End-to-End Object Detection with Transformers论文阅读笔记
摘要
作者提出了一种新的基于Transformer的目标检测模型DETR,将检测视为集合预测问题,无需进行nms以及anchor generation等操作。同时,对模型进行简单的修改就可以应用到全景分割任务中。
方法
Object detection set prediction loss
DETR给出的是N个预测,N为预先设定的远大于GT目标框数量的一个值,难点在于根据GT对这些预测框进行评分。作者在这里对预测框与GT进行二分图匹配,从而计算损失。具体来说,设为GT集合,为N个预测结果,为了满足二分图完美匹配的条件,作者将GT集合的大小同样扩充为N,多出来的部分用no object来补足。之后,使用匈牙利算法找到一组完美匹配(完美匹配一定是最大匹配),用这一组匹配计算损失(这里的目的实际上是找到一组最小的损失,进行取负之类的操作就可以转换成求最大匹配了)。
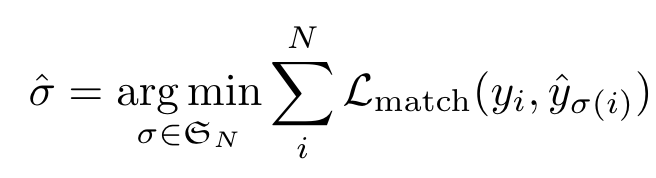
匹配的损失需要同时考虑类别分数以及预测框和GT的相似度。对于GT集合中的每个边界框,可以将其看作,表示类别标签,表示边界框的相对图像的中心坐标和长宽。对于下标为的预测结果,设其预测为类别的概率为,预测框为,可以表示为,最终的匈牙利损失可以表示为:
。在实际训练时,对于no object的对数概率的权重设置为原来的1/10,从而避免类别不平衡的问题。需要注意的是,如果一个预测框匹配到no object,这个匹配的损失是常数0。对于bounding box的损失定义为,这是因为直接计算两个框中心的L1 loss的话,两个框即便中心相近,大小很有可能存在较大差异,因此作者选择使用IoU loss与L1 loss的线性组合。
DETR architecture
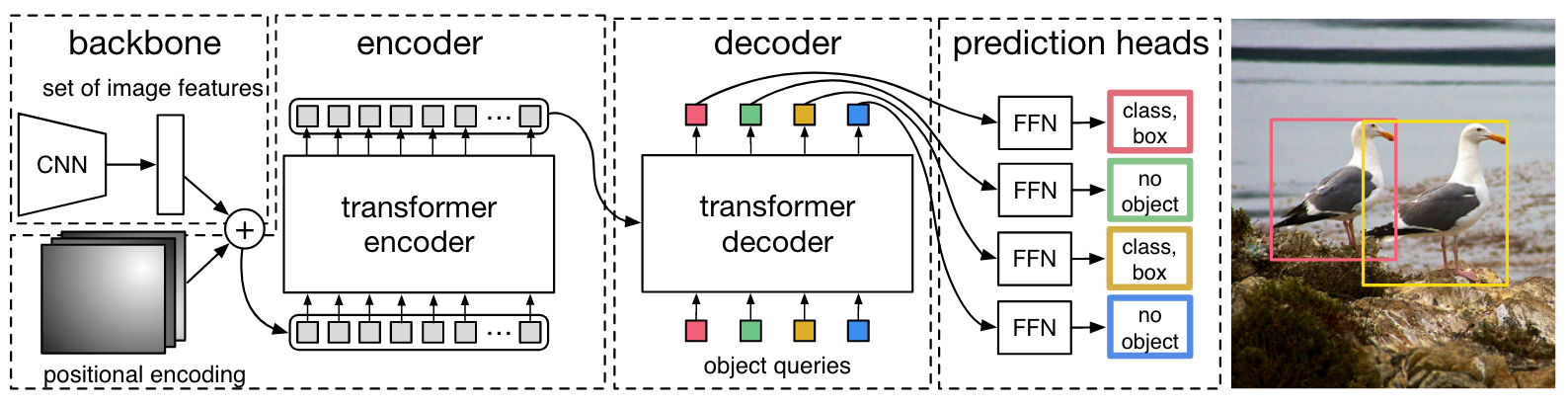
网络使用了一个CNN作为特征提取器,使用Transformer对特征进行编码/解码,将输出送入FFN进行预测。
Backbone
backbone为CNN,对三通道RGB图像提取得到大小为的特征。
Transformer encoder
首先通过1x1卷积将输入特征的通道维度降为d,之后将其维度转换为,与位置编码相加后送入标准的Transformer。
Transformer decoder
decoder同样是标准的Transformer,只不过解码的是N个可学习的query,这些query经过解码后送入FFN就得到了N个预测的box。使用这N个query以及image feature计算注意力可以使模型捕捉到每两个query之间的关系,同时引入了整个图像的上下文信息。
Prediction feed-forward networks (FFNs)
最终的预测通过一个三层的FFN实现。FFN分为两种,一种预测类别概率,一种预测边界框回归参数。类别概率中包含一个no object类,起到的作用类似background。
Auxiliary decoding losses
在训练时作者还使用了辅助损失,可以参考https://ojs.aaai.org/index.php/AAAI/article/view/4182
实验
实验比较有趣的是DETR在全景分割中的应用。作者首先训练模型分辨每个边界框属于stuff还是things,之后使用mask head对于每个框预测一个mask,对于每个像素的所有mask scores求argmax就能得到最终的结果:
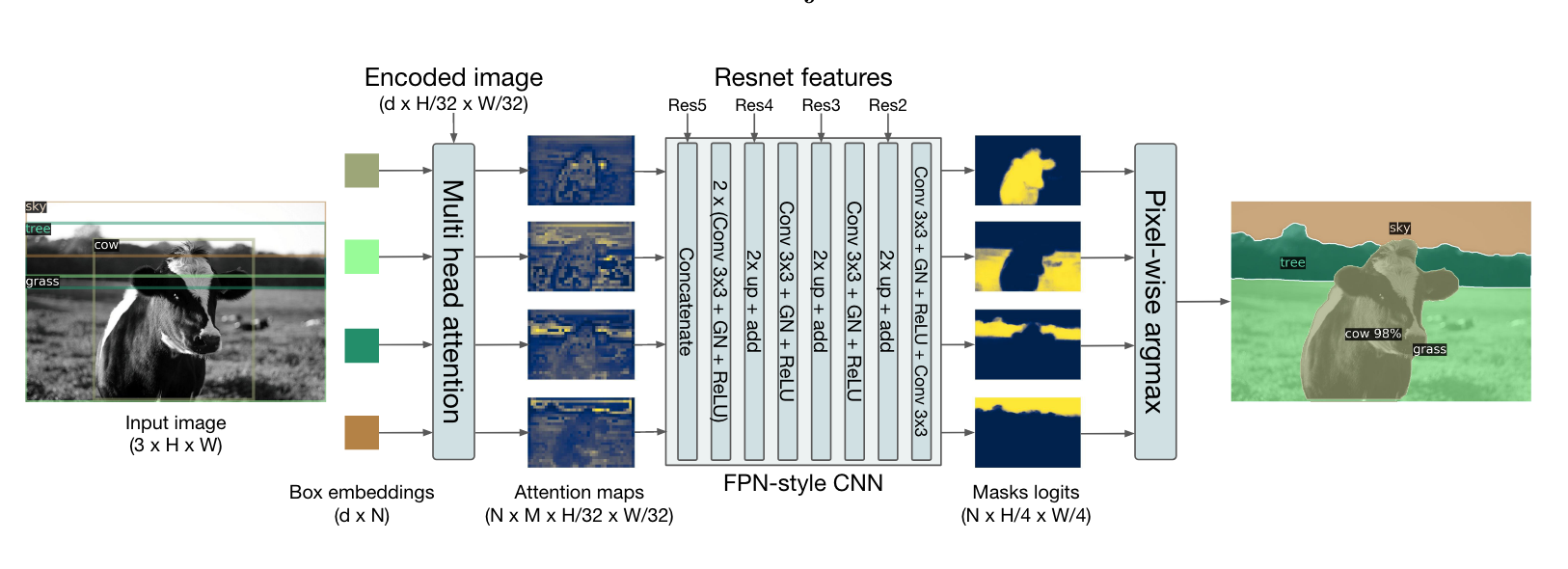
具体过程可以看官方代码https://github.com/facebookresearch/detr/blob/main/models/segmentation.py的PostProcessPanoptic函数。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!