康复训练一
1 二分
查找第一个大于等于B的数
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long ll;
const int maxn=1e6+100;
int a[maxn];
int main(){
int n;
cin>>n;
for(int i=1;i<=n;i++){
cin>>a[i];
}
int b;
cin>>b;
int ans=-1,l=1,r=n;//第一个大于等于a[mid]的数
while(r>=l){
int mid=(r+l)/2;
if(a[mid]>=b){
r=mid-1;
ans=a[mid];
}
else{
l=mid+1;
}
}
cout<<ans<<endl;
}
或者有个库函数就是lower_bound()和upper_bound()
例如这个lower_bound(a+1,a+n+1,x)-a;这个是数组下标是从1开始到n,然后返回的是a[i]数组中大于等于x的第一个数的下标,或者lower_bound(a,a+n,x)-a,这个是数组下标是从0开始到n-1,然后也是返回的是a[i]数组中大于等于x的第一个数的下标,这个upper_bound(a+1,a+n+1,x)-a这个是大于a[i]的第一个数的下标
2 最长公共子序列
dp的方法
#include<iostream>
#include<algorithm>
#include<cstring>
#include<string.h>
using namespace std;
const int maxn=100;
int dp[maxn][maxn];
char a[maxn],b[maxn];
int main(){
scanf("%s",a+1);
scanf("%s",b+1);
int n=strlen(a+1),m=strlen(b+1);
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
if(a[i]==b[j]){
dp[i][j]=dp[i-1][j-1]+1;
}
else{
dp[i][j]=max(dp[i-1][j],dp[i][j-1]);
}
}
}
cout<<dp[n][m]<<endl;
}
3 二进制枚举
点击查看代码
#pragma GCC optimize(2)
#include<cstdio>
#include<iostream>
#include<algorithm>
#include<map>
#include <math.h>
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
inline int read()
{
int x=0,f=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){x=x*10+ch-'0';ch=getchar();}
return x*f;
}
const int INF=0x3f3f3f3f;
const int maxn=1e5+100;
int a[maxn];
int main(){
int n;
cin>>n;
for(int i=0;i<n;i++){
cin>>a[i];
}
for(int i=0;i<(1<<n);i++){
for(int j=0;j<n;j++){
if(i&(1<<j)){
//(i>>j)&1
printf("%d ",a[j]);
}
}
printf("\n");
}
}
4 01背包
传送门或者这个
dp[i][j]代表的是前i个背包,容量是j的时候的时候的最大权值
那么对于第i个背包就有选和不选两种状态
不选:dp[i][j]=dp[i-1][j]
选:dp[i][j]=max(dp[i][j],dp[i-1][j-v[i]]+w[i])
code
#include<iostream>
#include<algorithm>
using namespace std;
int dp[1100][1101];//dp[i][j]代表的是前i个草药,用j分种最大值
int v[1011],w[1101];
int main(){
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>v[i]>>w[i];
}
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
dp[i][j]=dp[i-1][j];
if(j>=v[i])
dp[i][j]=max(dp[i][j],dp[i-1][j-v[i]]+w[i]);
}
}
cout<<dp[n][m]<<endl;
}
5 完全背包问题
传送门
问题描述
有 N 种物品和一个容量是 V 的背包,每种物品都有无限件可用。第 i 种物品的体积是 vi,价值是 wi。求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。输出最大价值。
解题思路
还是那个dp[i][j]代表的是前i个背包,容量为j的时候的最大权值
不选:dp[i][j]=dp[i-1][j]
选1个:dp[i][j]=max(dp[i][j],dp[i-1][j-1v[i]]+1w[i])
选2个:dp[i][j]=max(dp[i][j],dp[i-1][j-2v[i]]+2w[i])
.....
选k个:dp[i][j]=max(dp[i][j],dp[i-1][j-kv[i]]+kw[i])
这个可以用一个for循环
code
#include<iostream>
#include<algorithm>
using namespace std;
int dp[1101][1101];//dp[i][j]代表的是前i个草药,用j分种最大值
int v[1101],w[1101];
int main(){
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>v[i]>>w[i];
}
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
dp[i][j]=dp[i-1][j];
for(int k=1;k*v[i]<=j;k++){
dp[i][j]=max(dp[i][j],dp[i-1][j-k*v[i]]+k*w[i]);
}
}
}
cout<<dp[n][m]<<endl;
}
但是这样是超时的:所以得优化
其实这个是不用k这个循环的
只需要f[i][j] = max(f[i][j],f[i][j-v[i]]+w[i]);//完全背包问题
注意和01背包的区别
两个代码其实只有一句不同(注意下标)
f[i][j] = max(f[i][j],f[i-1][j-v[i]]+w[i]);//01背包
f[i][j] = max(f[i][j],f[i][j-v[i]]+w[i]);//完全背包问题
code
#include<iostream>
#include<algorithm>
using namespace std;
int dp[1101][1101];//dp[i][j]代表的是前i个草药,用j分种最大值
int v[1101],w[1101];
int main(){
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>v[i]>>w[i];
}
// for(int i=1;i<=n;i++){
// for(int j=1;j<=m;j++){
// dp[i][j]=dp[i-1][j];
// for(int k=1;k*v[i]<=j;k++){
// dp[i][j]=max(dp[i][j],dp[i-1][j-k*v[i]]+k*w[i]);
// }
// }
// }
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
dp[i][j] = dp[i-1][j];
if(j-v[i]>=0)
dp[i][j] = max(dp[i][j],dp[i][j-v[i]]+w[i]);
}
}
cout<<dp[n][m]<<endl;
}
6 多重背包的二进制优化
有 N 种物品和一个容量是 V 的背包。
第 i 种物品最多有 s[i] 件,每件体积是 v[i],价值是 w[i]。
求解将哪些物品装入背包,可使物品体积总和不超过背包容量,且价值总和最大。
输出最大价值。
输入格式
第一行两个整数,N,V,用空格隔开,分别表示物品种数和背包容积。
接下来有 N 行,每行三个整数 vi,wi,si,用空格隔开,分别表示第 i 种物品的体积、价值和数量。
输出格式
输出一个整数,表示最大价值。
数据范围
0<N≤1000
0<V≤2000
0<vi,wi,si≤2000
解析:
要想做这个题要知道一个前置知识,就是:一个数n,最少要多少个数才能把从1-n中的所有数表示出来;
答案是log2(n)上取整个数
每一组有:1、2、4、8、16、…、2^n 个,这些数可以表示 0 ~ 1023 中的任何数。
例如:某种物品有 200 个,打包为:1、2、4、8、16、32、64、73(用128的话会凑出256,多了)
证明:0 ~ 128-1 都能凑出来,加上73:73 ~ 200 也都能凑出来。 能表示 0 ~ 200
就用logs个物品代替原来 s 个物品,转化为 0 1 背包问题,打包的每个组作为一个物品最多只能拿一次

然后就转化为01背包了。
code
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn=1e6+100;
int v[maxn],w[maxn],s[maxn];
int dp[maxn];
int main(){
int n,m,cnt=1,v1,w1,s;
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>v1>>w1>>s;
int t=1;
while(s>=t){
v[cnt]=v1*t;
w[cnt]=w1*t;
cnt++;
s-=t;
t*=2;
}
if(s>0){
v[cnt]=v1*s;
w[cnt]=w1*s;
}
}
for(int i=1;i<=cnt;i++){
for(int j=m;j>=v[i];j--){
dp[j]=max(dp[j],dp[j-v[i]]+w[i]);
}
}
cout<<dp[m]<<endl;
}
7.二维费用背包
有 N 件物品和一个容量是 V 的背包,背包能承受的最大重量是 M。
每件物品只能用一次。体积是 vi,重量是 mi,价值是 wi。
求解将哪些物品装入背包,可使物品总体积不超过背包容量,总重量不超过背包可承受的最大重量,且价值总和最大。
输出最大价值。
输入格式
第一行三个整数,N,V,M,用空格隔开,分别表示物品件数、背包容积和背包可承受的最大重量。
接下来有 N 行,每行三个整数 vi,mi,wi,用空格隔开,分别表示第 i 件物品的体积、重量和价值。
输出格式
输出一个整数,表示最大价值。
数据范围
0<N≤1000
0<V,M≤100
0<vi,mi≤100
0<wi≤1000
输入样例
4 5 6
1 2 3
2 4 4
3 4 5
4 5 6
输出样例:
8
code
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
#define HEAP(...) priority_queue<__VA_ARGS__ >
#define heap(...) priority_queue<__VA_ARGS__,vector<__VA_ARGS__ >,greater<__VA_ARGS__ > >
template<class T> inline T min(T &x,const T &y){return x>y?y:x;}
template<class T> inline T max(T &x,const T &y){return x<y?y:x;}
ll read(){ll c = getchar(),Nig = 1,x = 0;while(!isdigit(c) && c!='-')c = getchar();if(c == '-')Nig = -1,c = getchar();while(isdigit(c))x = ((x<<1) + (x<<3)) + (c^'0'),c = getchar();return Nig*x;}
#define read read()
const ll inf = 1e18;
const int INF=0x3f3f3f3f;
const int maxn = 1e5 + 7;
const int mod = 1e9 + 7;
const int N = 1000;
int f[N][N];
int main()
{
int n,v,w;
cin>>n>>v>>w;
for(int i=1;i<=n;i++){
int a,b,c;
cin>>a>>b>>c;
for(int j=v;j>=a;j--)
for(int k=w;k>=b;k--){
f[j][k]=max(f[j][k],f[j-a][k-b]+c);
}
}
printf("%d",f[v][w]);
return 0;
}
8.并查集
链接
题目描述
如题,现在有一个并查集,你需要完成合并和查询操作。
输入格式
第一行包含两个整数 \(N,M\) ,表示共有 \(N\) 个元素和 \(M\) 个操作。
接下来 \(M\) 行,每行包含三个整数 \(Z_i,X_i,Y_i\) 。
当 \(Z_i=1\) 时,将 \(X_i\) 与 \(Y_i\) 所在的集合合并。
当 \(Z_i=2\) 时,输出 \(X_i\) 与 \(Y_i\) 是否在同一集合内,是的输出
Y ;否则输出 N 。
输出格式
对于每一个 \(Z_i=2\) 的操作,都有一行输出,每行包含一个大写字母,为 Y 或者 N 。
样例 #1
样例输入 #1
4 7
2 1 2
1 1 2
2 1 2
1 3 4
2 1 4
1 2 3
2 1 4
样例输出 #1
N
Y
N
Y
提示
对于 \(30\%\) 的数据,\(N \le 10\),\(M \le 20\)。
对于 \(70\%\) 的数据,\(N \le 100\),\(M \le 10^3\)。
对于 \(100\%\) 的数据,\(1\le N \le 10^4\),\(1\le M \le 2\times 10^5\),\(1 \le X_i, Y_i \le N\),\(Z_i \in \{ 1, 2 \}\)。
这里用到了启发式合并,就是用一个r[maxn]
code
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn=1e6+100;
int n,pre[maxn],r[maxn];
int find(int x){
if(pre[x]==x){
return pre[x];
}
else{
pre[x]=find(pre[x]);
return pre[x];
}
}
void marge(int x,int y){
int t1=find(x);
int t2=find(y);
if(t1==t2){
return ;
}
if(r[t1]>r[t2]){
pre[t2]=t1;
r[t1]+=r[t2];
}
else{
pre[t1]=t2;
r[t2]+=r[t1];
}
}
int main(){
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++){
pre[i]=i;
r[i]=1;
}
int op,x,y;
for(int i=1;i<=m;i++){
scanf("%d%d%d",&op,&x,&y);
if(op==1){
marge(x,y);
}
else{
if(find(x)==find(y)){
cout<<"Y"<<endl;
}
else{
cout<<"N"<<endl;
}
}
}
}
9.离散化+并查集
例题
数组离散化就是这个一堆数据,如果处理的时候和他的大小没有关系,只和他的相对位置有关,那么可以把这个数组离散话,这样可以把很大的数弄成比较小的n以内的
code
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn=1e6+100;
int pre[maxn],id[maxn],r[maxn];
int cnt=0;
int n;
struct node{
int ai;
int bi;
int ci;
}a[maxn];
int find(int x){
if(pre[x]==x){
return pre[x];
}
else{
pre[x]=find(pre[x]);
return pre[x];
}
}
void marge(int x,int y){
int t1=find(x);
int t2=find(y);
if(t1==t2){
return ;
}
if(r[t1]>r[t2]){
pre[t2]=t1;
r[t1]+=r[t2];
}
else{
pre[t1]=t2;
r[t2]+=r[t1];
}
}
void init(){//离散化
sort(id+1,id+cnt+1);
for(int i=1;i<=n;i++){
a[i].ai=lower_bound(id+1,id+1+cnt,a[i].ai)-id;
a[i].bi=lower_bound(id+1,id+1+cnt,a[i].bi)-id;
}
}
int main(){
int t;
cin>>t;
while(t--){
cin>>n;
cnt=0;
for(int i=1;i<=n;i++){
scanf("%d%d%d",&a[i].ai,&a[i].bi,&a[i].ci);
id[++cnt]=a[i].ai;
id[++cnt]=a[i].bi;
}
init();
for(int i=1;i<=cnt;i++){
r[i]=1;
pre[i]=i;
}
int flag=1;
for(int i=1;i<=n;i++){
if(a[i].ci==1){
marge(a[i].ai,a[i].bi);
}
}
for(int i=1;i<=n;i++){
if(a[i].ci==0){
int u=find(a[i].ai);
int v=find(a[i].bi);
if(v==u){
flag=0;
break;
}
}
}
if(flag){
printf("YES\n");
}
else{
printf("NO\n");
}
}
}
10.最小生成数
题目链接
这个有两个做法一个prime算法,一个是Kruskal
先说这个Kruskal算法这个和并查集有关,这个就是算法的思想就是先按照边从小到大排序,然后按照边权从小到大选,如果选上这个边不构成环的话,就选上,所以这个算法最主要的就是判环,这正是并查集干的活
code
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long ll;
int n,m;
const int maxn=1e6+100;
int pre[maxn],r[maxn];
struct node{
int x,y,z;
}a[maxn];
int cmp(node x,node y){
return x.z<y.z;
}
int find(int x){
if(pre[x]==x){
return pre[x];
}
return pre[x]=find(pre[x]);
}
void marge(int x,int y){
int t1=find(x);
int t2=find(y);
if(t1==t2){
return ;
}
if(r[t1]>r[t2]){
pre[t2]=t1;
r[t1]+=r[t2];
}
else{
pre[t1]=t2;
r[t2]+=r[t1];
}
}
int main(){
cin>>n>>m;
for(int i=1;i<=n;i++){
pre[i]=i;
r[i]=1;
}
for(int i=1;i<=m;i++){
cin>>a[i].x>>a[i].y>>a[i].z;
}
sort(a+1,a+m+1,cmp);
ll cnt=0,x,y,z,ans=0;
for(int i=1;i<=m;i++){
if(find(a[i].x)!=find(a[i].y)){
marge(a[i].x,a[i].y);
ans+=a[i].z;
cnt++;
}
}
if(cnt==n-1){
cout<<ans<<endl;
}
else{
cout<<"orz"<<endl;
}
}
然后就是Prim算法
Prim在稠密图中比Kruskal优,在稀疏图中比Kruskal劣。Prim是以更新过的节点的连边找最小值,Kruskal是直接将边排序。
code
#include<bits/stdc++.h>
using namespace std;
int read()
{
int x=0,f=1;char c=getchar();
while(c<'0'||c>'9'){if(c=='-') f=-1;c=getchar();}
while(c>='0'&&c<='9') x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*f;
}//快读,不理解的同学用cin代替即可
#define inf 123456789
#define maxn 5005
#define maxm 200005
struct edge
{
int v,w,next;
}e[maxm<<1];
//注意是无向图,开两倍数组
int head[maxn],dis[maxn],cnt,n,m,tot,now=1;
long long ans=0;
//已经加入最小生成树的的点到没有加入的点的最短距离,比如说1和2号节点已经加入了最小生成树,那么dis[3]就等于min(1->3,2->3)
bool vis[maxn];
//链式前向星加边
void add(int u,int v,int w)
{
e[++cnt].v=v;
e[cnt].w=w;
e[cnt].next=head[u];
head[u]=cnt;
}
int prim()
{
//先把dis数组附为极大值
for(int i=2;i<=n;++i)
{
dis[i]=inf;
}
//这里要注意重边,所以要用到min
for(int i=head[1];i;i=e[i].next)
{
dis[e[i].v]=min(dis[e[i].v],e[i].w);
}
while(++tot<n)//最小生成树边数等于点数-1
{
int minn=inf;//把minn置为极大值
vis[now]=1;//标记点已经走过
//枚举每一个没有使用的点
//找出最小值作为新边
//注意这里不是枚举now点的所有连边,而是1~n
for(int i=1;i<=n;++i)
{
if(!vis[i]&&minn>dis[i])
{
minn=dis[i];
now=i;
}
}
ans+=minn;
//枚举now的所有连边,更新dis数组
for(int i=head[now];i;i=e[i].next)
{
int v=e[i].v;
if(dis[v]>e[i].w&&!vis[v])
{
dis[v]=e[i].w;
}
}
}
return ans;
}
int main()
{
n=read(),m=read();
for(int i=1,u,v,w;i<=m;++i)
{
u=read(),v=read(),w=read();
add(u,v,w),add(v,u,w);
}
printf("%lld",prim());
return 0;
}
11.树状数组
图片出自
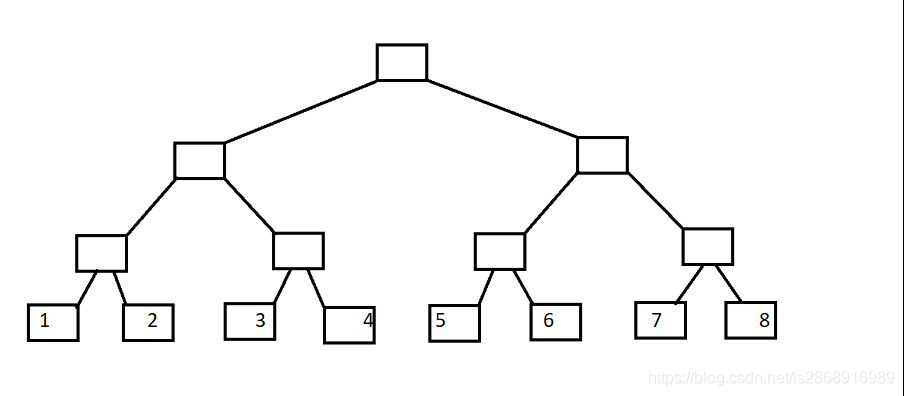
然后这个变形一下就是这样的
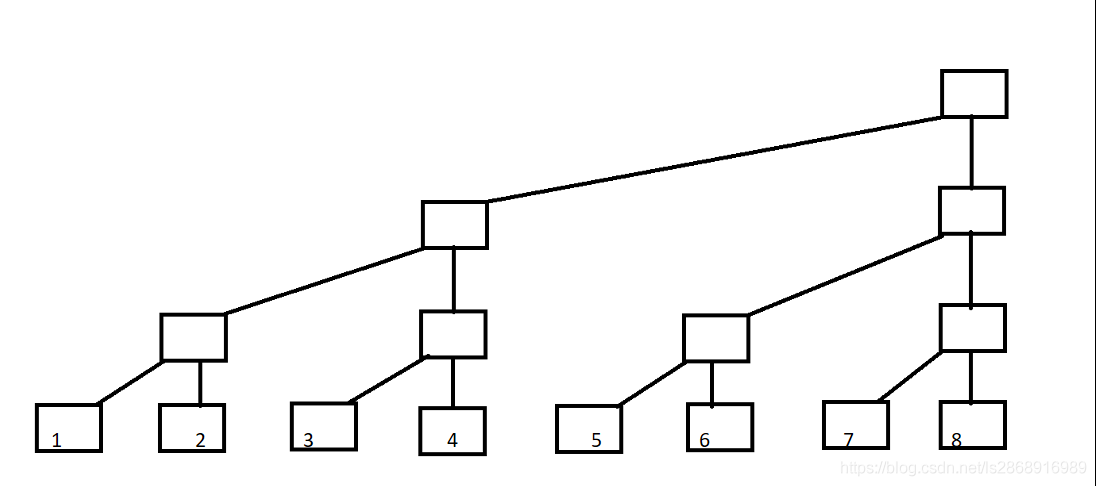
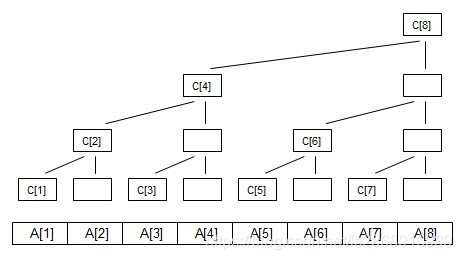
首先知道一个知识lowbit.其实lowbit(x)就是求x最低位的1;
C[i]代表子树的叶子节点的权值之和,如图可以知道:
C[1]=A[1];
C[2]=A[1]+A[2];
C[3]=A[3];
C[4]=A[1]+A[2]+A[3]+A[4];
C[5]=A[5];
C[6]=A[5]+A[6];
C[7]=A[7];
C[8]=A[1]+A[2]+A[3]+A[4]+A[5]+A[6]+A[7]+A[8];
首先是区间查询(求和):
利用C[i]数组,求A数组中前i项和,举两个栗子:
①i=7,前7项和:sum[7]=A[1]+A[2]+A[3]+A[4]+A[5]+A[6]+A[7];
而C[4]=A[1]+A[2]+A[3]+A[4];C[6]=A[5]+A[6];C[7]=A[7];可以得到:sum[7]=C[4]+C[6]+C[7]。
数组下标写成二进制:sum[(111)]=C[(100)]+C[(110)]+C[(111)];
②i=5,前5项和:sum[5]=A[1]+A[2]+A[3]+A[4]+A[5];
而C[4]=A[1]+A[2]+A[3]+A[4];C[5]=A[5];可以得到:sum[5]=C[4]+C[5];
数组下标写成二进制:sum[(101)]=C[(100)]+C[(101)];
1.单点修改,区间查询
其实这个就包含单点修改,单点查询
code
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long ll;
const int maxn=1e6+100;
int n,m;
ll a[maxn],c[maxn];
ll lowbit(ll x){
return x&-x;
}
ll add(int x,ll k){
for(int i=x;i<=n;i+=lowbit(i)){
c[i]+=k;
}
}
ll getsum(int x){
ll ans=0;
for(int i=x;i>0;i-=lowbit(i)){
ans+=c[i];
}
return ans;
}
int main(){
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>a[i];
add(i,a[i]);
}
for(int i=1;i<=m;i++){
int op,x,y;
cin>>op>>x>>y;
if(op==1){
add(x,y);
}
else{
ll ans=getsum(y)-getsum(x-1);
cout<<ans<<endl;
}
}
}
2.区间修改 单点求和
题目链接
要想学习这个就要先知道一个知识就是差分数组,就是d[i]=a[i]-a[i-1],
设数组a[]={1,6,8,5,10},那么差分数组b[]={1,5,2,-3,5}
也就是说b[i]=a[i]-a[i-1];(a[0]=0;),那么a[i]=b[1]+....+b[i];(这个很好证的)。
假如区间[2,4]都加上2的话
a数组变为a[]={1,8,10,7,10},b数组变为b={1,7,2,-3,3};
发现了没有,b数组只有b[2]和b[5]变了,因为区间[2,4]是同时加上2的,所以在区间内b[i]-b[i-1]是不变的.
所以对区间[x,y]进行修改,只用修改b[x]与b[y+1]:
b[x]=b[x]+k;b[y+1]=b[y+1]-k;
然后这个题就转化成了维护一个差分数组,然后这个区间修改,就是add(x,k),add(y+1,-k),这个单点求和就是getsum(x)
code
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long ll;
const int maxn=1e6+100;
//树状数组区间修改单点求值
int n,m;
ll a[maxn],c[maxn];
ll lowbit(ll x){
return x&-x;
}
void add(int x,ll k){
for(int i=x;i<=n;i+=lowbit(i)){
c[i]+=k;
}
}
ll getsum(int x){
ll ans=0;
for(int i=x;i>0;i-=lowbit(i)){
ans+=c[i];
}
return ans;
}
int main(){
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>a[i];
add(i,a[i]-a[i-1]);//维护一个差分数组
}
int op,x,y;
ll k;
for(int i=1;i<=m;i++){
cin>>op>>x;
if(op==1){
cin>>y>>k;
add(x,k);
add(y+1,-k);
}
else{
ll ans=getsum(x);
cout<<ans<<endl;
}
}
}
3.区间修改,区间求和
这个比较难说,建议用线段树
code
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long ll;
const int maxn=1e6+100;
//树状数组区间加和区间查询
ll sum1[maxn];
ll sum2[maxn];
ll a[maxn];
int n,m;
ll lowbit(int x){
return x&-x;
}
void add(int x,ll k){
for(int i=x;i<=n;i+=lowbit(i)){
sum1[i]+=k;
sum2[i]+=1ll*k*(x-1);
}
}
ll getsum(int x){
ll ans=0;
for(int i=x;i>0;i-=lowbit(i)){
ans+=x*sum1[i]-sum2[i];
}
return ans;
}
int main(){
cin>>n>>m;
for(int i=1;i<=n;i++){
scanf("%lld",&a[i]);
add(i,a[i]-a[i-1]);
}
char str[100];
ll l,r;
ll k;
for(int i=1;i<=m;i++){
scanf("%s",str);
if(str[0]=='C'){
scanf("%lld%lld%lld",&l,&r,&k);
add(l,k);
add(r+1,-k);
}
else{
scanf("%lld%lld",&l,&r);
printf("%lld\n",getsum(r)-getsum(l-1));
}
}
}
12.链式前向星建图
首先先看个代码
code1
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int maxn=1e6+100;
struct node{
int to,next;
}edge[maxn];
int head[maxn];
int cnt=0;
void add(int u,int v){
edge[++cnt].to=v;
edge[cnt].next=head[u];
head[u]=cnt;
}
int main(){
//memset(head,-1,sizeof(head));//这个是把edge[cnt].to=v,head[u]=cnt++,然后
//遍历的时候就是i=head[u];~i;i=edge[i].next
int n,m;
cin>>n>>m;
for(int i=1;i<=m;i++){
int x,y;
cin>>x>>y;
add(x,y);
}
for(int i=1;i<=n;i++){
for(int j=head[i];j;j=edge[j].next){
cout<<edge[j].to<<" ";
}
cout<<endl;
}
}
/*
5 7
1 2
2 3
3 4
1 3
4 1
1 5
4 5
*/
code2
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int maxn=1e6+100;
struct node{
int to,next;
}edge[maxn];
int head[maxn];
int cnt=0;
void add(int u,int v){
edge[cnt].to=v;
edge[cnt].next=head[u];
head[u]=cnt++;
}
int main(){
memset(head,-1,sizeof(head));//这个是把edge[cnt].to=v,head[u]=cnt++,然后
//遍历的时候就是i=head[u];~i;i=edge[i].next
int n,m;
cin>>n>>m;
for(int i=1;i<=m;i++){
int x,y;
cin>>x>>y;
add(x,y);
}
for(int i=1;i<=n;i++){
for(int j=head[i];~j;j=edge[j].next){
cout<<edge[j].to<<" ";
}
cout<<endl;
}
}
/*
5 7
1 2
2 3
3 4
1 3
4 1
1 5
4 5
*/
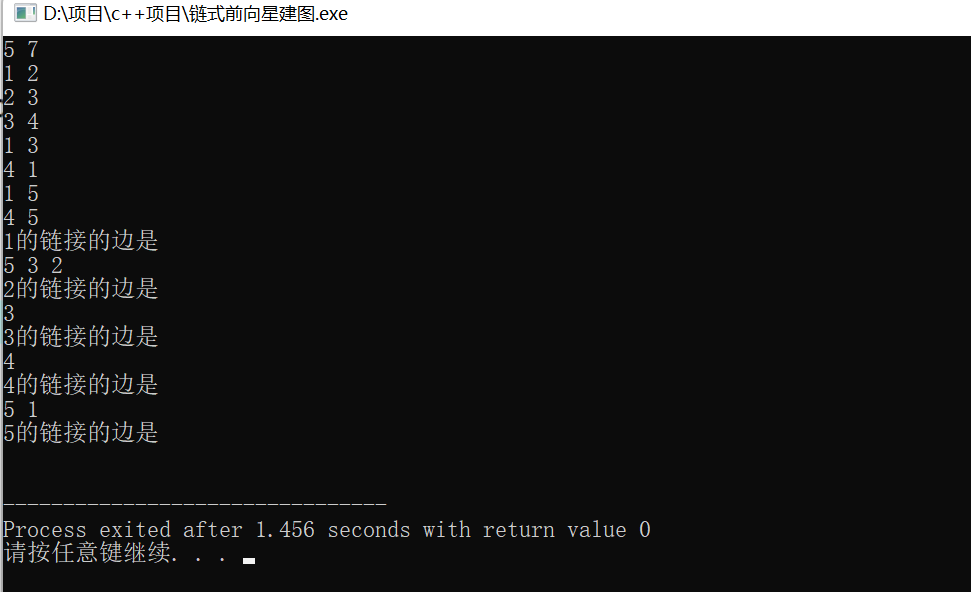
例如这个图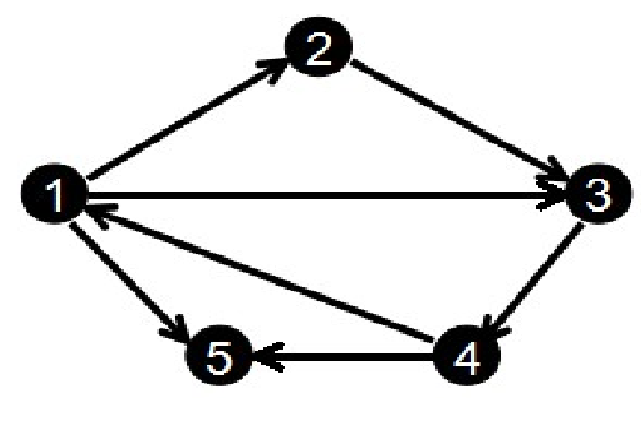
这个图里面的边是这样的
1 2
2 3
3 4
1 3
4 1
1 5
4 5
然后这执行的是这样的
这是添加边的代码:
void add(int u,int v){
edge[cnt].to=v;
edge[cnt].next=head[u];
head[u]=cnt++;
}
这个是cnt初始化为0,head数组需要初始化一下为-1,然后遍历的时候~i
其实这个存边的时候是倒着存的,例如这个
1 2
1 3
1 4
可以模拟一下
edge[0].to=2,edge[cnt].next=-1,head[1]=0,cnt=1;
edge[1].to=3,edge[1].next=0,head[1]=1,cnt=2
edge[2].to=4,edge[2].next=1,head[1]=2,cnt=3
13.最短路
1.dijkstra
题目链接
code
#include<iostream>
#include<algorithm>
#include<stdio.h>
#include<cstdio>
using namespace std;
typedef long long ll;
const int maxn=1e6+100;
ll qpow(ll a,ll b){
ll ans=1;
while(b){
if(b&1){
ans=(ans*a);
}
a=a*a;
b/=2;
}
return ans;
}
ll dis[maxn];
int vis[maxn],head[maxn];
int n,m,s,cnt=0;
struct node{
int to,next;
ll w;
}edge[maxn];
void add(int u,int v,int w){
edge[++cnt].to=v;
edge[cnt].w=w;
edge[cnt].next=head[u];
head[u]=cnt;
}
void dijkstra(int u){
for(int i=1;i<=n;i++){
dis[i]=0x3f3f3f3f;
}
dis[u]=0;
while(1){
int minn=0x3f3f3f3f;
int k=-1;
for(int i=1;i<=n;i++){
if(!vis[i]&&dis[i]<minn){
k=i;
minn=dis[i];
}
}
vis[k]=1;
if(k==-1){
break;
}
for(int i=head[k];i;i=edge[i].next){
int v=edge[i].to;
if(dis[v]>dis[k]+edge[i].w){
dis[v]=dis[k]+edge[i].w;
}
}
}
}
int main(){
cin>>n>>m>>s;
int x,y,w;
for(int i=1;i<=m;i++){
cin>>x>>y>>w;
add(x,y,w);
}
dijkstra(s);
for(int i=1;i<=n;i++){
if(dis[i]==0x3f3f3f3f){
printf("%lld ",qpow(2,31)-1);
}
else{
printf("%lld ",dis[i]);
}
}
cout<<endl;
}
2.spfa
spfa 是Bellman-Ford的队列的实现方法
它的原理是对图进行 |v|-1次松弛操作,得到所有可能的最短路径。
贝尔曼-福特算法与迪科斯彻算法类似,都以松弛操作为基础,即估计的最短路径值渐渐地被更加准确的值替代,直至得到最优解。在两个算法中,计算时每个边之间的估计距离值都比真实值大,并且被新找到路径的最小长度替代。 然而,迪科斯彻算法以贪心法选取未被处理的具有最小权值的节点,然后对其的出边进行松弛操作;而贝尔曼-福特算法简单地对所有边进行松弛操作,共|v|-1 次,其中 是图的点的数量。在重复地计算中,已计算得到正确的距离的边的数量不断增加,直到所有边都计算得到了正确的路径。这样的策略使得贝尔曼-福特算法比迪科斯彻算法适用于更多种类的输入。
code
#include<iostream>
#include<algorithm>
#include<queue>
#include<cstring>
#include<cstdio>
using namespace std;
typedef long long ll;
const int maxn=1e6+100;
struct node{
int to,next;
int w;
}edge[maxn];
int dis[maxn];
int vis[maxn],head[maxn],cnt=0;
int n,m,s;
void add(int u,int v,ll w){
edge[++cnt].to=v;
edge[cnt].w=w;
edge[cnt].next=head[u];
head[u]=cnt;
}
ll qpow(ll a,ll b){
ll ans=1;
while(b){
if(b&1){
ans=(ans*a);
}
a=(a*a);
b/=2;
}
return ans;
}
void spfa(int s){
memset(dis,0x3f,sizeof(dis));
memset(vis,0,sizeof(vis));
queue<int> q;
q.push(s);
dis[s]=0;
vis[s]=1;
while(!q.empty()){
int u=q.front();
q.pop();
vis[u]=0;//这里注意了
for(int i=head[u];i;i=edge[i].next){
int v=edge[i].to;
int w=edge[i].w;
if(dis[v]>dis[u]+w){
dis[v]=dis[u]+w;
if(!vis[v]){
vis[v]=1;
q.push(v);
}
}
}
}
}
int main(){
cin>>n>>m>>s;
int x,y;
ll z;
for(int i=1;i<=m;i++){
cin>>x>>y>>z;
add(x,y,z);
}
spfa(s);
for(int i=1;i<=n;i++){
if(dis[i]==0x3f3f3f3f){
printf("%lld ",qpow(2,31)-1);
}
else{
cout<<dis[i]<<" ";
}
}
}
14.大根堆和小根堆
大根堆:priority_queue<int,vector
小根堆:priority_queue<int,vector
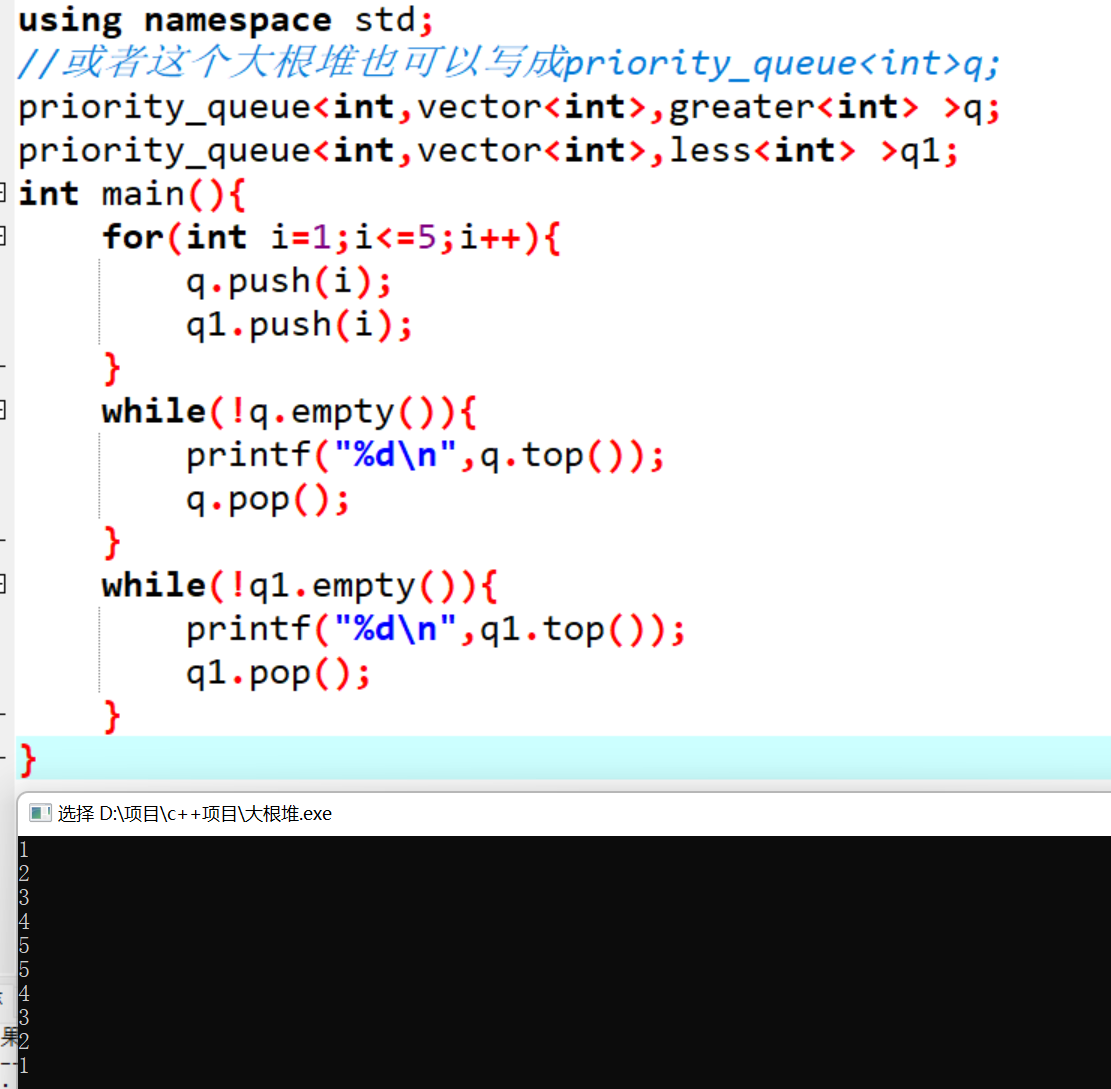
测试代码
#include<iostream>
#include<algorithm>
#include<queue>
using namespace std;
//或者这个大根堆也可以写成priority_queue<int>q;
priority_queue<int,vector<int>,greater<int> >q;
priority_queue<int,vector<int>,less<int> >q1;
int main(){
for(int i=1;i<=5;i++){
q.push(i);
q1.push(i);
}
while(!q.empty()){
printf("%d\n",q.top());
q.pop();
}
while(!q1.empty()){
printf("%d\n",q1.top());
q1.pop();
}
}
15.字典树
这个字典树很好理解的感觉就是一个如果是满的话,就是一个满的26叉树,其他的不多说了,这个是学习博客
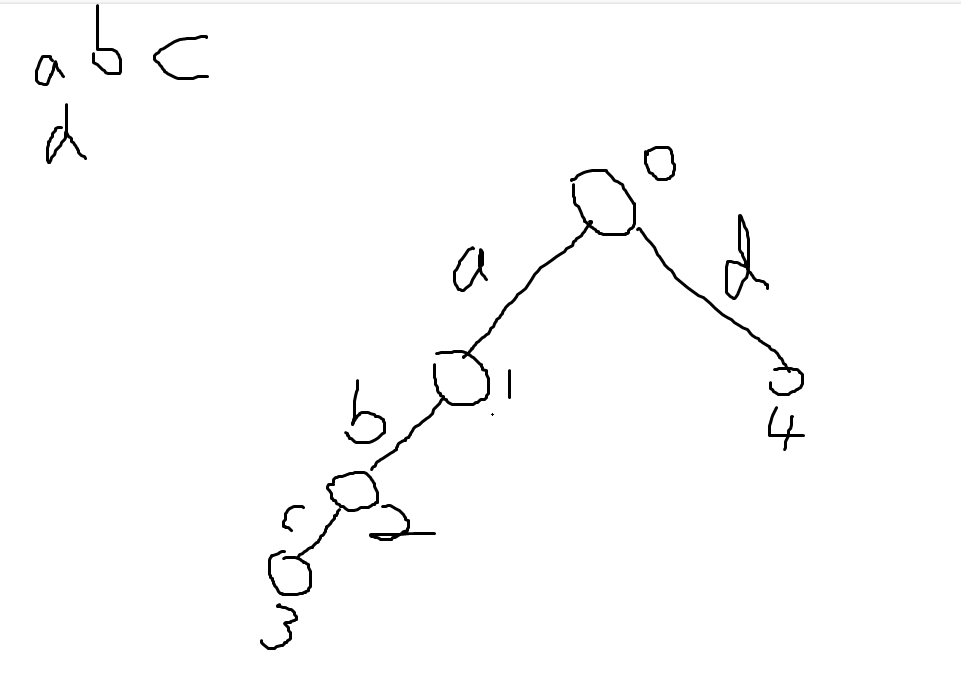
主要有一个地方,就是这个一开始cnt=0;而建树的时候则是=++cnt;
void insert(char *s){
int len=strlen(s);
int p=0;
for(int i=0;i<len;i++){
int ch=getnum(s[i]);
if(!tree[p][ch]){
tree[p][ch]=++tot;//这里就是++cnt,并且一开始cnt=0
}
p=tree[p][ch];
cnt[p]++;
}
}
这是为什么呢?一开始我也有这个疑问,画一下图就知道了
例题1:
给定 \(n\) 个模式串 \(s_1, s_2, \dots, s_n\) 和 \(q\) 次询问,每次询问给定一个文本串 \(t_i\),请回答 \(s_1 \sim s_n\) 中有多少个字符串 \(s_j\) 满足 \(t_i\) 是 \(s_j\) 的前缀。
一个字符串 \(t\) 是 \(s\) 的前缀当且仅当从 \(s\) 的末尾删去若干个(可以为 0 个)连续的字符后与 \(t\) 相同。
输入的字符串大小敏感。例如,字符串 Fusu 和字符串 fusu 不同。
输入格式
本题单测试点内有多组测试数据。
输入的第一行是一个整数,表示数据组数 \(T\)。
对于每组数据,格式如下:
第一行是两个整数,分别表示模式串的个数 \(n\) 和询问的个数 \(q\)。
接下来 \(n\) 行,每行一个字符串,表示一个模式串。
接下来 \(q\) 行,每行一个字符串,表示一次询问。
输出格式
按照输入的顺序依次输出各测试数据的答案。
对于每次询问,输出一行一个整数表示答案。
样例 #1
样例输入 #1
3
3 3
fusufusu
fusu
anguei
fusu
anguei
kkksc
5 2
fusu
Fusu
AFakeFusu
afakefusu
fusuisnotfake
Fusu
fusu
1 1
998244353
9
样例输出 #1
2
1
0
1
2
1
提示
数据规模与约定
对于全部的测试点,保证 \(1 \leq T, n, q\leq 10^5\),且输入字符串的总长度不超过 \(3 \times 10^6\)。输入的字符串只含大小写字母和数字,且不含空串。
code
#include<iostream>
#include<algorithm>
#include<cstring>
#include<cstdio>
using namespace std;
const int maxn=3000005+100;
char str[maxn];
int getnum(char x){
if(x>='A'&&x<='Z')
return x-'A';
else if(x>='a'&&x<='z')
return x-'a'+26;
else
return x-'0'+52;
}
int cnt[maxn],tree[maxn][100],tot=0,vis[maxn];
void insert(char *s){
int len=strlen(s);
int p=0;
for(int i=0;i<len;i++){
int ch=getnum(s[i]);
if(!tree[p][ch]){
tree[p][ch]=++tot;
}
p=tree[p][ch];
cnt[p]++;
}
vis[p]=1;//说明这个是一个单词的结尾
}
int check(char *s){
int len=strlen(s);
int p=0;
for(int i=0;i<len;i++){
int ch=getnum(s[i]);
if(!tree[p][ch]){
return 0;
}
p=tree[p][ch];
}
return cnt[p];
}
int main(){
int t;
cin>>t;
while(t--){
for(int i=0;i<=tot;i++){
for(int j=0;j<=100;j++){
tree[i][j]=0;
}
}
for(int i=0;i<=tot;i++){
cnt[i]=0;
}
tot=0;
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++){
scanf("%s",str);
insert(str);
}
while(m--){
scanf("%s",str);
printf("%d\n",check(str));
}
}
}
字典树变种:01字典树
这个题就是给你一个数组,然后任选两个数,使得这两个数的异或最大
code
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int maxn=4e6+100;
int a[maxn];
int t[maxn][3];
int cnt[maxn];
int idx;
void insert(int x){
int root=0;
for(int i=30;i>=0;i--){
int p=(x>>i)&1;
if(!t[root][p]){
t[root][p]=++idx;
}
root=t[root][p];
cnt[root]++;
}
}
int query(int x){
int ans=0;
int root=0;
for(int i=30;i>=0;i--){
int p=(x>>i)&1;
if(t[root][!p]){
ans+=(1<<i);
root=t[root][!p];
}
else{
root=t[root][p];
}
}
return ans;
}
int main(){
int n;
cin>>n;
for(int i=1;i<=n;i++){
cin>>a[i];
}
int ans=0;
insert(a[1]);
for(int i=2;i<=n;i++){
ans=max(ans,query(a[i]));
insert(a[i]);
}
printf("%d",ans);
}
16. 分块
这个分块,就是把数组分块,这样如果查询的跨过好几个块,然后就可以按照块处理,就是加入给你一个[x,y]的区间加和,然后就可以分成[x,块x的右边界],[块z], [块z+1]... [块y的左边界,y],然后这些不足一个块的左右边界可以直接访问,中间可以直接按照块来访问
void build(){
block=sqrt(n);//一个块的长度
tot=n/block;//一共多少个块
if(n%block){
tot++;//一共有tot个块
}
for(int i=1;i<=n;i++){//i属于那个块
belong[i]=(i-1)/block+1;
}
for(int i=1;i<=tot;i++){
l[i]=(i-1)*block+1;//第i个块的左右边界
r[i]=i*block;
}
r[tot]=n;
}
然后这个加和操作
void change(int x,int y,int k){
if(belong[x]==belong[y]){//如果是一个块里面的直接加
for(int i=x;i<=y;i++){
a[i]+=k;
}
}
else{
for(int i=x;i<=r[belong[x]];i++){//第一个边界的左边
a[i]+=k;
}
for(int i=belong[x]+1;i<belong[y];i++){//可以说这个是精髓,中间的直接用标记
lazy[i]+=k;
}
for(int i=l[belong[y]];i<=y;i++){//最后面的
a[i]+=k;
}
}
}
1.区间加和单点求值
例题区间加和单点求值
题目描述
给出一个长为 n 的数列,以及 n 个操作,操作涉及区间加法,单点查值。
输入格式
第一行输入一个数字 n。
第二行输入 n 个数字,第 i 个数字为 ai,以空格隔开。
接下来输入 n 行询问,每行输入四个数字opt、l、r、c,以空格隔开。
若 opt = 0,表示将位于 [l, r] 的之间的数字都加 c。
若 opt = 1,表示询问 ar 的值(l 和 c 忽略)。
输出格式
对于每次询问,输出一行一个数字表示答案。
样例
输入
4
1 2 2 3
0 1 3 1
1 0 1 0
0 1 2 2
1 0 2 0
输出
2
5
数据范围与提示
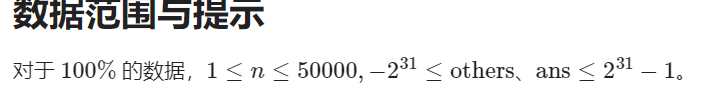
code
#include<iostream>
#include<algorithm>
#include<math.h>
using namespace std;
const int maxn=1e5+100;
int l[maxn],r[maxn],lazy[maxn],a[maxn];
int belong[maxn];
int n,block,tot,op,x,y,k;
void build(){
block=sqrt(n);//一个块的长度
tot=n/block;//一共多少个块
if(n%block){
tot++;//一共有tot个块
}
for(int i=1;i<=n;i++){//i属于那个块
belong[i]=(i-1)/block+1;
}
for(int i=1;i<=tot;i++){
l[i]=(i-1)*block+1;//第i个块的左右边界
r[i]=i*block;
}
r[tot]=n;
}
void change(int x,int y,int k){
if(belong[x]==belong[y]){//如果是一个块里面的直接加
for(int i=x;i<=y;i++){
a[i]+=k;
}
}
else{
for(int i=x;i<=r[belong[x]];i++){//第一个边界的左边
a[i]+=k;
}
for(int i=belong[x]+1;i<belong[y];i++){//可以说这个是精髓,中间的直接用标记
lazy[i]+=k;
}
for(int i=l[belong[y]];i<=y;i++){//最后面的
a[i]+=k;
}
}
}
int main(){
cin>>n;
for(int i=1;i<=n;i++){
cin>>a[i];
}
build();
for(int i=1;i<=n;i++){
scanf("%d%d%d%d",&op,&x,&y,&k);
if(op==0){
change(x,y,k);
}
else{
printf("%d\n",a[y]+lazy[belong[y]]);
}
}
}
2.区间加法,区间求和
这个题就是维护一个sum[],和一个lazy,整块中的用sum,剩下的不是整块的用lazy
链接
题目描述
给出一个长为 n 的数列,以及 n 个操作,操作涉及区间加法,区间求和。
输入格式
第一行输入一个数字 n。
第二行输入 n 个数字,第 i 个数字为 ai,以空格隔开。
接下来输入 n 行询问,每行输入四个数字 opt、l、r、c,以空格隔开。
若 opt = 0,表示将位于 [l, r] 的之间的数字都加 c。
若 opt = 1,表示询问位于 [l, r] 的所有数字的和 mod (c+1)。
code
#include<iostream>
#include<algorithm>
#include<math.h>
using namespace std;
typedef long long ll;
const int maxn=1e5+100;
ll l[maxn],r[maxn],belong[maxn],lazy[maxn];
ll sum[maxn];
ll a[maxn];
int block,tot,x,y,op;
ll k;
int n;
void build(){
block=sqrt(n);
tot=n/block;
if(n%block){
tot++;
}
for(int i=1;i<=n;i++){
belong[i]=(i-1)/block+1;
}
for(int i=1;i<=tot;i++){
l[i]=(i-1)*block+1;
r[i]=i*block;
}
r[tot]=n;
for(int i=1;i<=tot;i++){
for(int j=l[i];j<=r[i];j++){
sum[i]+=a[j];
}
}
}
void add(int x,int y,ll k){
if(belong[x]==belong[y]){
for(int i=x;i<=y;i++){
a[i]+=k;
sum[belong[x]]+=k;
}
}
else{
for(int i=x;i<=r[belong[x]];i++){
a[i]+=k;
sum[belong[x]]+=k;
}
for(int i=l[belong[y]];i<=y;i++){
a[i]+=k;
sum[belong[y]]+=k;
}
for(int i=belong[x]+1;i<belong[y];i++){
lazy[i]+=k;
sum[i]+=1ll*(r[i]-l[i]+1)*k;
}
}
}
ll query(int x,int y,ll mod){
ll ans=0;
if(belong[x]==belong[y]){
for(int i=x;i<=y;i++){
ans=(ans+a[i]+lazy[belong[x]])%mod;
}
}
else{
for(int i=x;i<=r[belong[x]];i++){
ans=(ans+a[i]+lazy[belong[x]])%mod;
}
for(int i=l[belong[y]];i<=y;i++){
ans=(ans+a[i]+lazy[belong[y]])%mod;
}
for(int i=belong[x]+1;i<belong[y];i++){
// ans=(ans+sum[i]+(r[i]-l[i]+1)*lazy[i])%mod;
ans+=(sum[i])%mod;
}
}
return ans%mod;
}
int main(){
cin>>n;
for(int i=1;i<=n;i++){
scanf("%lld",&a[i]);
}
build();
for(int i=1;i<=n;i++){
scanf("%d%d%d%lld",&op,&x,&y,&k);
if(op==0){
add(x,y,k);
}
else{
printf("%lld\n",query(x,y,k+1));
}
}
}
17.线段树
1.区间修改,区间求和
这个可能会有些疑问:
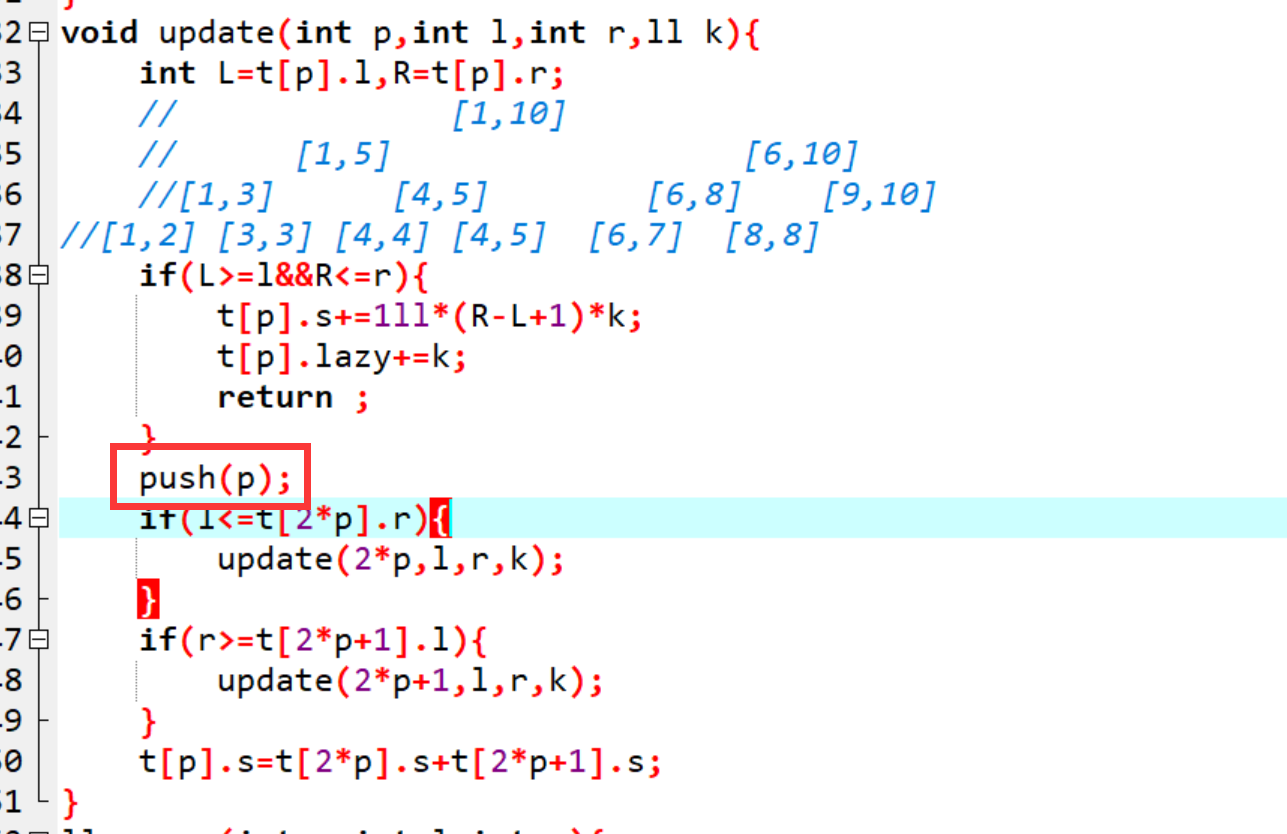
这个地方有一个push(p),这是因为举个例子吧
// [1,10]
// [1,5] [6,10]
//[1,3] [4,5] [6,8] [9,10]
//[1,2] [3,3] [4,4] [4,5] [6,7] [8,8] [9] [10]
加入第一次修改[1,8],第二次修改[1,7]
第二次修改[1,7]的时候就会看到[6,8]的lazy不为零,得下传
code
#include<iostream>
#include<algorithm>
#include<cstdio>
using namespace std;
const int maxn=1e6+100;
typedef long long ll;
struct node{
int l,r;
ll s,lazy;
}t[maxn];
int a[maxn];
int n,m;
void build(int p,int l,int r){
t[p].l=l;
t[p].r=r;
if(l==r){
t[p].s=a[l];
return ;
}
int mid=(l+r)/2;
build(p*2,l,mid);
build(p*2+1,mid+1,r);
t[p].s=t[2*p].s+t[2*p+1].s;
}
void push(int p){
t[2*p].lazy+=t[p].lazy;
t[2*p].s+=(t[2*p].r-t[2*p].l+1)*t[p].lazy;
t[2*p+1].lazy+=t[p].lazy;
t[2*p+1].s+=(t[2*p+1].r-t[2*p+1].l+1)*t[p].lazy;
t[p].lazy=0;
}
void update(int p,int l,int r,ll k){
int L=t[p].l,R=t[p].r;
// [1,10]
// [1,5] [6,10]
//[1,3] [4,5] [6,8] [9,10]
//[1,2] [3,3] [4,4] [4,5] [6,7] [8,8]
if(L>=l&&R<=r){
t[p].s+=1ll*(R-L+1)*k;
t[p].lazy+=k;
return ;
}
push(p);
if(l<=t[2*p].r){
update(2*p,l,r,k);
}
if(r>=t[2*p+1].l){
update(2*p+1,l,r,k);
}
t[p].s=t[2*p].s+t[2*p+1].s;
}
ll query(int p,int l,int r){
ll ans=0;
int L=t[p].l,R=t[p].r;
if(L>r||l>R){
return 0;
}
if(L>=l&&R<=r){
return t[p].s;
}
int mid=(t[p].l+t[p].r)/2;
push(p);
if(l<=mid){
ans+=query(2*p,l,r);
}
if(r>mid){
ans+=query(2*p+1,l,r);
}
return ans;
}
int main(){
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>a[i];
}
build(1,1,n);
int op;
int l,r;
ll k;
while(m--){
scanf("%d%d%d",&op,&l,&r);
if(op==1){
scanf("%lld",&k);
update(1,l,r,k);
}
else{
ll ans=query(1,l,r);
printf("%lld\n",ans);
}
}
}
18.最长上升子序列
这个就是用二分优化成nlogn
code
#include<cstdio>
#include<iostream>
#include<algorithm>
#include<map>
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
inline int read()
{
int x=0,f=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){x=x*10+ch-'0';ch=getchar();}
return x*f;
}
const int maxn=1e6;
int n,t;
ll a[maxn];
ll s[maxn];
void inint(){
cin>>n;
for(int i=1;i<=n;i++){
cin>>a[i];
}
}
ll b_seach(ll x){
ll pos=-1;
ll l=1,r=t;
while(r>=l){
int mid=(l+r)/2;
if(s[mid]>=x){
r=mid-1;
pos=mid;
}
else{
l=mid+1;
}
}
return pos;
}
int main(){
inint();
s[1]=a[1];
t=1;
for(int i=2;i<=n;i++){
if(a[i]>s[t]){
s[++t]=a[i];
}
else{
int pos=b_seach(a[i]);
s[pos]=a[i];
}
}
printf("%lld",t);
}
