Per-Pixel Classification is Not All You Need for Semantic Segmentation论文阅读笔记
作者的解读:https://www.zhihu.com/search?type=content&q=MaskFormer
摘要
现有的语义分割方法将分割视为逐像素的分类,本文提出了MaskFormer,把分割转化为预测一系列的mask以及为这些mask预测一个global类别,这样可以很方便地将语义分割与实例分割、全景分割等任务统一起来。实验证明MaskFormer在语义分割与全景分割任务上达到了SOTA。
方法
作者首先介绍了Per-pixel classification和Mask classification。Per-pixel就是目前大部分的语义分割方式,即对每个像素进行分类。Mask classification则是将图像分为N个segment,每个segment对应一个概率分布\(p_i\in \Delta^{K+1}\)(包含一个类别“no object”),ground truth同样包含\(N^{gt}\)个segment,每个segment对应一个确定的类别标签。如果N与类别数K相等,则可以进行fixed matching,当然也可以通过二分图匹配等方式为预测的segment分配标签。训练的损失函数由交叉熵损失和二值掩码损失组成:
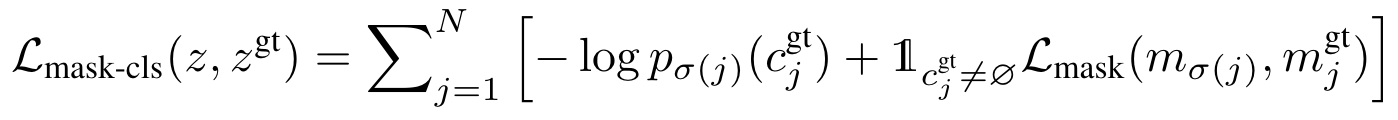
MaskFormer
Pixel-level module
该模块接收输入图像,将其下采样得到大小为\(C_F\times \frac{H}{S}\times \frac{W}{S}\)的特征图(S取32)。之后pixel decoder再将低分辨率的特征图上采样到\(C_{\epsilon}\times H\times W\)得到per-pixel embedding(\(C_{\epsilon}\)为编码空间大小)。
Transformer module
该模块由若干transformer decoder block组成,借助特征图与N个可学习的query(positional embedding)得到N个大小为\(C_Q\times N\)的per-segment embedding(\(C_{Q}\)为编码空间大小)。
Segmentation module
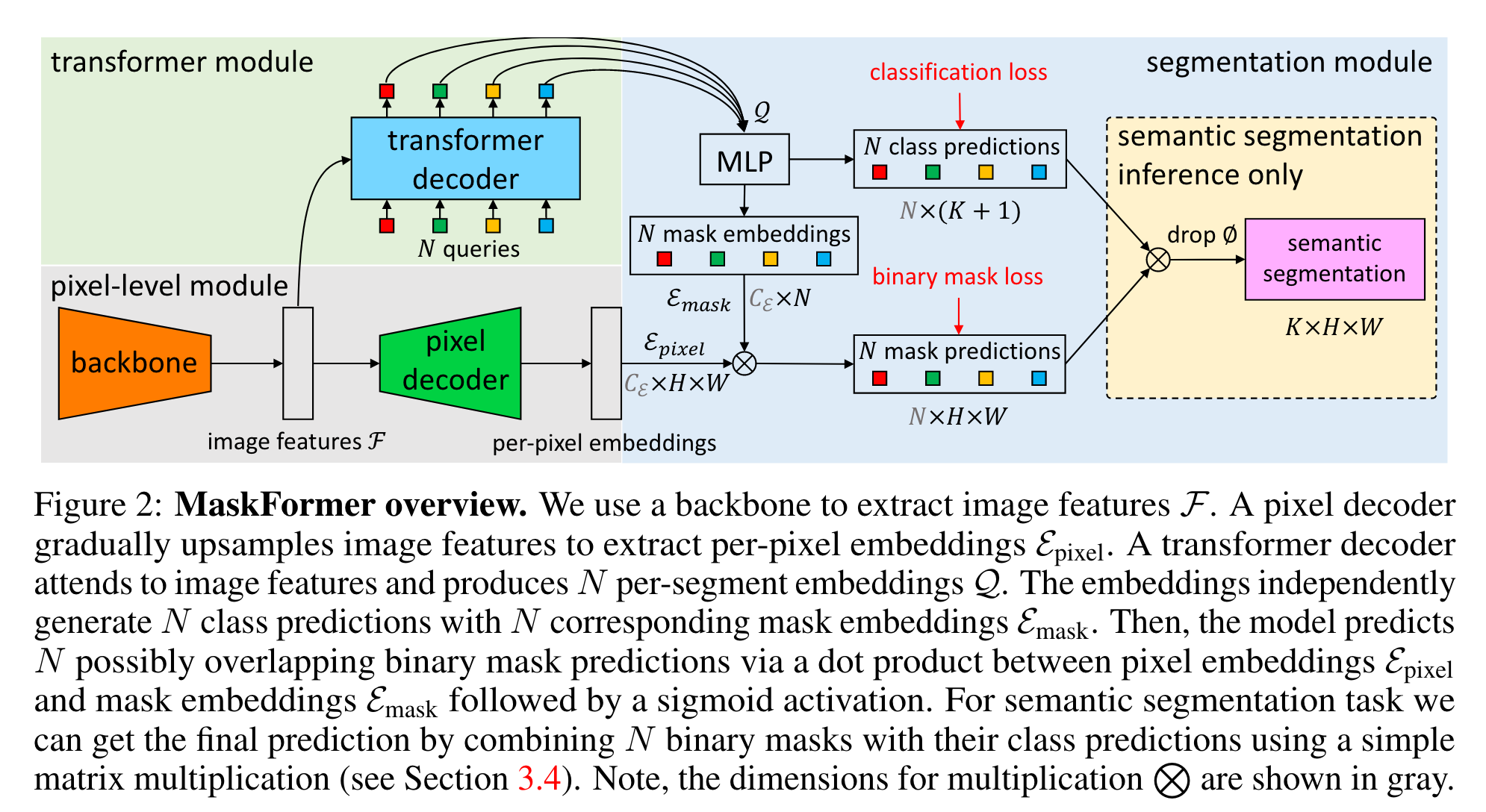
该模块通过线性分类层以及softmax将送入的per-segment embedding来生成每个segment对应的类别概率分布;通过MLP将per-segment embedding转化为N个mask embedding,其维度为\(C_{\epsilon}\)。最后将per-pixel embedding与mask embedding做点乘再过sigmoid得到每个segment的预测掩码:
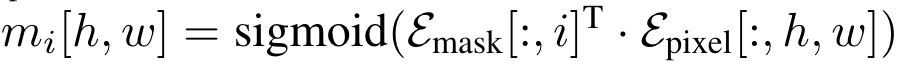
计算loss则采用与DETR相同的方式,将focal loss与dice loss线性组合。
Mask-classification inference
General inference
针对语义分割和全景分割,可以使用统一的推理方式确定每个像素的类别和区域:
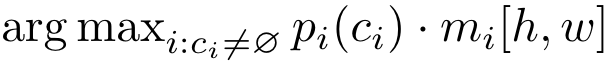
其中\(c_i\)是这个segment最有可能属于的类别,\(m_i[h, w]\)是当前像素属于segment的概率。
为了减少全景分割中的假阳性率,作者采用了Panoptic segmentation等文章中的策略。
Semantic inference
针对语义分割,计算的方式是:
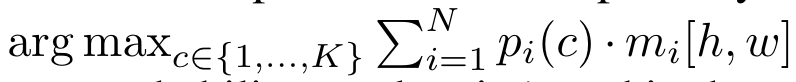
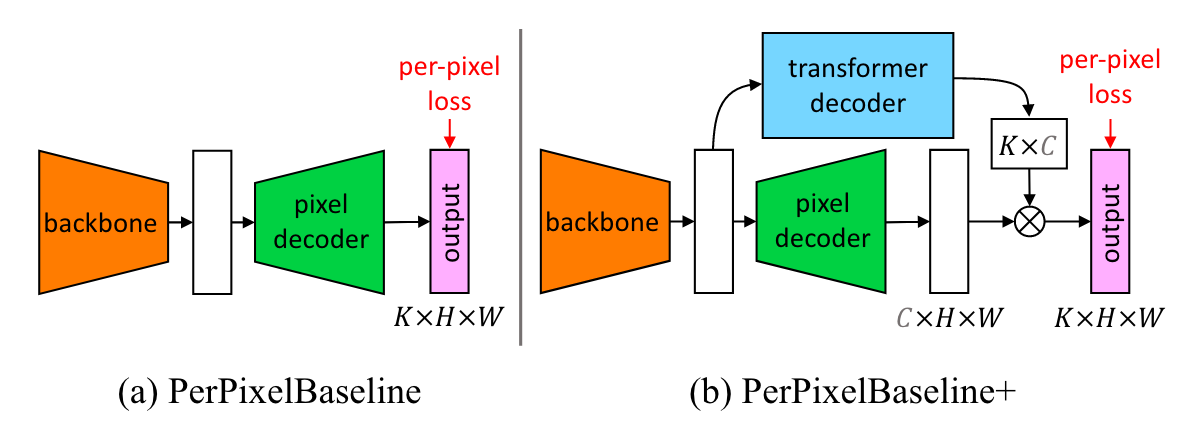
实验
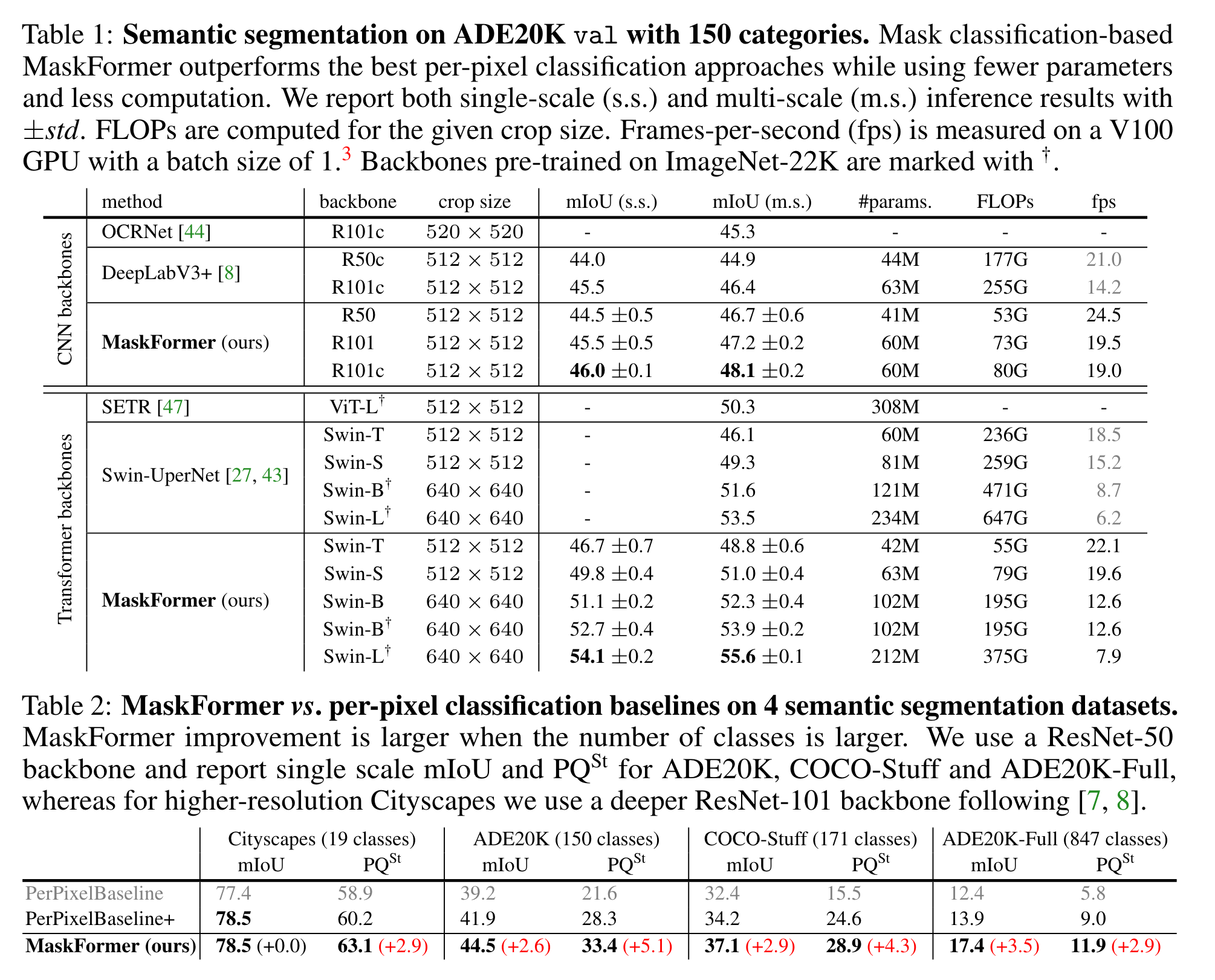

区域数量N的实验:
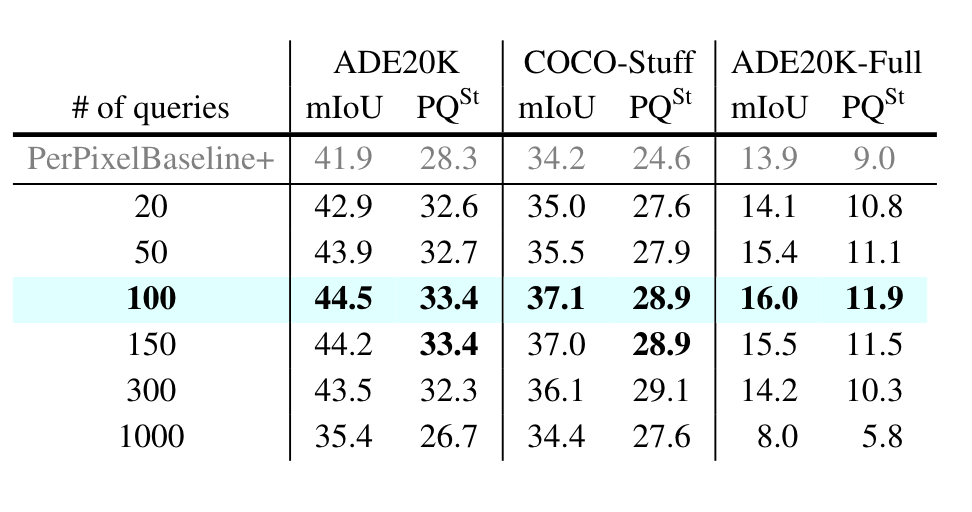
N是固定的吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号