Qwen2-VL论文阅读笔记
Motivation & Abs
之前的MLLM通常使用预定义的固定分辨率,Qwen2-VL引入了朴素动态分辨率,使模型能够生成更高效、更准确的视觉表示,与人类感知过程紧密结合。同时,模型还使用了多模态旋转位置编码(M-RoPE),促进了不同模态信息的有效融合。同时,作者使用了统一的范式处理图像和视频,增强了模型的视觉感知能力。同时,作者还探索了LVLM中的scaling law,不同大小的模型均能取得极具竞争力的表现。
Method
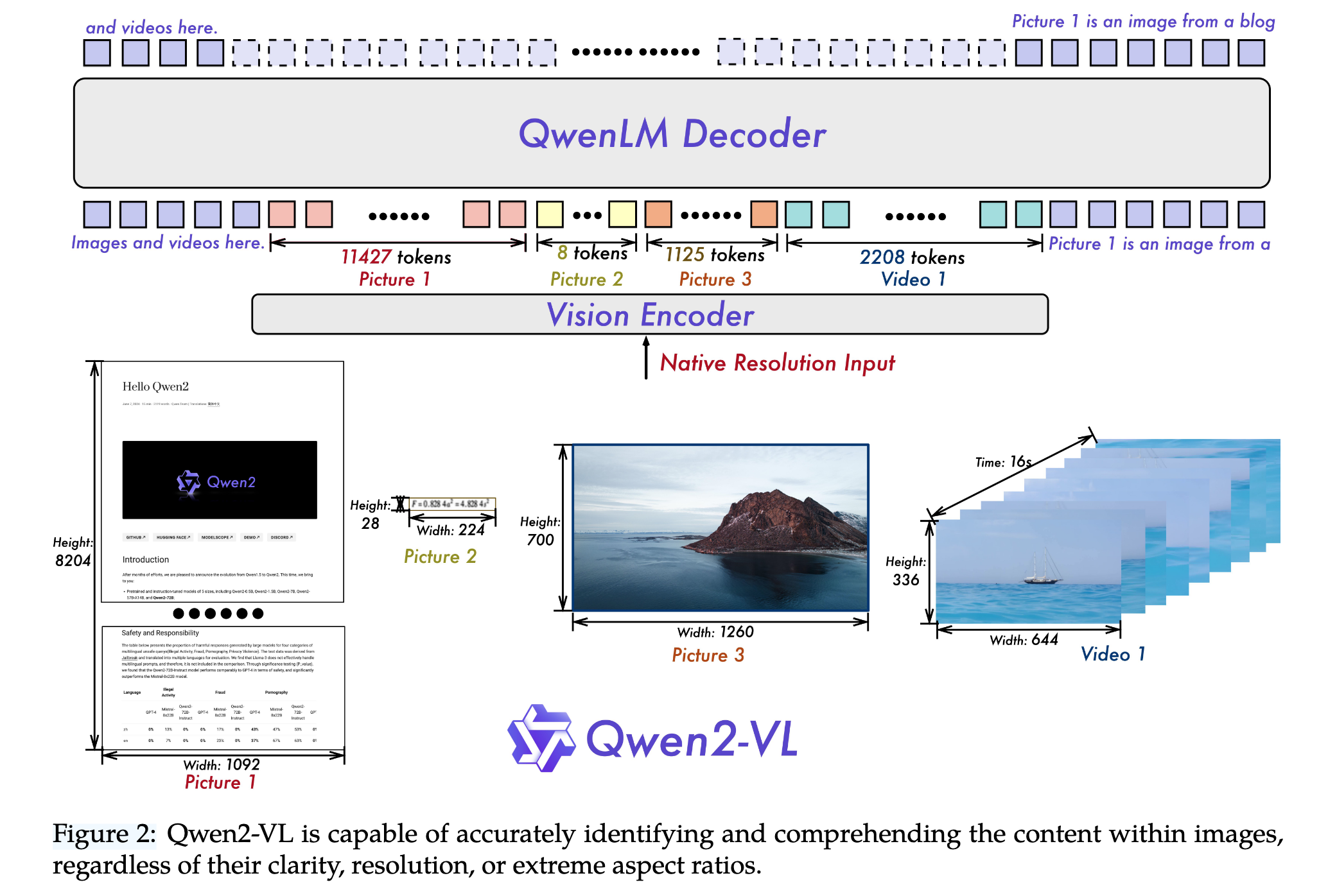
Model Architecture
vision encoder采用675m的ViT,能够处理图片和视频输入。language model采用Qwen2。为了进一步增强模型能力,作者设计了如下策略:
Naive Dynamic Resolution
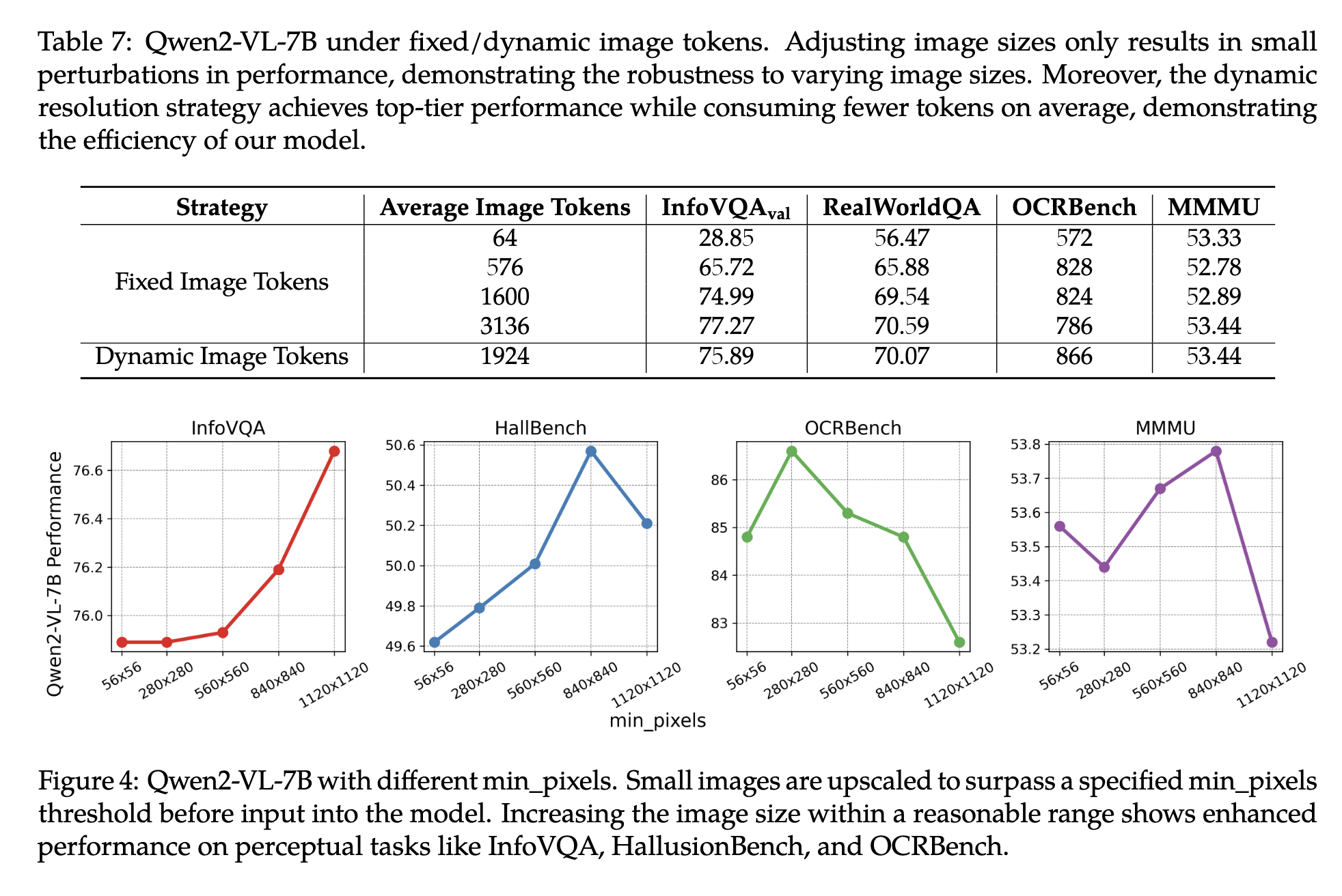
不同于Qwen-VL,Qwen2-VL能够任何分辨率的图像,动态地将其转为可变数量的视觉token。为此,作者将原始的绝对位置编码改成了2d的旋转位置编码。在推理阶段,不同分辨率的图像被打包到一个序列中,并控制打包长度以限制 GPU 内存的使用。为了进一步减少每张图片的视觉token数量,视觉编码器后紧跟一个MLP,用于将邻近的2x2 token转化为一个token,通过<|vision_start|>和<|vision_end|>标记。例如对于224x224的图像,使用patch size=14的ViT编码,最终压缩后的输出为长度66的序列(64+2个标记)。
Multimodal Rotary Position Embedding (M-RoPE)
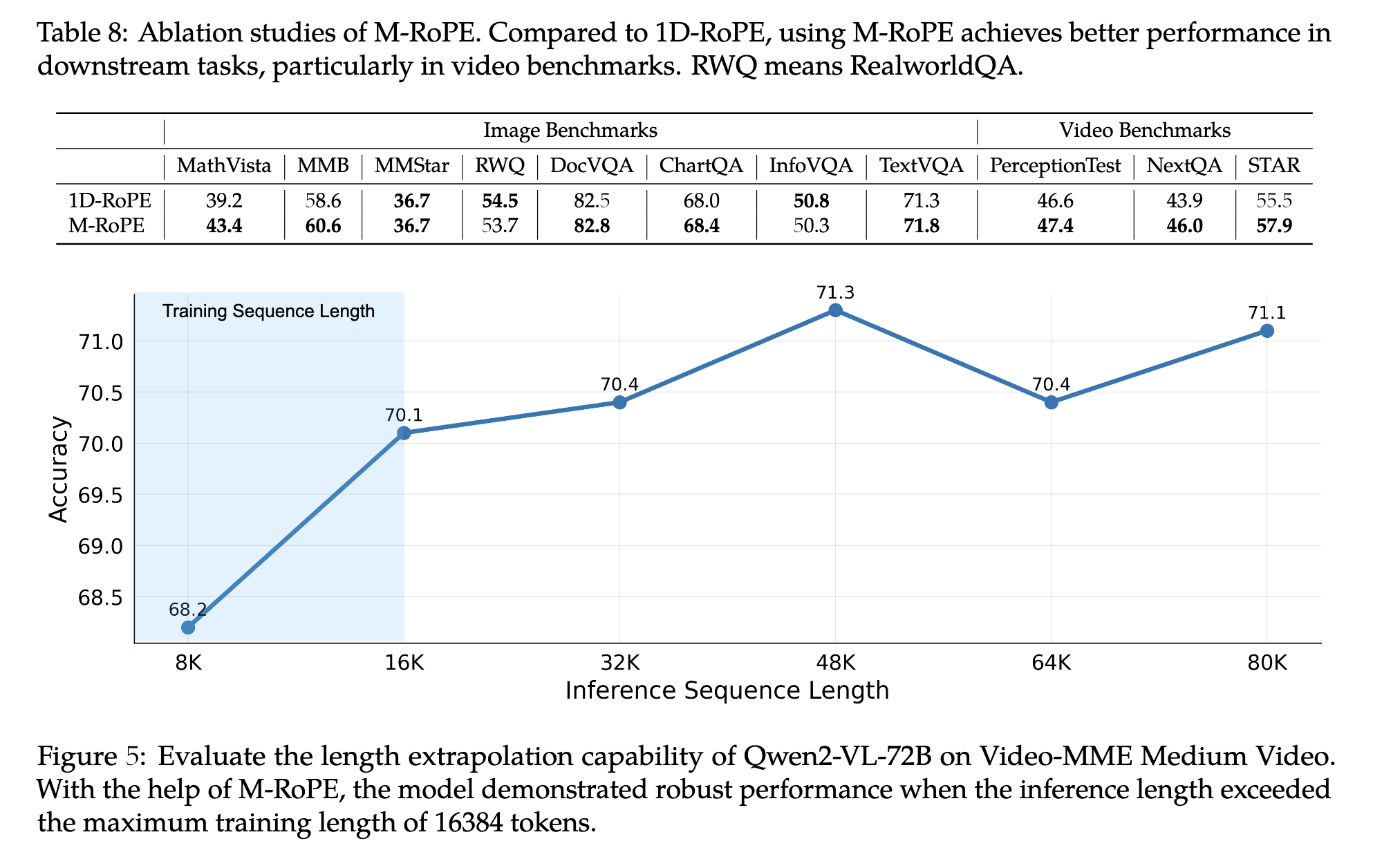
另一个关键的设计是多模态旋转位置编码。不同于LLM用的1D RoPE,M-RoPE能够用于不同模态的输入:将原始的rotary embedding分解为三部分:时序、高度和宽度。对于文本序列,这些组件使用相同的位置 ID,M-RoPE等同于1D-RoPE;对于图片,每个token的时序id保持一致,不同的 ID 则根据令牌在图像中的位置分配给 height 和 width 组件;对于被视为帧序列的视频,每个帧的时态 ID 都会递增,而 height 和 width 分量则遵循与图像相同的 ID 分配模式。在模型的输入包含多个模态的情况下,每个模态的位置编号是通过将前一个模态的最大位置 ID 递增 1 来初始化的。
Unified Image and Video Understanding
Q wen2-VL同时使用图像和视频进行训练,对视频每秒采样两帧,同时使用两层3D卷积处理视频输入,在不增加序列长度的同时处理更多的视频帧。为了保证一致性,图片被视为两个相同的帧。为了平衡长视频处理的计算需求和整体训练效率,作者动态调整了每个视频帧的分辨率,将每个视频的 Token 总数限制为 16384 个。这种训练方法在模型理解长视频的能力和训练效率之间取得了平衡。
Training
训练方式和Qwen-VL相同,一阶段只训练视觉编码器,二阶段打开全部参数,三阶段冻结视觉编码器并微调LLM。训练数据集包括包括图像-文本对、光学字符识别 (OCR) 数据、交错图像-文本文章、视觉问答数据集、视频对话和图像知识数据集。
第一阶段,使用600b token的语料库对模型预训练。LLM使用Qwen2的参数初始化,visual encoder则使用来自DFN(Data filtering networks)的ViT初始化,区别在于固定的位置编码换成了RoPE-2D。预训练阶段主要侧重于学习图像-文本关系、通过 OCR 识别图像中的文本内容以及图像分类任务。
第二阶段使用800b token的数据进行训练,包含了VQA等任务,有助于更细致地理解视觉和文本信息之间的相互作用。
在指令微调阶段,作者采用ChatML 格式来构建指令跟踪数据。该数据集不仅包括纯基于文本的对话数据,还包括多模态对话数据。多模态组件包括图像问答、文档解析、多图像比较、视频理解、视频流对话和基于智能体的交互。
Data Format


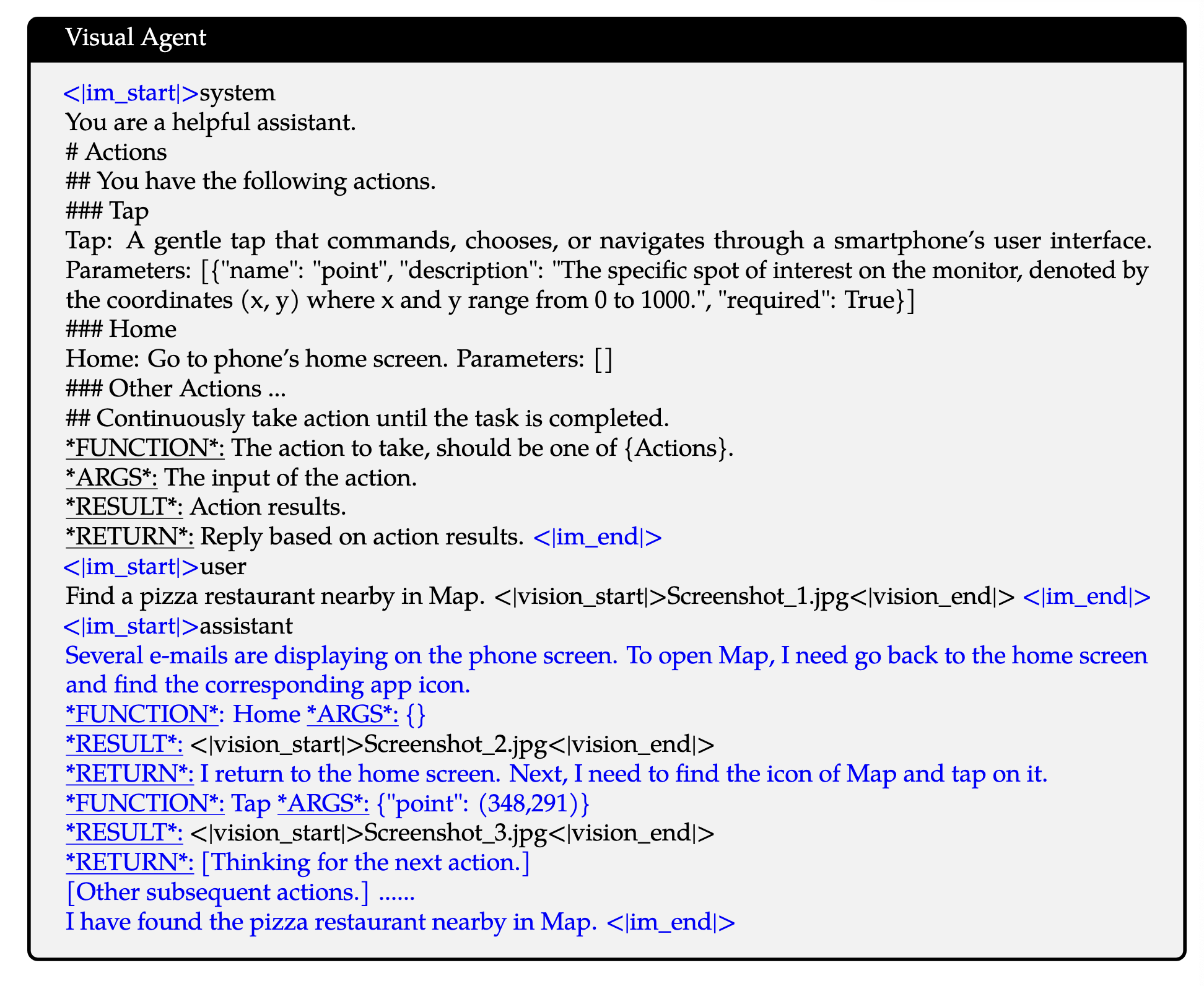
Multimodal Model Infrastructure
存储:使用阿里云的超高速 CPFS(云并行文件存储),将文本数据和视觉数据存储解耦。视频数据解码是一个主要的瓶颈,为此作者选择了缓存解码技术。检查点在CPFS存储每个 GPU 的优化器和模型状态。
...
并行:DP、TP、PP,利用 deepspeed 的 zero-1 redundancy optimizer 对状态进行分片以节省内存。利用序列并行性 (SP)和选择性检查点激活来减少内存使用。由于卷积算子的非确定性行为,TP 训练会导致不同的模型共享权重,作者通过对共享权重执行离线 reduce 来解决此问题,从而避免了额外的 all-reduce 通信步骤。这种方法对性能的影响很小。
...
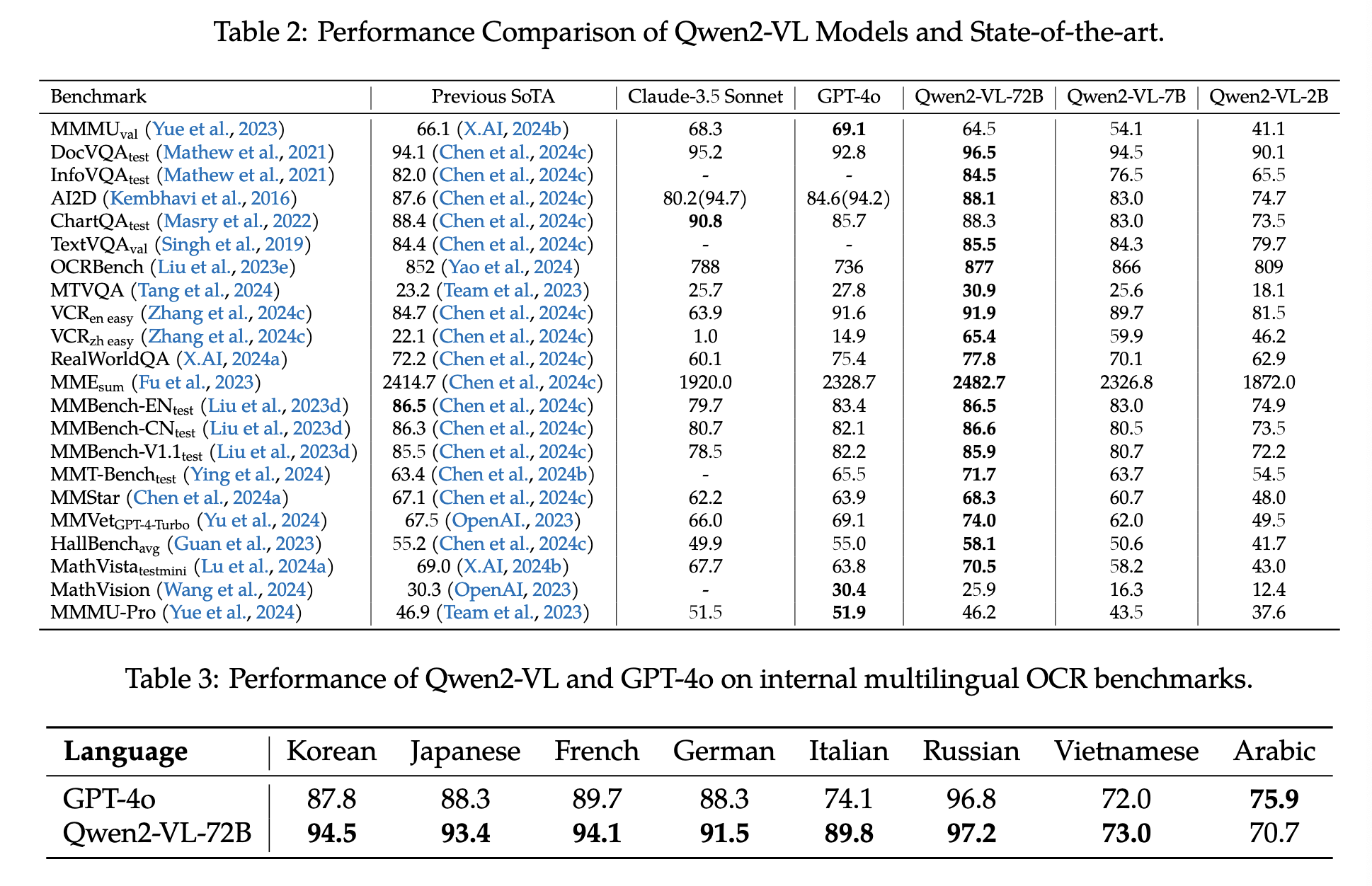
实验



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!