VISUALBERT: A SIMPLE AND PERFORMANT BASELINE FOR VISION AND LANGUAGE论文阅读笔记
摘要
作者提出了VisualBERT这一框架,其由一系列的Transformer layer组成,通过self attention将文本与图像隐式地对齐,甚至对于语法关系也很敏感。
方法
VisualBERT
方法的核心就是使用self attention对输入的文本以及图像区域隐式地进行对齐。这里作者引入了visual embedding,通过物体探测器对图像的一个区域生成得到。每一个embedding是如下三个embedding的和:
,边界框区域送入卷积神经网络计算得到;,用于表示这是图像而非文本的embedding;,position embedding,用于表示区域在图像的空间信息。之后将visual embedding与text embedding一起送入Transformer layer。
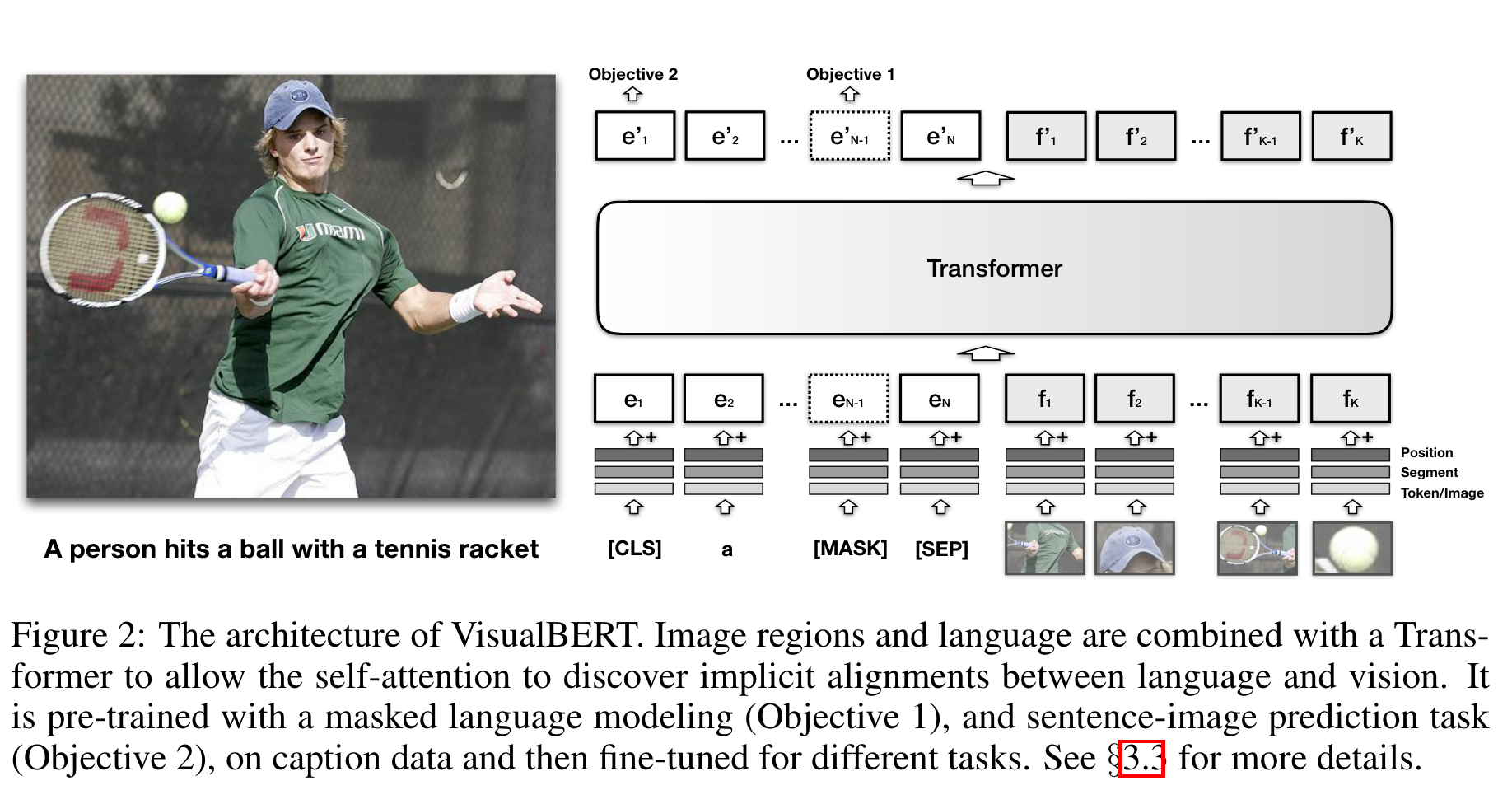
TRAINING VISUALBERT
训练过程分为三个阶段:
Task-Agnostic Pre-Training
训练时mask掉text的一部分并对其进行预测,但不对visual input进行mask。同时,COCO数据集中一张图像有若干caption,训练时text segment包含两个caption,一个是对应的,另一个有50%的概率变成另一个对应的,50%的概率变为一个随机的。
Task-Specific Pre-Training
将visual bert在下游任务fine tune前,通过masked language modeling使用目标任务的数据进行训练是十分有必要的。
Fine-Tuning
分类:
论文学习



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!