F-LMM: Grounding Frozen Large Multimodal Models
Motivation & Abs
为现有的多模态大模型引入visual grounding的能力能够增强AI对世界以及人机交互的理解,然而现有的方法通常需要对LLM的参数进行FT以学习额外的seg token,同时过拟合grounding和segmentation的数据集,这会导致对于通用知识以及指令遵循能力的灾难性遗忘。为此作者提出了F-LLM,核心思想在于冻结LLM以保持通用知识,同时利用word-pixel attention map进行分割。
Method
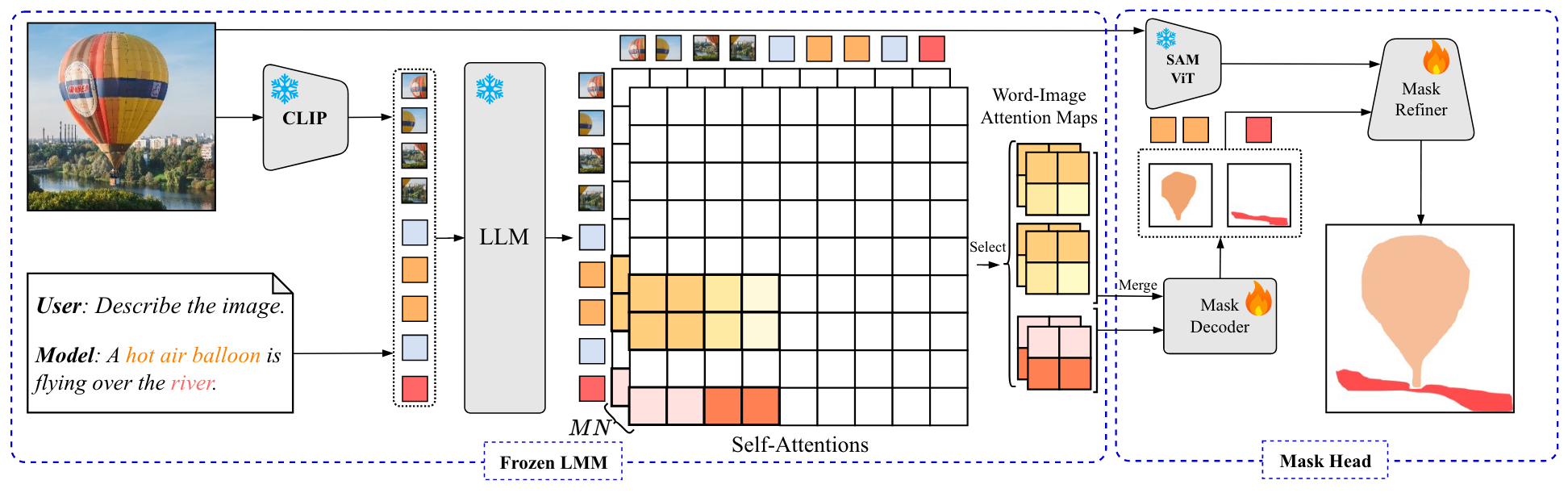
Segmentation Priors from Frozen LMM
Vision-Language Sequence
Large Multimodal model(LMM)包括一个image encoder ,一个vision-language projector 以及一个LLM 。输入为图像 以及对应的文本。输入图像通过image encoder编码,随后通过投影到LLM的input space,序列长度为hw:
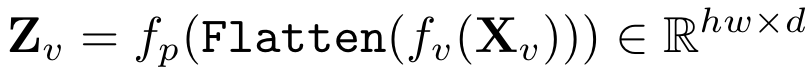
同理,文本输入首先被编码为离散的token,随后投影,序列长度为L:

image和text embedding拼接送入LLM。
Segmentation Priors in Self-Attention
在中,输入的vision-language sequence主要通过因果自注意力(causal self-attention)进行处理。具体来说,对于vision-language sequence 在位置i的work token,其embedding 通过前i个embedding的加权和进行更新:
。考虑到多模态场景下的word-image交互,可以选择word token与image mebedding的attention weight:
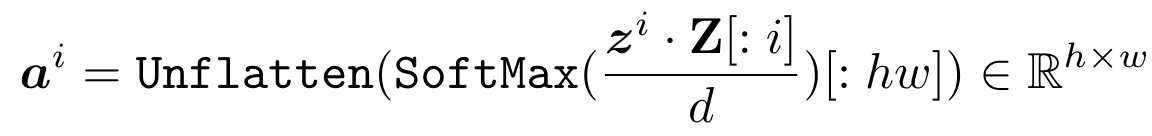
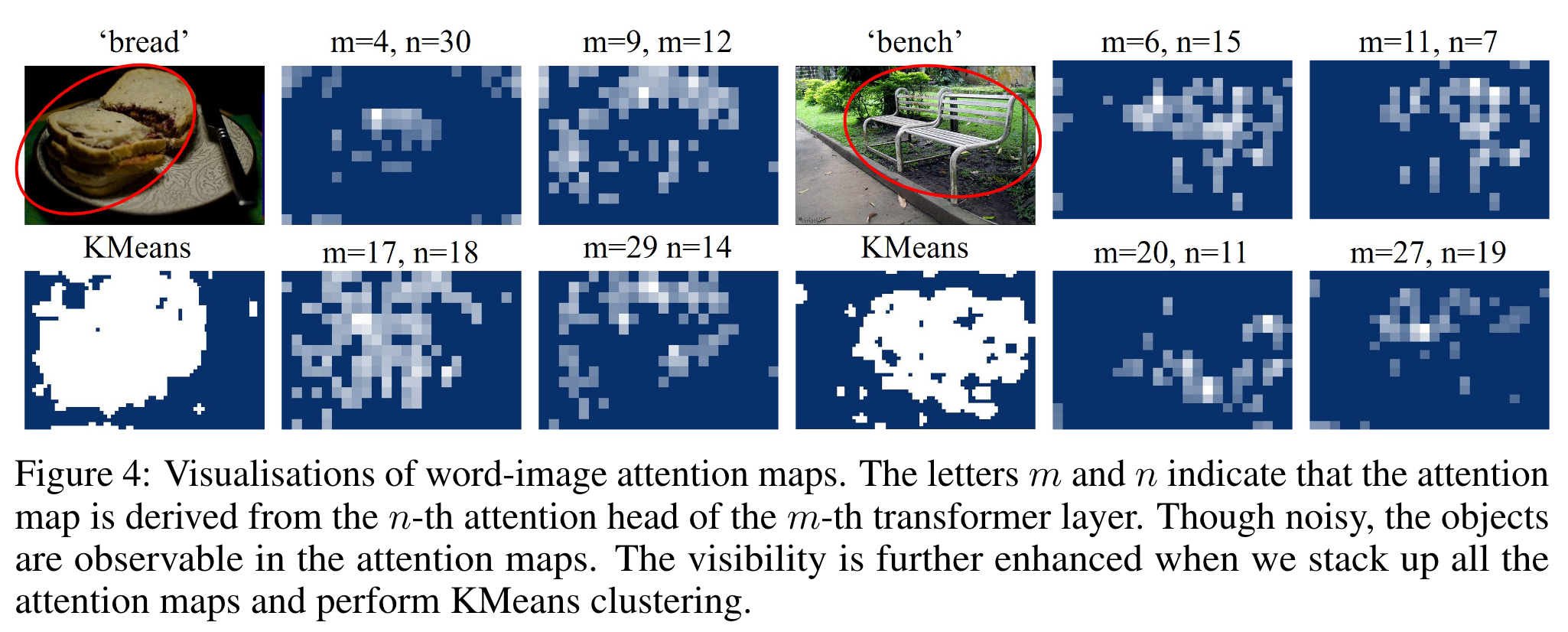
如图所示,attention map提供了有意义的分割先验以及用于grounding的视觉和几何线索。
Language Cues
F-LLM还可以用中对象相应的文本嵌入为grounding提供额外的语言线索。
Visual Grounding with Mask Head
作者使用来自冻结LMM的分割先验进行像素级的grounding,需要用到一个mask decoder以及一个mask refiner。
Mask Decoder
mask decoder 为2D CNN结构,将word-image attention转换为grounding object的mask logits,其具体结构为3个stage的U-Net。对于被多个word描述的同一个物体,作者将其对应的word-attention map进行合并从而得到一个单独的attention map (通过element-wise的average或max操作)。对于每个attention map,还需要对其进行归一化使得所有元素的和为1。对于总共M层,有N个头的情况,作者将个attention map进行concat:,作为mask decoder的输入。考虑到分割模型需要高分辨率的输入,作者将堆叠的attention map上采样为大小。随后,mask decoder将映射为mask logits:。获得预测结果:。训练过程中,通过BCE和DICE损失优化mask decoder。
Mask Refiner
mask refiner 改进自SAM的mask head,使用SAM的prompt encoder将转换为dense prompt embedding(2D特征图)以及将的box转换为box embedding。除了来自mask和box的prompt,还利用了语言线索。考虑来自M个Transformer layer的text embedding,作者训练了M个可学习的标量从而对这些embedding进行加权,得到的结果通过一个linear层后拼接到box embedding从而构成SAM mask decoder的sparse embedding。这些prompt embedding以及SAM encoder生成的image embedding共同送入mask refiner 用于生成细粒度的mask预测结果。训练期间SAM的encoder是冻结的,损失同样为BCE和DICE。
User-AI Interaction with Grounding

实验
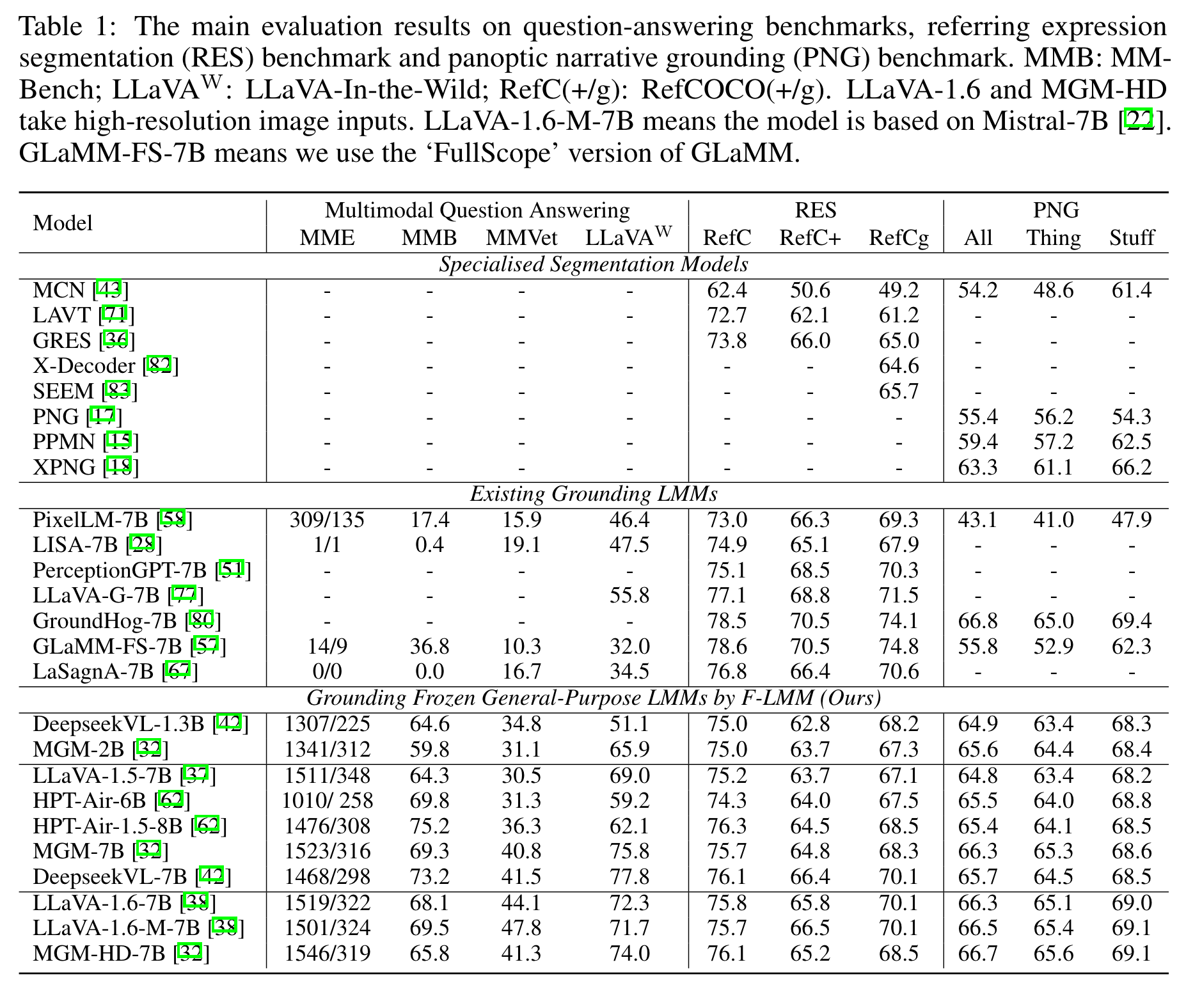
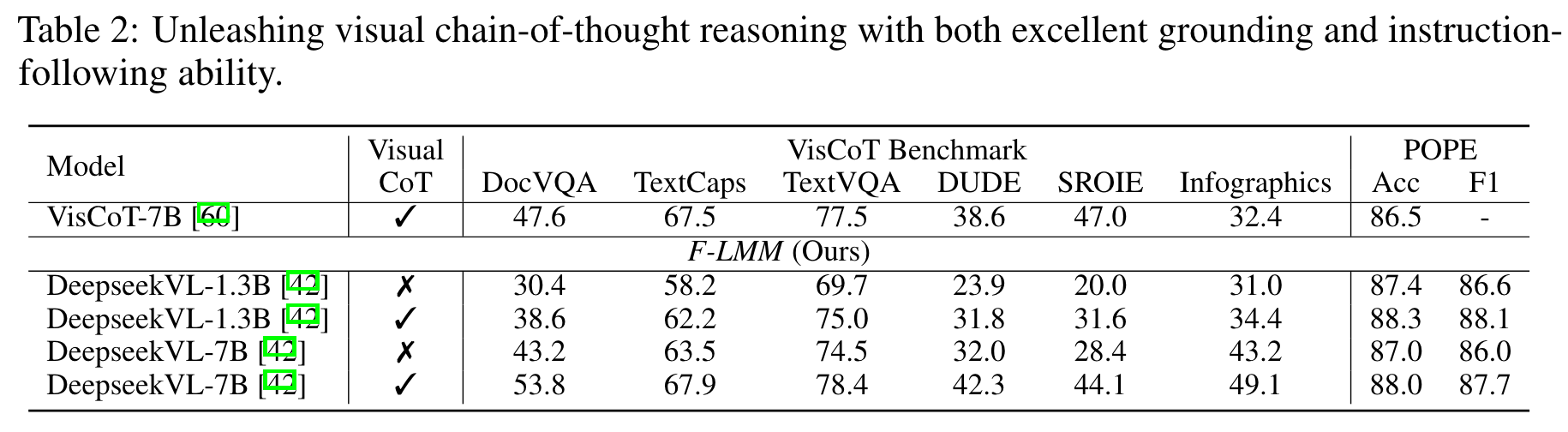
训练:8卡A800(40G)训练20h(只在RefCOCO(+/g)y i集PNG数据集训练)。
Questions
F-LMM怎么判断用户是否要求做分割?还是简单的VQA?等有时间看一下code
还有一点就是F-LMM似乎无法做reasoning seg



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!