Text Augmented Spatial-aware Zero-shot Referring Image Segmentation论文阅读笔记(EMNLP23 Findings)
Motivation & Method
关注的任务为zero-shot referring image segmentation,模型无法获得pixel-level的分割标注。之前的方法通常使用预训练的多模态模型如CLIP,然而CLIP使用图像文本对进行训练,难以做到image local patch与referring sentence的细粒度对齐。为此作者提出了TAS。TAS包含了一个mask proposal network用于提取instance level的mask,一个用于挖掘图像-文本相关性的文本增强视觉-文本匹配分数,以及一个用于mask后处理的空间校正器。三个数据集的结果表明方法取得了sota。
Method
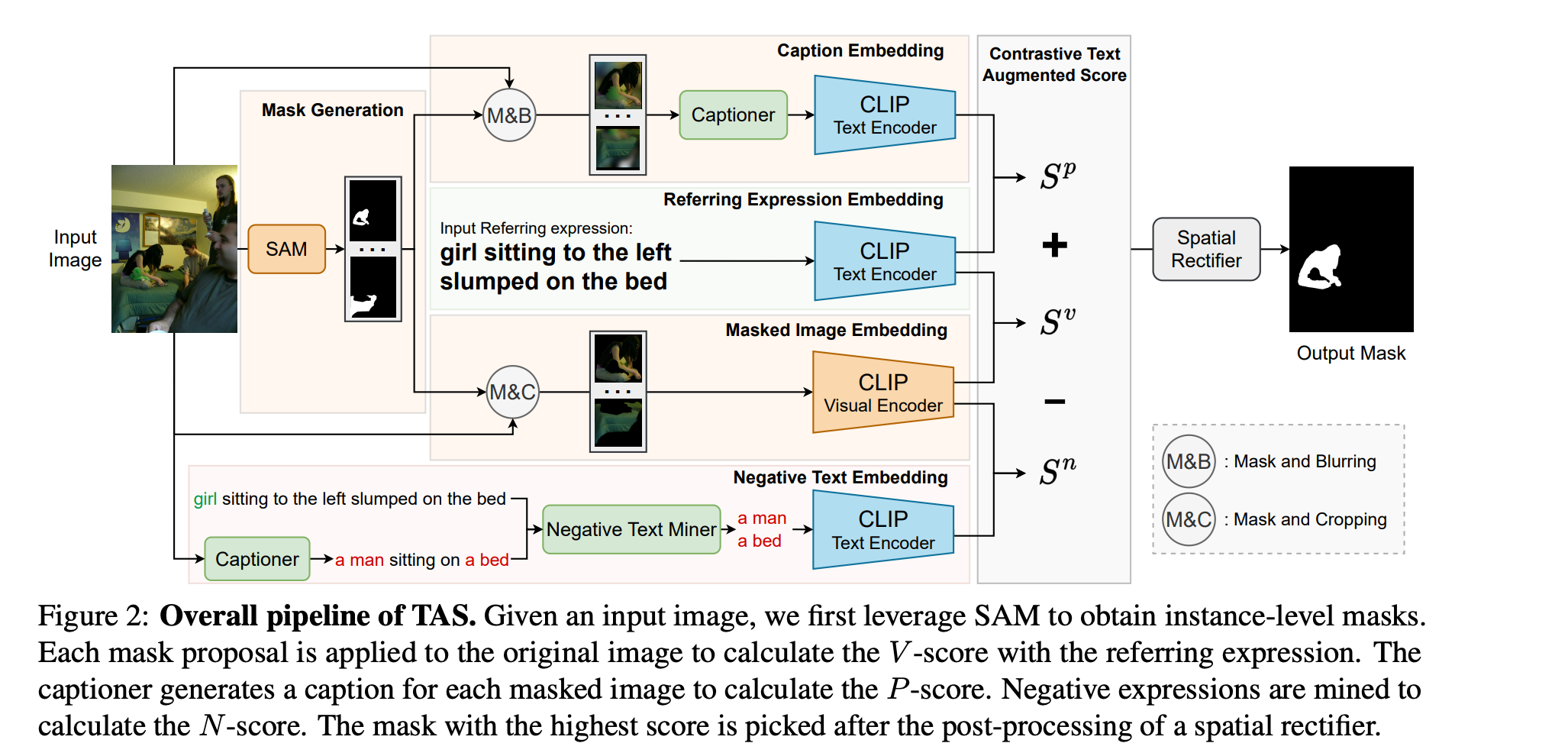
Mask Proposal Network
直接将CLIP用于密集预测任务效果不好,可以采用分阶段提取mask+masked image-text matching的方式。以前的工作利用 FreeSOLO(类别无关的实例分割网络)来获取所有掩码。然而最近提出的SAM在分割单个对象方面表现出强大的性能,特别是对于遮挡等场景而言。因此文章中的mask proposal network选择了SAM。
Text-augmented visual-text matching score
mask proposal network提供的mask并不包含语义信息,一种方法是使用masked image与text计算score,然而CLIP可能不适用于细粒度的region-text matching,且masked image与natural image可能存在domain gap。为此作者使用补充文本挖掘区域信息,引入了一个由 V 分数、P 分数和 N 分数组成的文本增强视觉-文本匹配分数。
V-score。给定三通道RGB图像与一个referring expression,SAM首先提取若干个binary mask,将每个mask施加到图像上,对前景部分裁剪然后送入CLIP visual encoder,使用提取得到的visual feature与text feature计算cosine similarity。
P-score。如前所述,natural image和masked image之间的domain gap影响视觉-文本对齐。为此作者引入P-score,借助captioning model提升对齐的质量。具体做法是通过一个captioning model为masked image生成一个互补的caption,之后计算P scpre:
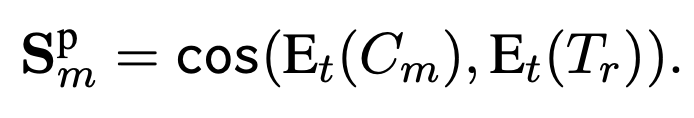
N-score。N score主要是针对图像中与参考表述无关的情况。为了挖掘不相关的表达,作者首先为输入图像生成一个总体描述,总体描述总结了图像中的所有物体,然后使用spaCy从描述中提取名词短语,并将它们视为潜在的负面表达。同时,在指代表达中可能存在指示同一物体的短语。为了避免这种情况,作者使用WordNet消除包含指代表达中主体同义词的短语。具体做法是计算两个同义词集的路径相似度来决定是否消除同义词。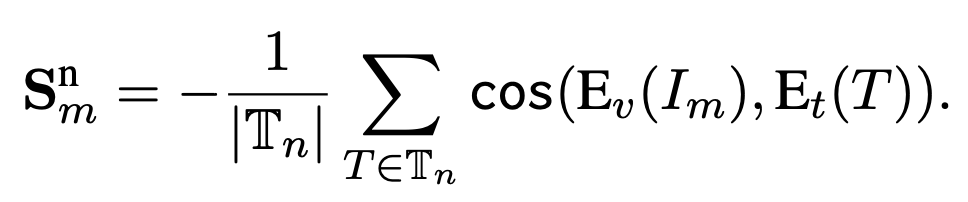
最终的分数以及mask选择: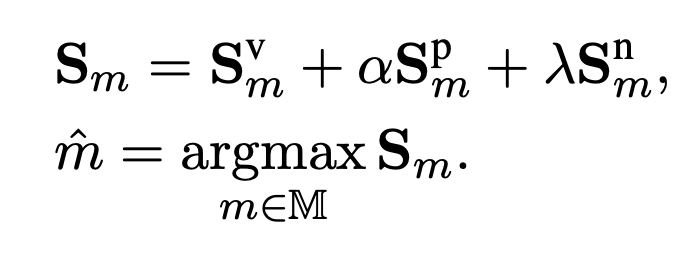
Spatial Rectifier
CLIP的训练过程无法使其理解参考表述的空间关系。为此,作者提出了一个基于规则的空间解析器用于后处理,强制框架从特定区域选择遮罩。该过程可以分解为三个步骤:方向描述识别、位置计算和空间校正。
方向描述识别。首先通过spaCy提取指代表达Tr的主题的描述性词汇,并检查是否有“上、下、左、右”等方向词。如果在描述性词汇中没有发现方向词,则不应用空间校正。
位置计算。其次,为了空间校正预测,需要每个mask proposal的位置信息。每个mask的中心点被用作位置的代理。具体来说,每个遮罩的中心点位置是通过平均所有前景像素的坐标来计算的。
空间校正。在获得中心点位置后选择在相应方向区域下总体得分S最高的mask。
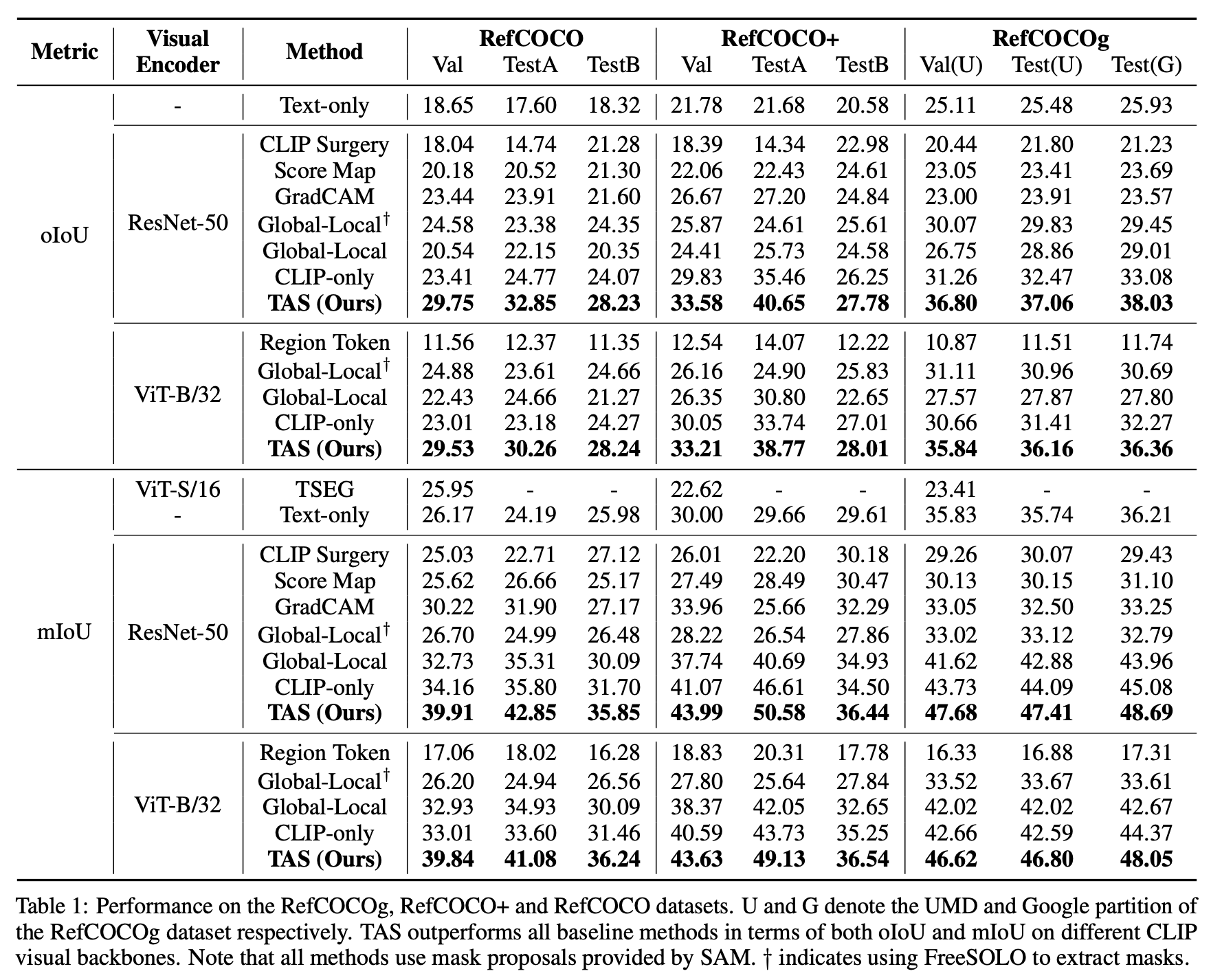
实验



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2023-09-05 pytorch分布式训练报错:Duplicate GPU detected : rank 1 and rank 0 both on CUDA device 35000
2022-09-05 CF1453D Checkpoints(期望)