
利用CART算法建立分类回归树
常见的一种决策树算法是ID3,ID3的做法是每次选择当前最佳的特征来分割数据,并按照该特征所有可能取值来切分,也就是说,如果一个特征有四种取值,那么数据将被切分成4份,一旦按某特征切分后,该特征在之后的算法执行过程中将不会在起作用,这种切分方法比较迅速,但是一个比较明显的缺点是不能直接处理连续型的特征,只有事先将连续型的数据转换成离散型才能再ID3算法中使用。
CART(Classification And Regression Tree)算法采用一种二分递归分割的技术,将当前的样本集分为两个子样本集,使得生成的的每个非叶子节点都有两个分支。因此,CART算法生成的决策树是结构简洁的二叉树。CART算法是非常有名的一种树构建算法,它使用二元切分来处理连续型的变量,对CART稍作修改就能处理回归问题。
在树的构建过程中,需要解决多重类型数据的存储问题,我们使用一部字典来存储树的结构,该字典包含以下4个元素:
1.待切分的特征
2.待切分的特征值
3.右子树,单不需要再切分的时候,也可以是单个值
4.左子树
建树:在分类回归树中,我们把类别集Result表示因变量,选取的属性集attributelist表示自变量,通过递归的方式把attributelist把p维空间划分为不重叠的矩形,具体建树的基本步骤参见:http://baike.baidu.com/view/3075445.htm。
CART算法是怎样进行样本划分的呢?它检查每个变量和该变量所有可能的划分值来发现最好的划分,对离散值如{x,y,z},则在该属性上的划分有三种情况({{x,y},{z}},{{x,z},y},{{y,z},x}),空集和全集的划分除外;对于连续值处理引进“分裂点”的思想,假设样本集中某个属性共n个连续值,则有n-1个分裂点,每个“分裂点”为相邻两个连续值的均值 (a[i] + a[i+1]) / 2。将每个属性的所有划分按照他们能减少的杂质(合成物中的异质,不同成分)量来进行排序,杂质的减少被定义为划分前的杂质减去划分之后每个节点的杂质量*划分所占样本比率之和,目前最流行的杂质度量方法是:GINI指标,如果我们用k,k=1,2,3……C表示类,其中C是类别集Result的因变量数目,一个节点A的GINI不纯度定义为:
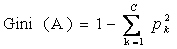
其中,Pk表示观测点中属于k类得概率,当Gini(A)=0时所有样本属于同一类,当所有类在节点中以相同的概率出现时,Gini(A)最大化,此时值为(C-1)C/2。
对于分类回归树,A如果它不满足“T都属于同一类别or T中只剩下一个样本”,则此节点为非叶节点,所以尝试根据样本的每一个属性及可能的属性值,对样本的进行二元划分,假设分类后A分为B和C,其中B占A中样本的比例为p,C为q(显然p+q=1)。则杂质改变量:Gini(A) -p*Gini(B)-q*Gini(C),每次划分该值应为非负,只有这样划分才有意义,对每个属性值尝试划分的目的就是找到杂质该变量最大的一个划分,该属性值划分子树即为最优分支。
剪枝:在CART过程中第二个关键的思想是用独立的验证数据集对训练集生长的树进行剪枝。
分析分类回归树的递归建树过程,不难发现它实质上存在着一个数据过度拟合问题。在决策树构造时,由于训练数据中的噪音或孤立点,许多分枝反映的是训练数据中的异常,使用这样的判定树对类别未知的数据进行分类,分类的准确性不高。因此试图检测和减去这样的分支,检测和减去这些分支的过程被称为树剪枝。树剪枝方法用于处理过分适应数据问题。通常,这种方法使用统计度量,减去最不可靠的分支,这将导致较快的分类,提高树独立于训练数据正确分类的能力。
决策树常用的剪枝常用的简直方法有两种:事前剪枝和事后剪枝,CART算法经常采用事后剪枝方法:该方法是通过在完全生长的树上剪去分枝实现的,通过删除节点的分支来剪去树节点。最下面未被剪枝的节点成为树叶。
CART用的成本复杂性标准是分类树的简单误分(基于验证数据的)加上一个对树的大小的惩罚因素。惩罚因素是有参数的,我们用a表示,每个节点的惩罚。成本复杂性标准对于一个数来说是Err(T)+a|L(T)|,其中Err(T)是验证数据被树误分部分,L(T)是树T的叶节点树,a是每个节点的惩罚成本:一个从0向上变动的数字。当a=0对树有太多的节点没有惩罚,用的成本复杂性标准是完全生长的没有剪枝的树。在剪枝形成的一系列树中,从其中选择一个在验证数据集上具有最小误分的树是很自然的,我们把这个树成为最小误分树。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号