CoMFormer: Continual Learning in Semantic and Panoptic Segmentation论文阅读笔记
摘要
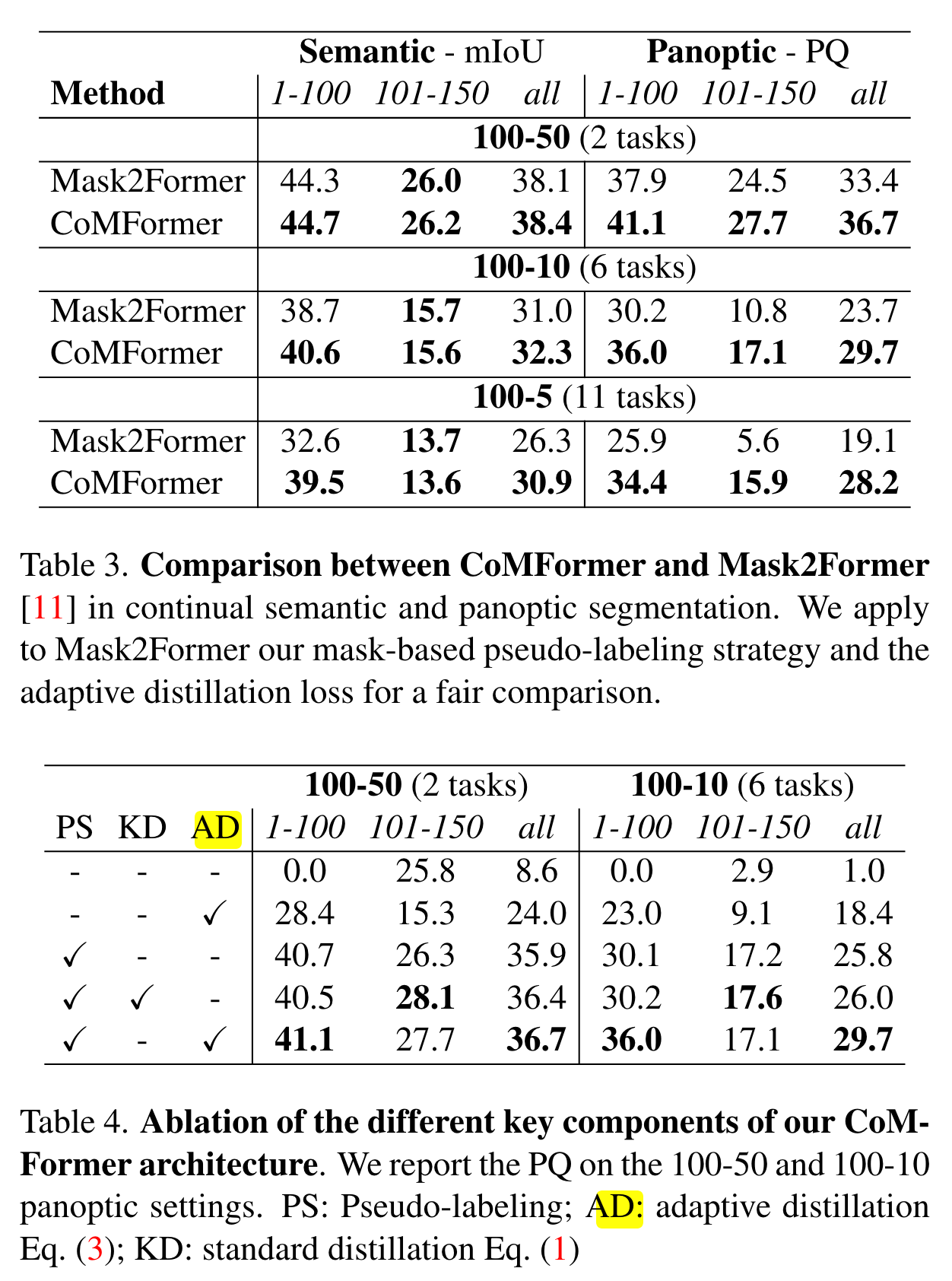
文章的贡献是借助MaskFormer设计了CoMFormer,从而完成对全景分割的连续学习,提出了基于mask的伪标签以对抗遗忘。
方法
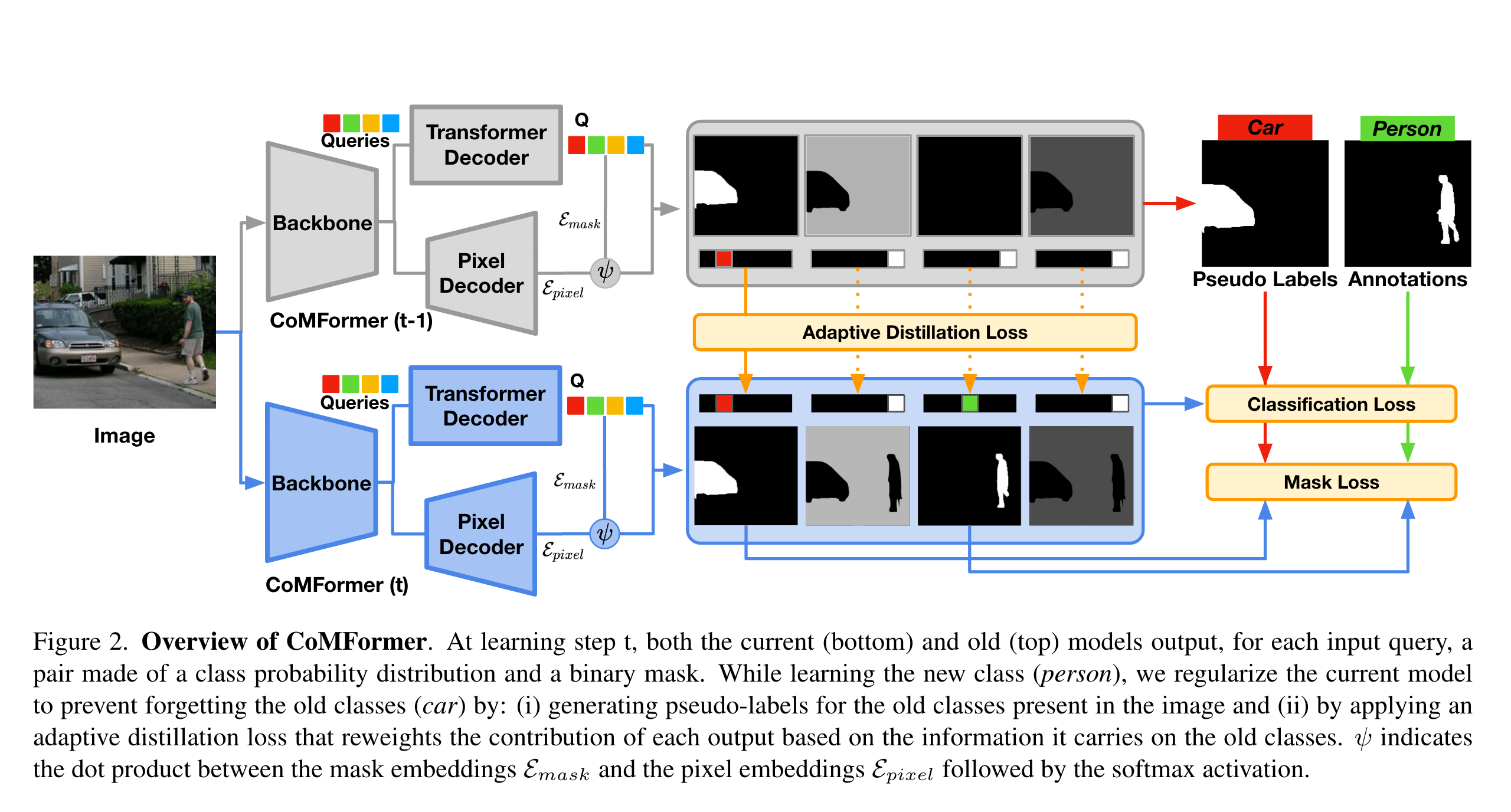
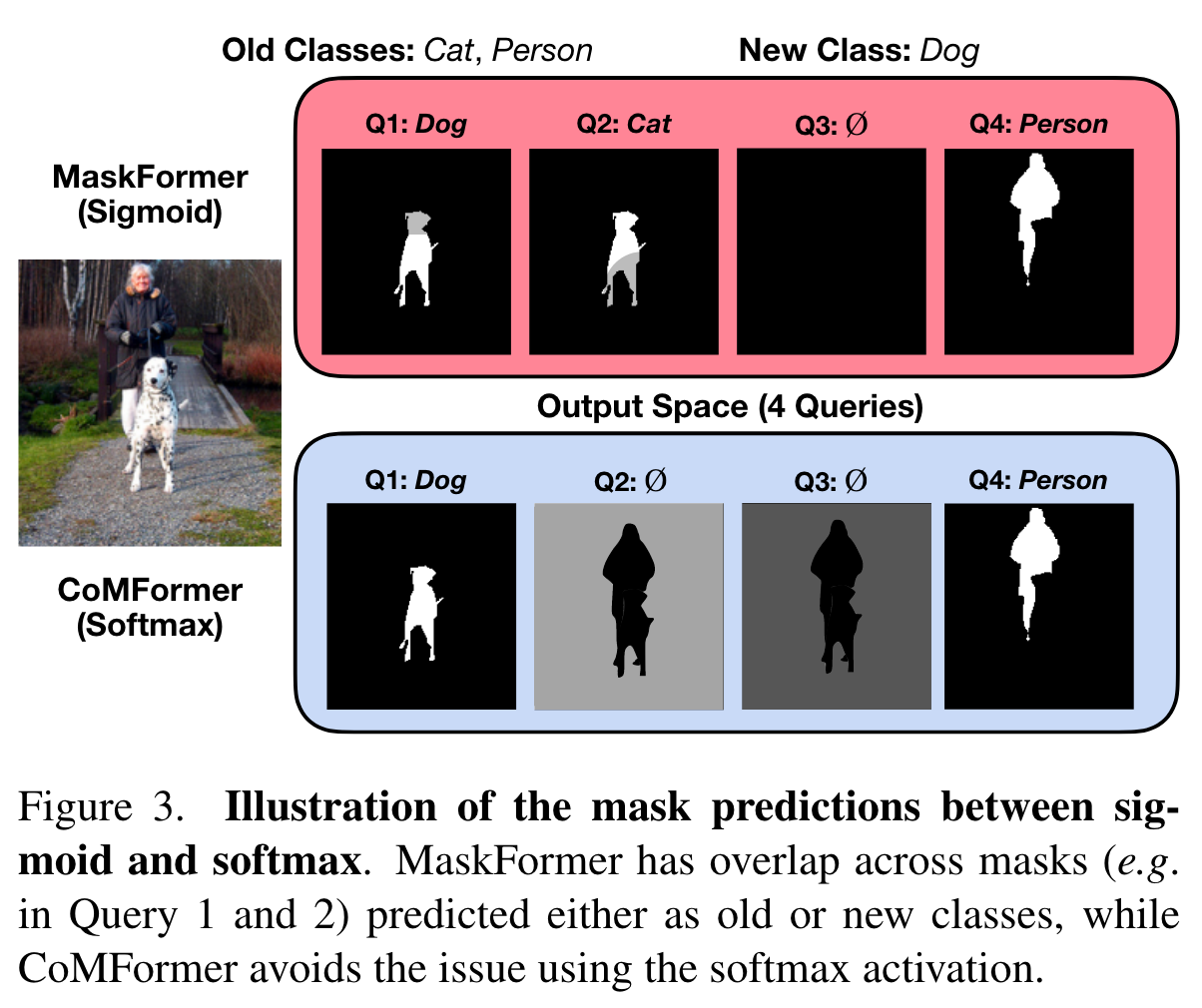
基于MaskFormer,作者将分割视为对mask的分类。输出的形式等都与MaskFormer相同,模型结构也与MaskFormer基本一致。对于每一个step的模型,由backbone、transformer decoder以及pixel decoder构成。作者特别指出,在得到mask预测结果时使用 softmax比sigmoid效果更好,使用sigmoid可能会导致单个像素被分到不同的区域,如下图所示:
为了实现连续学习,作者还加了许多操作:
Adaptive Distillation Loss
这里针对的是输出类别概率进行蒸馏:
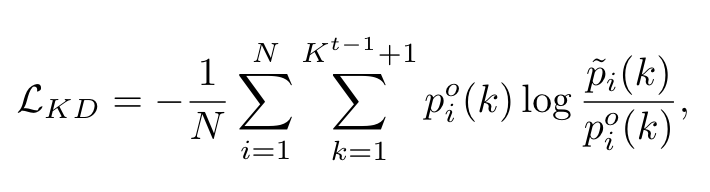
对于每个segment的概率,用KL散度衡量新模型和旧模型给出的概率分布的差异。指的是要额外加上no object这个类别的概率。特别地,将当前step学习的类以及no object类的概率加起来作为新模型预测的no object类别的概率(unbiased probability distribution):
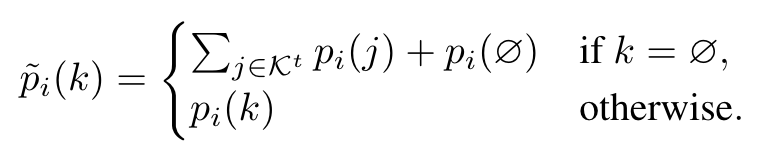
然而,作者指出较大的no object概率会导致降低其它类别的重要性。因此,作者提出了adaptive distillation loss:
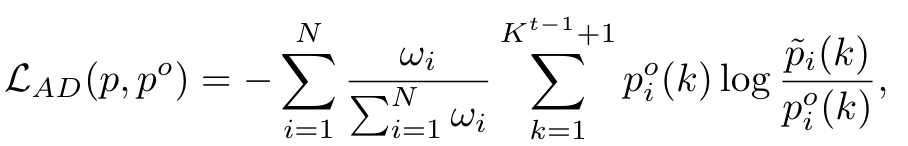
其中。
Mask-based Pseudo-labeling Strategy
一种简单的伪标签策略是,对于旧模型的N个输出,将预测类别不是no object的作为伪标签。然而这些segment很有可能与gt重叠,或者mask包含噪声且置信度低。为此,作者提出了mask-based pseudo-labeling,同时考虑mask以及class的概率以避免噪声。对于第i个输出,其置信度为,其中,是旧模型预测得到的mask,pseudo-class为。生成伪标签时需要注意,pseudo-mask与gt segment不能重叠;包含进pseudo-mask的像素置信度在所有输出中应该最大。令(即mask中概率大于0.5的位置为1,其余为0,类似pytorch的张量操作),gt segment的并为(这里不是特别理解为什么是而不是),则:
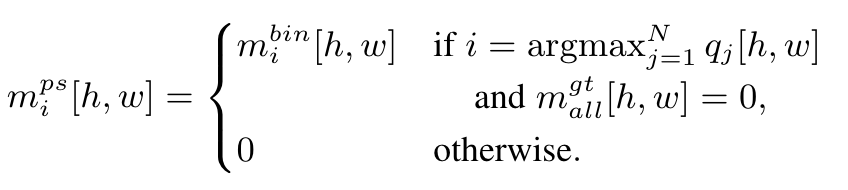
事实上,可能存在一个pseudo-mask包含许多0,因此最终的伪标签segment集合只包含相对于至少有一半像素且至少有一个活动像素的mask(这里也没太理解什么是相对于 ..),最终的标签数为。
训练损失
通过匈牙利算法找到一组匹配,之后计算两个loss:以及。计算的是自适应蒸馏损失,如下:
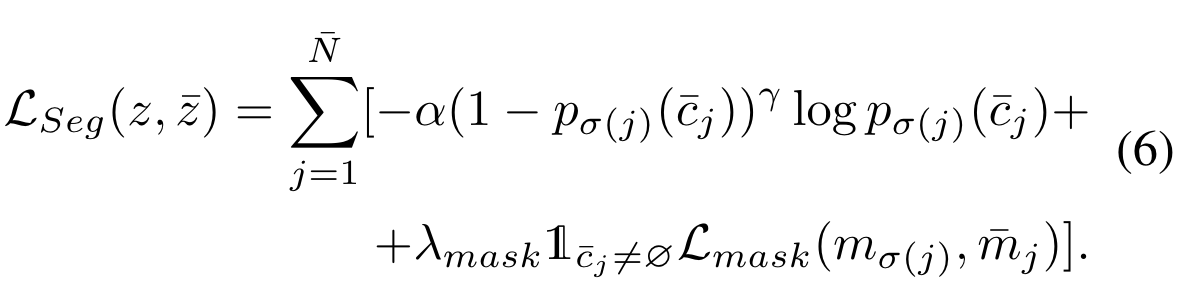
前半部分是focal loss,是dice与cross-entropy的和。
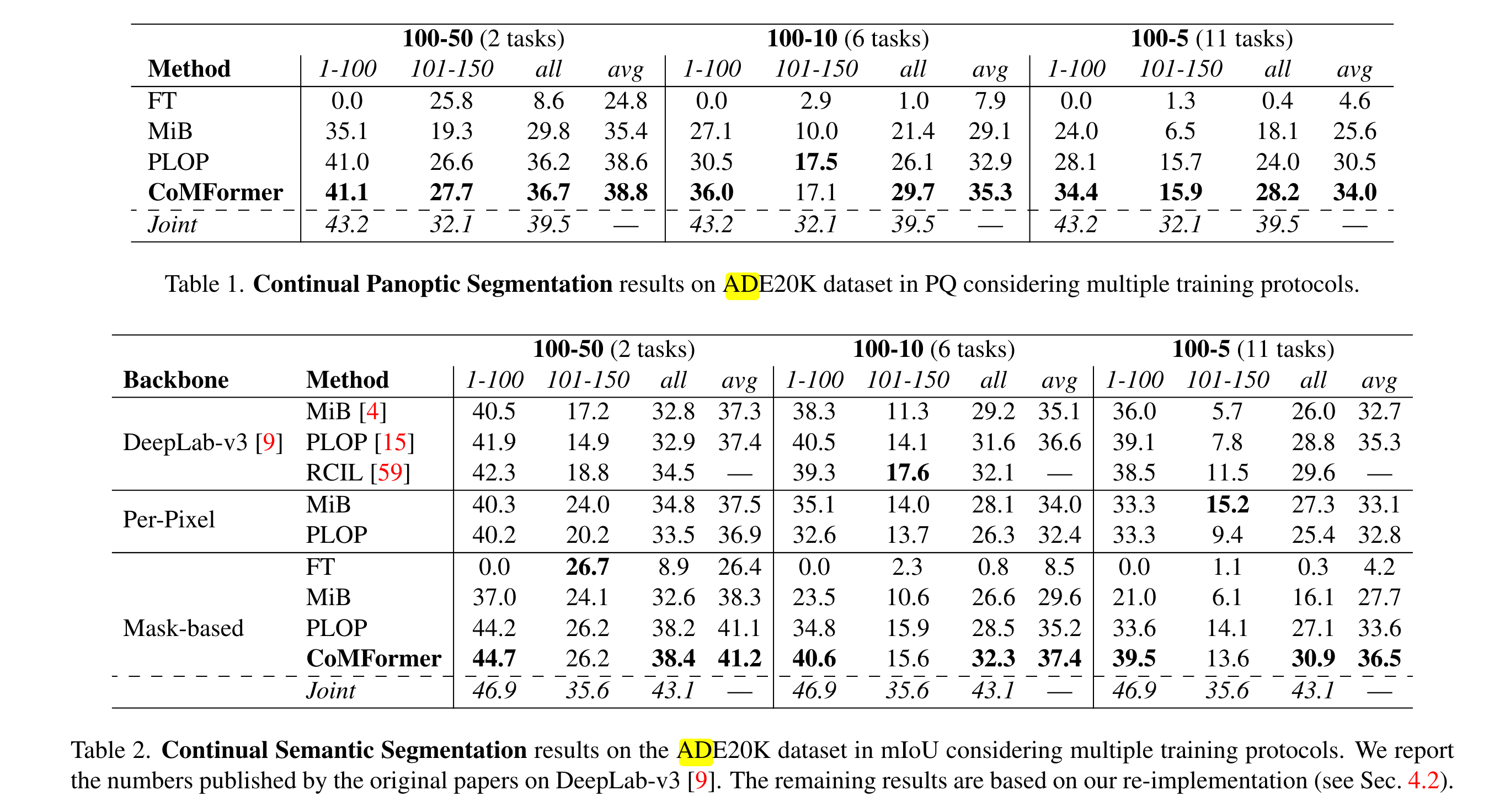
实验



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2022-02-06 A ConvNet for the 2020论文阅读笔记
2020-02-06 洛谷P1140 相似基因(线性DP)
2020-02-06 洛谷P1280 尼克的任务
2020-02-06 Codeforces #617 (Div. 3) D. Fight with Monsters(贪心,排序)
2020-02-06 Codeforces #617 (Div. 3) C. Yet Another Walking Robot
2020-02-06 Codeforces #617 (Div. 3)B. Food Buying
2020-02-06 Codeforces Round #617 (Div. 3)A. Array with Odd Sum(水题)