FOSTER:Feature Boosting and Compression for Class-Incremental Learning论文阅读笔记
摘要
先前的类增量学习方法要么难以在稳定性-可塑性之间取得较好的平衡,要么会带来较大的计算/存储开销。受gradient boosting的启发,作者提出了一种新型的两阶段学习范式FOSTER,以逐步适应目标模型和先前的集合模型之间的残差,使得该模型能够自适应地学习新的类别。具体来说,作者首先动态扩展新的模块以适应目标模型和原始模型输出之间的残差,之后通过蒸馏去除冗余的参数和特征维度以保持单一的骨干模型。在CIFAR-100等数据集的实验结果表明作者的方法取得了SOTA的性能。
前置知识
Gradient Boosting
可以参考这篇文章帮助理解:https://www.zhihu.com/search?type=content&q=gradient boosting
Class Incremental Learning
方法
From Gradient Boosting to Class-Incremental Learning
假定在阶段t已经得到了前一个阶段的模型\(F_{t-1}\)(可以被解耦为feature embedding以及linear classifier):\(F_{t-1}(x)=(W_{t-1})^{\top}\Phi_{t-1}(x)\),其中\(\Phi_{t-1}(·):\mathbb{R}^D\rightarrow\mathbb{R}^d\),\(W_{t-1}\in \mathbb{R}^{d\times|\hat{\mathcal{Y}}_{t-1}|}\)。受到gradient boosting的启发,作者训练了一个新模型以适应y和\(F_{t-1}\)的残差。新模型\(\mathcal{F}_t\)同样包含\(\phi_{t-1}(·):\mathbb{R}^D\rightarrow\mathbb{R}^d\),\(\mathcal{W}_{t}\in \mathbb{R}^{d\times|\hat{\mathcal{Y}}_{t}|}\),其中\(\mathcal{W}_t\)可以被分解为\([\mathcal{W}_t^{(o)},\mathcal{W}_t^{(n)}]\),\(\mathcal{W}_t^{(o)}\in\mathbb{R}^{d\times |\hat{\mathcal{Y}}_{t-1}|}\),\(\mathcal{W}_t^{n}\in\mathbb{R}^{d\times |\mathcal{Y}_t|}\)。因此,训练过程可以被表示为:
和gradient boosting一样,令\(\mathcal{l}(·,·)\)为均方误差损失。
理想情况下:
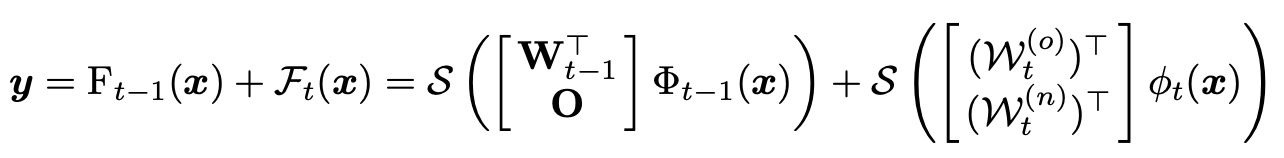
\(\mathcal{S}\)是softmax操作,\(O\in\mathbb{R}^{d\times |\mathcal{Y}_t|}\)是零矩阵或者是\(\Phi_{t-1}\)在\(\hat{\mathcal{D}_t}\)上fine tune得到的。该过程可以表示为如下优化问题:
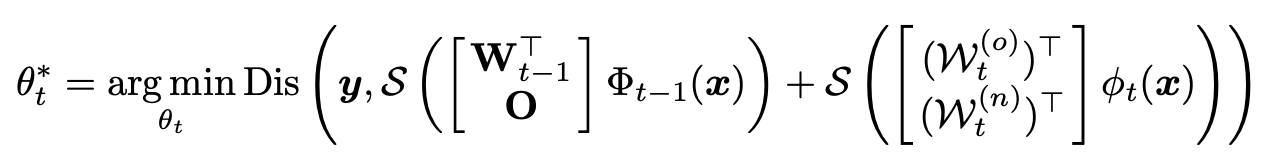
Dis为距离指标,如欧式距离等,\(\theta_t\)为\(\mathcal{F}_t\)的参数。之后,作者将softmax后求和换为求和后softmax,同时使用KL散度作为衡量指标,得到目标函数如下:
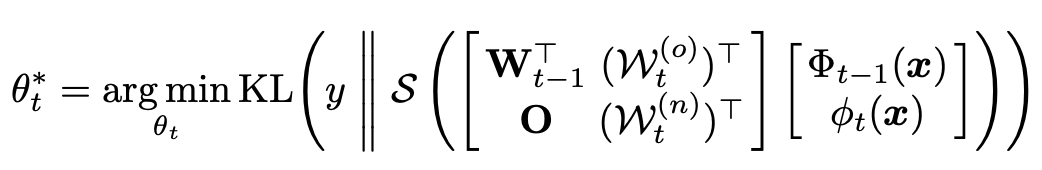
因此,\(F_t\)可以被看作扩大的线性分类器\(W_t\)以及拼接后的超特征提取器\(\Phi_t(·)\):

输出:
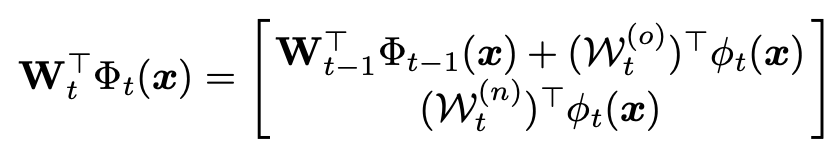
Calibration for Old and New
在新任务训练时,类别不平衡的训练集会导致模型的预测出现偏差,同时,feature boosting倾向于忽略样本数量较少的类别的残差。为此,作者提出了:
Logits Alignment
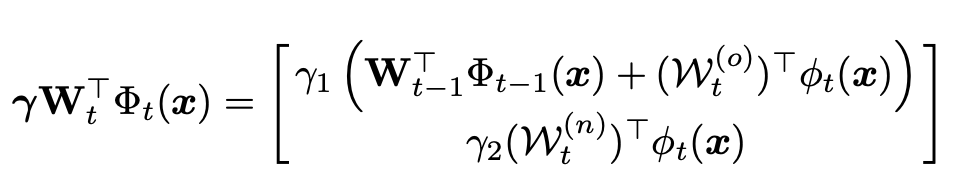
其中\(0<\gamma_1 < 1, \gamma_2 > 1\),\(\lambda\)是一个对角矩阵,这样可以促使模型生成更大的旧类概率,同时降低新类概率值。计算过程如下:
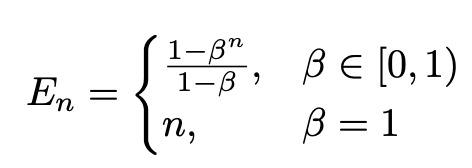
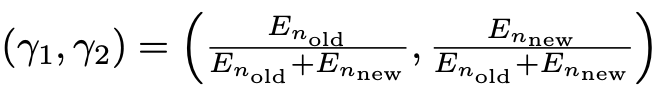
Feature Enhancement
仅仅让\(\mathcal{F}_t(x)\)去适应残差通常是不够的。考虑极限情况:残差为0,则\(\mathcal{F}_t(x)\)不能学到有关旧类别的信息,因此需要对新模型进行提示,整个过程分为两步。首先初始化一个新的线性分类器\(W_t^{(a)}\in\mathbb{R}^{d\times |\hat{\mathcal{Y}}_t|}\),将新的特征\(\phi_t(x)\)变换为所有见过的类别的概率,使新特征能够用于分类:
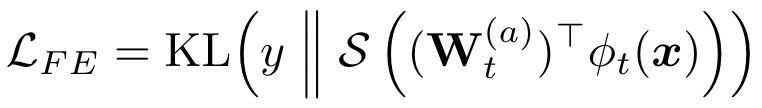
同时,使用one-hot编码向量训练新的分类器可能会导致模型对新类别过拟合,为此作者使用了知识蒸馏:
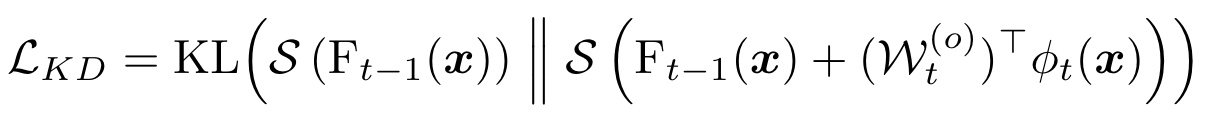
总的损失: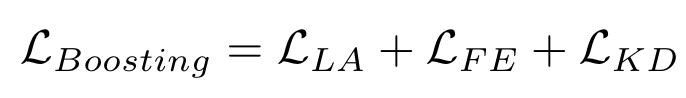
Feature Compression
每一个task都增加一个网络会带来极大的空间开销,因此,作者考虑对模型进行蒸馏,将\(F_t\)的特征空间进行压缩,同时不会带来明显的性能下降。损失函数:
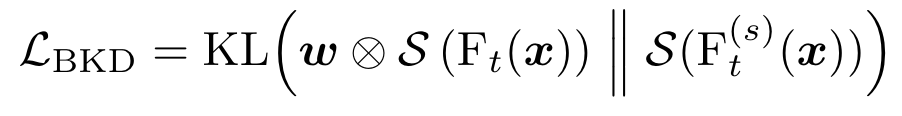
\(⊗\)为tensor的点乘(自动广播),\(w\)是权重向量(由之前的Eq 13得到)。
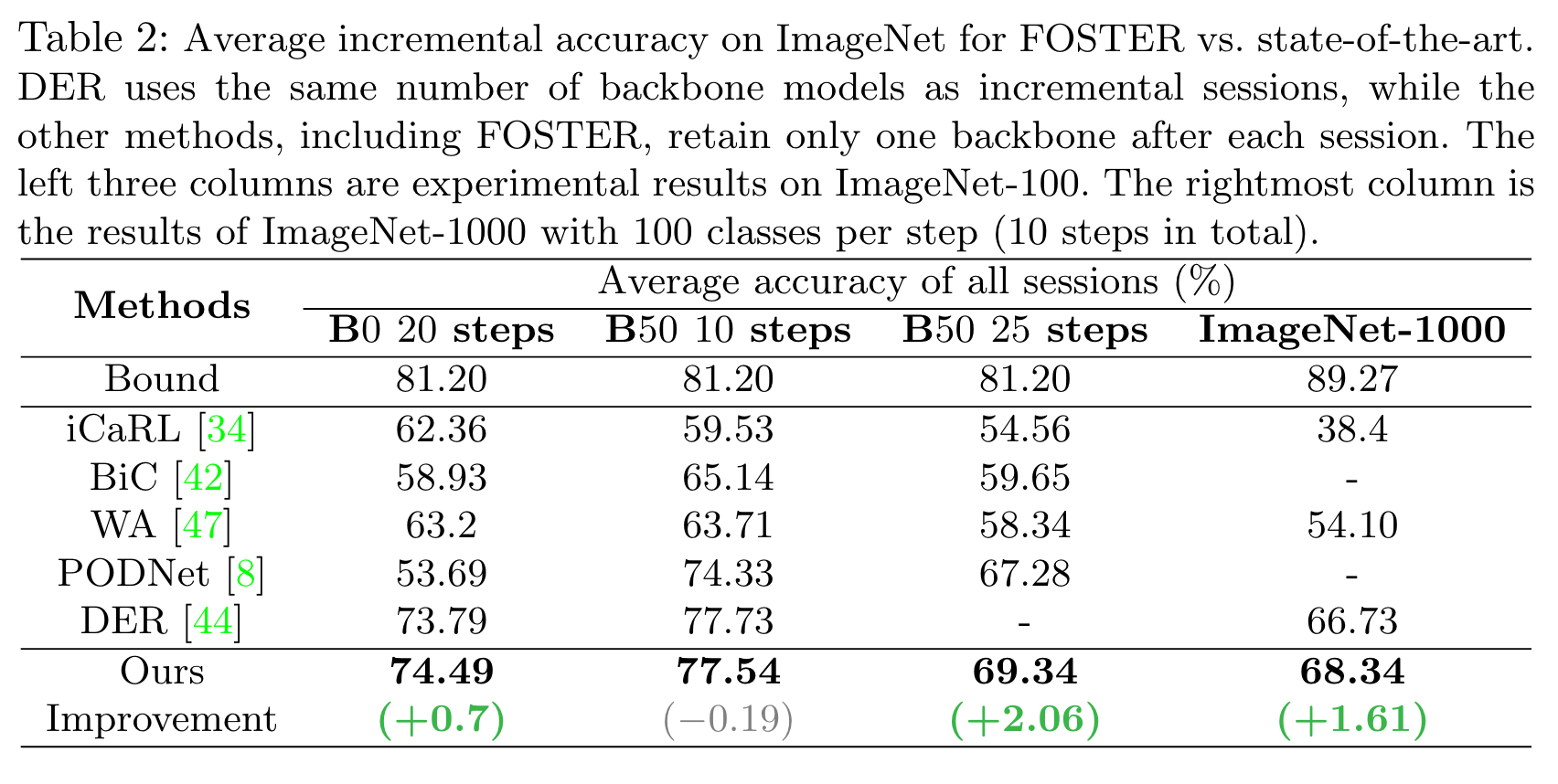
实验