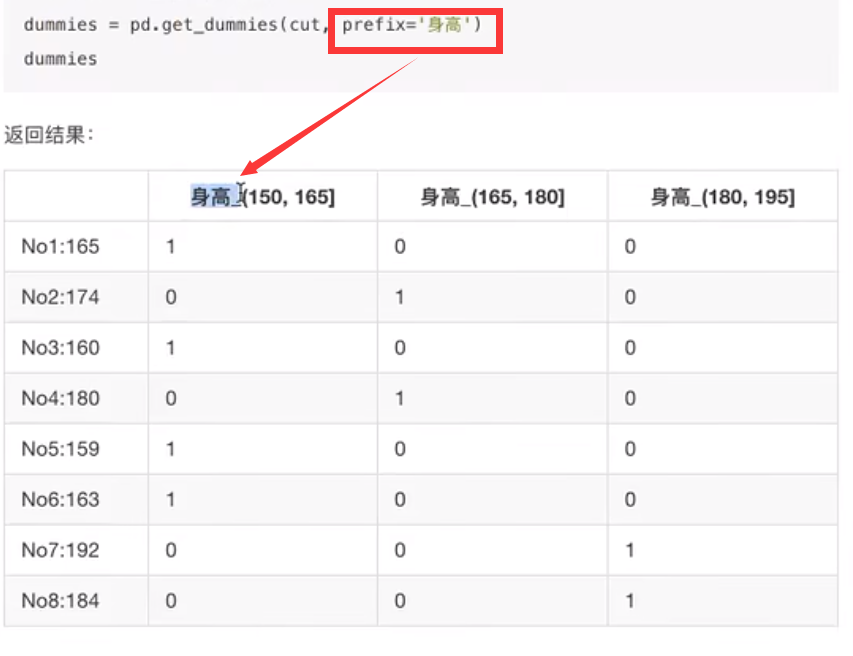
pd.get_dummies(sr, prefix=)
准备数据
# 1)准备数据
data = pd.Series([165,174,160,180,159,163,192,184], index=['No1:165', 'No2:174','No3:160', 'No4:180', 'No5:159', 'No6:163', 'No7:192', 'No8:184'])
分组、自动分组
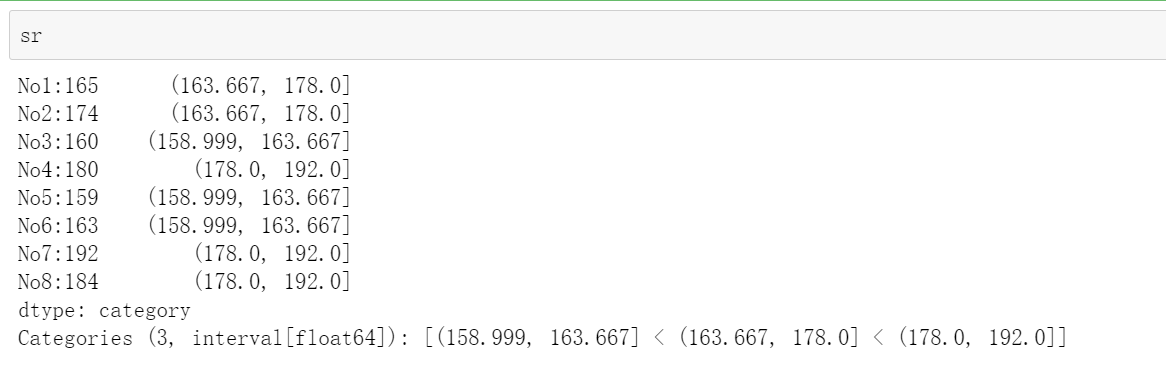
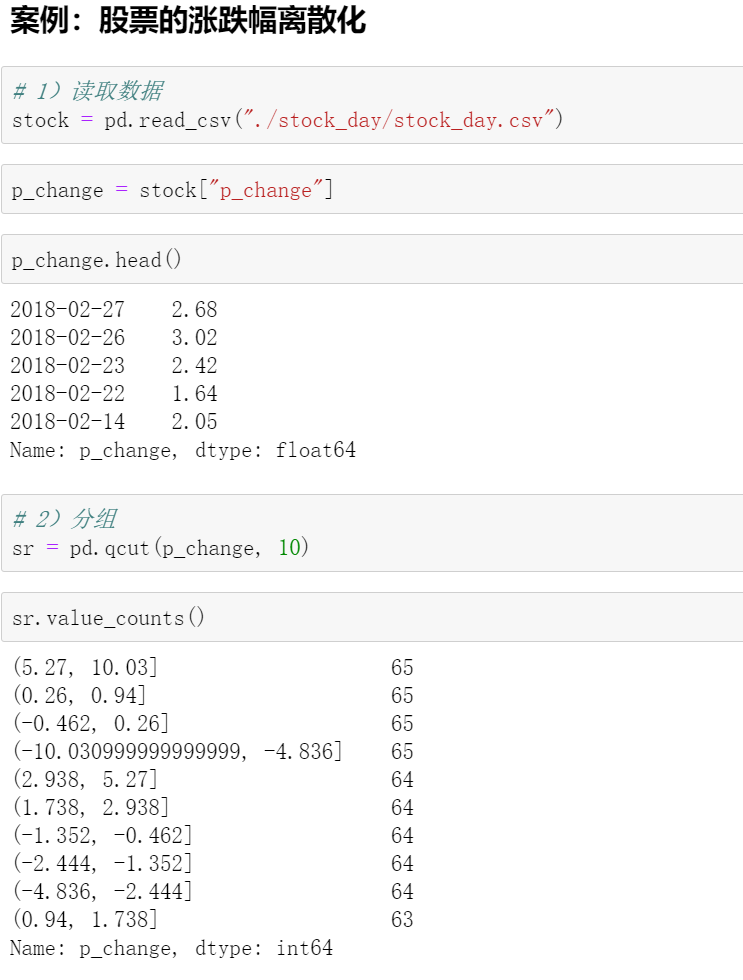
sr = pd.qcut(data, 3)
# 2)分组
# 自动分组
sr = pd.qcut(data, 3)
sr
sr.value_count()

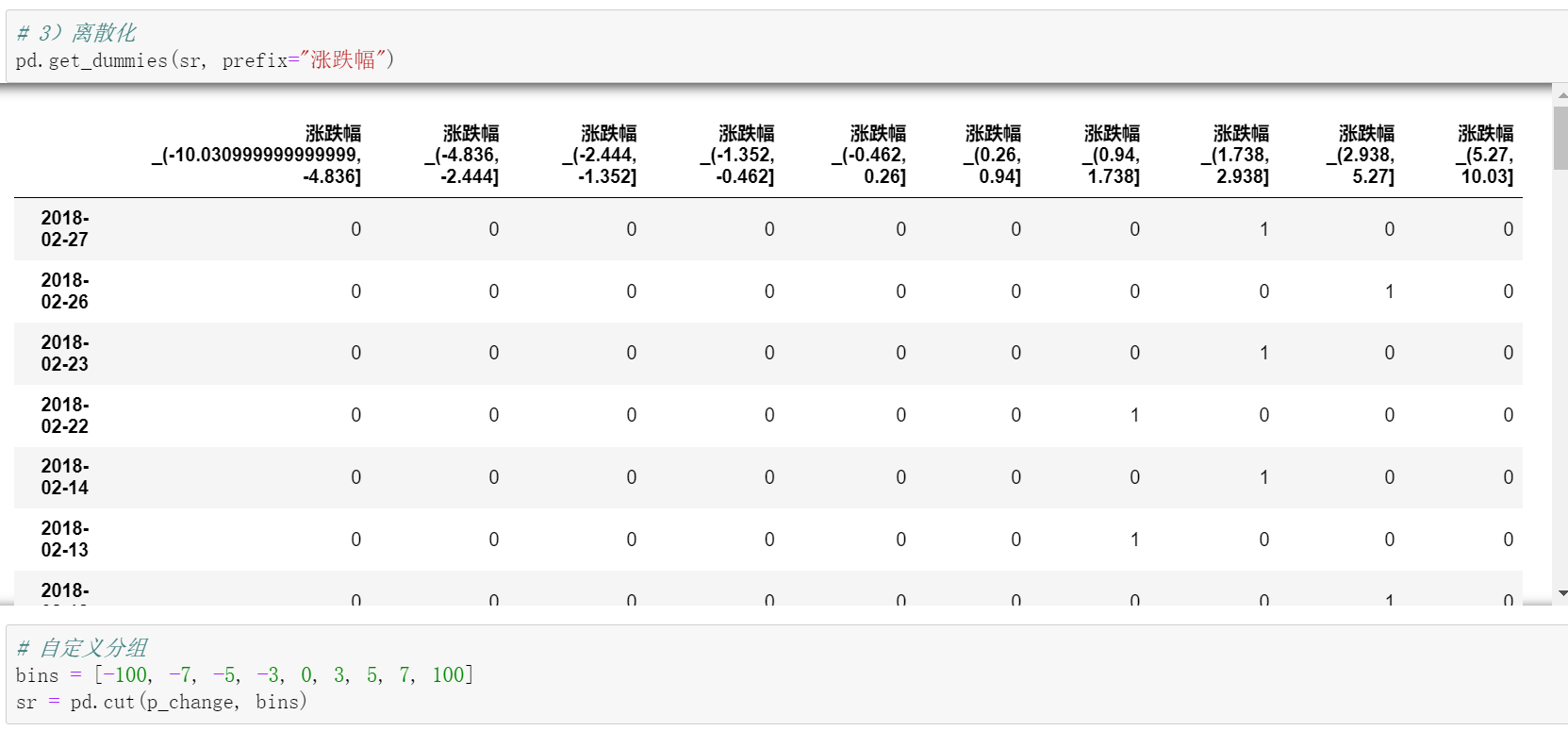
3)转换成one-hot编码
pd.get_dummies(sr, prefix="height")
#转换成one-hot编码
pd.get_dummies(sr, prefix="height")
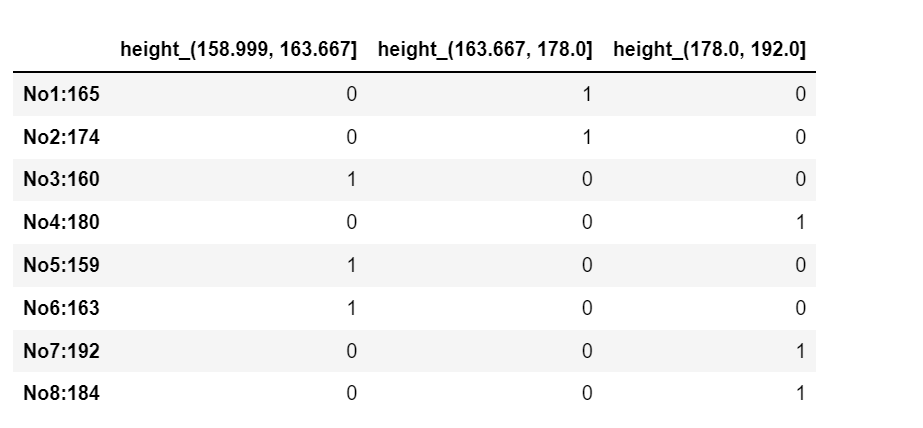
上面是分成三组
自定义分组
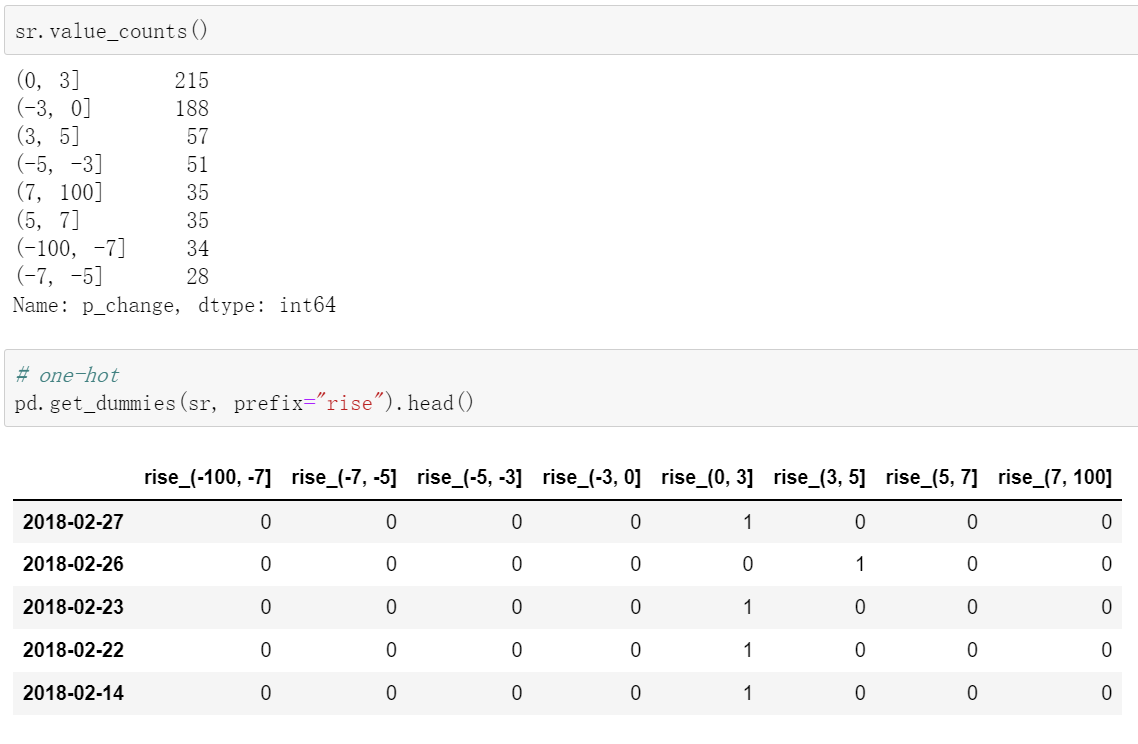
bins = []
sr = pd.cut(data, bins)
# 自定义分组
bins = [150, 165, 180, 195]
sr = pd.cut(data, bins)

# 3)转换成one-hot编码
pd.get_dummies(sr, prefix="height")
实例
一个很好得处理流程:
参考
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
print(all_features)
# 数据预处理
# 若无法获得测试数据,则可根据训练数据计算均值和标准差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features, dummy_na=True)
完整代码
# coding: utf-8
# @Author : lishipu
# @File : 实战Kaggle比赛:预测房价.py
import hashlib
import os
import tarfile
import zipfile
import requests
# 下载和缓存数据集
#@save
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
def download(name, cache_dir=os.path.join('..', 'data')): #@save
"""下载一个DATA_HUB中的文件,返回本地文件名"""
assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"
url, sha1_hash = DATA_HUB[name]
os.makedirs(cache_dir, exist_ok=True)
fname = os.path.join(cache_dir, url.split('/')[-1])
if os.path.exists(fname):
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
if sha1.hexdigest() == sha1_hash:
return fname # 命中缓存
print(f'正在从{url}下载{fname}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
return fname
def download_extract(name, folder=None): #@save
"""下载并解压zip/tar文件"""
fname = download(name)
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, '只有zip/tar文件可以被解压缩'
fp.extractall(base_dir)
return os.path.join(base_dir, folder) if folder else data_dir
def download_all(): #@save
"""下载DATA_HUB中的所有文件"""
for name in DATA_HUB:
download(name)
#访问和读取数据集
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
DATA_HUB['kaggle_house_train'] = ( #@save
DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce')
DATA_HUB['kaggle_house_test'] = ( #@save
DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
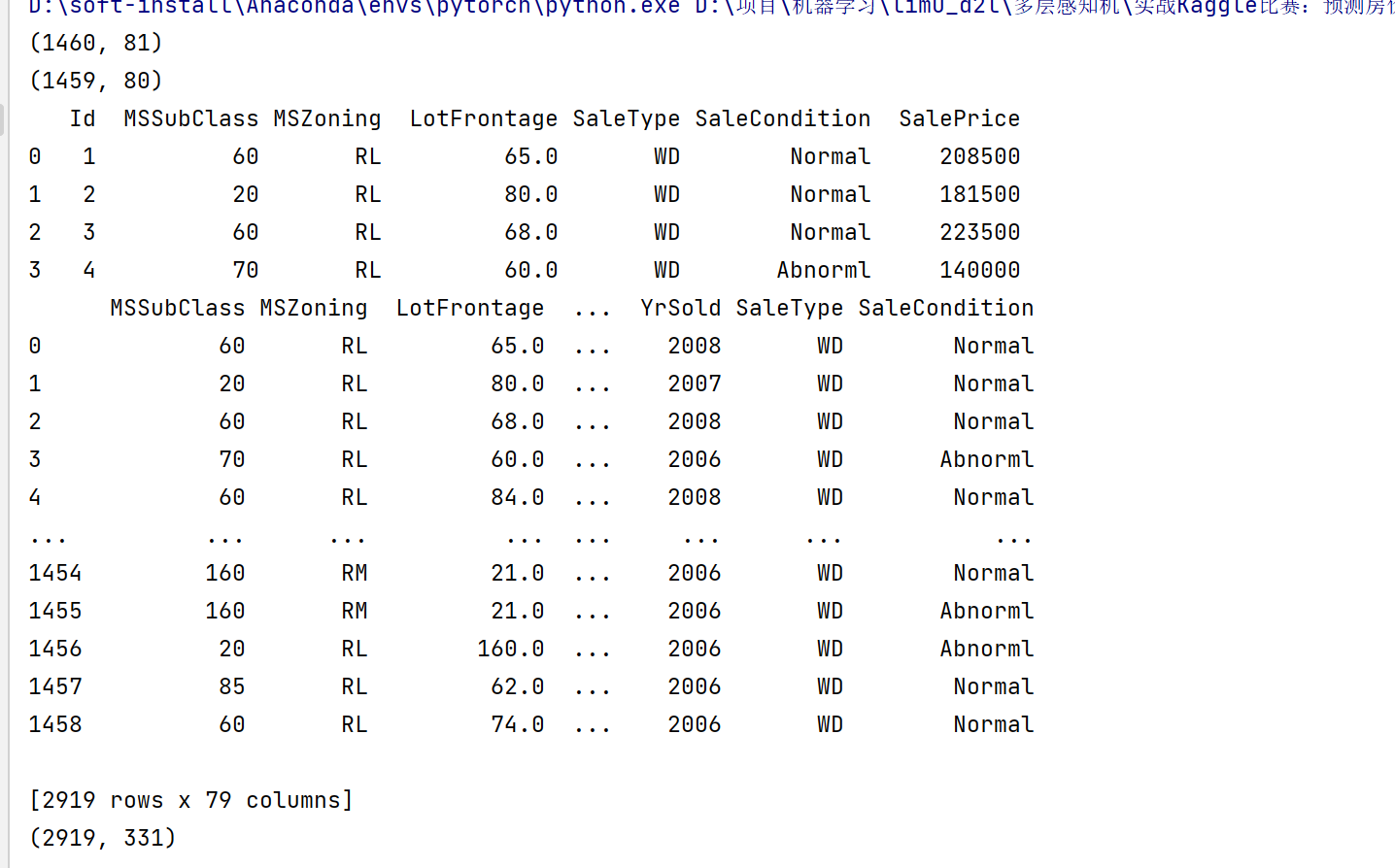
print(train_data.shape)
print(test_data.shape)
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
print(all_features)
# 数据预处理
# 若无法获得测试数据,则可根据训练数据计算均值和标准差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features, dummy_na=True)
print(all_features.shape)
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号