Semantic-SAM: Segment and Recognize Anything at Any Granularity论文阅读笔记
Motivation & Abs
现有的结构限制了模型以端到端的方式预测多粒度分割mask;同时目前没有大规模的语义感知&粒度感知数据集,同时不同数据集之间语义和粒度的固有差异给联合训练工作带来了重大挑战。
本文提出通用图像分割模型,能够以任何粒度分割识别任何内容,给一个点作为prompt能够生成多种粒度的mask。
Dataset
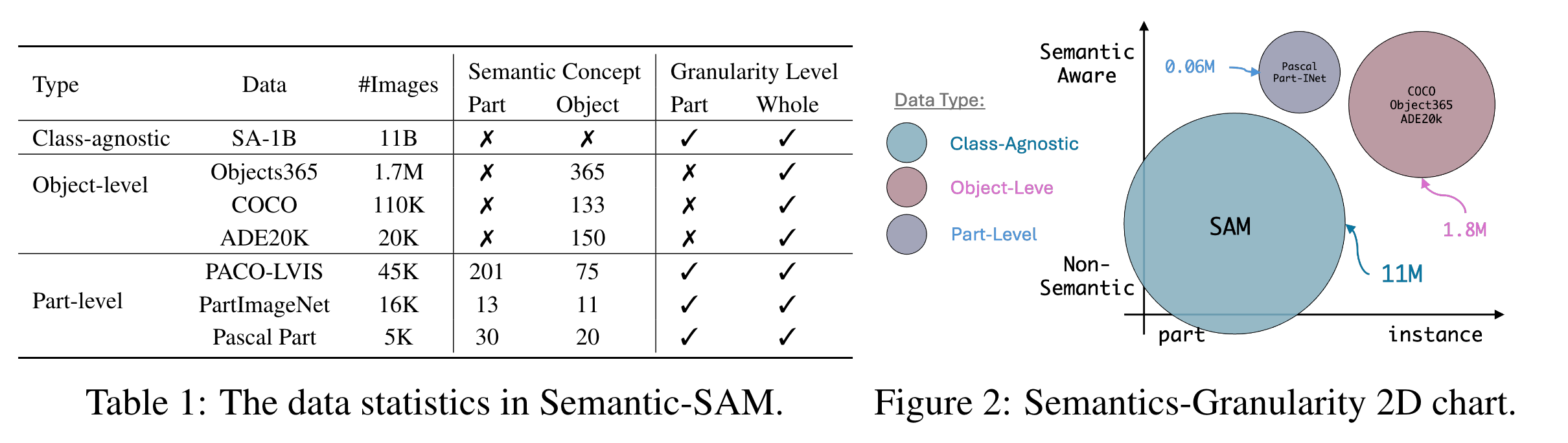
7个包含不同粒度级别mask的数据集:SA-1B, COCO panoptic, ADE20k panoptic, PASCAL part, PACO, PartImageNet, Objects365。
Method
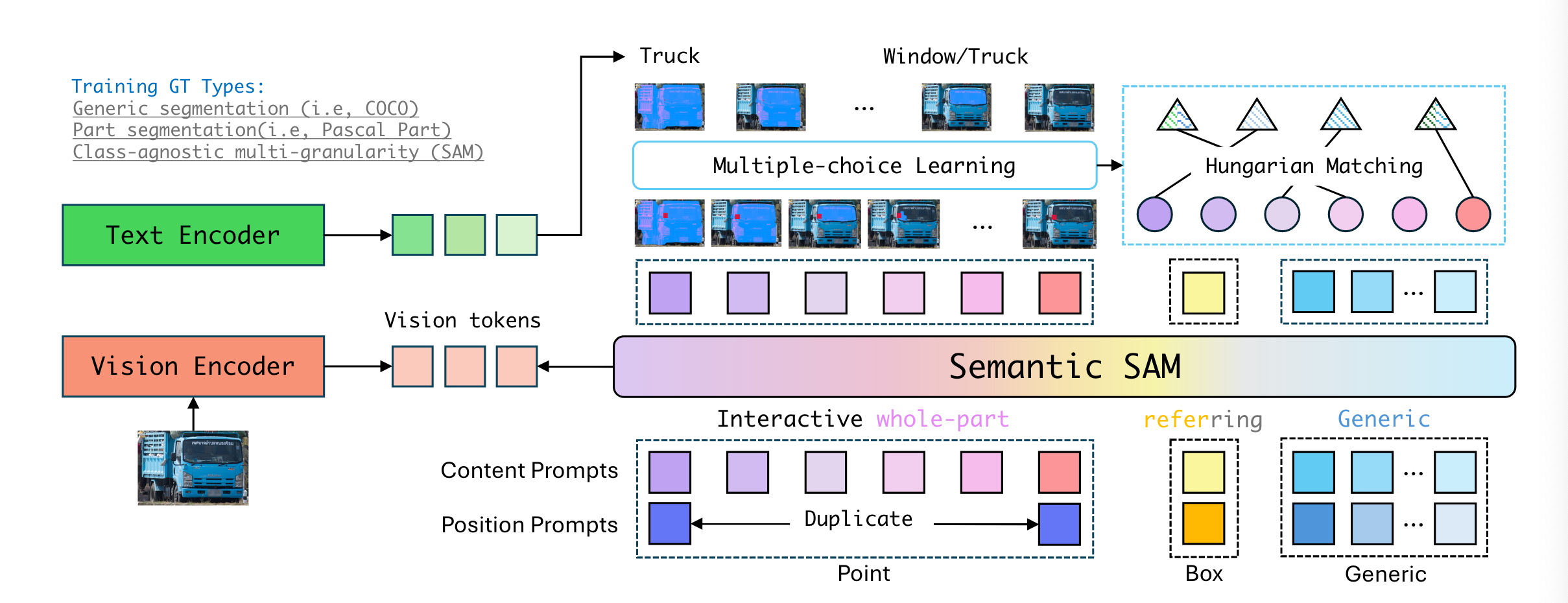
Model
Semantic-SAM基于Mask dino,利用基于query的mask decoder来生成语义感知和多粒度mask。相比于通常的query,Semantic-SAM还支持两种promot:点以及边界框。对于点,作者用极小的边界框进行近似,因此可以用一种统一的形式表示。为了捕获不同粒度的mask,每一次click首先被编码为position prompt以及K个content prompt,每一个content prompt时可学习的,用以表示不同粒度的信息,文章中K的取值为6。content embeddings表示为一系列的query vector ,对于第i个query,,时对于粒度等级的embedding,用于区分不同的query type(点 or 边界框)。
mask decoder: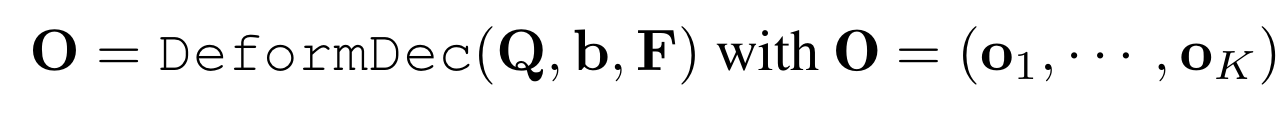
为encoder提取的特征,DeformDec是deformable decoder,接收query feature、refernece box以及图像特征。每一个包含预测的类别以及mask,用于计算分类和分割的损失。
Training
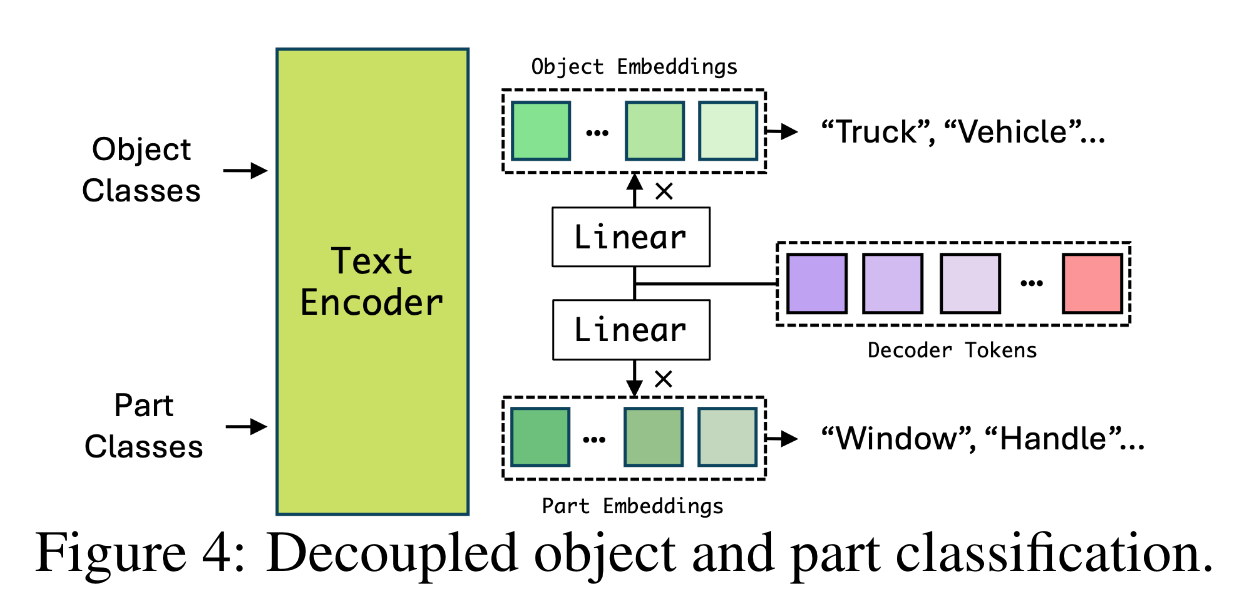
有的数据集包含实例级别的标注,有的则包含part级别的标注,SA-1B没有语义标注但mask涵盖了所有语义级别。为此,作者提出将object识别和part识别进行解耦,如图所示。需要注意,所有数据共享统一的格式但损失可能不同,如下表所示:

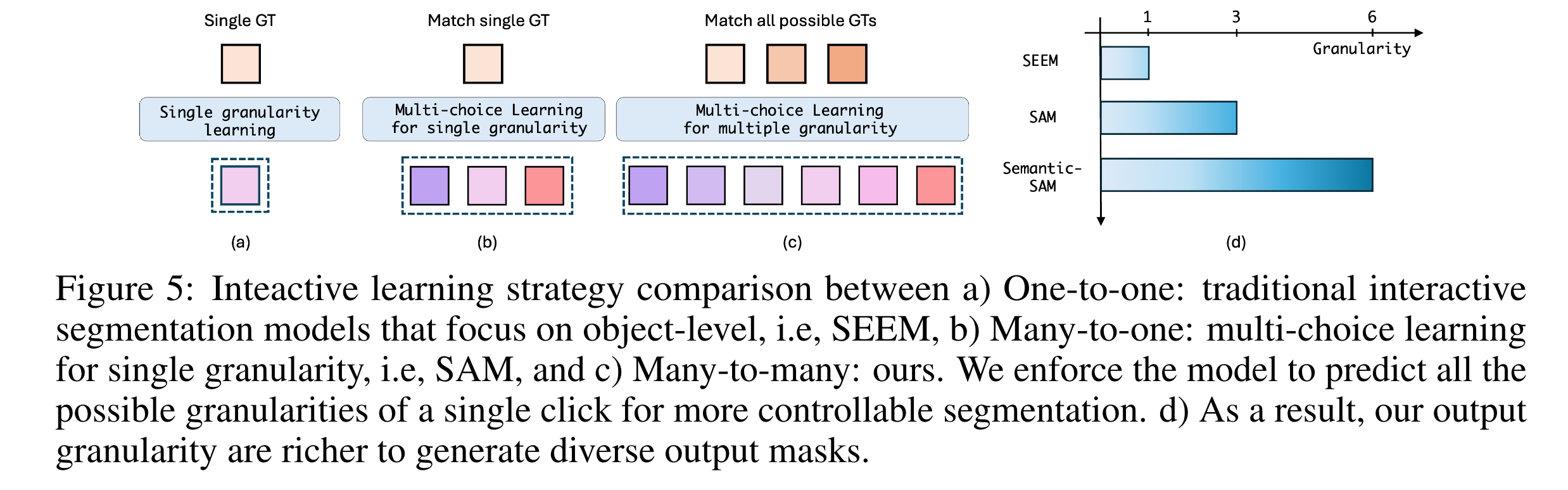
为了赋予模型多粒度分割的能力,作者在训练中使用了many-to-many的匹配策略。
对于框输入和通用分割,为了从输入框生成掩码,作者遵循与去噪训练(DN)类似的想法。即向真实框添加噪声,以模拟用户不准确的框输入,这些噪声框充当decoder的spatial prompt。该模型经过训练,可以在给定噪声框的情况下重建原始框和mask。对于box prompt的content part,作者使用可学习的标记作为通用提示。对于通用分割,流程与Mask DINO相同。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2023-06-17 RuntimeError: CUDA error: CUBLAS_STATUS_INTERNAL_ERROR when calling cublasCreate(handle)
2020-06-17 Chapter 11 Inheritance