CLIP is Also an Efficient Segmenter: A Text-Driven Approach for Weakly Supervised Semantic Segmentation论文阅读笔记
摘要
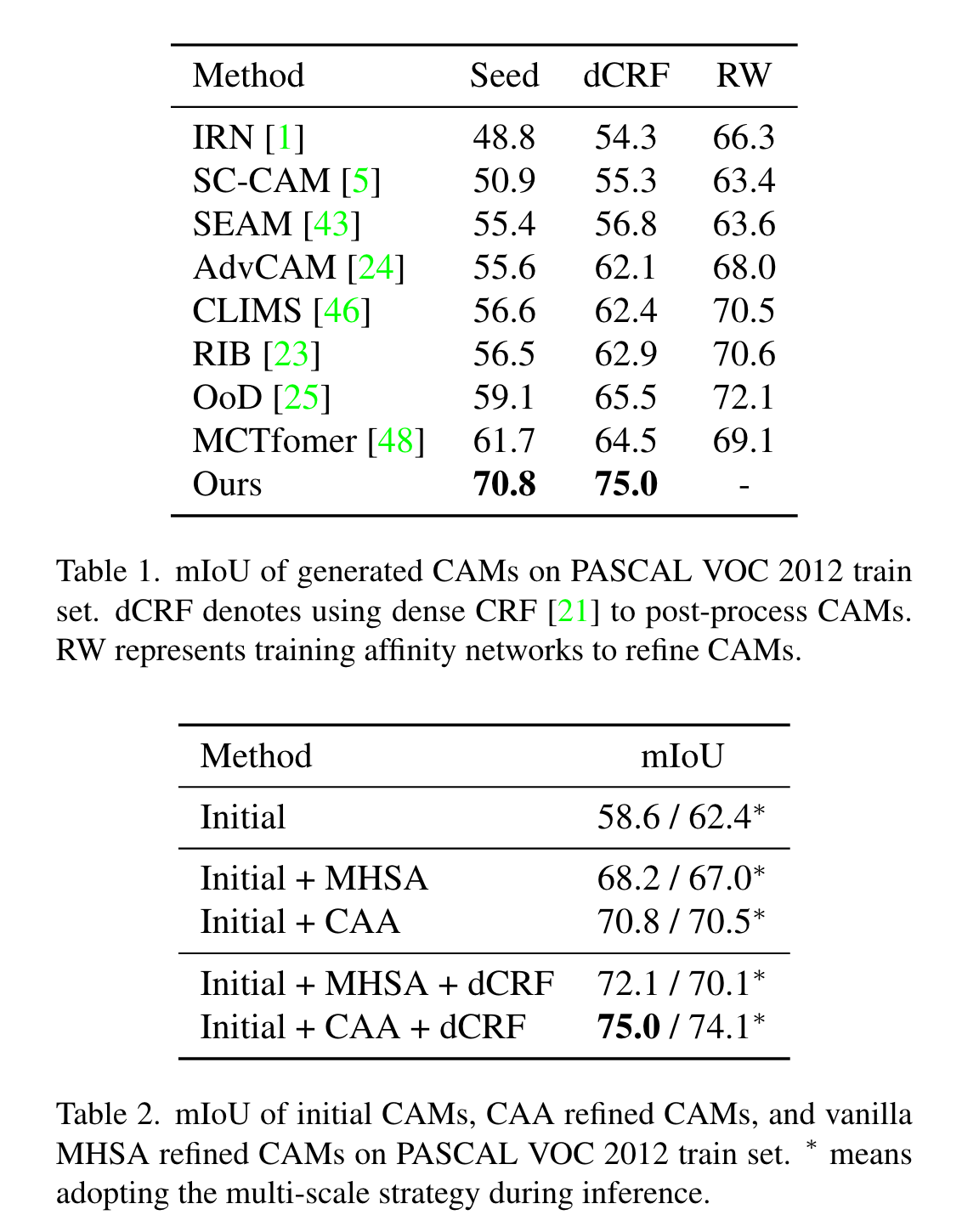
文章提出了一种利用CLIP模型进行弱监督语义分割的新方法,称为CLIP-ES,它能够在不需要额外训练的情况下,仅使用图像级标签就能生成高质量的分割掩码。它通过对CLIP进行特殊设计来改进WSSS的三个阶段:
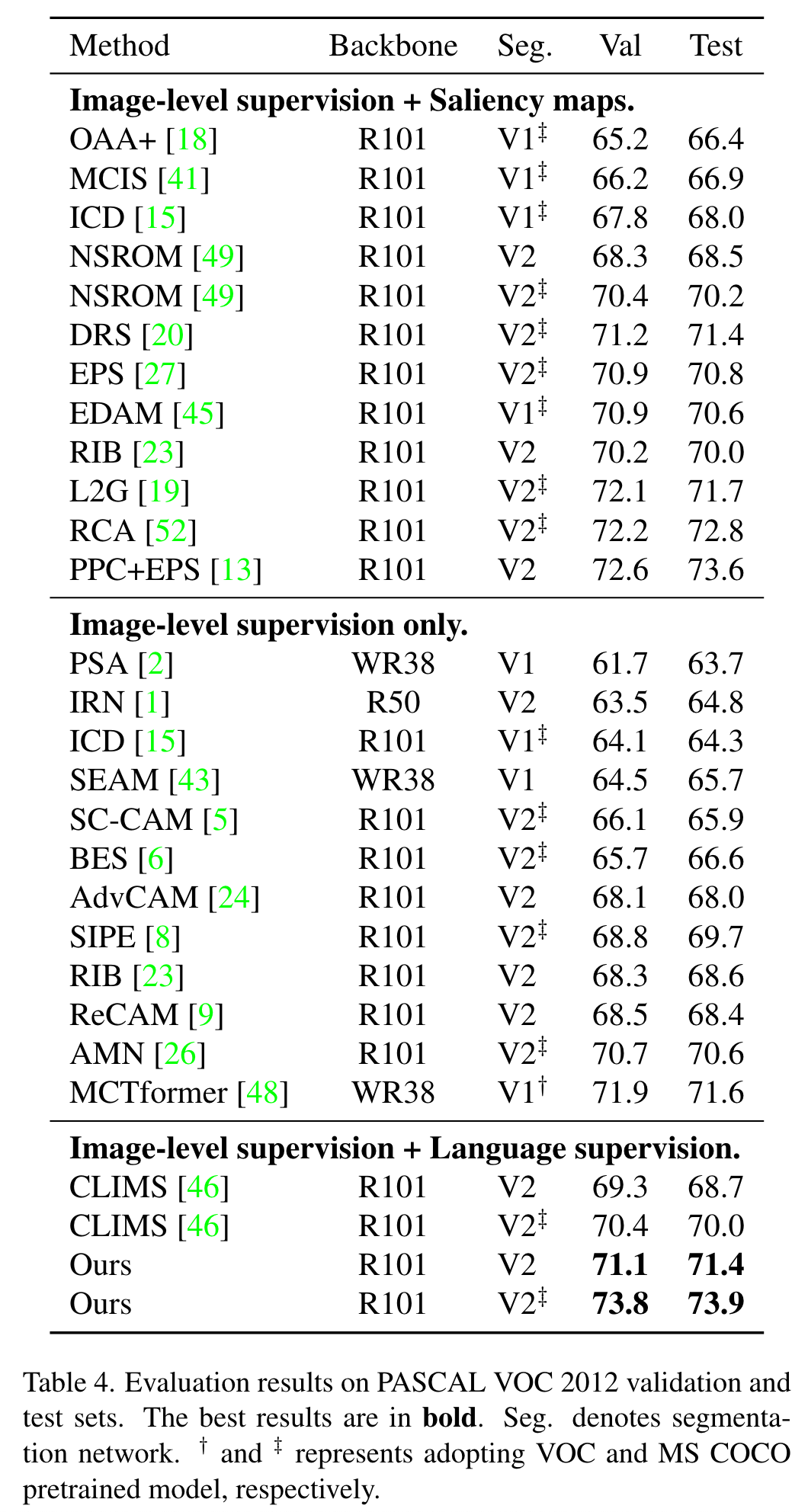
1)将softmax函数引入GradCAM,并利用CLIP的zero-shot能力抑制非目标类别和背景造成的混淆。同时,为了充分利用CLIP,作者在WSSS设置下设计了两种基于文本的策略:基于锐度的提示选择和同义词融合。2)为了简化CAM细化阶段,作者提出了一种基于CLIP-ViTs内部多头自注意力(MHSA)机制的实时类感知注意力(CAA)模块。3)当使用CLIP生成的掩码训练最终分割模型时,作者引入了一种置信度引导损失(CGL),以减轻噪声并关注可信区域。本文的方法在两个公开数据集上达到了sota,并且在生成伪掩码方面比之前的方法快了10倍。
方法
Softmax-GradCAM
这一节作者首先介绍了CAM与GradCAM。可以参考:
https://zhuanlan.zhihu.com/p/269702192
以及https://blog.csdn.net/qq_37541097/article/details/123089851
之后作者尝试将GradCAM应用到CLIP。传统的GradCAM中,最终的分数是softmax层前的logits。但WSSS是多标签的任务,使用的损失函数通常是BCE而非CE,因此缺乏不同类别间的竞争。使用CLIP的话同样会遭遇类别混淆的问题,因为CLIP的训练数据是图像文本对,文本可能会描述很多类别的视觉概念,无法通过softmax进行竞争。本文中作者将softmax引入GradCAM:
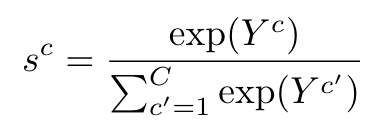
其中是softmax后第c个类别的分数。之后用这个计算梯度,得到每个类别的权重(求导的时候参考一下的表达式):
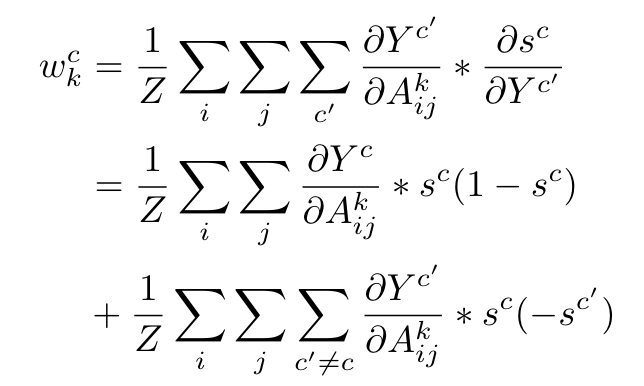
其中k是指第k层的feature map。这个公式表明,目标特征图的权重将被非目标类别抑制。因此,目标类别的相应CAMs可以由其余类别进行修正。然而,竞争仅限于数据集中定义的类别。为了将目标类别的像素与背景类别分离,作者提出了一种与类别相关的背景抑制方法,定义了一个包含M个常见与数据集中定义的类别相关的类别的背景类别集合,从而抑制背景类的像素。由于CLIP具有zero-shot能力,因此只需要修改输入文本而不需要像之前基于训练的方法那样重新训练分类网络来处理背景类别。
Text-driven Strategies
本节作者重新探讨了文本输入在WSSS设置下的作用,提出了sharpness-based prompt selection以及synonyms fusion。
Sharpness-based Prompt Selection
prompt ensembling在分类任务中效果好,但分割则不然。对于多标签图像来说,一个显著的目标类别会抑制其他目标类别的分数。这会影响GradCAM后续的梯度计算,并导致分割性能差。为了验证猜想,作者基于变异系数(Coefficient of Variation,值越大代表数据变化范围大)设计了一个矩阵sharpness,使用不同的prompt衡量多标签图像的目标类别分数分布。假定数据集中有n张图像和k个类别,该矩阵计算如下:
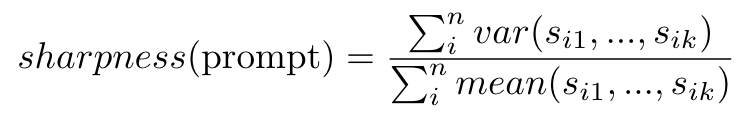
表示第i张图像softmax后第j个类别的分数。当平均值接近0时,变异系数的稳定性不高,因此作者使用方差代替标准差来突出离散程度的影响。
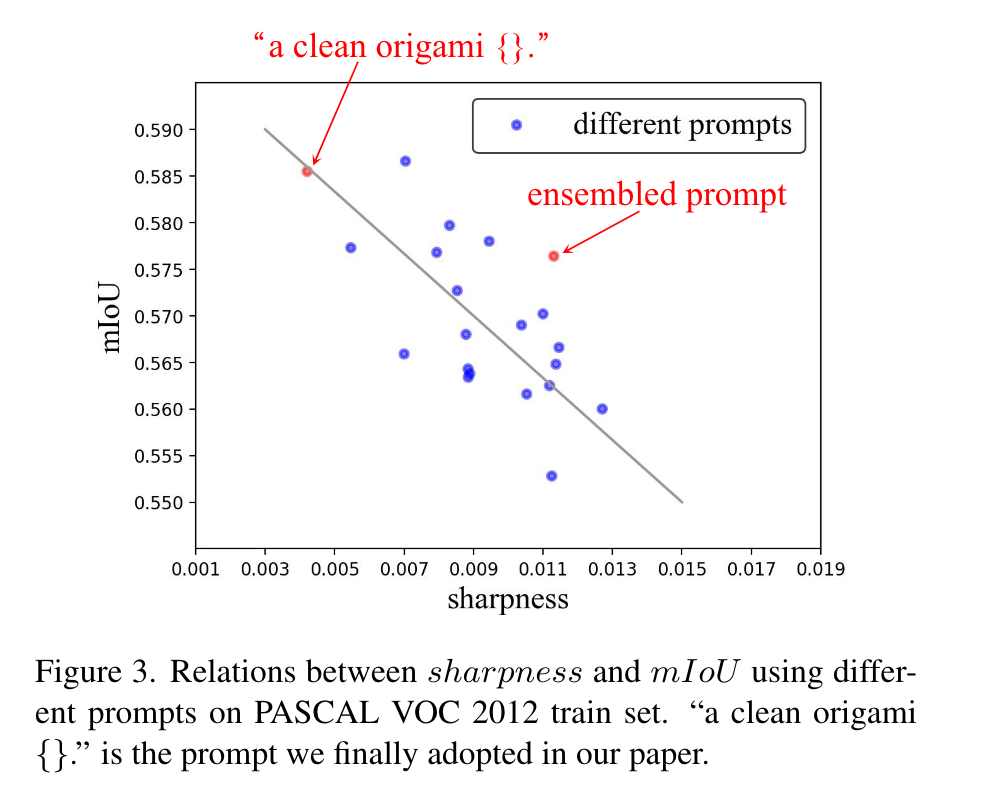
如图,作者比较了从CLIP使用的ImageNet prompt中随机选择的20个提示在Pascal VOC 2012训练集上的锐度和相应的分割结果。结果表明,文章提出的度量与分割性能大致呈负相关。同时作者发现一些抽象的描述,例如“折纸”和“渲染”,以及一些形容词,例如“清洁”,“大”和“奇怪”,对分割性能有积极影响。作者最终选择了锐度最低的“a clean origami {}.”作为提示。
Synonym Fusion
作者使用同义词丰富语义并消除歧义。文章中作者选择在句子级别合并同义词,即将同义词放进一个句子:
“A clean origami of person, people, human”。作者还使用了“person with clothes”替换“person”,从而解决只分割人脸的问题。
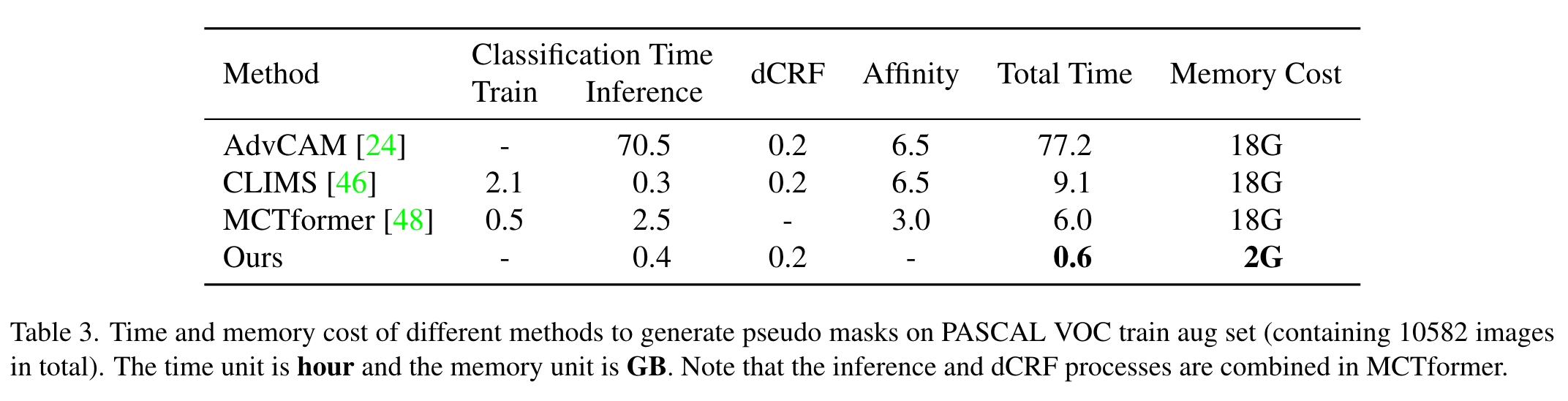
Class-aware Attention-based Affinity (CAA)
使用transformer的注意力作为语义级别的相似度优化初始CAM需要另外添加网络或额外的层,因为原始的MHSA是类别不可知的,而CAM是按类别分的。直接利用MHSA可能会通过在精细化期间将噪点传播到其语义上相似的区域而放大噪声:

为此作者提出了一种基于类别感知的注意力相似度,通过注意力权重生成相似度矩阵。然而相似度矩阵是对称的,注意力矩阵是非对称的(q与k使用不同的层)。作者使用Sinkhorn标准化将注意力权重矩阵W转换为双重随机矩阵D,然后可以得到对称的相似度矩阵A:
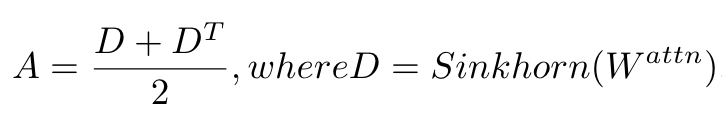
获取基于注意力的相似度后令其与目标类别相关联,通过设置阈值在CAM图上找到连接的区域,得到包含目标类的多个矩形框,用这些框来掩蔽相似度从而优化CAM。
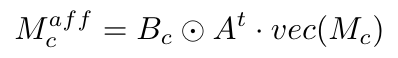
Confidence-guided Loss (CGL)
在CAM中设置阈值来生成伪掩码可能会引入噪声,因此作者提出了一种置信度引导损失(CGL)来充分利用生成的CAM。给定一个包含c个类别的CAM map ,置信度可以用如下公式计算:
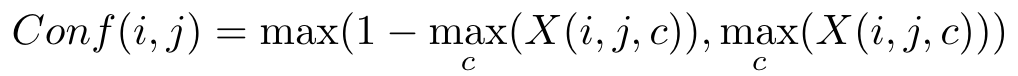
最终的loss:
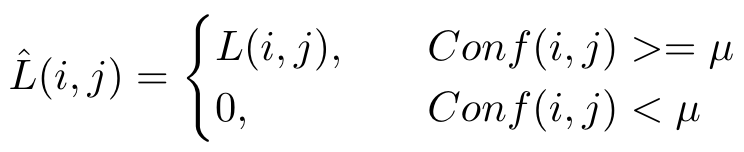
实验



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2022-02-22 CCF-CSP认证 202112-3 登机牌条码(90分)
2021-02-22 洛谷P5194 [USACO05DEC]Scales S (搜索/剪枝)
2021-02-22 2021牛客寒假算法基础集训营5 D. 石子游戏(差分/贪心)
2021-02-22 2021牛客寒假算法基础集训营5 B. 比武招亲(上)(排列组合)
2021-02-22 UVA532 Dungeon Master(三维BFS)
2020-02-22 2019CSP-S T1格雷码