SUPERVISION EXISTS EVERYWHERE: A DATA EFFICIENT CONTRASTIVE LANGUAGE-IMAGE PRE-TRAINING PARADIGM论文阅读笔记
摘要
CLIP需要用大量数据去训练,因此本文提出一种数据高效的模型DeCLIP,相比于CLIP,使用了(1)每种模态内的自监督;(2)跨模态的多视角监督;(3)来自其它相似图像文本对的最近邻监督,可以在数据量大幅减少的情况下与CLIP-Res50媲美(ImageNet上做zs),同时在下游任务上能取得很好的表现。
方法
Self-Supervision within each modality
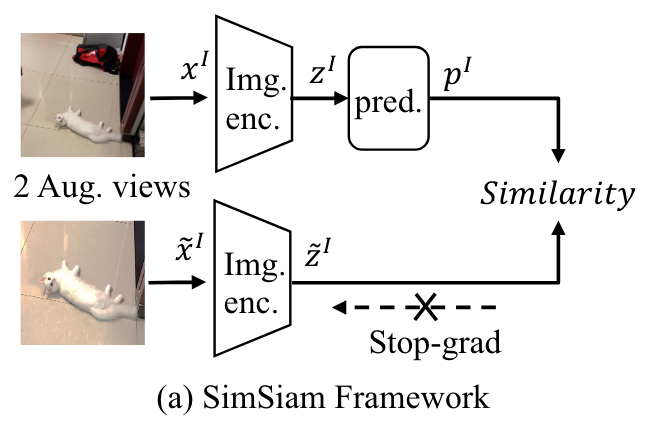
这里主要是使用原图与增广后(例如crop)的图像送入Image encoder计算相似度,同时增广图像的一路停止梯度反传。这里作者还使用了一个两层的MLP,用来提高Image encoder的表达质量,结构如下:
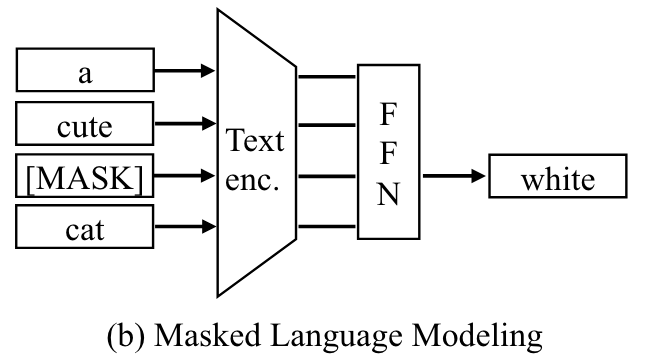
对于文本模态,作者采用了与Bert相同的自监督策略,在每个sequence中随机选择了15%的token进行替换,80%替换为[mask],10替换为随机token,10%不改变。之后将输出的结果与原始结果计算cross-entropy loss。
Multi-View Supervision
通常使用的是一张图片的全局特征与文本进行对比学习,但是文本描述的可能仅仅是图像的一小部分。比如“一只白猫”所对应的图片中猫猫占的比例可能很小。因此作者采用RandomResizedCrop来获得图像的一个small local view。为了理解句子的整体语义,作者使用EDA生成两种text views。这样就可以构建四种对比学习的损失(\(2\times 2\))。
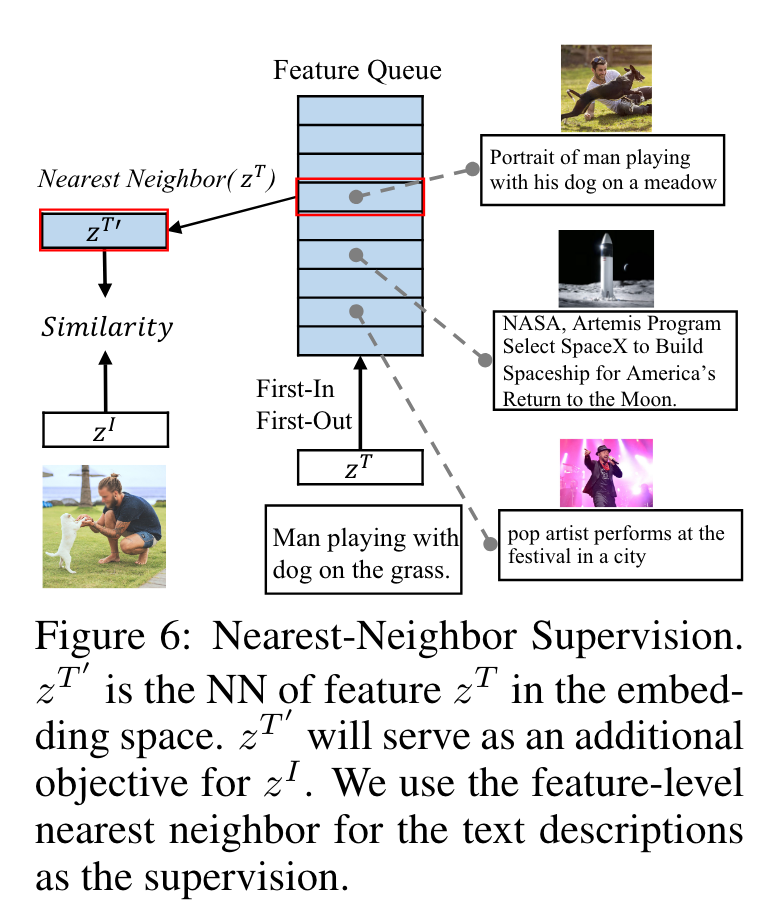
Nearest-Neighbor Supervision
对于一张图片往往有其它类似的文本描述,为此作者提出使用nearst-neighbor(NN)来获得更加多样性的监督方式,即在embedding space中找到当前文本的NN,距离采用余弦相似度进行计算。为了降低计算量,作者使用队列(大小为64K)来模拟整体的数据分布(这里没有搞懂队列是怎么构建的,有待研究源码)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号