GSVA: Generalized Segmentation via Multimodal Large Language Models论文阅读笔记
Motivation & Abs
Generalized Referring Expression Segmentation (GRES):相比于原始的RES任务,一个文本描述里可能出现多个需要分割的物体,或者没有需要分割的物体,难点在于建模不同实体之间复杂的空间关系,以及识别不存在的描述。现有的方法如LISA难以处理GRES任务,为此作者提出了GSVA,利用多个<SEG>提示分割模型生成多个mask,同时插入<REJ> token以应对没有需要分割的物体的情况。
Method
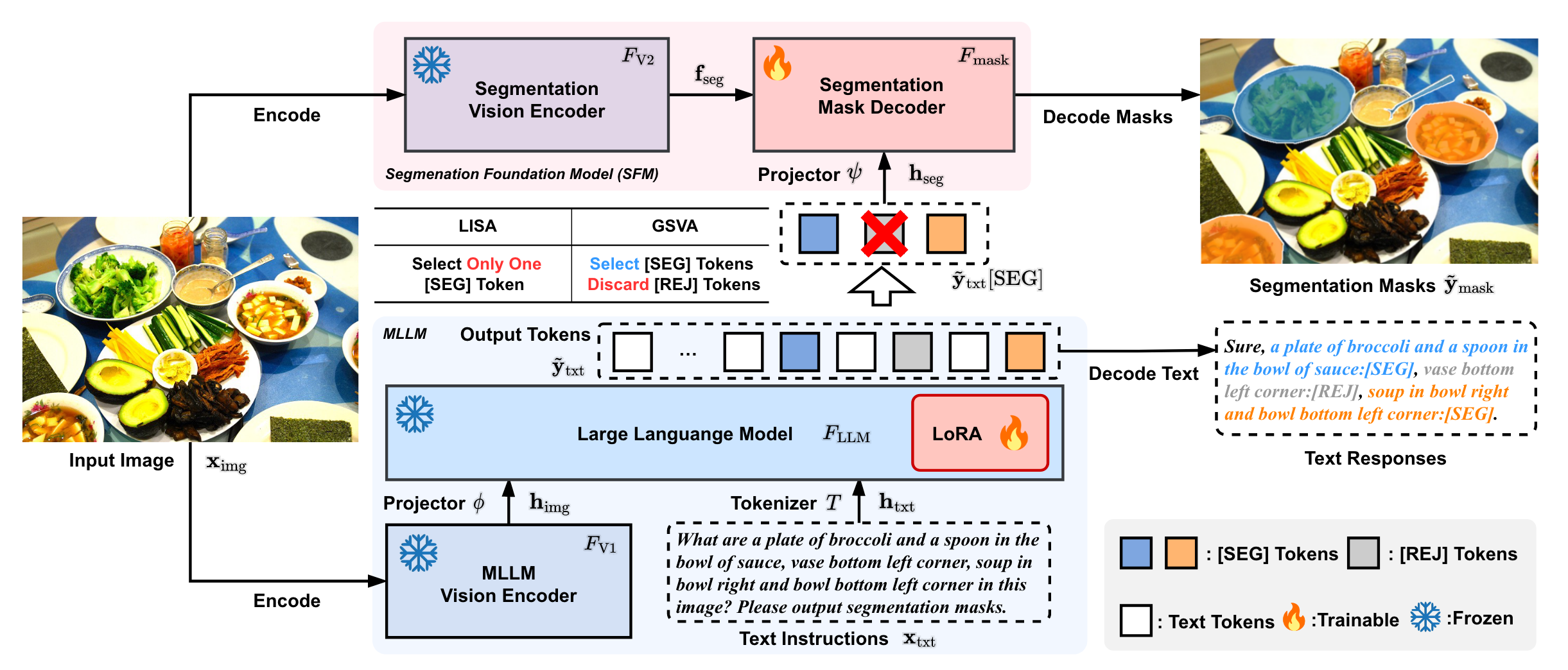
结构
与LISA类似,GSVA的结构分为MLLM(作为对齐的视觉语言认知模块)以及分割基础模型(SFM)。MLLM由decoder-based LLM (自回归的形式生成文本应答)以及vision encoder 从输入图像提取特征,还有一个线性层对齐两个模态的特征。
不同的是,LISA 假设输入图像及其相应指令中仅存在一个目标来进行分割。然而 GSVA 将其扩展到具有多个目标和空目标的新场景,包括多个 [SEG] 标记来调用分割和 [REJ] 标记来拒绝图像中不存在的不合理指示目标。如图,GSVA 在输出序列中支持多个 [SEG]/[REJ] token,选择所有 [SEG] token并丢弃每个 [REJ] token。
GRES: Task and Challenges
Task
Generalized Referring Expression Segmentation (GRES)不对一个文本表达中的参考目标数量作出限制,目标可以是多个实例,或者没有目标。
Challenges
多目标 / 无目标。
对比Reasoning Segmentation
reasoning segmentation的指令更加隐式 / 复杂;而GRES则需要模型理解复杂的空间关系。
Multiple [SEG] Tokens for Multiple Targets
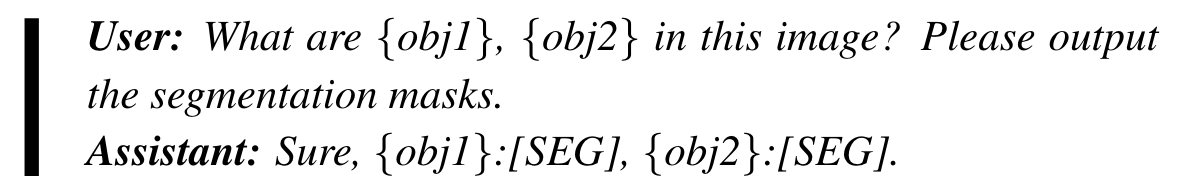
为了防止歧义,每个seg token前先给出mask的expression。这种能力可以看做隐式多模态上下文学习(ICL)。
Rejecting Empty Targets via [REJ] Tokens
GRES中与expression不匹配的目标应该被视为空目标(负样本),之前的方法如LISA则无法识别这些负样本(不存在对应的训练数据)。为此,GSVA对于图像中不存在但在expression中出现的目标预测为[REJ]:

实验
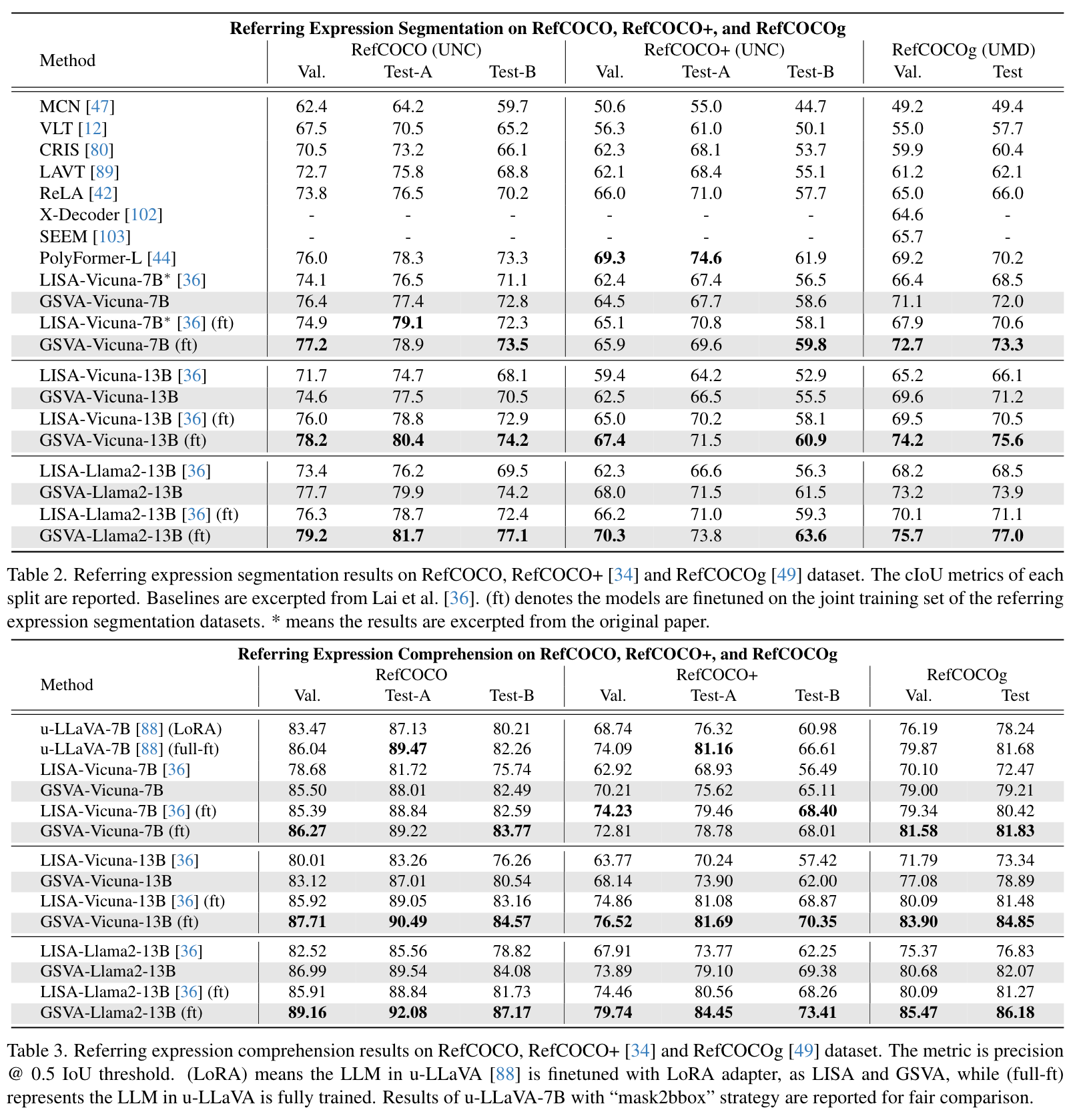
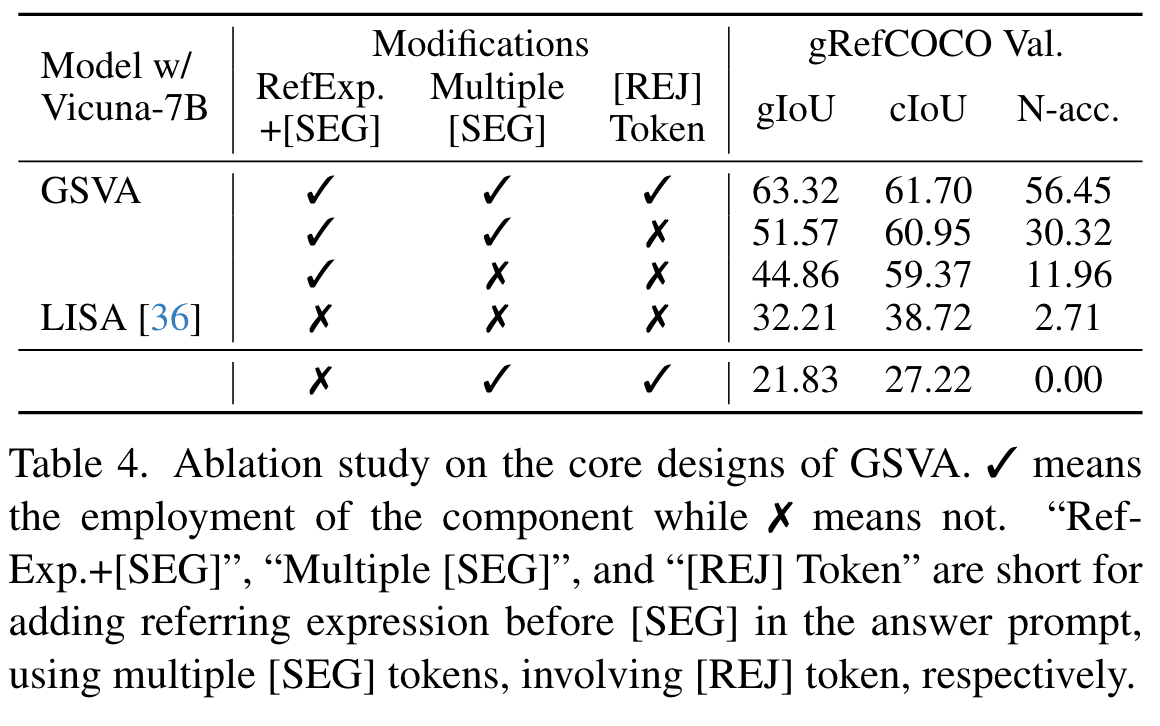



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!