Cross Language Image Matching for Weakly Supervised Semantic Segmentation论文阅读笔记
摘要
目前的类激活图通常只激活区分度较高的目标区域,且会包含与目标相关的背景(文章中举例为如果要分割的是火车,轨道对分类也有一定的贡献,而轨道作为背景不应该被分割)。为解决这一问题,作者提出了一种基于CLIP的跨语言图像匹配框架CLIMS,引入自然语言作为监督信号,从而更准确、紧凑地激活目标区域。
方法
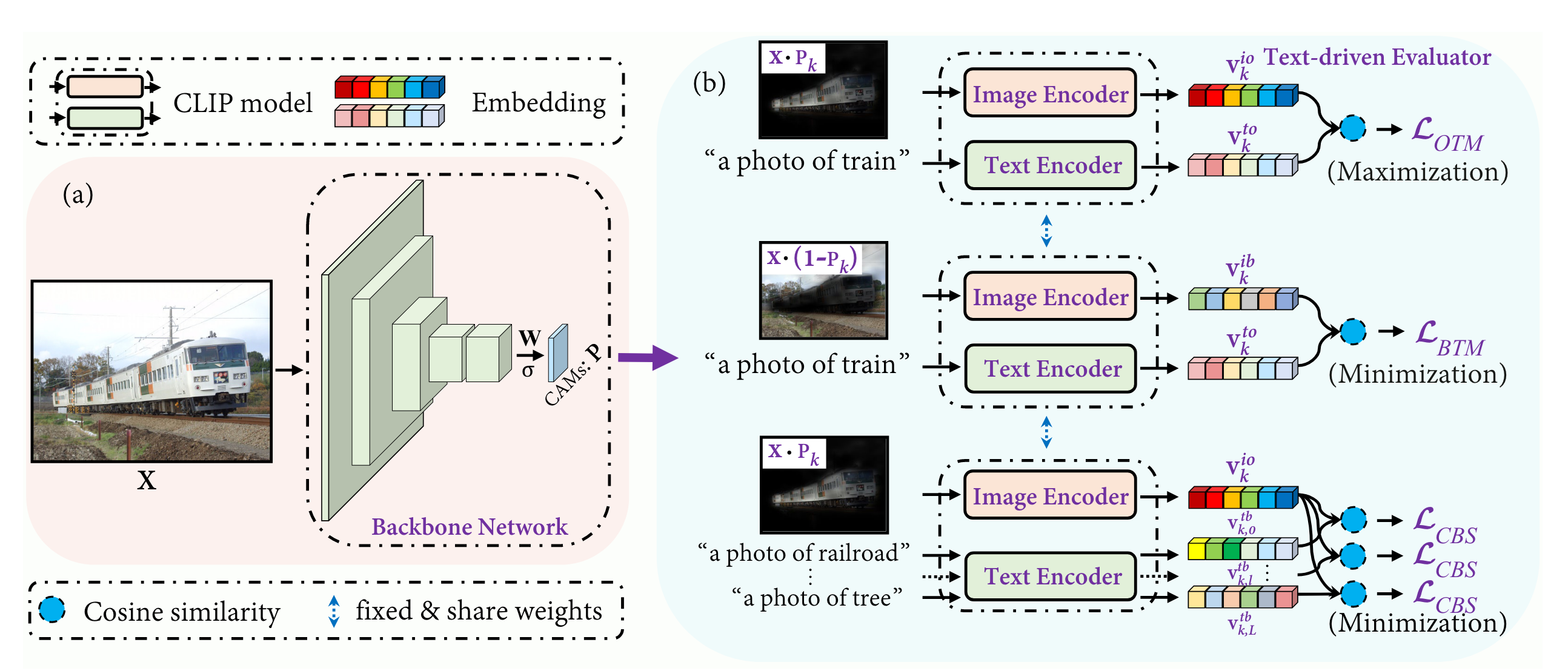
上图中,先通过backbone得到CAM,记为P(注意这里没有GAP):
为了能够识别其他的物体类别,作者提出了基于CLIP的tex-driven evaluator,其包含一个image encoder 以及一个text encoder ,用以及对原图处理得到对于当前类k的前景物体与背景物体,分别送入得到与:
对于文本特征,第k个类的文本prompt表述为:"a photo of {}",如"a photo of train",与之相关的背景文本prompt表述则是预先定义好的,例如对于boat这个类的背景表述为"a photo of a lake",为"a photo of a river",分别送入text encoder得到以及:
其中k,l指的是对于类别k的第l个相关的背景。
得到了这些特征之后,就可以计算损失了。第一个损失是物体区域与文本标签的匹配损失:
如果当前图像的标签中有第k个类的话则,为与的余弦相似度。
第二个损失是背景标签与文本区域的匹配损失:
这个损失的目的是尽量减小与背景的相似度。
上述两个损失只能保证P完全覆盖目标对象,没有考虑到对于与当前类别共同出现的背景类别的错误激活。为此,作者提出了共现背景抑制损失:
如果仅有以上损失,当目标物体与不相关的背景一同出现时,CLIP仍然可以正确识别,因此,作者还设计了一个像素级别的区域正则项,限制激活图的大小从而保证不相关的背景被排除在以外:
总的损失就是这四项损失的和,通过超参数加以调节:
总的来说,就是借助这四项损失去优化分割网络,无需像素级别的gt就能达到很好的性能。推理时直接用训练好的backbone即可。
实验
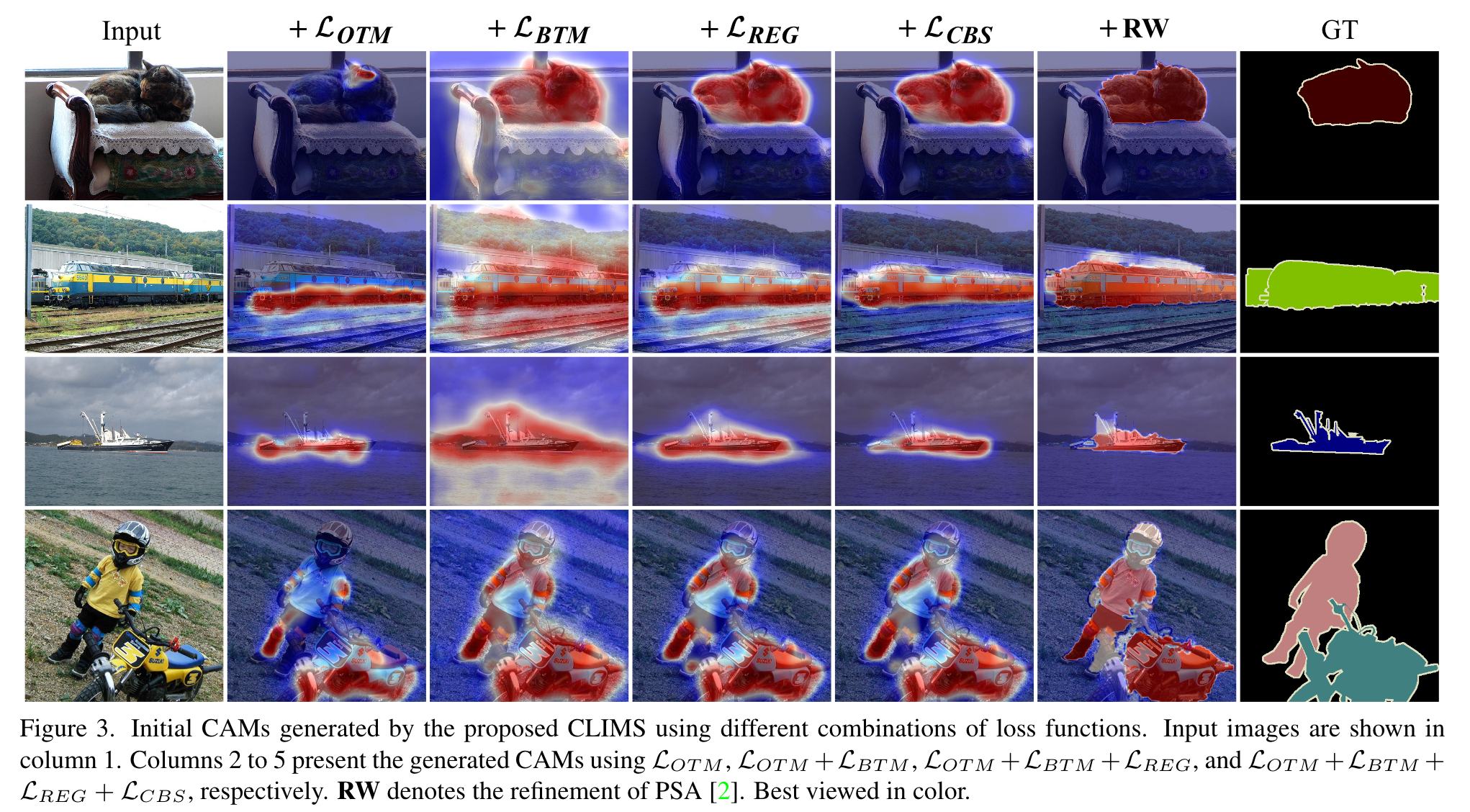
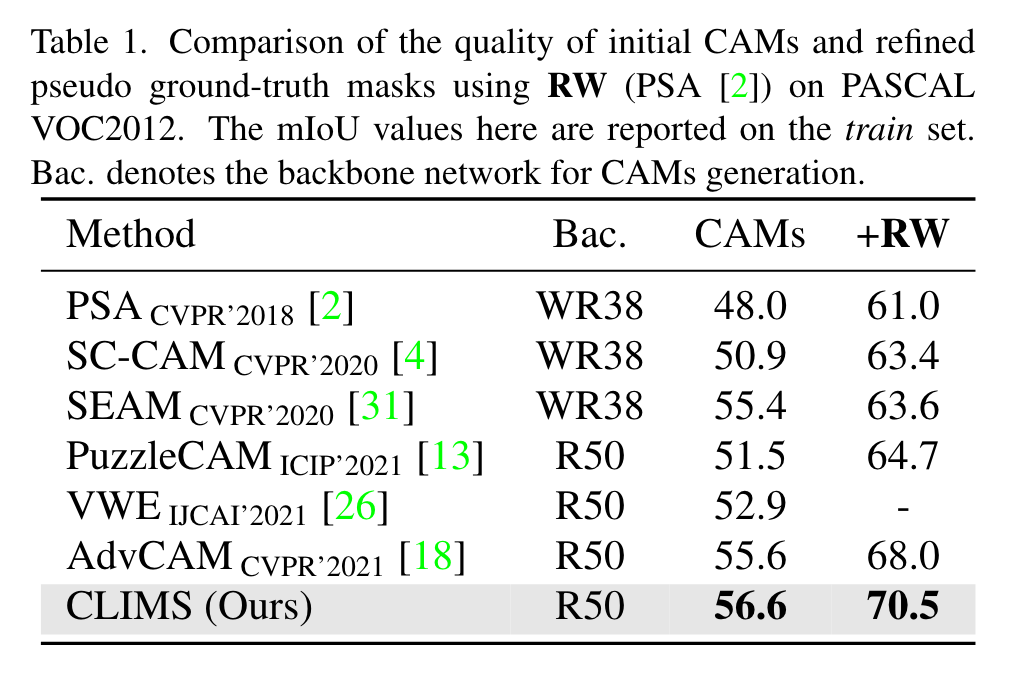




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!