ClearCLIP: Decomposing CLIP Representations for Dense Vision-Language Inference论文阅读笔记
Motivation & Abs
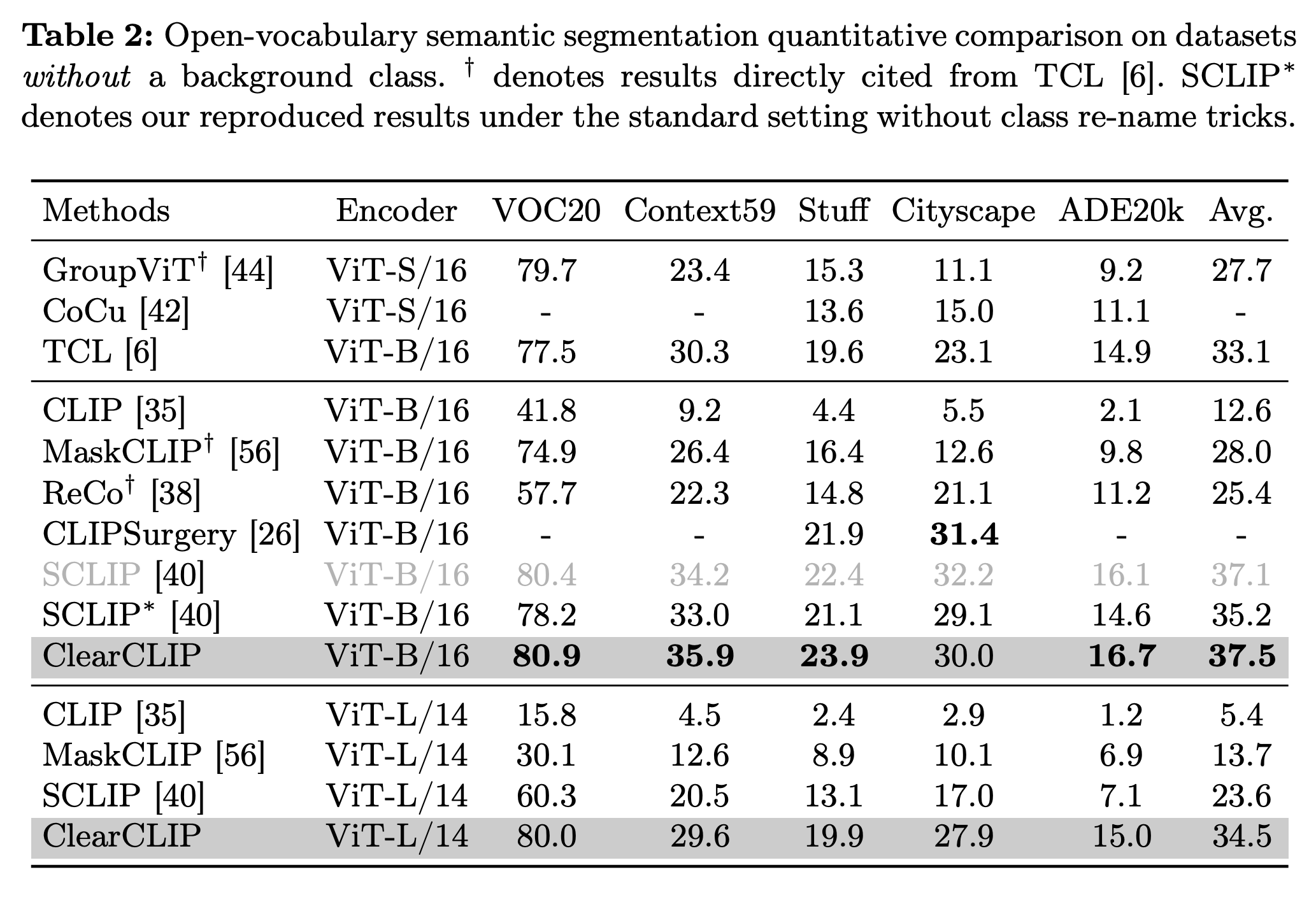
文章关注的任务为用VLM(如CLIP)做开放词汇分割,motivation主要来自于作者的一个观察:分割图中的噪声主要来自于残差连接,这会导致在文本-图像预训练更加强调全局特征,从而牺牲了局部判别能力,从而导致了分割结果中的噪声。为此作者提出了ClearCLIP,对CLIP的特征进行解耦,从而提升开放词汇分割方法的性能。最后一层的主要改动分为三点:移除残差连接,实现self-attention以及丢弃FFN。因此,ClearCLIP能够生成更加干净且准确的分割结果。
Method
CLIP的残差结构
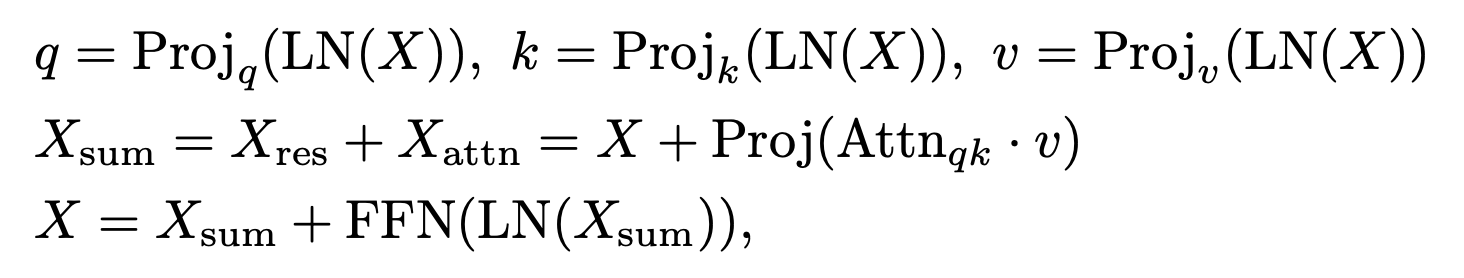
最简单的基于CLIP的dense prediction就是拿类名对应的text embedding去query图像特征,但是CLIP本身是通过image-level contrastive loss进行训练的,将text与region对应的能力非常弱。许多方法尝试修改最后一层的为self-attn或identity-attn(如),旨在对空间信息进行重新整合。然而,这些方法仍然会产生次优的带有噪声的结果,同时,当模型尺寸scale到ViT-L时,这些方法的表现不佳。为此,作者对噪声产生的原因进行了研究。
首先,作者分析了最后一层中残差连接以及的二范数:
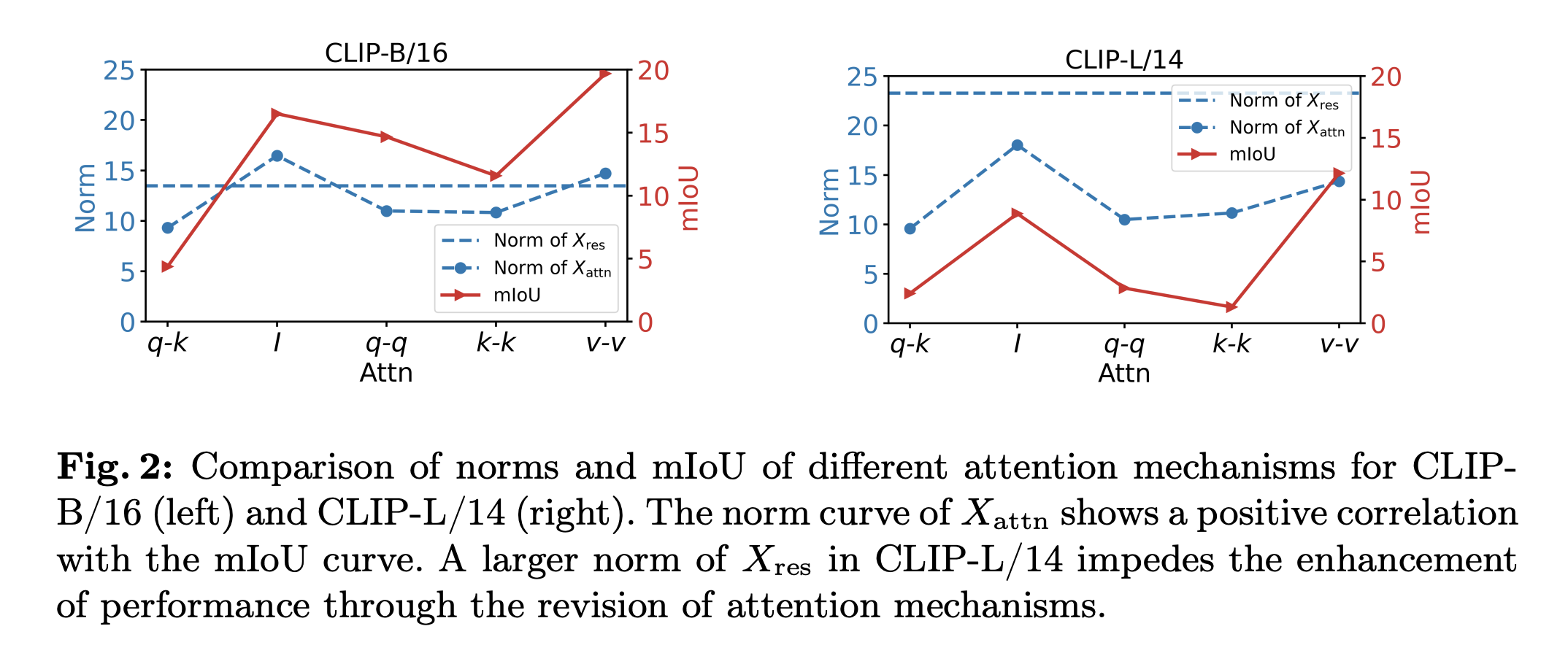
两个图的共性为的mIoU曲线和范数曲线表现出一定的正相关性。区别在于:CLIP-B/16的res范数远小于CLIP-L/14的res范数,同时CLIP-B/16中注意力修改在q-k baseline上是一致的(CLIP-L/14则不然)。因此,作者假设只有当res范数比较小的时候,对于注意力的修改才是有效的。因此作者假设,残差连接是导致CLIP在密集预测任务表现不佳的主要原因。为此,作者在coco上进行了实验:
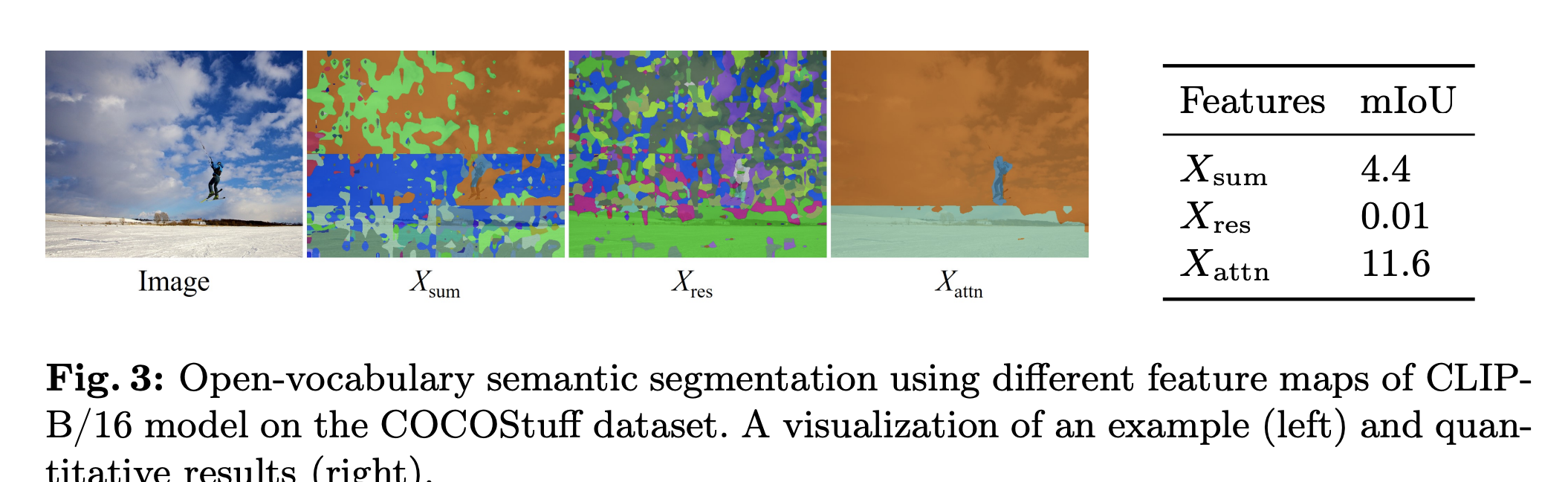
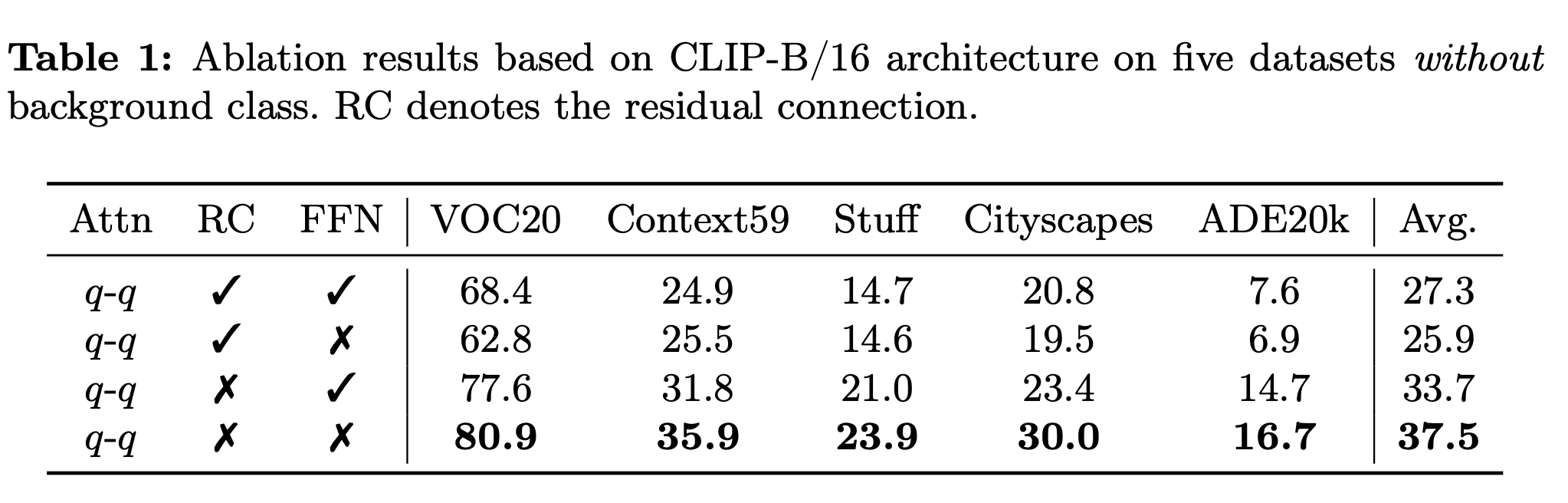
根据结果,残差连接只会起到负面作用,分割结果中的噪声很可能来自于残差连接。作者还进行了一系列分析:
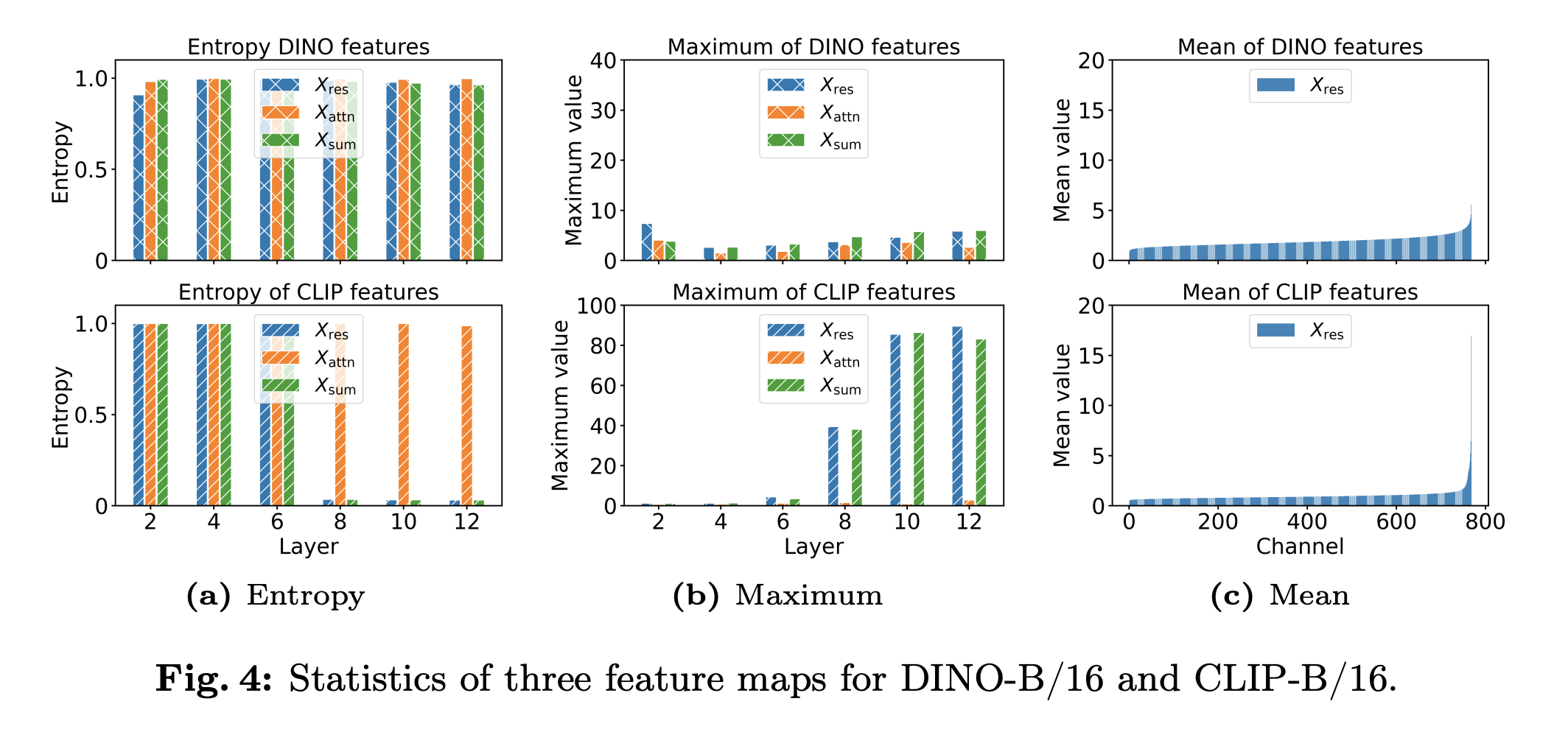
对于CLIP-B/16,和的最大值随着层深逐渐增加,因此其熵急剧下降。通过观察特征图可视化结果以及每个通道的平均归一化均值发现,这些峰值出现在少数通道中,这很有可能就是CLIP在密集预测任务中表现不佳的原因,同时这种现象在较大的模型中更加明显,因此之前的方法在CLIP-L/14中效果不好。因此,作者最终决定直接舍弃残差连接,从而提升方法性能。
此外,作者还讨论了FFN的影响。之前的工作发现,在推理期间,FFN对于图像表征的影响几乎可以忽略不计,同时最后一个block的FFN输出的特征与最后的分类特征有非常大的cosine夹角。本文中,作者发现在OVS任务中移除FFN对原始的CLIP不会有很大影响,但能极大程度提高移除了残差连接的CLIP的性能(特别是对于CLIP-L/14这种模型而言)。
基于上述观察,作者选择的最终方案:
注意力中可以选择不同组合的query-key,实验证明qq组合效果最好。
实验
注意,该方法无需训练。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2021-07-27 2021“MINIEYE杯”中国大学生算法设计超级联赛(3)1007. Photoshop Layers(前缀和)
2021-07-27 2021“MINIEYE杯”中国大学生算法设计超级联赛 1004. Game on Plane(几何)
2021-07-27 2021“MINIEYE杯”中国大学生算法设计超级联赛(3)1011. Segment Tree with Pruning(记忆化搜索)
2020-07-27 HDU6768 The Oculus(Hash)
2020-07-27 HDU6672 Lead of Wisdom(爆搜)