Learning to Prompt for Continual Learning论文阅读笔记
摘要
本文的主要贡献是提出了一种连续学习的方法L2P,可以自动学习提示(Prompt)一个预训练的模型,从而能够在学习一系列的任务的同时减轻灾难性遗忘,并且这个过程无需使用记忆回放等方法。本文的方法中提示是小的可学习的参数,最终目的是优化提示从而在保证可塑性的同时指导模型的预测以及明确地管理任务变量和任务特定知识。
方法
From prompt to prompt pool
作者列举了使用prompt pool的动机:首先任务的同一性在测试时难以得到保证,所以针对每个任务训练prompt不可行(个人理解是测试时所有任务是混杂在一起的,无法针对某个测试样本使用其对应的prompt);其次即使测试时针对每个task样本使用特定的prompt,这也会限制相似任务之间的知识共享;最后,如果针对所有的task使用相同的prompt,虽然可以实现知识共享,但会加剧遗忘(作者也通过实验进行了说明)。理想的情况是针对相似任务进行知识共享,不同的任务要保持知识的独立性,因此作者提出了prompt pool存储编码后的知识,其中包括M个prompt,每个prompt的shape与编码后的特征一样。从中取N个prompt组成一个子集,与原始输入拼接得到:
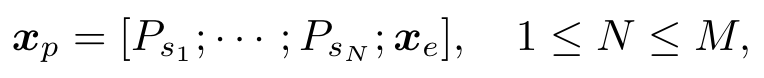
Instance-wise prompt query
作者设计了一个基于键值对的询问策略从而动态的为每个输入选择对应的prompt。每个prompt作为value对应一个可学习的key,其维度为,作者通过函数将属于的输入映射到,q对于不同任务是一个确定的函数,而冻结的pretrained model可以很好的完成这个任务:直接将输入通过特征提取器(ViT等)得到的cls token作为函数的值。用卷积网络进行特征提取也是可以的。之后将计算得到的询问与key计算余弦距离,取距离最小的前N个作为prompt子集。为了能让模型学到task-specific的prompt,作者还设计了Optionally diversifying prompt-selection,实际上就是按照每个prompt在过去task中被使用的频率对其进行加权:
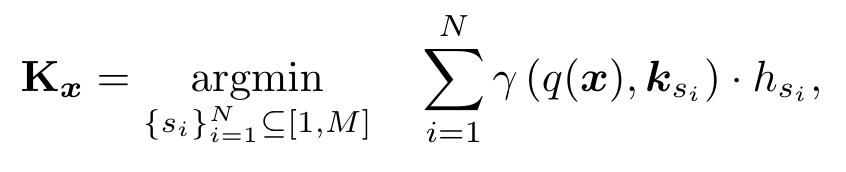
注意这个加权仅在训练时进行。
实验
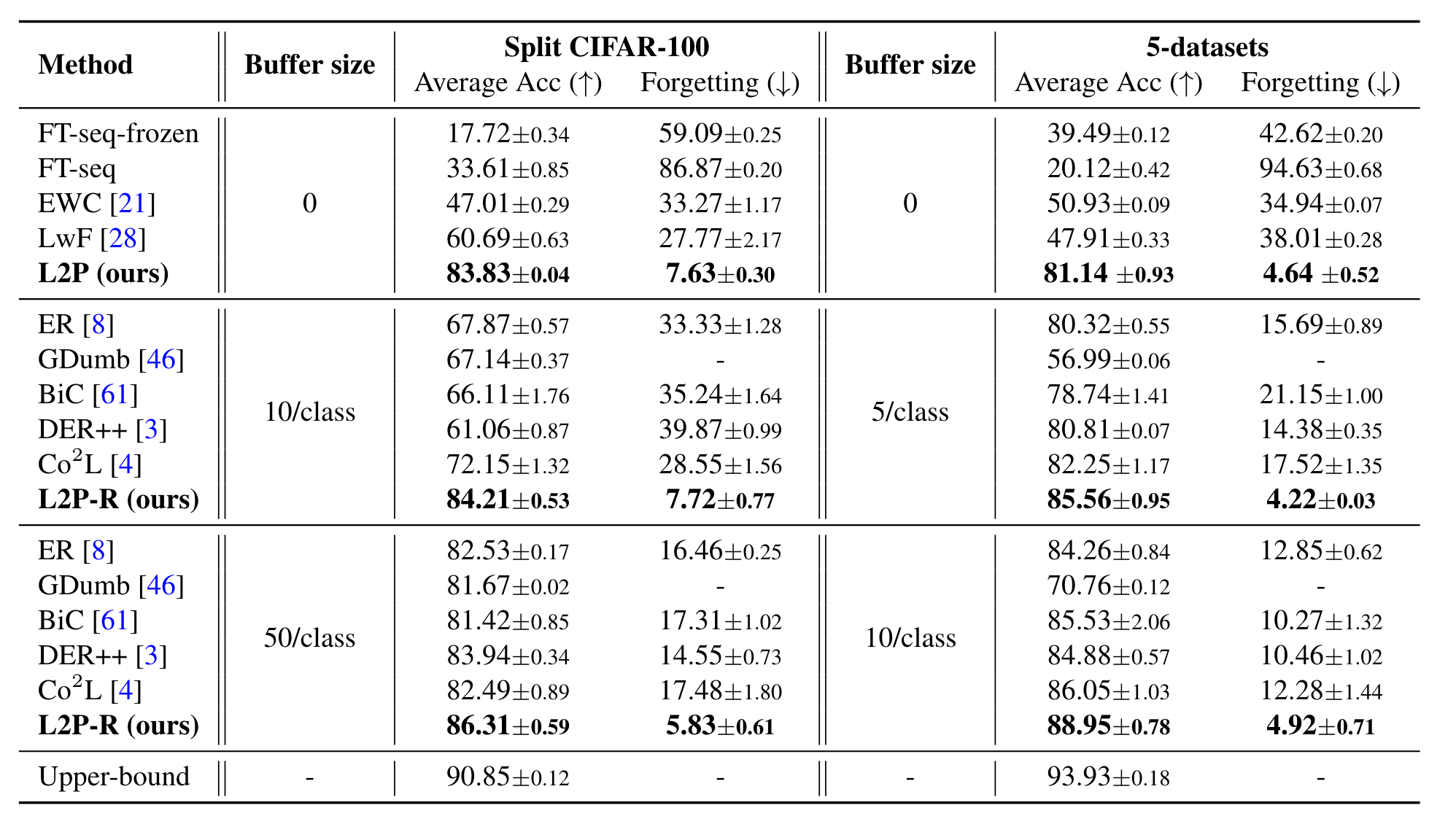
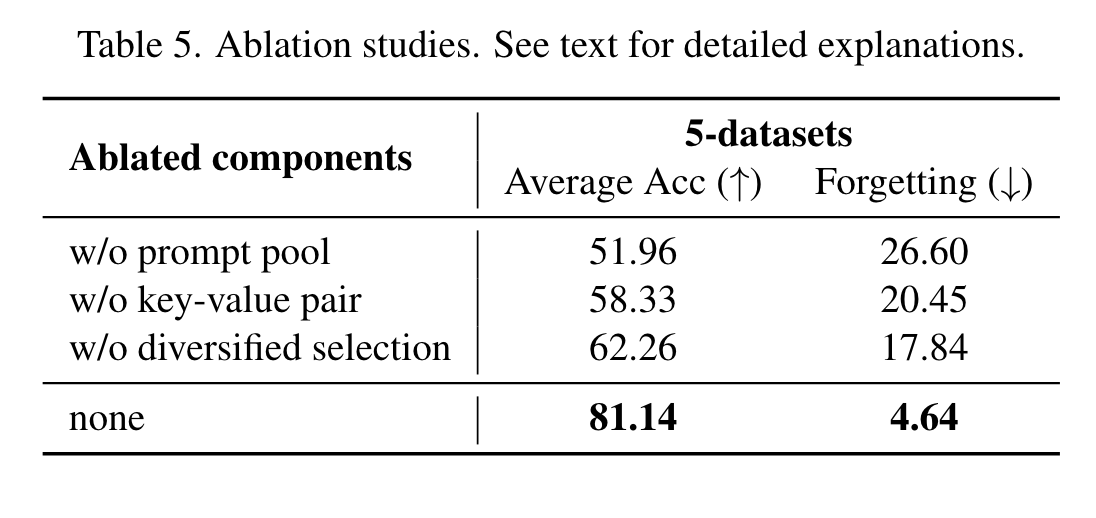
...



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2022-01-29 Leetcode 1765. 地图中的最高点(BFS)
2022-01-29 2022牛客寒假算法基础集训营3 ABCDEGIL
2020-01-29 洛谷 P1498 南蛮图腾