Open-Vocabulary Panoptic Segmentation with MaskCLIP论文阅读笔记
这篇文章的arxiv版看着太折磨了,可以直接看openreview上作者修改后的版本https://openreview.net/forum?id=zWudXc9343以及rebuttal帮助理解。
摘要
本文提出了一个新任务:开放词汇全景分割,同时作者给出了基于ViT CLIP骨干的baseline——MaskCLIP,借助mask queries完成语义分割与实例分割。作者设计了一个RMA module, 为ViT CLIP添加额外的token用于语义分割,从而有效利用预先训练好的CLIP特征,避免了裁剪图像和从外部CLIP图像模型计算特征带来的时间开销。
方法
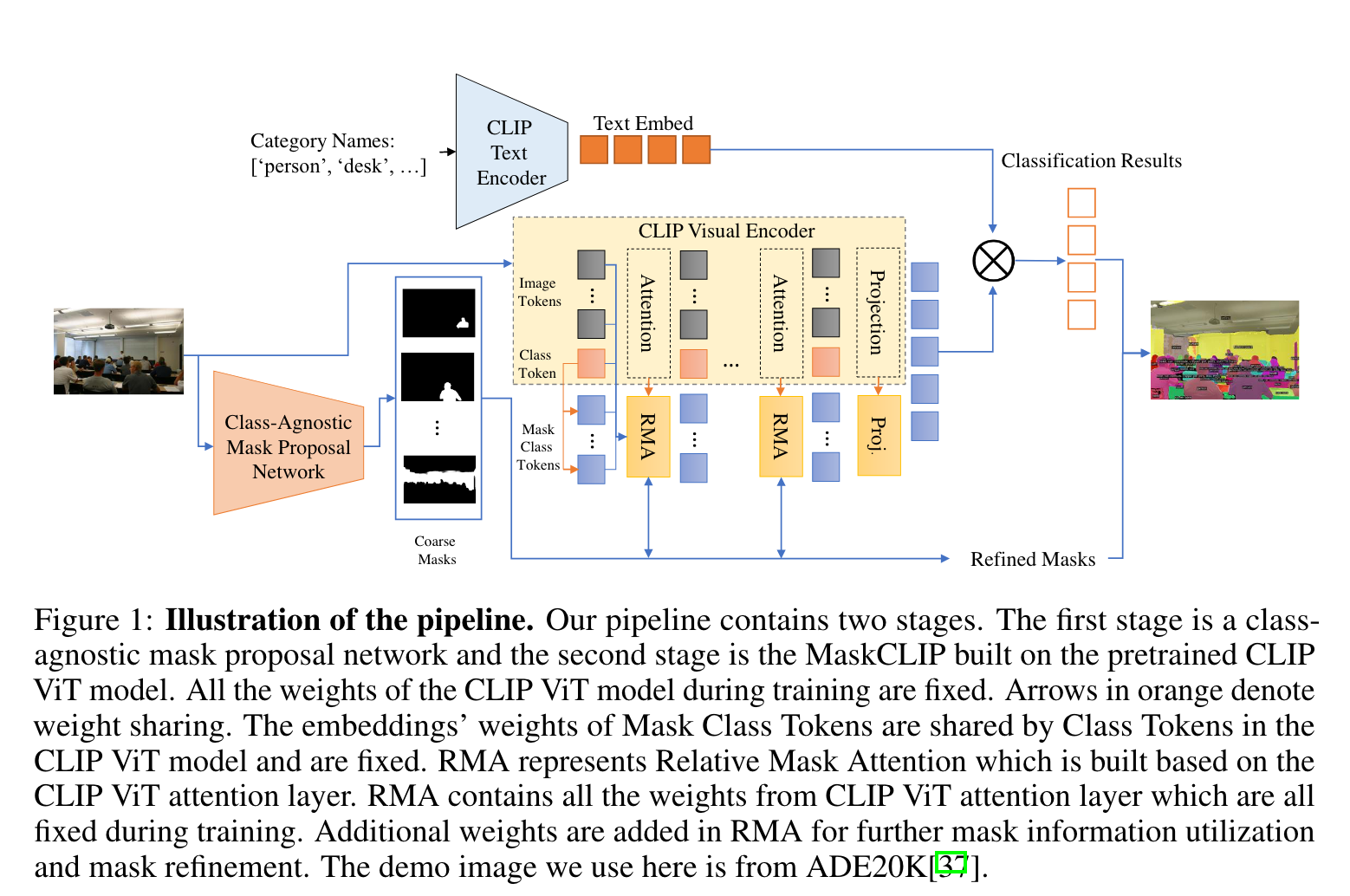
如上图所示,整体流程分为两个阶段。第一阶段通过一个单独的网络生成类别无关的mask proposals,第二阶段通过RMA以及图像特征对生成的mask进行调整,最后借助text embedding对mask进行分类。
Mask Class Tokens
为了通过mask或者bbox获取密集图像表示,一种简单的方法是通过这些mask或bbox对图像进行crop,之后送入image encoder,然而这会带来极大的计算开销,而且会导致模型无法看到图像的上下文信息,而这对于某些物体的分类是异常关键的。同时,针对分割任务,直接对图像mask得到的结果与训练CLIP时使用的数据不符,可能会导致预测出现偏差。
作者为此提出了Mask Class Tokens,在原始ViT CLIP模型的基础上(1 cls token+N img tokens)加入了M个mask class tokens,对其embedding的权重与cls token相同且被冻结,借助其得到图像的密集表示。为此,作者设计了attention mask,表示如下:
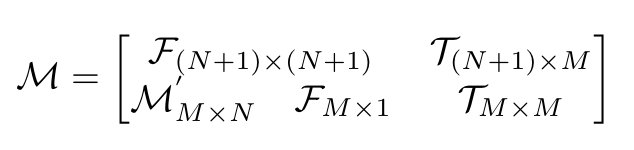
这个矩阵中,表示全为True的子矩阵,表示全为False的子矩阵,
为False当且仅当包含至少一个属于的像素。需要注意的是,True表示这个位置被mask,不起作用。这个矩阵的作用实际上就是使用由q与k得到的注意力分数对v进行加权时,确保原始的cls token以及image tokens不受mask class tokens的干扰,且保证mask class token仅受和其有关的那部分patch的影响。可以借助下图进行理解(左侧是注意力分数,右侧是value)

Relative Mask Attention
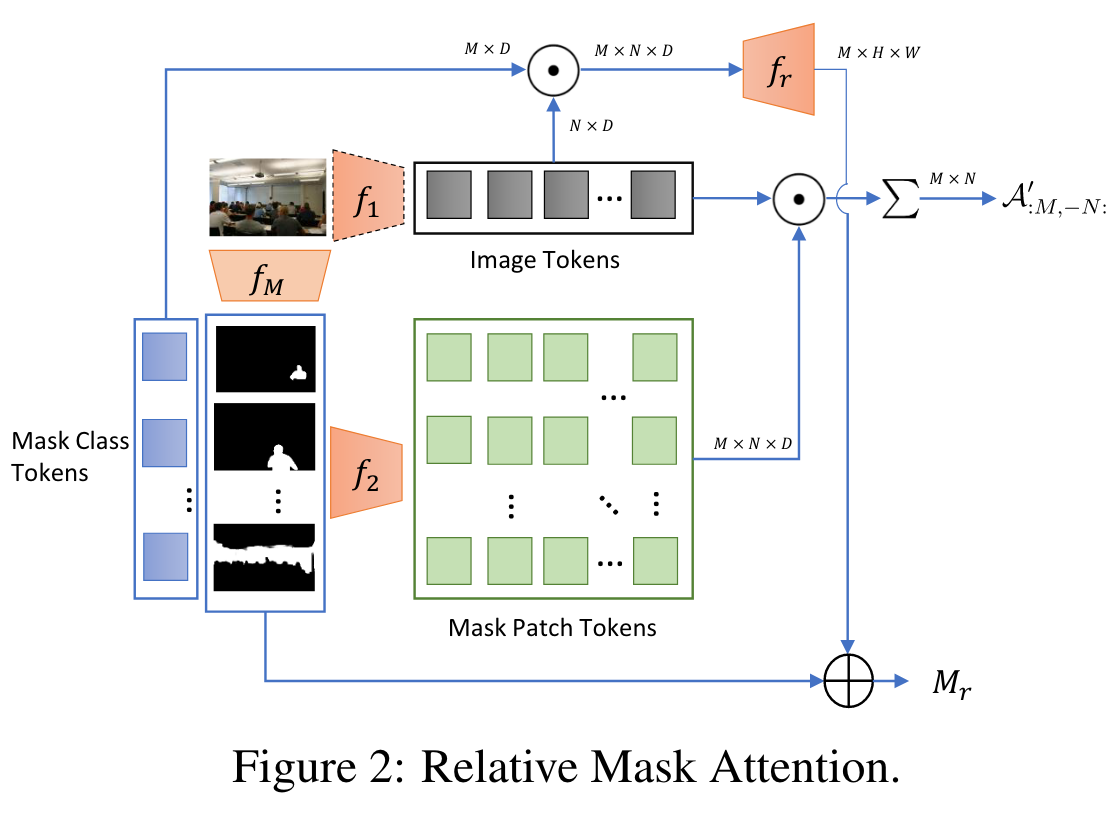
为了对mask进行调整,作者提出了RMA,为了保护image embedding与text embedding始终是对齐的,在仅改变Transformer中注意力矩阵的情况下使模型根据mask的信息学习出更好的value的线性组合。RMA整体结构如上图所示,用于生成mask proposals,和用于对图像和mask进行下采样得到对应的image tokens以及mask patch tokens,是一个两层的卷积网络,将attention matrix映射到mask residual。假设编码为度为D,每个mask的class token ,M个mask的patch token ,每张图像的N个token ,M个mask的class token ,有:
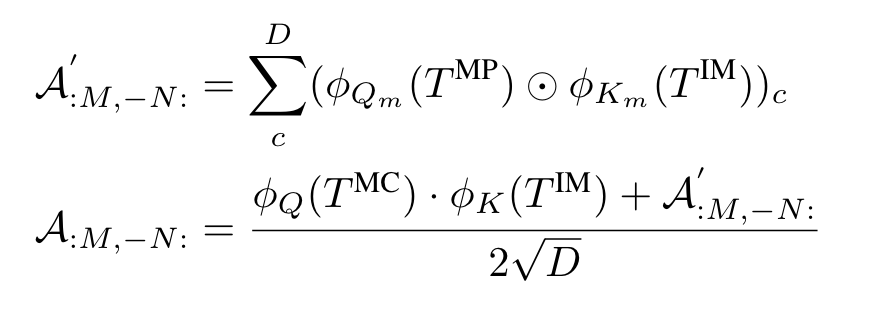
其中为线性变换,表示逐元素乘。将被广播到的维度再进行运算。表示在embedding dimension进行求和。优化mask的过程如下:
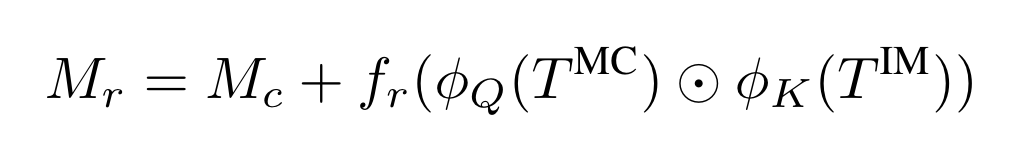
(这里的有什么用?)
实验
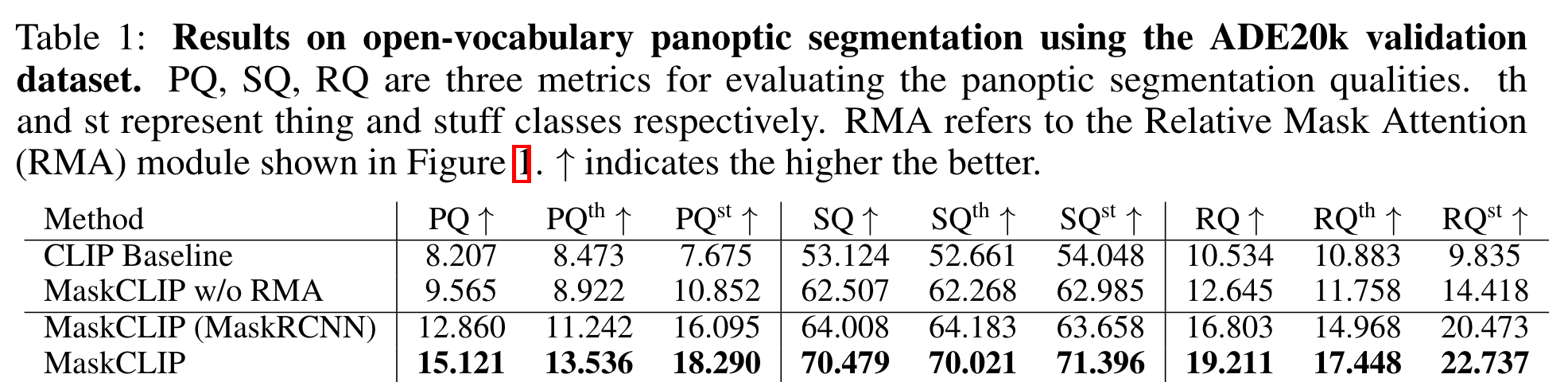
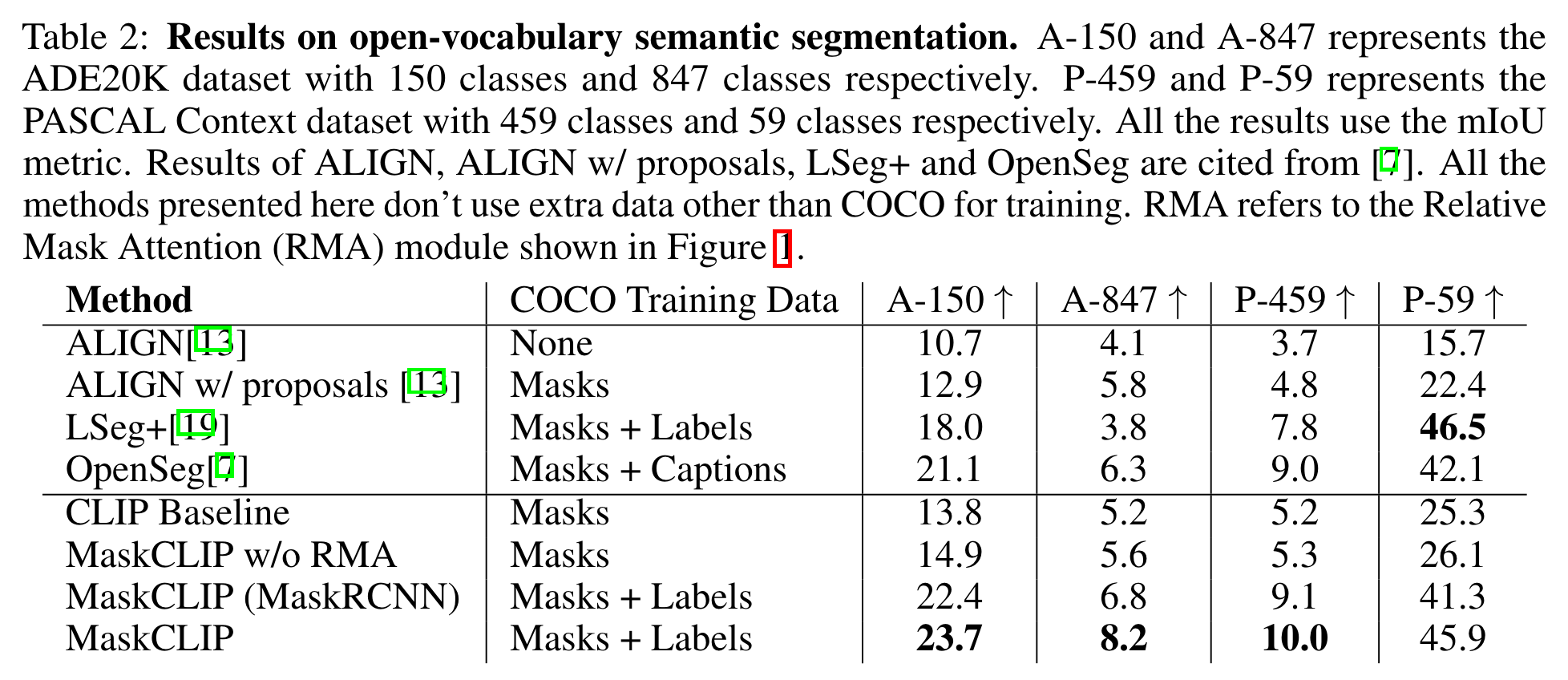



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!