Decoupling Zero-Shot Semantic Segmentation论文阅读笔记
摘要
现有的方法将零样本语义分割(Zero-shot semantic segmentation,ZS3)视为逐像素的zs分类,并且使用仅用文本预训练的模型来完成已知类到未知类的知识迁移,而文本图像预训练模型对于视觉任务有更大的潜力。同时,人类通常进行的是区域级的语义标注,因此,作者提出了一种新的范式,将ZS3解耦为两个子任务:将像素分为分割区域,对区域进行zs分类。第一个任务不包含类别信息,可以用于聚合未知类别的像素;后一个阶段可以很自然的利用大规模的文本图像预训练模型实现ZS3。为此,作者提出了ZegFormer,在VOC和COCO Stuff上取得了突出的表现。
方法
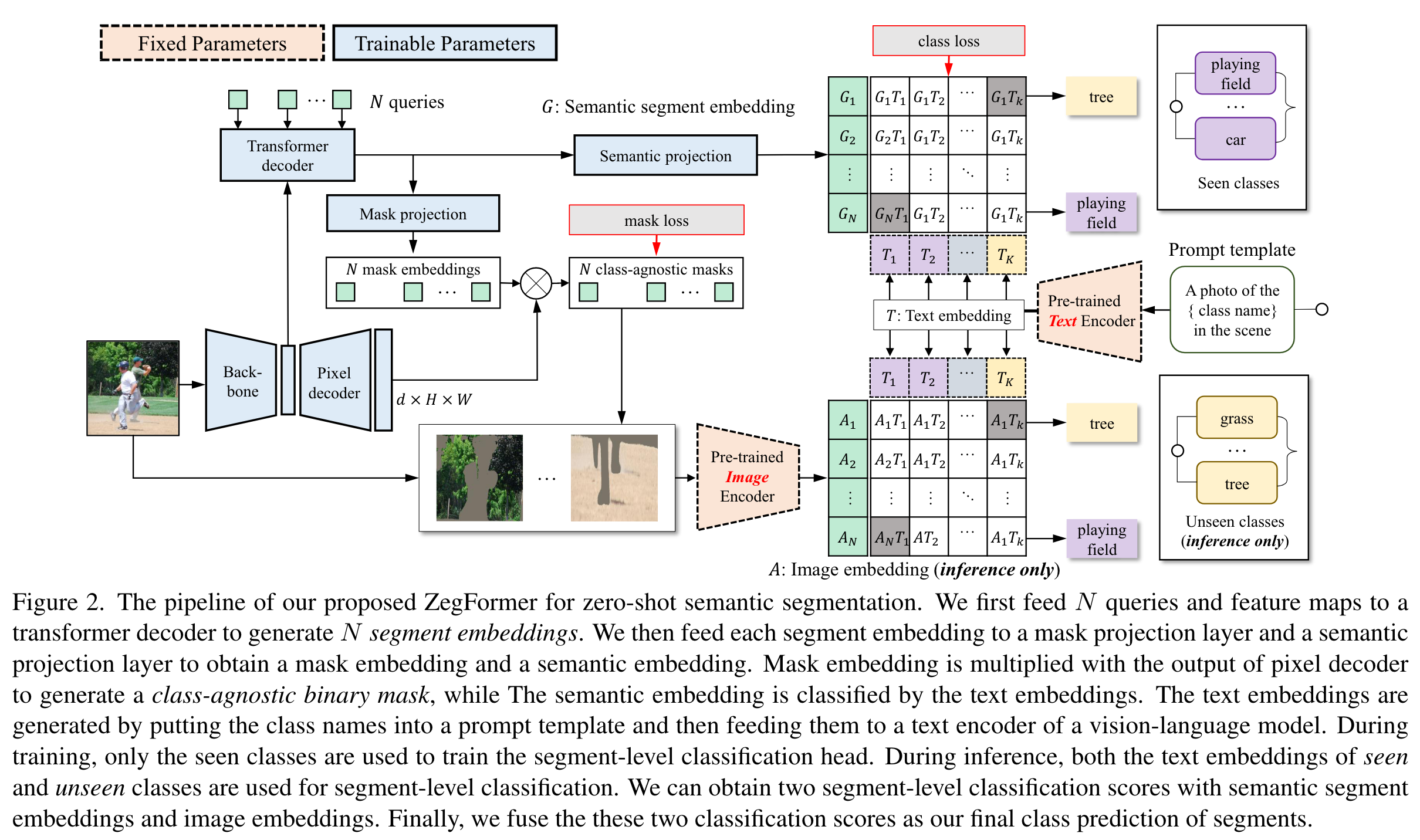
如果熟悉MaskFormer的话模型的pipeline就很清晰了。在seen class训练时,通过N个query与backbone提取到的feature生成N个segment embedding,经过投影后与text embedding计算相似度从而计算class loss;同时pixel decoder的输出与N个mask embedding计算得到N个类不可知的mask,再计算mask loss。推理时,将mask作用于原图,预处理后送入clip的image-encoder,得到的image- embedding与text- embedding计算相似度,得到最终的分类结果。
概率分布计算:
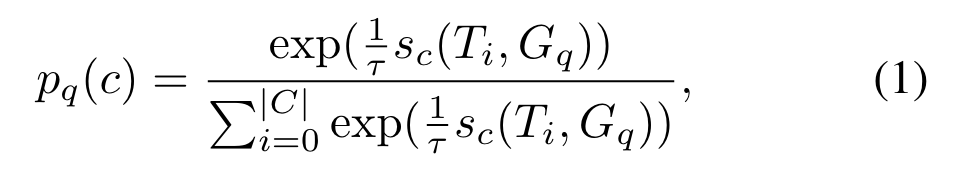
在推理时,为了避免结果偏向seen class,需要在求类别的时候降低seen class的概率:
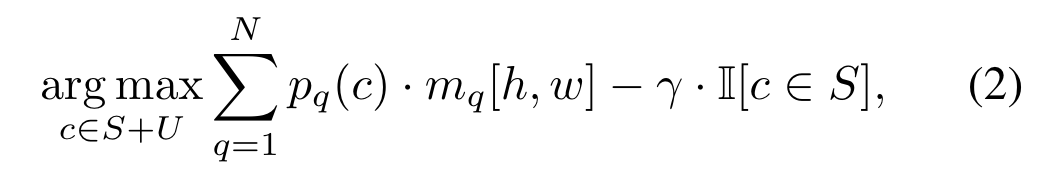
对于每个query,将ZegFormer-seg和ZegFormer-img的结果进行融合(代码mask_former_model.py的373行):
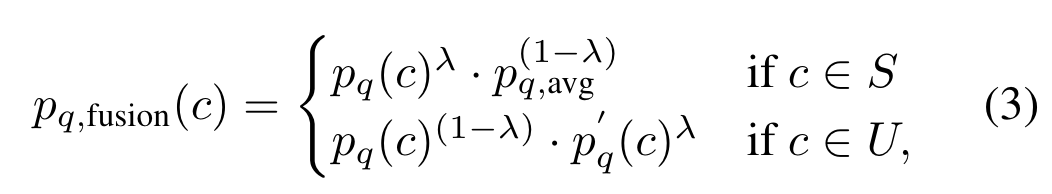
实验
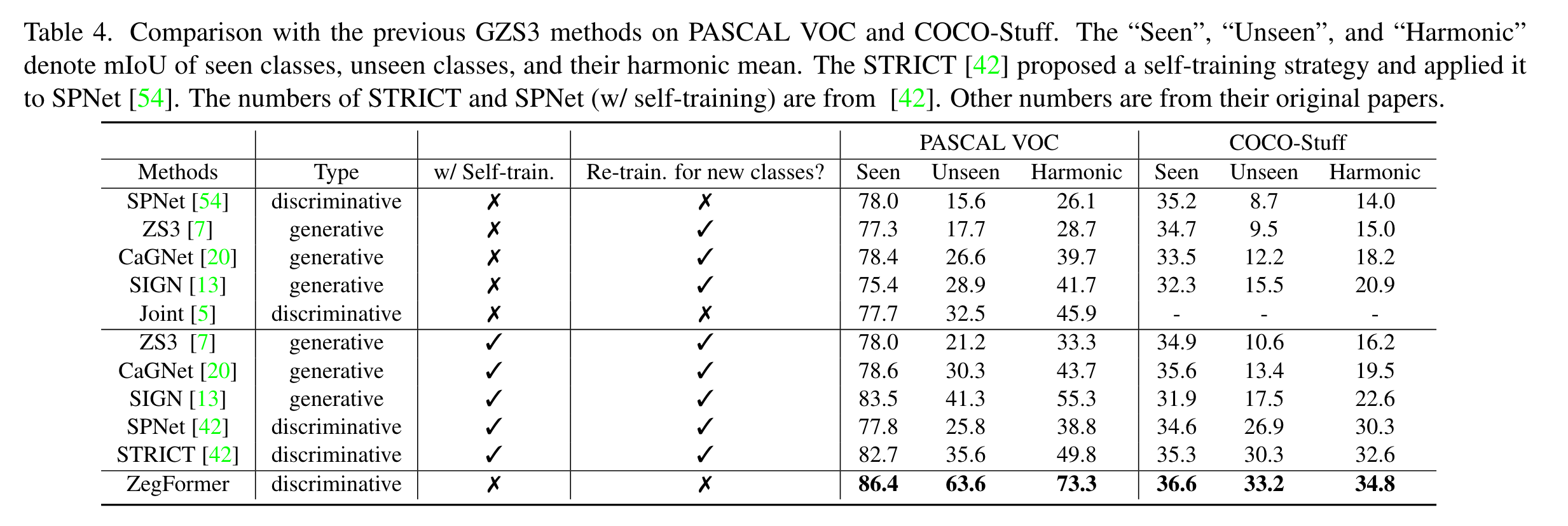
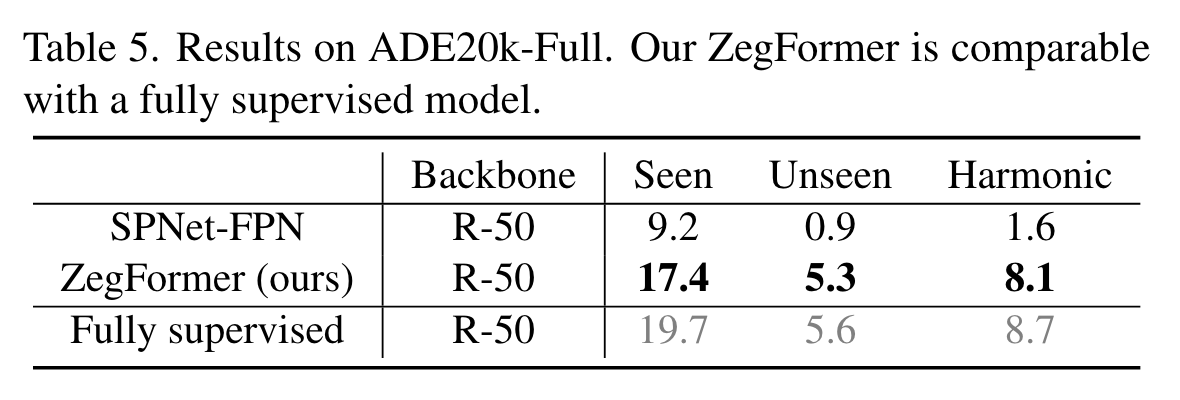
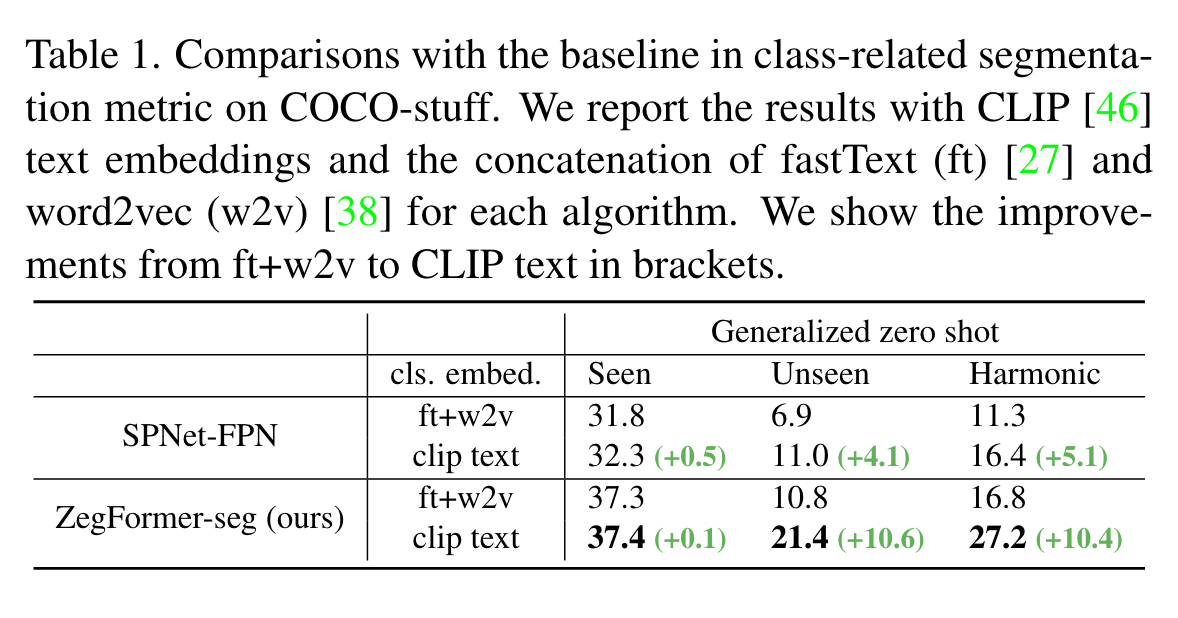
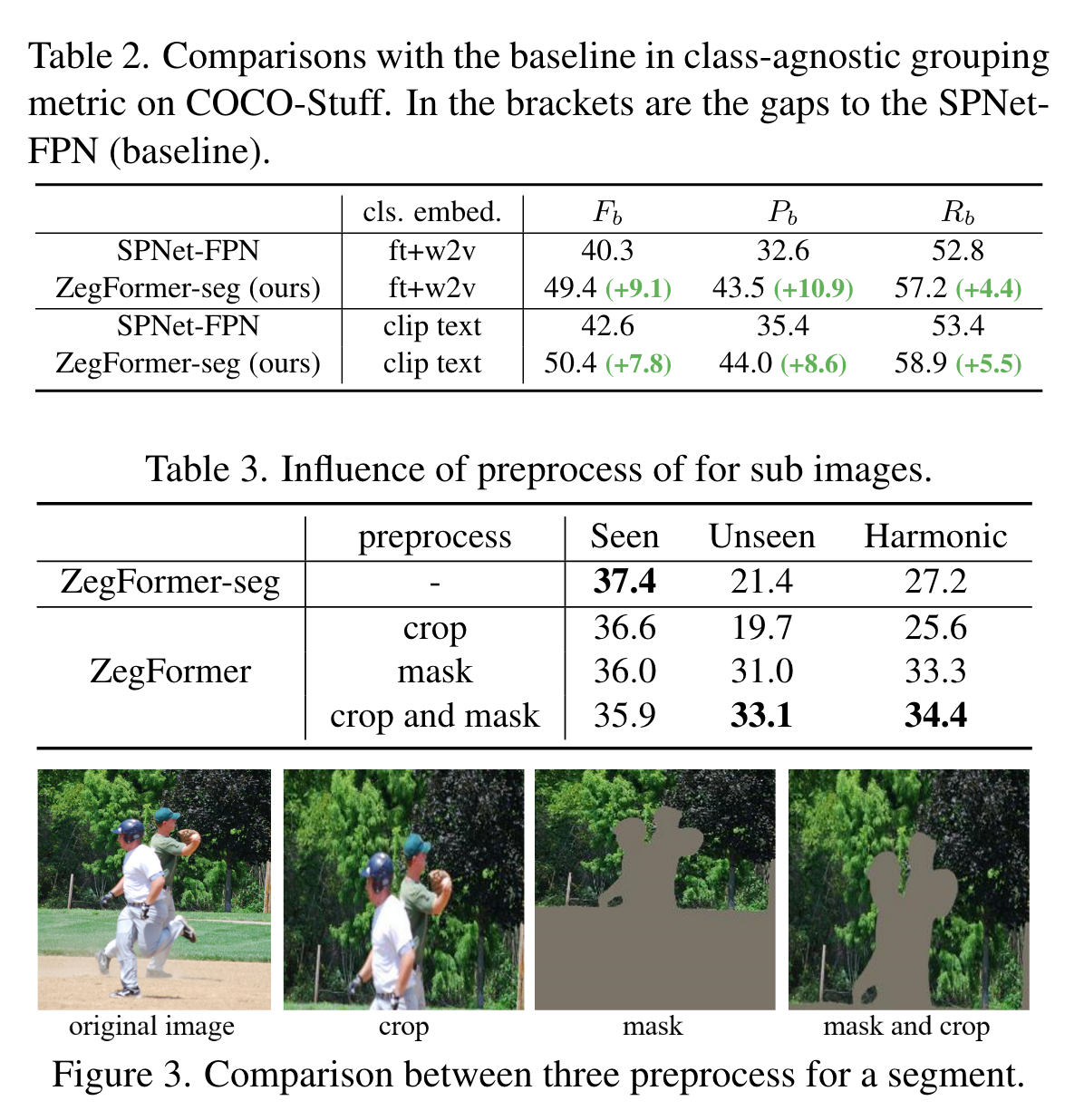
预处理这一部分还是比较有趣的,具体细节可以看一下代码,看看是如何进行crop的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号