Qwen-VL论文阅读笔记
Motivation & Abs
Qwen-VL系列模型,通过设计(1)视觉感受器;(2)输入输出接口;(3)3阶段训练流水线;(4)多语言多模态高质量语料库从而赋予模型视觉感受的能力。除了传统的image description以及VQA任务外,作者还通过对齐image-caption-box从而使模型具有visual grounding以及文本阅读的能力。Qwen-VL在一系列benchmark上取得了sota的结果,同时在真实世界场景中也表现出了优越性。

Method
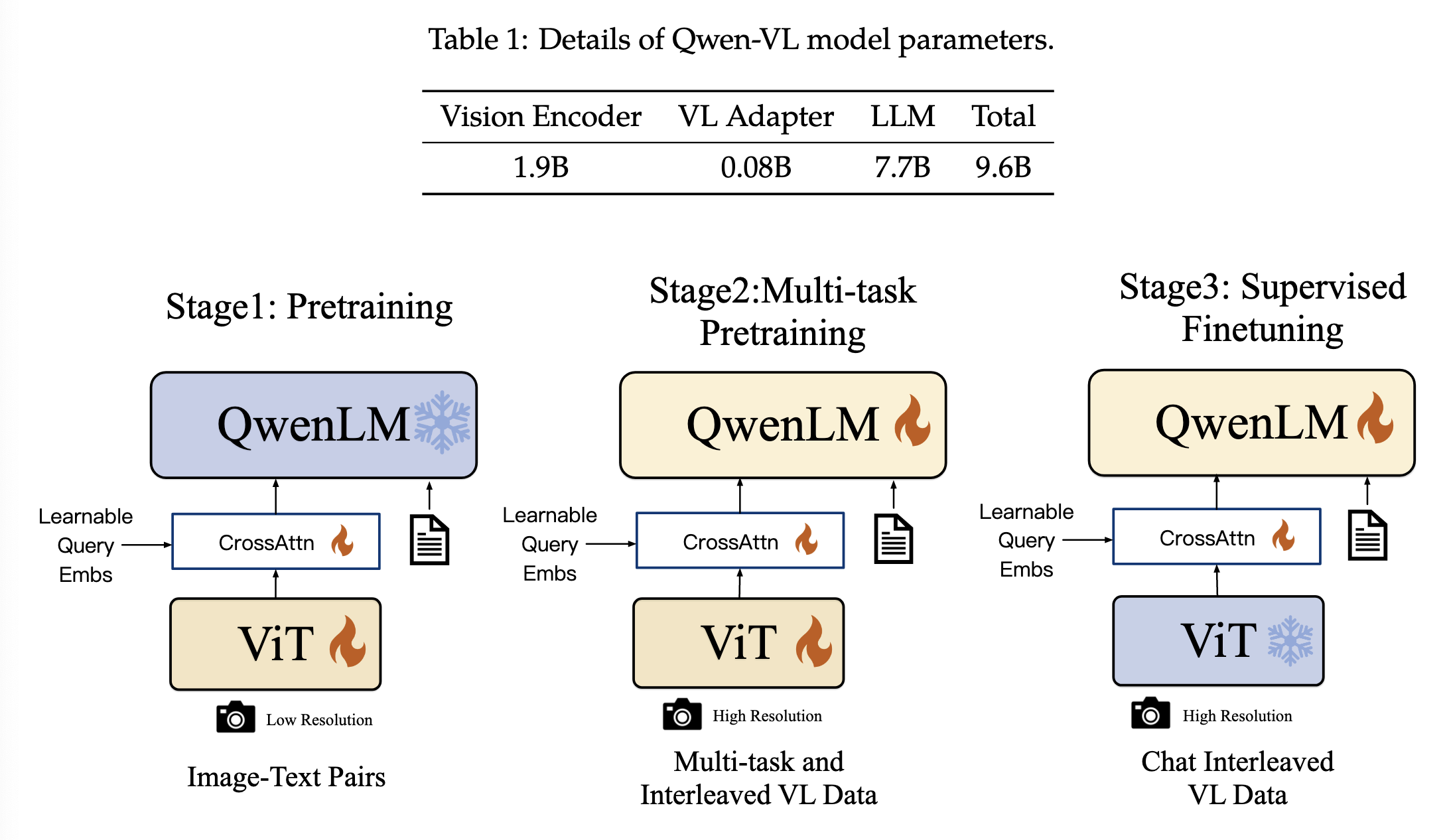
模型结构
LLM 使用Qwen-7B的预训练权重进行初始化。
Visual Encoder 采用Openclip的ViT-bigG进行初始化。在训练和推理阶段,输入图像被resize为固定大小的分辨率(patch size为14)。
Position-aware Vision-Language Adapter 为了减轻图像sequence带来的计算开销,Qwen-Vl引入了vision-language adapter用于压缩视觉特征。adpter包含单层cross-attention module(随机初始化),使用一组可学习的query与图像特征(作为key)计算cross-attention,从而将图像特征sequence压缩至256的长度。同时考虑到位置信息对于细粒度图像理解的重要性,作者还将2D绝对位置编码引入了cross-attention的q-k pairs,从而减轻压缩过程中位置信息的丢失。
输入 & 输出
Image Input 为了区分视觉输入和文本输入,需要加入两个特殊token:<img>以及</img>。
Bounding Box Input and Output 为了增强模型对于图像的细粒度理解能力以及visual groudning的能力,Qwen-VL的训练数据包含region descriptions、questions以及detections,此任务需要模型准确理解并以指定格式生成区域描述。对于任意一个给定的bounding box,首先执行归一化过程(范围是[0, 1000)),随后变成特定的字符串格式:
\((X_{top left}, Y_{top left}),(X_{bottomright}, Y_{bottomright})\)。为了区分detection的字符串和常规的文本,需要在box字符串的左右两边加入<box>以及</box>。此外,为了将边界框与其相应的描述性单词或句子适当地关联起来,作者引入了另一组特殊标记 (<ref> 和 </ref>),用于标记边界框引用的内容。
Training
训练过程包含三个阶段:两个阶段的pre-training以及最后的instruction fine-tuning training。
Pre-training
在预训练的第一阶段,主要使用的数据是大规模、弱标记、网络爬取的图像-文本对。数据集包含几个公开的数据集以及一些内部数据集。原始数据集总共包含50亿个图像-文本对,清理后总共包含14亿的图像文本对,英文数据占77.3%,中文数据占22.7%。
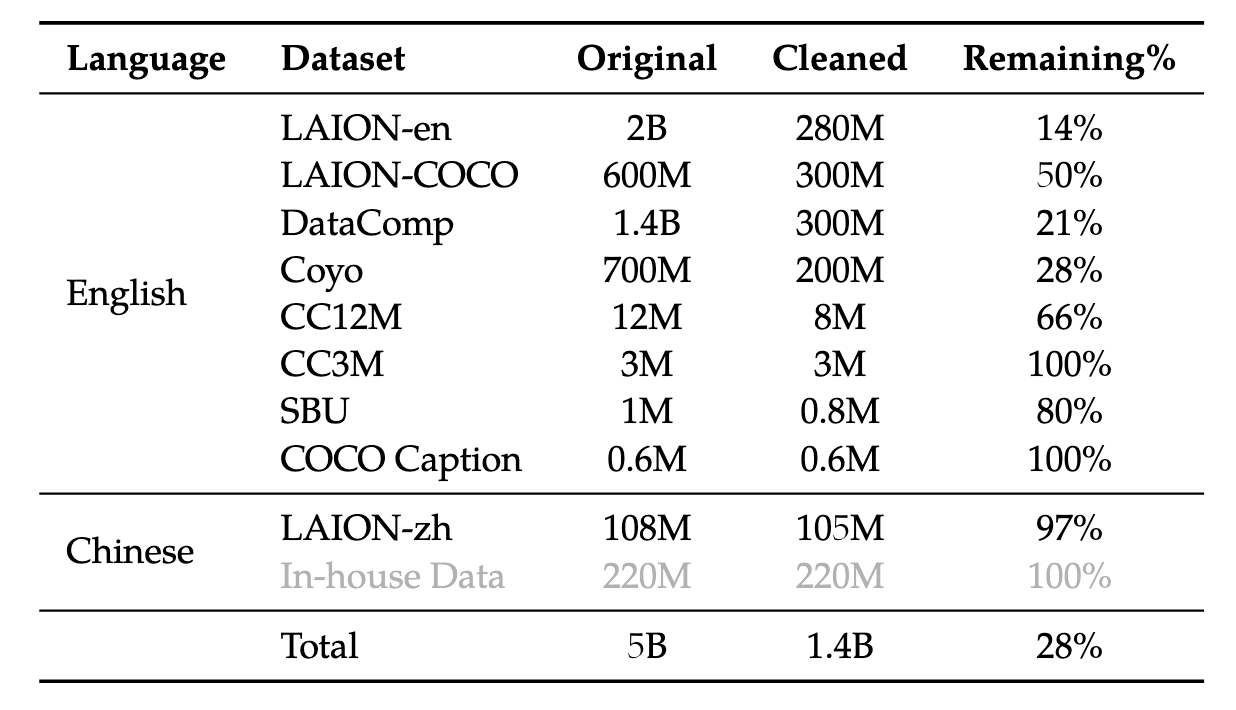
第一阶段训练的时候需要冻结language model,只训练adapter和vision encoder。输入图像被resize为224x224大小,训练目标是最小化输出的text token的CE loss,lr为2e-4,bs为30720,step为50000。
Multi-task Pre-training
第二阶段使用高质量、细粒度、高分辨率的VL标注数据:
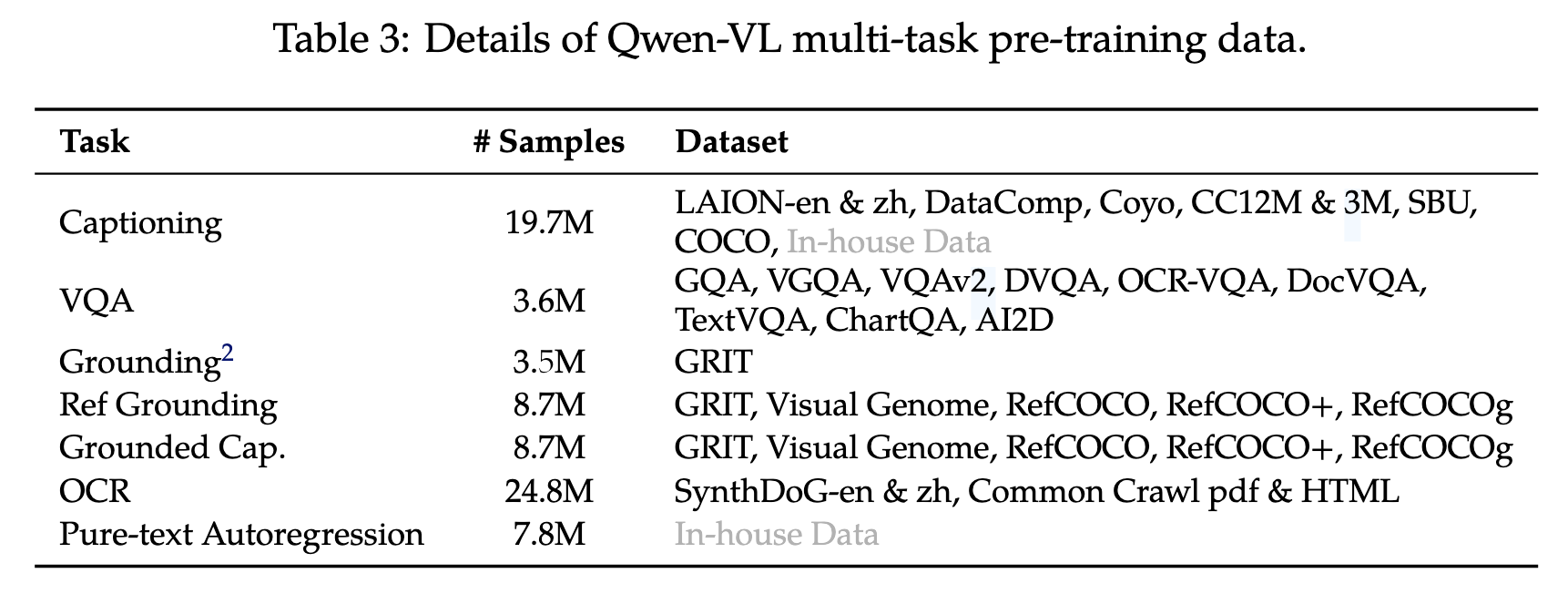
最后,作者将相同任务的数据打包为长度为2048的序列,得到交错的图像-文本数据。第二阶段训练时,输入图像的分辨率由224x224提升为448x448,从而减轻下采样带来的信息损失;语言模型全部解冻,训练目标与一阶段相同。
Supervised Fine-tuning
第三阶段,通过instruction fine-tuning增强模型instruction following & 对话能力,从而得到Qwen-VL-Chat模型。多模态指令微调数据主要来自通过大语言模型(LLM)自我指令生成的图像描述数据或对话数据,这类数据通常仅涉及单图像的对话和推理,并局限于图像内容的理解。作者通过人工标注、模型生成和策略拼接构建了一组额外的对话数据,以将定位能力和多图像理解能力引入 Qwen-VL 模型。此外,训练时作者将多模态对话数据以及纯文本对话数据进行混合,从而保证模型的通用对话能力。此阶段,visual encoder被冻结,只训练语言模型和adapter。
Evaluation
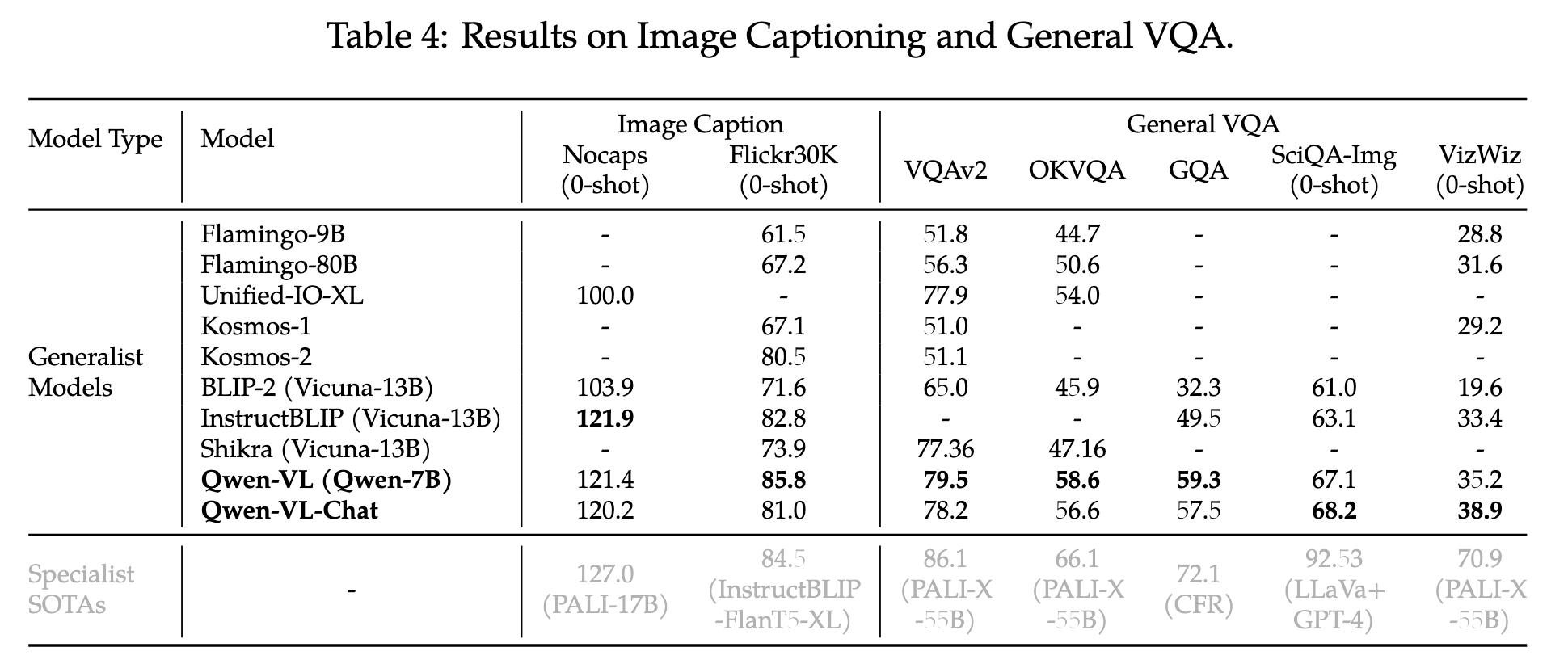
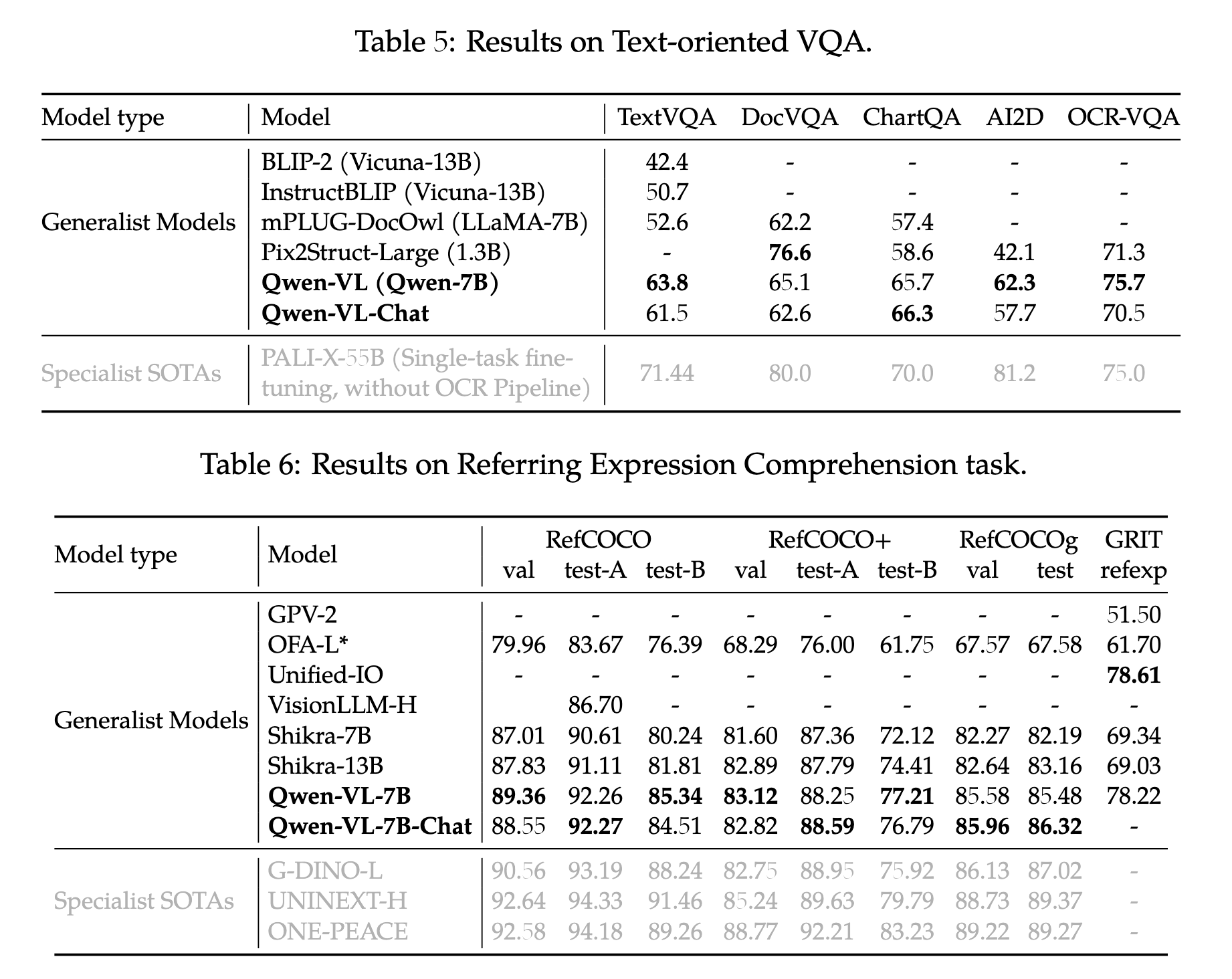
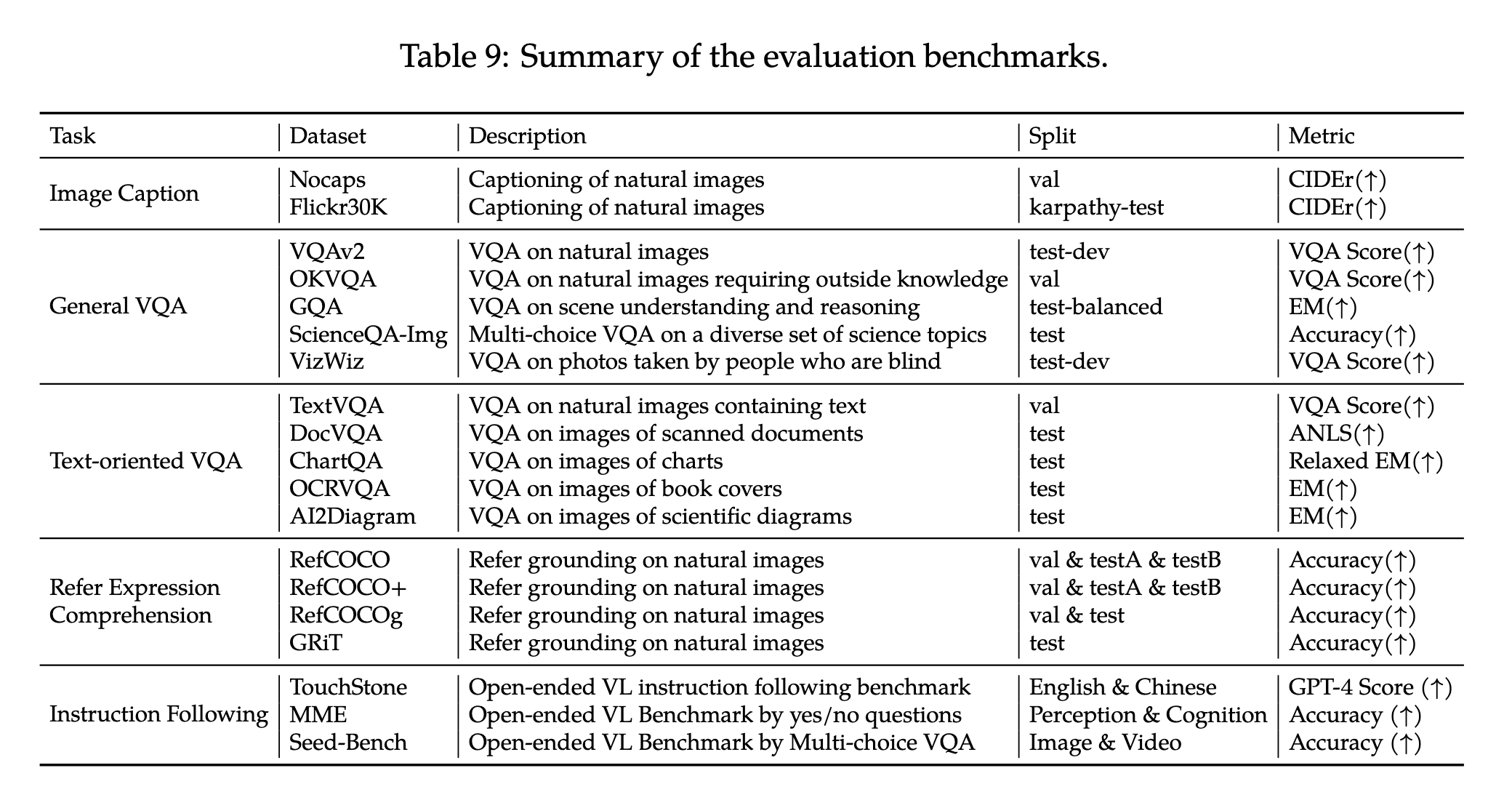
image caption task指标:CIDEr score

 浙公网安备 33010602011771号
浙公网安备 33010602011771号