LISA: Reasoning Segmentation via Large Language Model
Motivation & Abs
现有的感知系统依赖人类的指示,难以主动推理以理解人类意图。
新任务:reasoning segmentation,模型需要根据给定的复杂 / 具有隐含意义的文本输出相应的seg mask。
新的benchmark:包含1000张左右图像的数据集(image-instruction-mask)。
模型:LISA,既有LLM的语言生成能力,又有生成分割mask的能力。训练好的模型在非reasoning的数据集上也有着较强的zs能力,同时仅仅使用少量reasoning data对模型进行ft就可以大幅提升性能。
Reasoning Segmentation
reasoning segmentation相当于更加困难的referring segmentation,查询的文本是更复杂的表达或者更长的句子,涉及到对现实世界知识的推理。数据集:文本为短语和长句子,图像总计1218张,包含239张训练图像,200张验证图像以及779张测试图像。
Method
Architecture
Embedding as Mask. 之前的方法如LLaVA以及BLIP2等仅能接受图片输入同时输出文本,无法输出细粒度的分割mask。VisionLLM提供了一种解决方案,将掩码表示为一系列的多边形顶点,使之能够用文本描述,然而使用多边形序列的端到端训练优化困难,并且可能会损害泛化能力,除非使用大量数据和计算资源。为此,作者提出了使用embedding作为mask的范式从而将分割能力融入LLM,对LLM的词汇表进行扩充,额外添加了<SEG> token, 用来代表输出的分割结果。
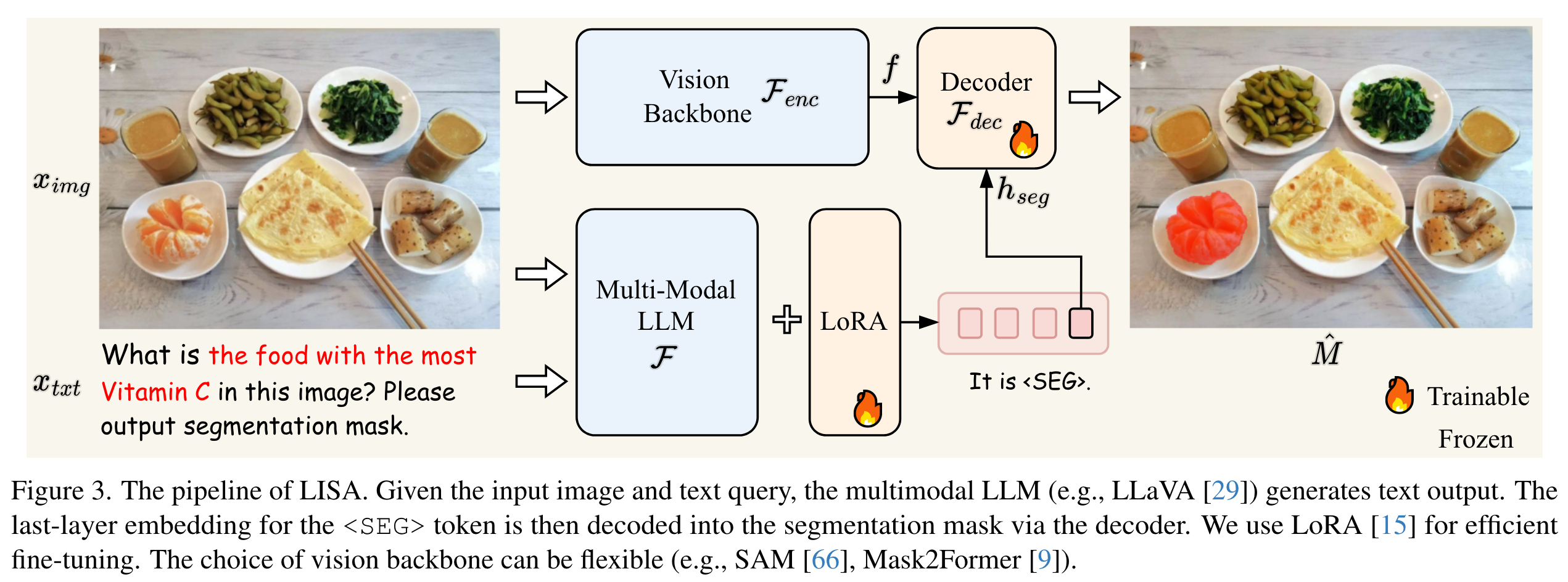
给定文本指令以及输入图像,作者将其输入多模态LLM ,得到输出(包含<SEG>标记)。同时将SAM image encoder给出的dense feature与<SEG>送入SAM的decoder即可得到分割mask。
损失函数:
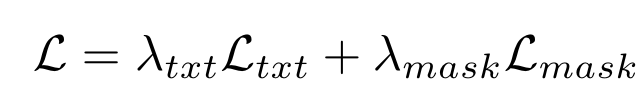
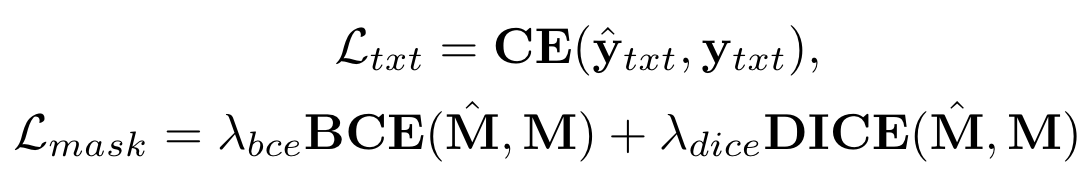
这种方式能够支持端到端的训练,比两阶段的方法更加有效。
训练
训练数据形式。
Semantic Set Dataset:训练时对每张图片随机选择几个类别,类别对应的mask为GT。QA模版如同:“USER: <IMAGE> Can you segment the {class name} in this image? ASSISTANT: It is <SEG>.”
Vanilla Referring Segmentation Dataset:数据包含图片和对应物体的文本描述。QA模版:“USER: <IMAGE> Can you segment {description} in this image? ASSISTANT: Sure, it is <SEG>.”
Visual Question Answering Dataset:目的是保持MLLM的VQA能力。
可学习参数。用lora微调LLM,冻住image encoder,训练mask decoder、LLM token embedding、LLM head、projection layer。
为什么不会发生灾难遗忘:训练使用了VQA数据。
实验
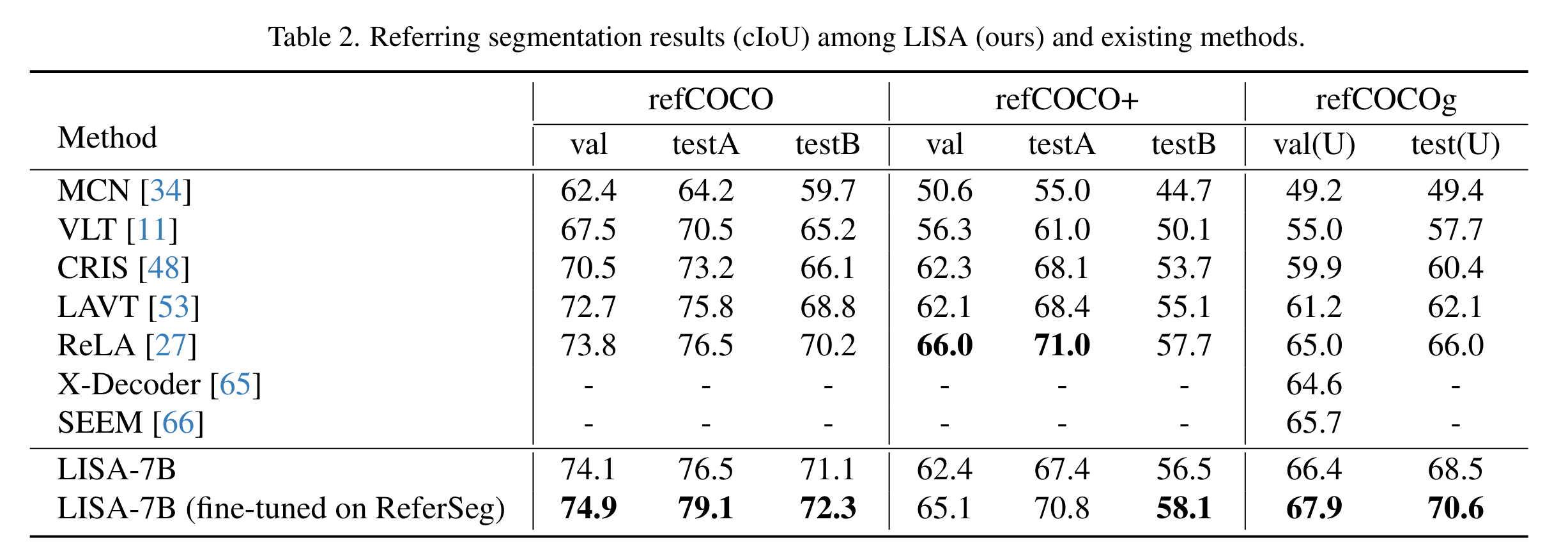
Metric: gIoU和cIoU,gIoU 为所有图像IoU的平均值,而 cIoU 由累积并集上的累积交集定义。由于cIoU高度偏向于大面积物体,而且波动太大,所以首选gIoU。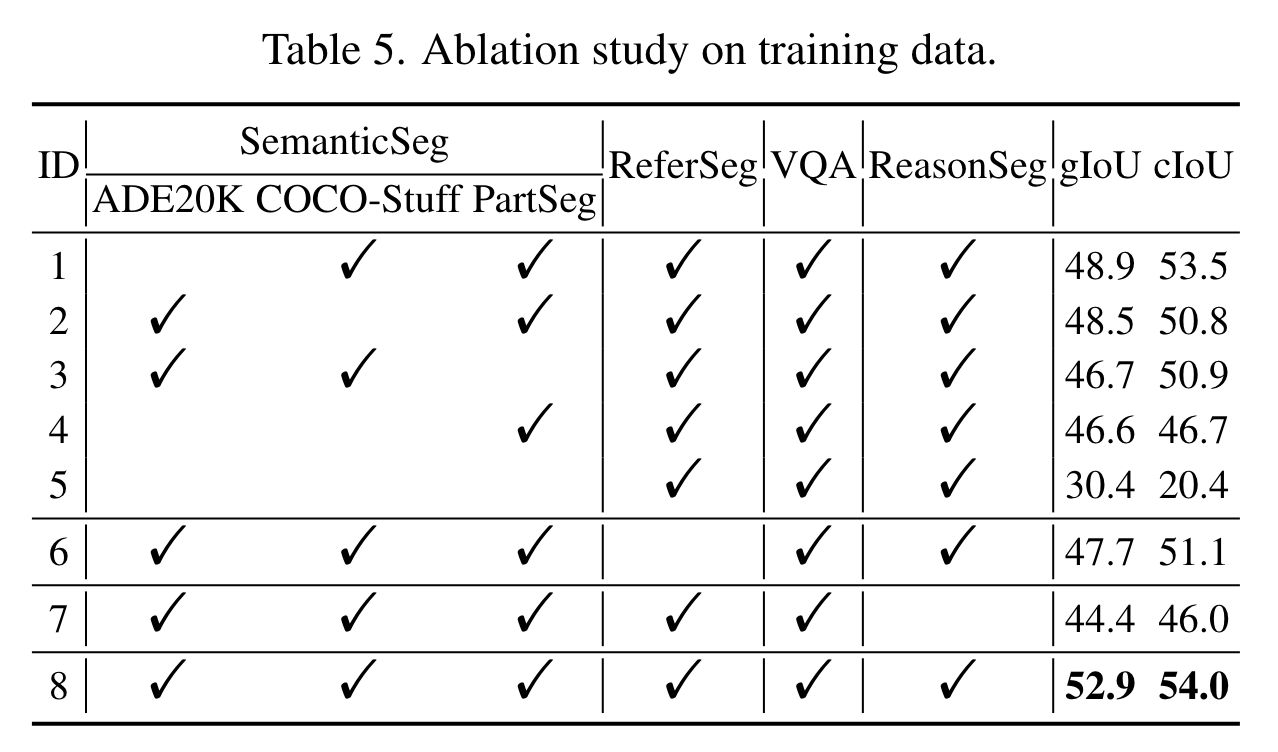



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!