CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks论文阅读笔记
CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks论文阅读笔记
摘要
这是一篇关于利用CLIP模型来提升视觉语言任务性能的论文。CLIP模型是一个可以从大量图片和文字数据中学习通用视觉语言表示的模型,它有很强的零样本和少样本学习能力。这篇论文提出了一种新的方法,叫做CLIP Targeted Distillation (CLIP-TD),它可以将CLIP模型的知识有效地转移给特定的视觉语言任务,比如图像分类、自然语言推理、视觉问答等。这种方法通过在训练过程中使用CLIP模型作为一个辅助教师,来指导目标任务模型学习更好的视觉语言表示。这篇论文在多个视觉语言任务上进行了实验,结果显示了CLIP-TD方法在少样本和全监督条件下都能显著提升目标任务模型的性能,并且超过了其他使用CLIP模型进行微调或者蒸馏的方法。(此段内容来自chatgpt)
方法
Knowledge Distillation
最基础的蒸馏是直接蒸馏CLIP image encoder的cls token以及学生的img token、CLIP text encoder的eos token以及学生的text cls token。方法是直接计算这几个token的L1 measure,然后加到原始任务的loss。
CLIP Targeted Distillation (CLIP-TD)
主要分为三部分:
Token Selective (TS) Distillation with Prior. 最具语义相关性的标记可能会随着实例而变化。因此作者设计了TS从而选择性的对token进行蒸馏。对于给定的一个text sequence (z是序列长度),Token Selection Module生成一组概率分布。由两部分构成:,就是计算每个text token与image的余弦相似度;是计算每个token对于整个文本在语义和句法上的重要性,作者在这里直接使用了一个pre-trained keyword extractor。
Confidence Weighted (CW) Distillation. 为了解决CLIP的先验知识在实例层面对模型的干扰,作者提出了置信权重蒸馏,根据计算得到的比率r来调整前面提到的损失函数中的权重w:
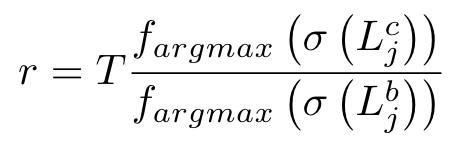
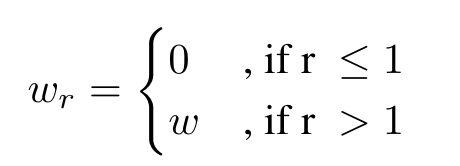
**Adaptive Finetuning (AF) with Contrastive Knowledge. **在最后一个阶段前,作者通过对base model进行微调,(是指的预训练任务)。
剩下的懒得看了,感觉论文整体讲的不清不楚>V<



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2021-02-17 Educational Codeforces Round 104 (Rated for Div. 2) A~D
2020-02-17 HDU1024 Max Sum Plus Plus (优化线性dp)
2020-02-17 HDU1495 非常可乐(BFS/数论)
2020-02-17 POJ3268 Silver Cow Party (建反图跑两遍Dij)