《Kubernetes权威指南》读书笔记
概述
kubernetes是基于容器技术的分布式架构方案,是一个完备的分布式系统支撑平台,是一个容器编排引擎。
kubenrnetes的优点:
- 方便开发复杂系统,可以把更多精力放在业务开发上。
- 全面拥抱微服务架构。
- 随时随地可以把系统整体搬迁到公有云。
- 弹性扩容机制可以让我应对突发流量,在公有云上接借用务,减少公司硬件投入。
- 横向扩容能力很强,添加Node就可以。
资源对象
我认为所谓资源对象就是用户可以通过yaml文件进行部署的对象,Kubernetes中的资源对象有:Pod、Service、Deployment、Job、RC、HorizontalPodAutoscaler(HPA)、Role、Ingress、EndPoint等
Pod
简述
Pod是kubernetes最小的调度单元。每一个Pod都有一个被称为根容器的pause容器和其他的业务容器。结构如下图所示:

为什么Kubernetes需要设计出Pod这种全新的模型?
- 在一组容器都作为一个单元的情况下,我们难以对整体简单地进行判断及有效地控制。
- Pod里多个业务容器共享Pause容器地IP,共享Pause容器挂载地Volume,简化了密切关联地业务容器之间地通信和文件共享问题。
Pod可以分为:
- 静态Pod
不存放到etcd中,而是存放在某个具体的Node上的一个具体的文件中,并且只在这个Node上运行。master不能删除它,只能由它所处的Node上手动删除。 - 普通Pod
放在etcd中,会被Master调度到某个Node上进行绑定,随后会被Kubelet进程实例化一组相关的Docker容器并启动。
Pod、容器和主机节点的关系如下图所示:

配置管理
Kubernetes提供了一种统一的集群配置管理方案——ConfigMap。ConfigMap以键值对的形式保存在kubernetes系统中,既可以用于表示一个变量的值,也可以用于表示一个完整配置文件的内容。
ConfigMap供容器使用的典型用法:
- 生成为容器内的环境变量。
实际上就是在ConfigMap保存配置信息,在容器的yaml中指定ConfigMap,容器启动后就能获取其配置内容。 - 设置容器启动命令的启动参数。
- 以Volume的形式挂载为容器内部的文件或目录。
就是在ConfigMap保存一个完整的文件,容器的yaml中指定ConfigMap及其存放路径,容器启动后就能在指定路径下获取整个文件。
可以通过YAML配置文件或者直接使用kubectl create configmap命令行的方式来创建。
ConfigMap的限制条件:
- 必须在Pod之前创建。
- 可以定义为属于某个Namespace,只有处于相同Namespace中的Pod可以引用它。
- kubelet只支持可以被API Server管理的Pod使用ConfigMap,静态Pod不能用。
- 对ConfigMap进行挂载的时候,容器内部只能挂载为目录,不能为文件。
容器内获取Pod信息
如何在容器内部获取外部的Pod信息,是通过Downward API实现的。它通过两种方式将Pod信息注入容器内部。
- 环境变量,用于单个变量。
- Volume挂载,将数组类信息生成文件挂载到容器内部。
Downward API的应用场景:
在某个集群中,需要实现一个服务注册的功能,也就是每个容器的所承载的服务需要被其他调用者发现,所以,可以在容器内部写一个预先启动脚本,通过Downward API获取容器的自身名称和IP,然后将这些信息写到注册中心去。
生命周期和重启策略
Pod的状态分为以下几种:
- Pending
已经创建了Pod,但是其内部还有容器没有创建。 - Running
Pod内部的所有容器都已经创建,只有由一个容器还处于运行状态或者重启状态。 - Succeeed
Pod内所有容器均已经成功执行并且退出,不会再重启。 - Failed
Pod内所有容器都退出,但至少有一个为退出失败状态。 - Unknown
由于某种原因不能获取该Pod的状态,可能是网络问题。
Pod的重启策略包括:
- Always:当容器失效,kubelet自动重启该容器。
- OnFailure:当容器终止运行且退出码不为0,由kubelet自动重启。
- Never:不论容器的状态如何,kubelet都不会重启该容器。
触发重启间隔:
kubelet自动重启失效容器的时间间隔以sync-frequency乘以2n来计算,例如1、2、4、8,最长延时5分钟,在成功重启容器的10分钟后重置该事件。
每种控制器对Pod的重启策略要求如下:
- RC和DaemonSet:必须设置为Always,需要保证这俩玩意持续运行。
- Job:OnFailure或者Never,确保容器执行完成后不再重启。
- kubelet:在Pod失效时自动重启它。
健康和服务可用性检查
Kubernetes通过两类探针来检查Pod的健康状况,kubelet定期执行这两类探针来诊断容器的健康状态:
- LivenessProbe:用于判断容器是否处于Running状态,如果不是,kubelet就会杀掉该容器给i,并根据重启策略做相应的处理。如果容器不包含该探针,那么kubelet就会默认返回值都是success。
- ReadinessProbe:用于判断容器是否启动完成,容器服务是否可用(Ready)。如果该探针检测到失败,则Pod的状态将被修改,将会从服务可用列表中剔除。
在配置Pod的yaml文件中可以添加探针参数,探针具有三种实现方式:
- ExecAction:在容器内部执行一个命令,该命令返回码为0表示容器健康。
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表示容器健康。
- HTTPGetAction:通过容器的IP地址和端口号以及路径调用HTTP GET方法,如果状态码大于200且小于等于400,表示容器装填健康。
对于使用每种探针,都需要设置两个参数:
- initialDelaySeconds:启动后进行首次检测的等待时间。
- timeoutSeconds:检测指令发送后的超时等待时间。
Pod Readiness Gates:
ReadinessProbe可能无法满足一些复杂的服务可用性状态的判断。所以引入Pod Readiness Gates。
通过该机制,用户可以将自定义的ReadinessProbe探测方式设置到Pod上,帮助kubernetes设置Pod何时到达服务可用状态。其流程就是由外部服务器来判断服务的状态,用户提供一个外部服务接口来向kubenetes反馈Pod相应的状态。
调度
在实际的生产环境中,我们很少直接创建一个Pod进行使用,大多数情况下都是通过RC、Deployment、DaemonSet、Job等控制器完成一组Pod的创建、调度以及生命周期的控制。下面对基本的调度方式进行介绍。
1.Deployment 或 RC 全自动调度
Deployment 或 RC可以自动部署容器的多个副本,以及持续监控和维持副本的数量。
2.NodeSelector定向调度
首先在节点上打上标签,在yaml中的NodeSelector属性中添加目标节点的标签,Pod只能被调用到具有标签的Node上。
3.Node亲和性调度
用于替换NodeSelector,目前有两种亲和性表达:
- 必须满足指定规则才能调度Pod到指定Node上,和NodeSelector很像。
- 强调优先满足指定规则,调度器才会尝试将Pod调度到优先满足的Node,并不强求。
4.Pod亲和与互斥调度
让用户从另一个角度控制了Pod可以运行的节点。也是通过标签进行设置。
5.污点和容忍
污点和容忍需要配合使用。在节点上设置污点标签,除非Pod配置了相应的容忍,否则Pod可能无法被调度到有污点的节点上。
污点也有软限制和硬限制,如果是硬限制,那么Pod无法被部署到这个污点节点。
常见用例:
- 独占节点:通过强制污点的设置,给一些应用打上容忍,这样可以让这些应用独占这批节点。
- 具有特殊硬件设备的节点。
- 定义Pod驱逐行为,以应对节点故障。没有设置容忍的Pod会被驱逐,只是了容忍时间的节点会在指定时间后被驱逐。
6.Pod优先级调度
为了提高Node资源的利用率,让所有负载的总量大于集群可以提供的资源,这样在资源不足的时候,可以剔除优先级低的服务。
7.在每个Node上都调度一个Pod
也就是DaemonSet,这种用法的需求有:在每个Node上都运行一个存储进程、日志采集程序或者性能监控程序。
8.批处理调度
通过Job资源对象来定义并启动一个批处理任务,主有有几种模式:
- 一个Job对象对应一个待处理任务。
- Job启动固定个Pod,然后去消费一个任务队列。
- Job动态启动数量不固定的Pod去消费任务队列。
- 静态方式分配任务,而不是队列模式。
Job可以分为三种:
- Job只启动一个Pod串行执行,只有Pod异常,才会重新启动Pod,Pod执行结束,Job就结束。
- Job启动多个Pod并行执行,正常结束的Pod满足一定个数,Job才结束。
- Job启动多个Pod并行执行,只要有一个正常结束,Job就结束。
9.定时任务:
新型Job,Cron Job。顾名思义,就是执行一段时间就结束的Job。
10.自定义调度器
需要自己边界调度器脚本。
升级和回滚
升级
当集群中的服务需要升级,我们就需要停止服务的所有Pod,并下载替换新的Pod,如果集群规模很大,我们就需要通过滚动升级的方式来保持服务性能和可用性。
所谓滚动升级,就是不会将所有Pod一次性全给升级了,而是每次升级一部分,其他部分还是可以正常提供服务的,至少还是有可用的Pod存在。
在yaml中的spec.strategy中可以指定Pod的升级策略,滚动升级还可配置具体的每次同时升级的比例。也可以不采用滚动升级。
回滚
我们可以将Pod回滚到从前的旧版本。
扩缩容
在实际生产中,我们会遇到因为资源紧张需要缩容,业务增多需要扩容的情况。可用通过Deployment的Scale机制来完成这些工作。
扩容操作提供了手动和自动的两种方式:
- 手动模式:可以通过kubectl scale命令或RESTful 接口对Deployment进行Pod数量进行设置。
- 自动模式:需要用户根据性能指标或者自定义业务指标,并指定Pod的数量范围,系统自动在这个范围内更具性能指标的变化进行调整容量。
HPA控制器:
用于实现基于CPU使用率等性能指标进行自动扩缩容的功能。其工作原理就是通过kubernetes中某个Metrics Server持续采集Pod的性能指标数据,然后反馈给HPA,HPA根据当前的副本和目标副本的偏移,调整Pod的数量。

HorizontalPodAutoscaler:
意思是Pod横向自动扩容,通过分析RC控制的所有Pod的负载变化情况,确定是否需要调整Pod的数量。
kubernetes通过HorizontalPodAutoscaler资源对象提供给用户来定义扩缩容的规则。现在有v1和v2两个版本,v1仅支持基于CPU使用率的自动扩容,v2支持任意指标的自动扩容。
Service
是Kubernetes核心的资源对象,每个Service其实就是微服务架构中的微服务。Service可以为一组具有相同功能的容器应用提供一个统一的入口地址,并将请求进行负载分后到后端的各个容器应用上,Service与后端的Pod副本集群式通过Label Selector进行匹配对接的。
Pod、RC与Service的逻辑关系如图所示。

其实我们可以直接通过IP和端口访问Pod,但是如果Pod崩了重启之后,IP可能会发生改变,而通过Service来访问Pod就能避免这个问题。
Endpoints
当我们在Service中添加标签选择器时,系统会给Service自动创建一个和这个Service同名的Endpoints资源对象,用于标识访问Service时获取的Pod位置。
如果我们内部需要访问外部的服务,可以创建一个不带标签选择器的Service,然后手动床创建一个和Service同名的Endpoints,用于指向实际的外部后端访问地址。

均衡负载
Service可以通过变迁选择器匹配多个后端Pod,然后通过均衡负载机制来将请求转发到不同的Pod上。
Kubernetes提供了两种负载分发策略:
- RoundRobin:轮询模式,轮询将请求转发到各个Pod上。
- SessionAffinity:基于客户端IP地址进行会话保持的模式,即第1次将某个客户端发起的请求转发到了某个Pod,那么之后相同的客户端发送的请求都会被发到这个Pod上。
Headless Service
当我们想要自定义的负载均衡策略,那么就可以通过这个方式实现,即Service设置ClusterIP属性为None,然后只通过标签选择器将后端的Pod列表返回给调用的客户端,然后客户端就可以自行决定Pod的访问。
外部访问Service或Pod
Pod和Service都是kubernetes集群内部的虚拟概念,所以集群外的客户端无法通过虚拟IP访问Service或者Pod,下面介绍几种访问方式。
1.将容器应用的端口映射到物理机。
这里又分为两中情况:
- 通过设置容器级别的hostPort属性,将容器应用的端口号映射到物理机上。
- 通过设置Pod级别的hostNetwork=true,该Pod所有的容器端口都将被直接映射到物理机上。
2.将Service的端口号映射到物理机。
- 通过nodePort映射到物理机,同时设置Service的类型为NodePort。
- 通过设置LoadBalancer映射到云服务商提供的LoadBalancer地址。
DNS
作为服务发现机制的基本功能,在集群内需要通过服务吗对服务进行访问,就需要一个集群范围内的DNS服务器来完成从服务名到ClusterIP的解析。
从Kubernetes1.11开始,集群的DNS服务由CoreDNS提供。高性能、插件式、易扩展。
CoreDNS总体架构如图所示。

Ingress
是kubernetes的一种资源对象,用于将不同的URL的访问请求转发到后端不同的Service,实现HTTP层的业务路由机制。Kubernetes使用了一个Ingress策略定义和一个绝体的Ingress Controller,两者结合并实现了一个完整的Ingress负载均衡器。
Ingress的工作原理如下图所示,感觉就像是做了一个RequestMapping,检测不同的路径,然后转发到不同的后端上。

Ingress的策略配置:
- 转发到单个后端服务上。
- 同一域名下,不同URL路径被转发到不同的服务上。
- 不同域名被转发到不同的服务上。
- 不适用域名的转发规则。就是直接用IP端口。
Ingress的TLS安全设置
为了Ingress提供HTTPS的安全访问,可以给Ingress中的域名进行TLS安全证书设置。步骤如下:
- 创建自签名的密钥和SSL证书文件;
- 将证书保存到Kubernetes的一个Secret资源对象上;
- 将该Secret对象设置到Ingress中。
核心组件
Kubernetes结构如下图所示。

API Server
Kubernetes API Server的核心功能是提供Kubernetes各类资源对象的增删改查以及HTTP Rest接口,成为集群内各个模块的数据交互和通信的中心,是整个系统的数据总线和数据中心。功能如下:
- 集群管理的API入口。
- 资源配额控制的入口。
- 提供了完备的集群安全机制。
Kubernetes API Server通过一个名为kube-apiserver的进程提供服务,该进程运行在Master节点上。该进程默认在本机端口的8080提供REST服务。同时可以启动HTTPS安全端口6443来启动安全机制。
通过命令行工具kubectl来与Kubernetes API Server交互的时候,也是通过REST调用。
API Server是决定Kubernetes集群整体性能的关键因素,设计者通过以下方式来保证其性能:
- API Server拥有大量高效的底层代码,使用协程+队列的轻量级高性能并发代码。
- 不同List接口结合异步Watch接口,不断解决了集群中各种资源对象性能同步问题,也提升了集群实时响应各种请求的灵敏度。
- 采用高性能的etcd数据库而非传统的关系型数据库,解决了数据的可靠性问题和数据访问层的性能。
API Server的架构
- API层:主要以REST方式提供各种API接口。
- 访问控制层:当客户端访问API接口时,该层负责对用户进行鉴权。
- 注册表层:Kubernetes把所有的资源对象都保存到了注册表中,针对注册表中的各种资源都定义了:资源对象的类型、如何创建资源对象、如何转换资源对象的不同版本。
- etcd数据库:用于持久化存储kubernetes资源对象的KV数据库。
Controller Manager
Controller Manager作为集群内部的自动化管理控制中心,负责集群内的Node、Pod副本、EndPoint、Namespace、服务账号、资源定额等管理,当某个Node宕机了,Controller Manager会及时发现故障并自动化修复,确保集群始终处于预期的工作状态。
Controller Manager内部包含了很多子控制器,每个控制器负责Controller Manager一部分的功能,例如节点控制、Pod副本数量控制之类的。
Scheduler
Scheduler在整个系统中承担了承上启下的重要功能,承上是指负责接收Controller Manager创建新的Pod,部署到合适的Node,启下是指部署工作完成之后,目标Node上的Kubelet服务进程接管后继工作,负责Pod生命周期。
Scheduler当前提供的默认调度流程分为以下两步:
- 预选调度过程,即遍历所有目标Node,筛选出符合要求的Node。
- 确定最优的节点。
Scheduler具有多种预选策略包括:
- NoDiskConflict
- PodFitsResources
- PodSelectorMatches
- podFitsHost
- CheckNodeLabelPresence
- CheckSerciceAffinity
- PodFitsPorts
Scheduler中的优选策略包括:
- LeastRequestedPriority
- CalculateNodeLabelPriority
- BalancedResourceAllocation
kubelet
集群中每个Node都会启动一个kubelet服务进程,该进程用于处理Master下发到本节点的任务,管理Pod以及Pod中的容器。每个kubelet都会在APIServer中注册节点自身的信息,定期向Master汇报节点资源和使用情况。
上面提到的探针也是可以由kubelet调用,用户获取容器的健康状况。
kubelet通过cAdvisor来获取其所在节点及容器的数据。cAdvisor自动查找节点上所有容器的性能数据,并在Node上的4194暴露一个简单的UI界面。
kube-proxy
集群中每个Node上都会运行一个kube-proxy服务进程,他是Service的透明代理兼均衡负载器,其核心功能是将某个Service的访问转发到后端的多个Pod上。

从kubernetes1.8开始,词用了IPVS(IP Virtual Server)模式,用于路由规则的配置。相比iptables,IPVS具有如下优势:
- 为大型集群提供了更好的扩展性和性能。采用哈希表的数据结构,更高效。
- 支持更复杂的负载均衡算法。
- 支持服务器健康检查和连接重试。
- 可以动态修改ipset的集合。
安全
Kubernetes通过一系列的机制来实现集群的安全控制,其中包括API Server的认证授权、准入控制机制及保护敏感信息的Secret机制。集群的安全性目标有:
- 保证容器与其所在宿主机的隔离。
- 限制容器给基础设施或其它容器带来干扰。
- 最小权限原则,每个组件只执行它的授权行为。
- 明确组件边界划分。
- 划分普通用户和管理员角色。在必要的时候将管理员权限给普通用户。
- 允许拥有Secret的应用在集群中允许。
API Server认证
Kubernetes中所有资源访问和修改都是通过API Server的REST接口来实现的,所以,集群安全的关键在于如何识别认证客户端的身份,以及随后访问的权限的授权。
集群提供了三种级别的客户端认证方式:
- 最严格的HTTPS证书认证
基于CA根证书签名的双向数字证书认证方式。其实就是HTTPS中SSL协议认证和数据加密的过程。不同的是,这里是双向的,也就是客户端也要有自己的证书,让服务端来验证客户端的身份。 - HTTP Token认证
通过一个Token来是被合法用户,就是用一个很长的特殊编码方式并且很难被模仿的字符串Token来表明客户端的身份。默认采用的就是这个方式。 - HTTP Base认证
通过用户名+密码的方式。
API Server授权
在用户认证之后,需要对用户执行一个授权流程,通过一个授权策略来决定一个API调用是否合法。目前支持一下几种授权策略:
- AlwaysDeny:拒绝所有请求,一般用于测试。
- AlwaysAllow:接收所有请求,Kubernetes默认配置。
- ABAC:(Attribute Based Access Control):基于属性的访问控制,表示使用用户配置的授权规则对用户请求匹配和控制。
- Webhook:通过调用外部REST服务对用户进行授权,将授权职责交给外部服务器。
- RBAC(Role Based Access Control):基于角色的访问控制。这个比较复杂,通过Role资源对象创建出角色以及该角色的权限,然后通过RoleBinding资源对象将用户名和Role进程绑定,这样就能让指定的用户具有角色以及对应的权限。
- Node:是一种专用模式,用于对kubelet发出的请求进行访问控制。
Admission Control
在完成授权之后,客户端的调用请求还需要准入控制的一个准入控制链的层层把关,才能获得成功的响应。
准入控制配备了一个准入控制器的插件列表,里面有三十多个插件,对请求一层层地检测,对请求的合法性等等进程控制,用户也可以自定义控制规则,然后写入插件列表。
Service Account
这是一种账号,是给运行在Pod中的进程使用的,用于给进程提供身份证明。当Pod内部需要访问API Server的时候,就需要用到这个账号进行认证。
其原理是利用一种类似于HTTP Token的方式——Service Account Auth。
Kubernets之所以要创建两套独立的账号系统:
- User账号是给人用的,Service Account是给Pod里的进程使用的,面向对象不同。
- User账号是全局的,Service Account属于某个Namespace。
- User账号是与后端的数据库同步的,使用比较复杂,而Service Account的使用是轻量级的。
- Service Account具有隔离性。
Secret
Secret是Kubernetes的一种资源对象,用于保管私密数据,比如密码、Token等,同时,将数据放在Secret里面,比直接发放在Pod或者Docker Image种更安全,也便于使用和分发。
Secret创建以后有三种方式使用:
- 在创建Pod时,通过Pod指定ServiceAccount来自动使用Secret。
- 通过挂载该Secret到Pod来使用。
- 在Docker镜像下载时使用,通过指定Pod的spc.ImagePullSecrets来引用。
PodSecurityPolicy
为了精确控制Pod对资源的使用方式,可以通过PodSecurityPolicy资源对象进行Pod安全策略管理。
PodSecurityPolicy对象种可以设置各种字段来控制Pod的运行策略,例如是否允许Pod共享主机进程空间,是否允许使用卷的类型,是否允许共享主机的路径之类的。
在设置了PodSecurityPolicy策略之后,系统将对Pod和Container级别的安全设置进行校验,不满足PodSecurityPolicy安全策略的就会拒绝创建。
Pod级别可以设置的安全策略如下:
- runAsUser:容器内运行程序的用户ID。
- runAsGroup:容器内运行程序的用户组ID。
- runAsNonRoot:是否必须以非root用户运行程序。
- fsGroup:SELinux相关设置。
- seLinuxOptions:SELinux相关设置。
- SupplementalGroups:允许容器使用启它用户组ID。
- sysctls:允许调整内核参数。
Container级别也差不多。
网络
网络模型
Kubernetes网络模型设计的基础原则是:每个Pod都拥有一个独立的IP地址,并假定所有Pod都在一个可以直接连通的、扁平的网络空间中。按照这个原则抽象出来的模型被称为IP-per-Pod模型。
Docker原生的通过动态端口映射方式实现的多节点访问模式的问题:
- Docker原生网络的动态端口映射会引入端口管理的复杂性。
- 访问者看到的IP地址和端口与服务提供者实际绑定的不同(因为NAT的缘故)。
- 导致标准的DNS名字解析服务也不适用,服务注册和发现机制也复杂了,因为Pod自身很难知道自己对外暴露的IP。
Kubernetes对集群网络有如下要求:
- 所有容器都可以在不用NAT的方式下同别的容器通信。
- 所有节点都可以在不用NAT的方式下同所有容器通信。
- 容器的地址和外部看到的是一致的。
网络实现
Kubernets网络主要解决以下问题:
- 容器到容器之间的直接通信。
也就是Pod内部的通信,直接访问localhost的端口就能实现。 - Pod到Pod的直接通信。
同一个Node中的Pod之间通过Docker bridge就可以通信,不同Node中的Pod需要通过Docker bridge和路由管理插件,例如Flannel。 - Pod到Service之间的通信。
- 集群外部与内部组件的通信。
CNI
CNI是一种容器网络规范,定义了荣光其允许环境与网络插件之间的简单接口规范,通过一个JSON Schema定义CNI插件提供的输入和输出参数,一个容器可以通过绑定多个网络插件加入多个网络中。
CNI提供了一种应用容器的插件化网络解决方案,定义对容器网络进行操作和配置的规范,通过插件的形式对CNI接口直接进行实现。
CNI插件包括两种:
- CNI Plugin
负责容器配置网络资源。 - IPAM Plugin
负责对容器的IP地址进行管理和分配。
Kubernets支持两种网络插件:
- CNI插件:根据CNI规范实现其接口,以与插件提供者直接对接。
- kubenet插件:使用bridge和host-local CNI插件实现一个基本cbr0。
目前已有多个开源支持CNI网络插件:Calico、Canal、Flannel、Weave Net等。
网络策略
为了使用Network Policy,Kubernetes引入了一个新的资源对象NetworkPolicy,用于设置Pod间网络访问策略。然后还需要通过第三方插件提供的策略控制器进行策略的实现。
NetworkPolicy可以定义Pod的作用范围、网络策略类型、允许访问的白名单之类的。
存储
Kubernetes通过PV和PVC两个资源对象实现对存储的管理子系统。
PV
PersistentVolume是对底层网络共享存储的抽象,将共享存储定义为一种资源,主要包括:
- 存储能力:目前只支持存储空间容量的设置。
- 存储卷模式:就是支持的文件系统和块硬件设备。
- 访问模式:用于描述用户的应用对资源的访问权限,包括读写权。
- 存储类型:通过StorageClassName参数指定一个StorageClass资源对象名, 设置存储类别。
- 回收策略:可以选择保留、回收空间和删除策略。
- 节点亲和性:可以通过该功能使得只能通过某些Node访问Volume,使用这些卷的Pod将被调度到对应的Node上。
PV的生命周期:
- 可用状态,还未与PVC绑定。
- 绑定状态。
- PVC被删除,资源以及释放,但没与被集群回收。
- 自动资源回收失败。
PVC
是用户对存储资源的需求申请,主要包括存储空间请求、访问模式、PV选择条件和存储类别信息的设置。
如果PVC被删除了,那么绑定在上面的PV也可能被删除。
Pod、PVC、PV、存储空间的关系如下:
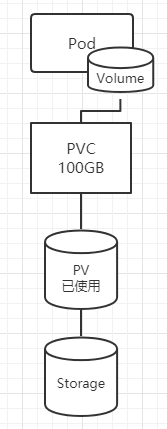
Kubernets支持两种资源供应模式:
- 静态模式:管理员手动创建PV,在定义PV时需要将后端存储的特性进行设置。
- 动态模式:通过StorageClass的设置对后端存储进行描述,PVC对存储的类型进行声明,系统自动完成PV的创建与PVC的绑定。
StorageClass
是存储资源的抽象定义,对用户设置的PVC申请屏蔽后端存储的细节,一方面减少了用户对于存储资源细节的关注,还减轻了管理员手工管理PV的工作。基于StorageClass的动态资源供应模式将成为云平台的标准存储配置模式。
CSI存储机制
该机制用于在Kubernetes与外部存储系统之间建立一套标准的存储管理接口,通过该接口为容器提供存储服务。
上面提到的,通过PV、PVC和StorageClass的方式以及可以实现很好的基于插件的存储管理机制,但是这些资源对象都是Kubernetes内部的,是紧耦合的开发模式,不利于开发。于是,Kubernetes才推出了CSI接口,使得外部插件能够使用原生存储机制为容器提供存储服务。
CSI中主要包括两类组件:
- Controller
提供存储服务视角对存储资源和存储卷进行管理和操作。建议部署为单实例Pod,保证存储插件只运行一个控制器。 - Node
对主机(Node)上的Volume进行管理和操作。建议部署为Daemonset,每个Node上都运行一个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号