RoPE论文阅读笔记
复数几何意义:https://zhuanlan.zhihu.com/p/646598747
https://zhuanlan.zhihu.com/p/359502624
Motivation & Abs
作者提出了旋转位置编码( Rotary Position Embedding, RoPE) 的新方法来有效利用位置信息。RoPE使用旋转矩阵对绝对位置进行编码,同时在自注意公式中纳入了明确的相对位置依赖性。RoPE 实现了序列长度的灵活性、随着相对距离的增加而衰减的标记间依赖性,以及为线性自注意力配备相对位置编码的能力。
Background
令为N个输入token构成的序列,对应的word embedding表示为,其中为d维的词嵌入,不包含任何的位置信息。自注意力首先将位置信息引入词嵌入,之后将其变为q、k、v:
,其中通过函数引入了和的位置信息。
自注意力计算:
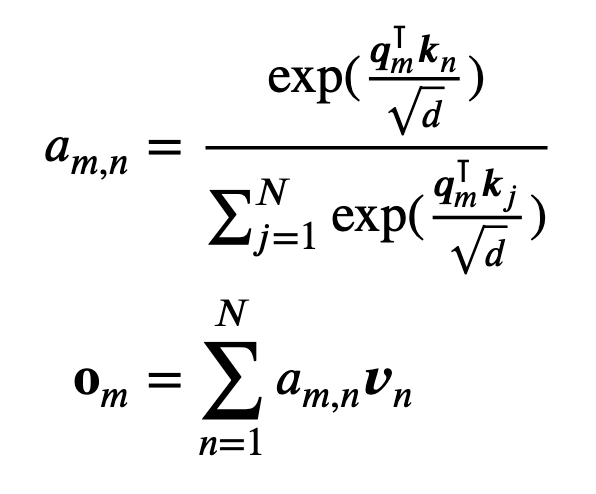
现有的基于transformer的位置编码方法旨在找到一个合适的函数。
Method
Formulation
基于 Transformer 的语言建模通常通过自注意机制来利用单个标记的位置信息。通常支持在不同位置的token之间进行信息的传递。想要引入相对位置信息,需要一个函数计算和的内积,函数的输入为,以及其相对位置:
最终目标是找到一种等效的编码机制来求解以及以符合上述关系。
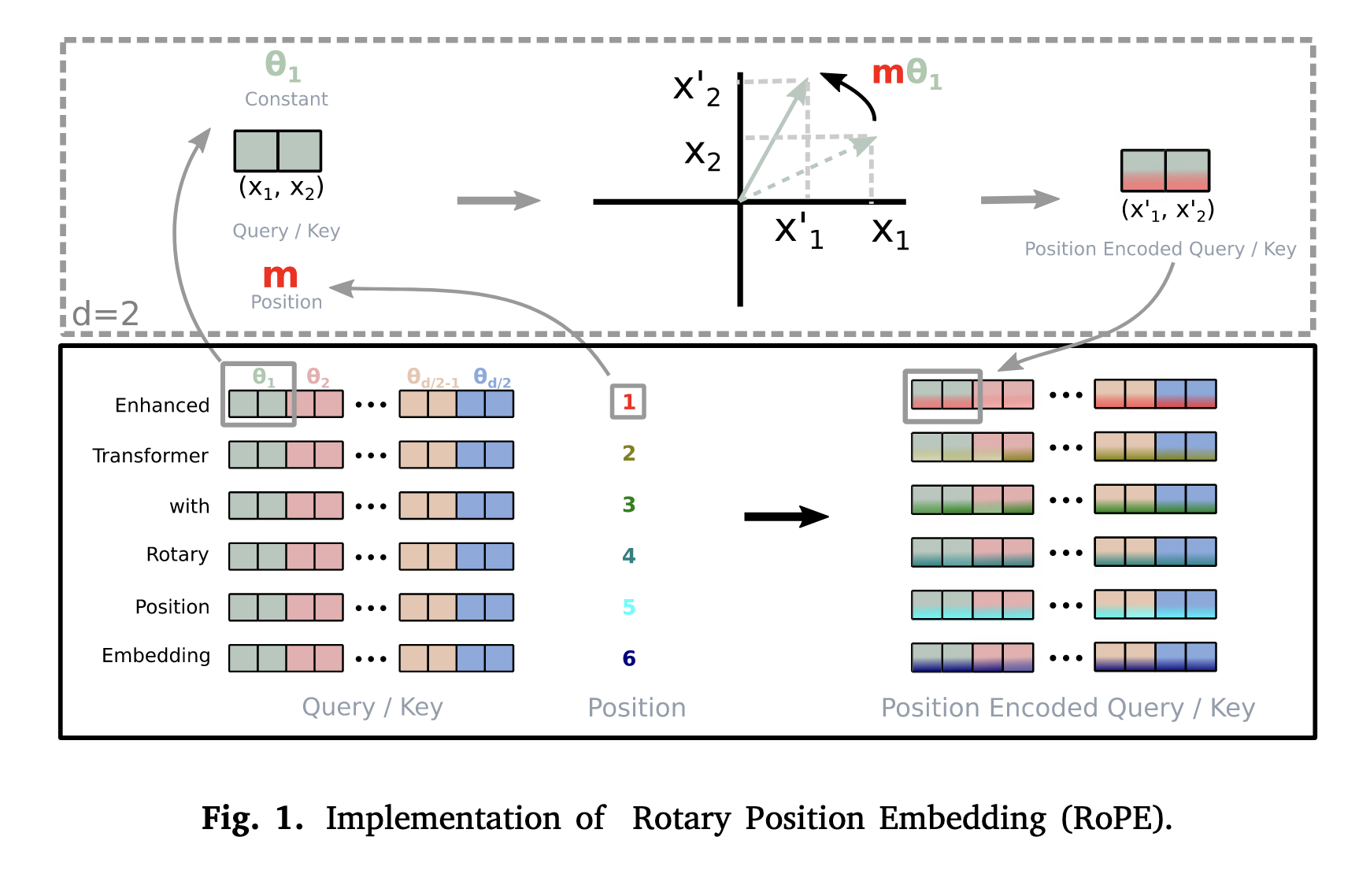
Rotary position embedding
作者首先分析了时的一个简单例子。这种情况下,作者使用了向量在2D平面的几何性质以及其复数性质从而证明我们想要的解为:
其中为复数的实部,为的共轭复数,为预设的非零常数。通过矩阵乘法表示:
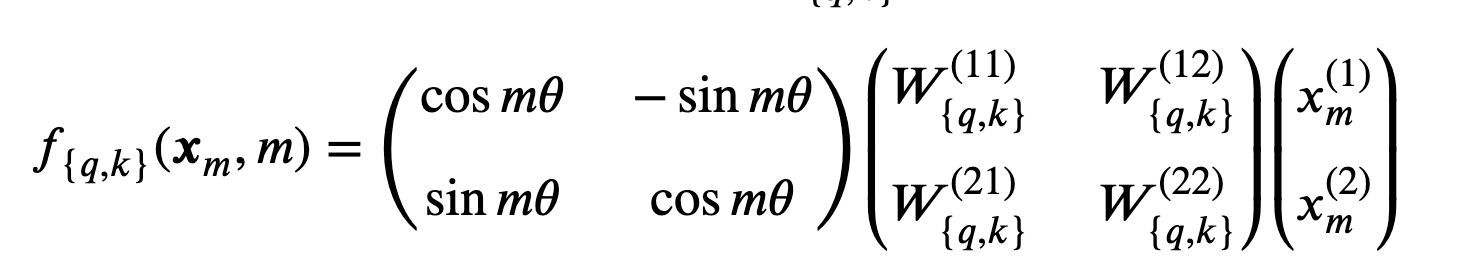
其中为2D平面的坐标。具体来说,其实就是将通过变换后的embedding旋转其位置索引的角度倍数。
为了将上述算法扩展为更一般的形式(且为偶数),作者将维空间分成了两个大小为的子空间,利用内积的线性性对其进行组合:
,其中:
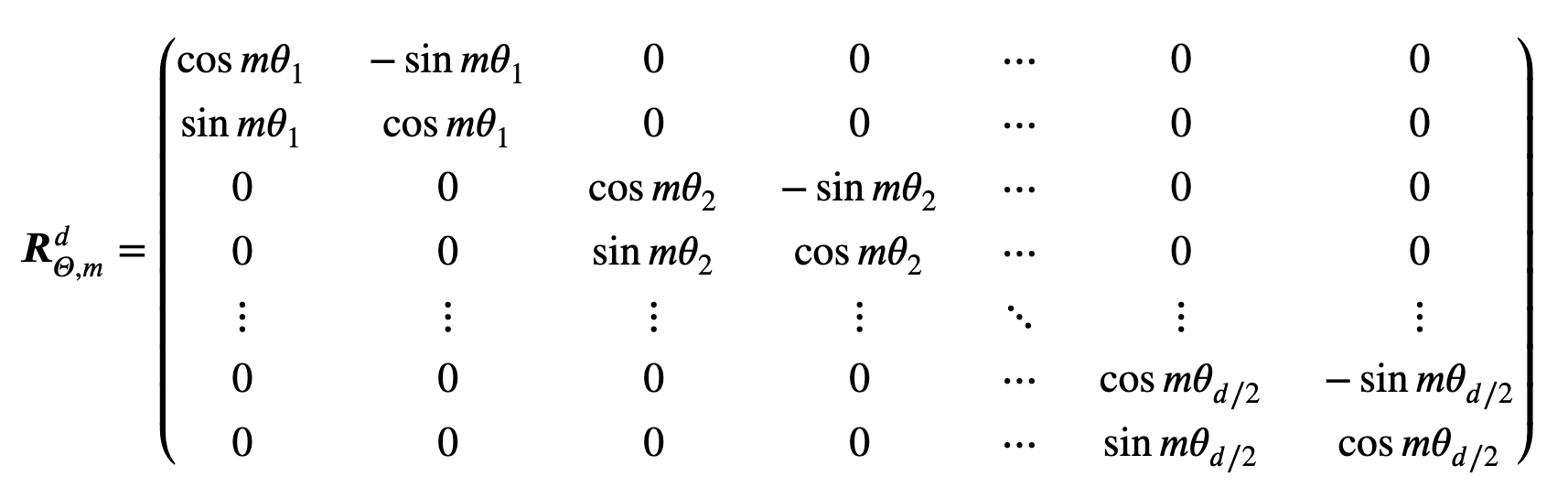
为旋转矩阵,。
内积变为:
值得注意的是是一个正交矩阵,保证了编码位置信息过程中的稳定性(正交矩阵不会改变位置信息的相对关系?)。
Properties of RoPE
Long-term decay
可以保证睡着相对位置距离的增加,内积逐渐衰减。
RoPE with linear attention
自注意力可以用更一般的形式重写:
原始 self-attention 应该计算每对 token 的 query 和 key 的内积,引入了二次复杂度。线性注意力可以表示为:
复杂度为。引入RoPE:
Computational efficient realization of rotary matrix multiplication
代码实现
TODO



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!