SigLIP论文阅读笔记
Motivaton & Abs
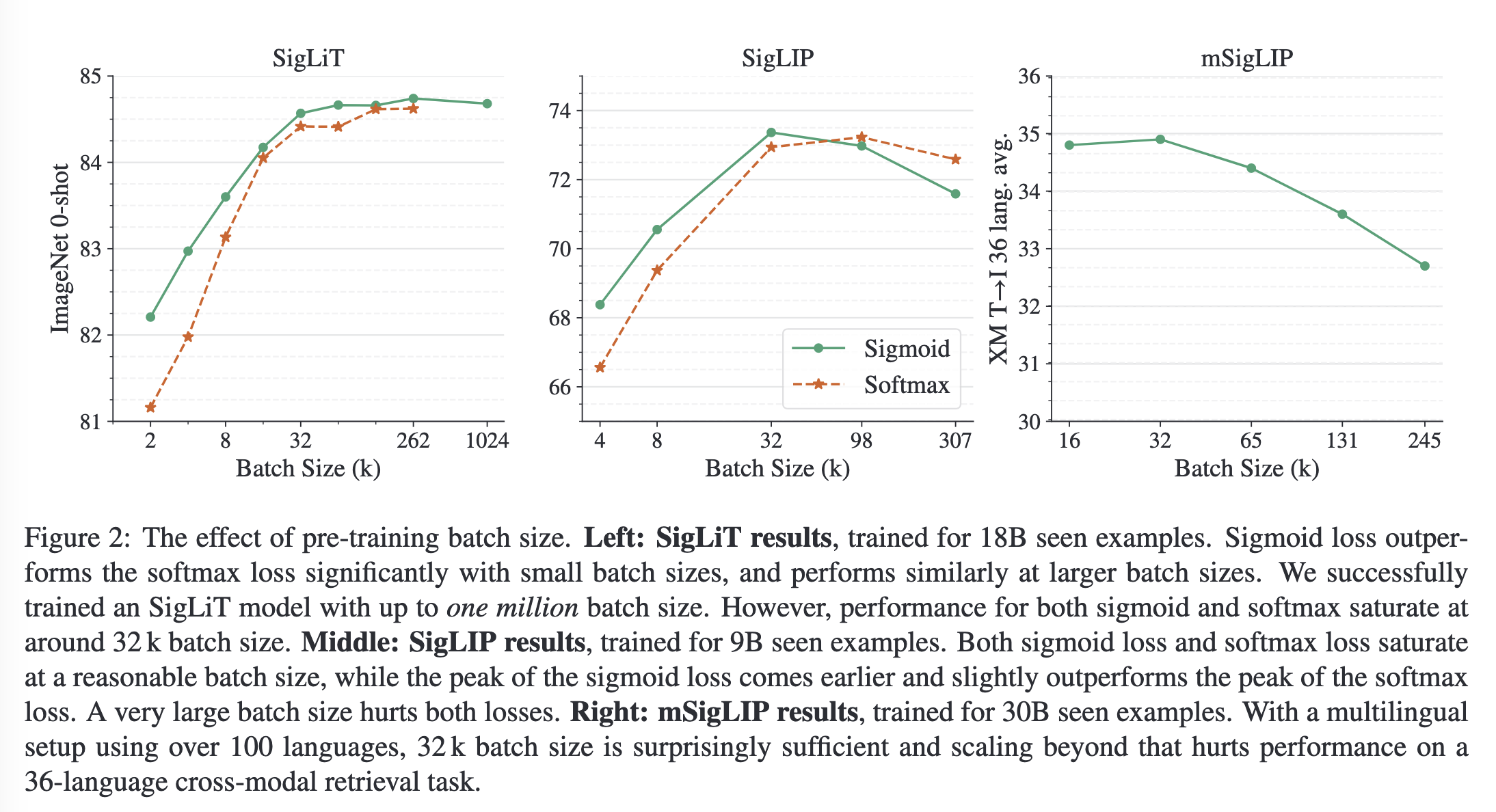
作者提出了一个简单的成对sigmoid损失以用于图像文本预训练,其仅作用于图像-文本对,不需要获取global view并进行归一化。sigmoid 损失同时允许进一步扩大 batch size,同时在较小的 batch size 上也表现得更好。最后,作者发现将batch size扩大到1m后,增加batch size带来的收益急剧缩小,32k的batch size就已经足够。
Method
给定一个mini batch ,对比学习的目标项使匹配的图文对尽可能彼此对齐,同时推远不匹配的图文对,这假定不匹配图文对的图像和文本没有任何关系。这种假定通常是带有噪声且不完美的。
Softmax loss for language image pre-training
使用softmax时,需要训练image model 与text model 以最小化如下损失:
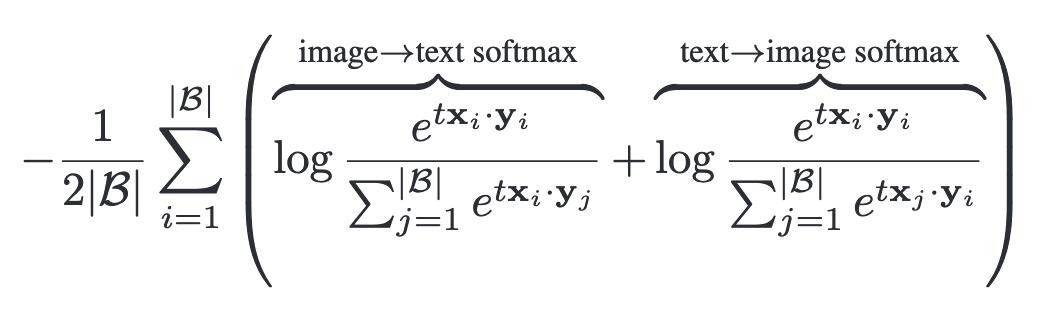
在这个过程中,normalization需要独立地执行两次
Sigmoid loss for language image pre-training
不同于基于softmax的对比学习损失,作者提出使用sigmoid,从而避免计算全局的normalization factor:
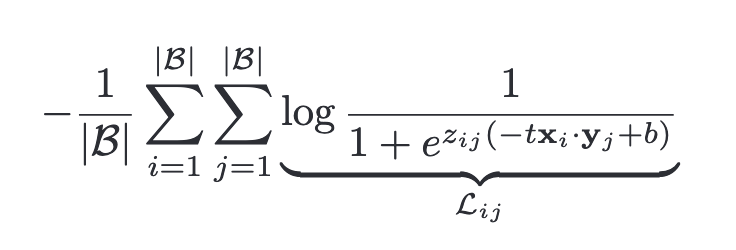
其中是给定图像和文本的标签,1为匹配,-1为不匹配。需要注意的是,在训练初期负样本会主导损失,导致优化步骤试图纠正这种偏差。为此,作者引入了额外的可学习项和,以10和-10作为初始值。
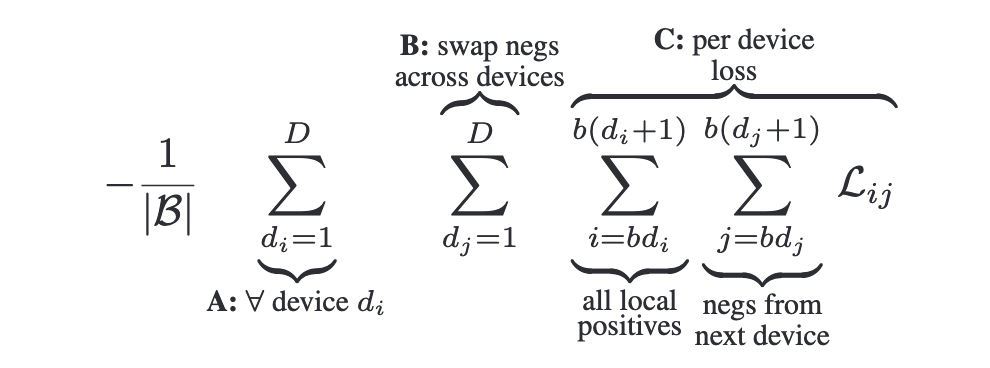
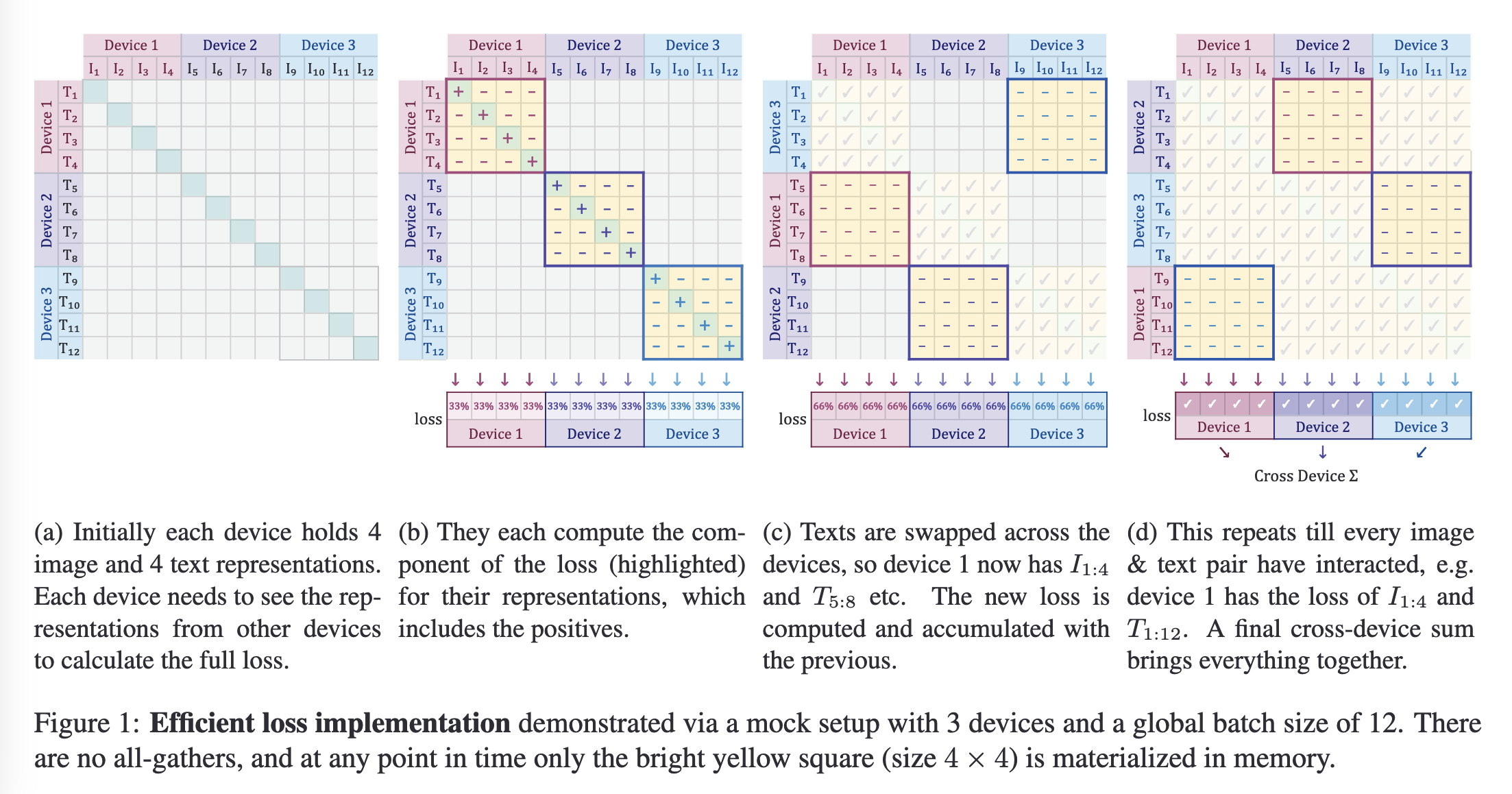
Efficient “chunked” implementation
Sigmoid能够避免对比学习训练时对loss进行all-gather的开销,同时无需计算相似性矩阵,节省了计算开销,对显存更加友好,同时保证了数值计算的稳定性。将per-device batch size表示为,总的loss可以表示为:
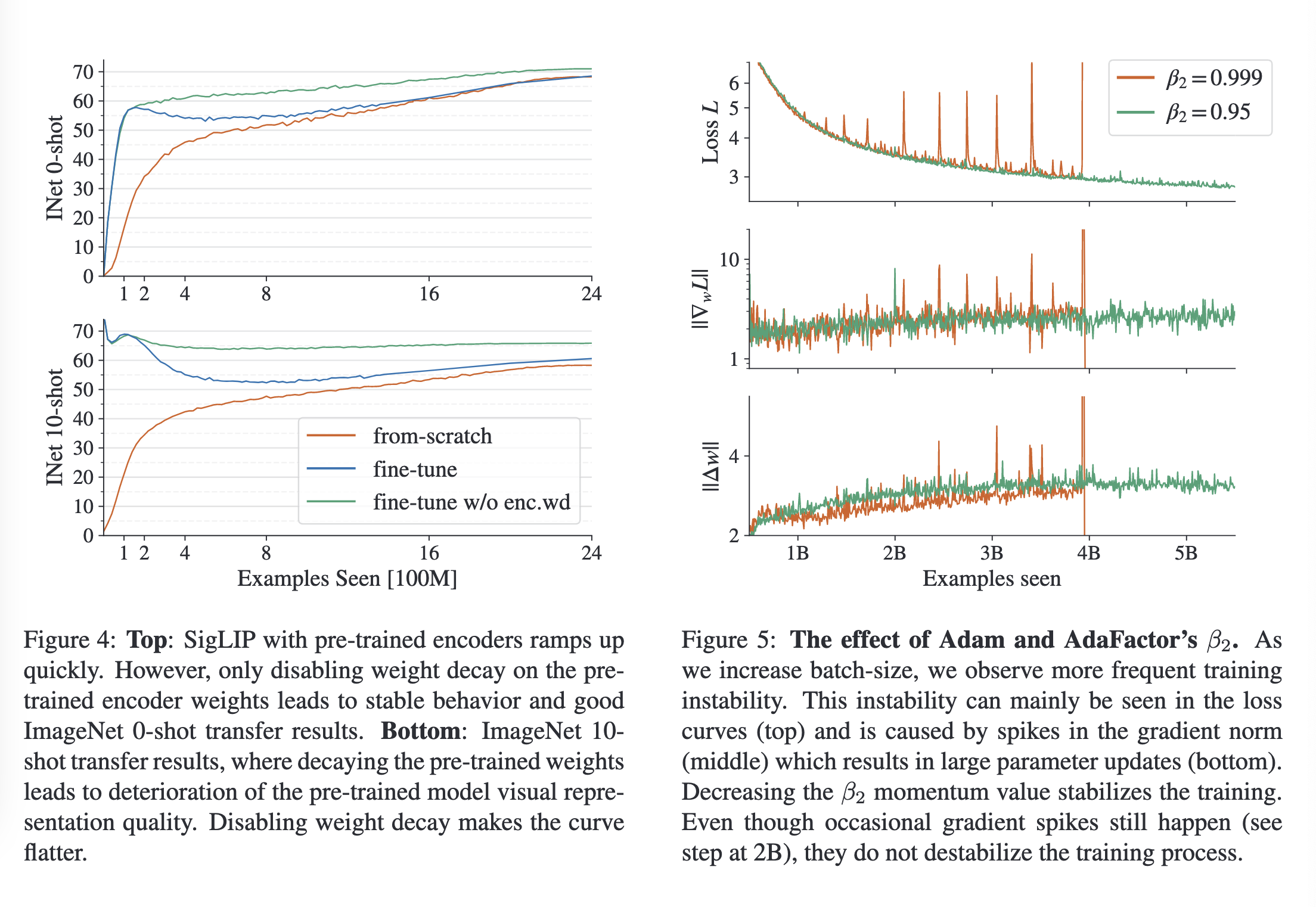
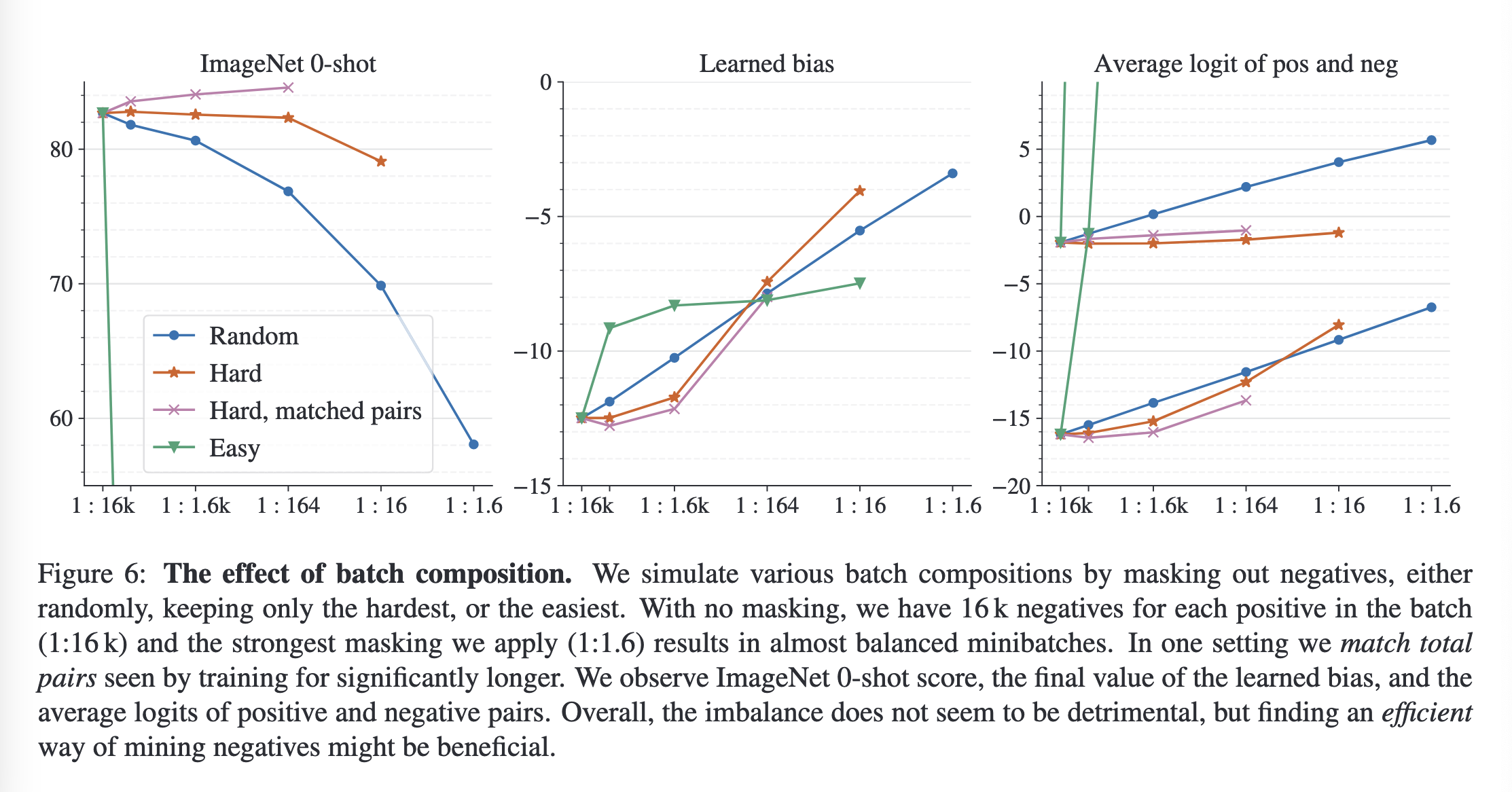
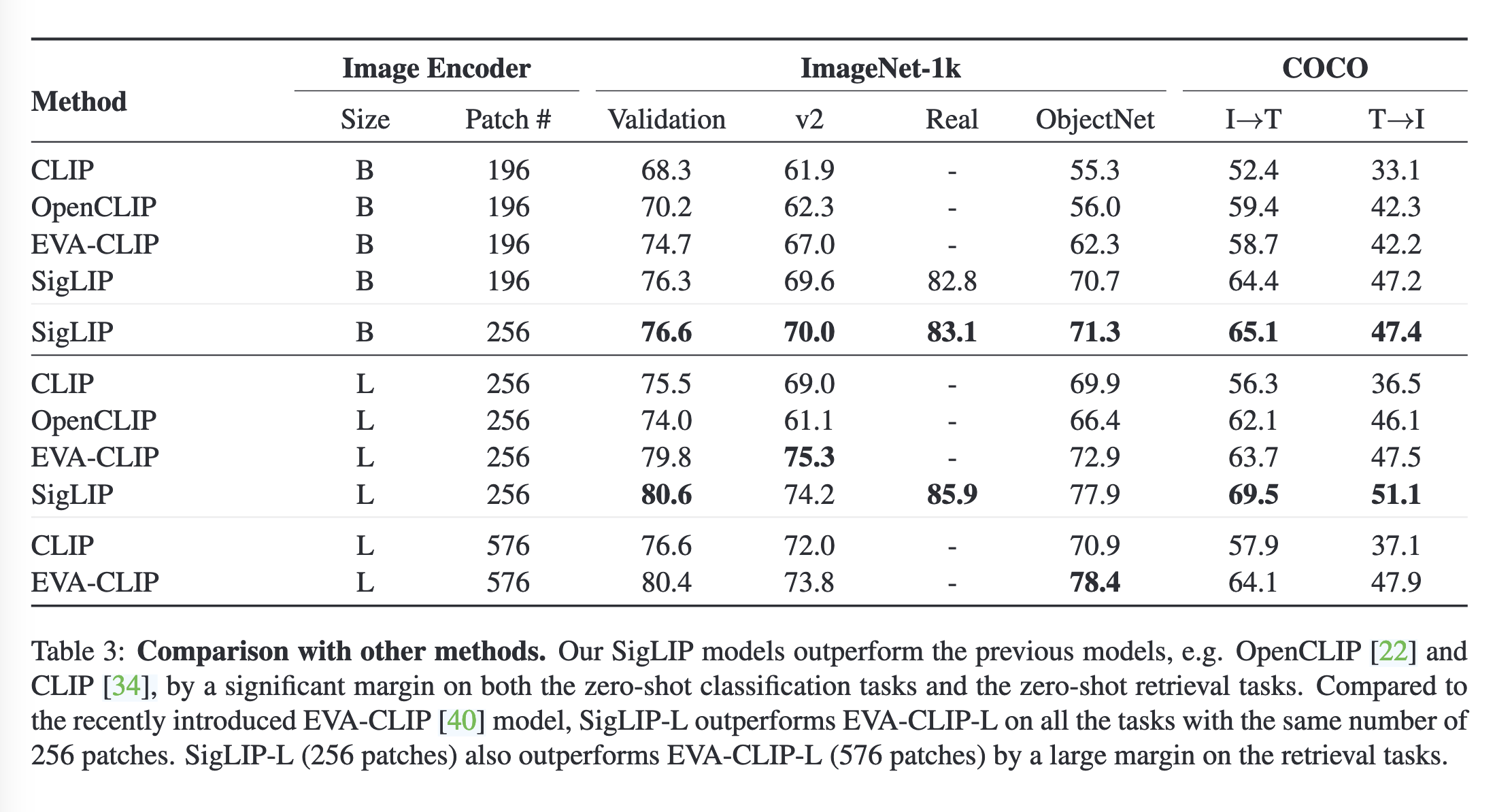
实验




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!