Extract Free Dense Labels from CLIP论文阅读笔记
Extract Free Dense Labels from CLIP论文阅读笔记
摘要
这篇文章探索的是使用CLIP在像素级别上进行密集预测,作者提出的MaskCLIP可以在没有微调的情况下取得很不错的结果。通过伪标签和自训练的策略,MaskCLIP+可以在zero shot语义分割上达到SOTA。
引言
作者指出,不打破CLIP特征空间中的视觉与语言的联系是十分重要的。作者早起曾经尝试微调CLIP的image encoder(对于分割任务)并失败,例如将CLIP预训练的image encoder权重加载到DeepLab的backbone,之后微调分割相关的权重。同时,如果对text embedding进行操作会导致zs的时候效果变差。经过一系列测试,作者最终得到的work的model被称作MaskCLIP。然而,受限于CLIP的image encoder,很难对MaskCLIP的分割能力进行提高。于是,作者发现,不仅可以在推理期间部署模型,也可以在训练期间部署模型,让其生成高质量的伪标签。通过这样的自训练策略得到的模型成为MaskCLIP+。MaskCLIP+还可以用于进行zero shot的语义分割。
方法
作者首先介绍了他们一次失败的尝试,主要就是将DeepLab的backbone换成CLIP的image encoder,然后通过一个mapper将text embedding映射到DeepLab分类器(卷积)的权重。这样DeepLab无需重新训练就能分割不同的类别了。作者尝试了一系列的mapper的结构,将整个数据集分为两部分,取一部分进行训练,发现这样对于见过的类别表现不错,但对于没有见过的类别分割效果差。可能的原因有三点:backbone网络结构方面与image encoder略有不同(这里没太懂这个backbone指的是什么);对image encoder做fine tune导致泛化性降低;mapper只在见过的类别上训练,导致泛化性降低。
发现fine tune效果不好之后,作者尝试避免引入额外参数,同时修改CLIP的特征空间。CLIP的全局注意力池化层与传统的全局平均池化有所不同,其计算方式如下:
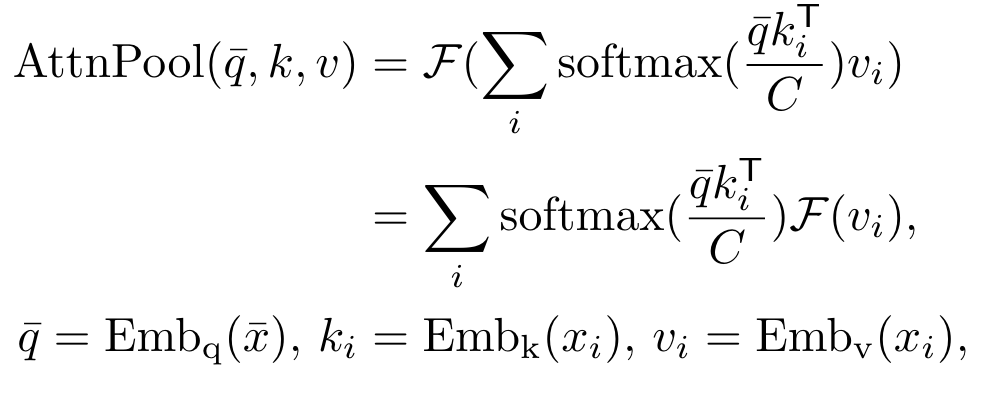
相当于计算全局特征时,用每个token对应query的均值作为全局特征的query,分别与每个token对应的key计算注意力分数,再与过完线性层的value做矩阵乘法,相加得到最终的输出。作者认为这个Transformer层的输出可以作为图像的一个全局表示。
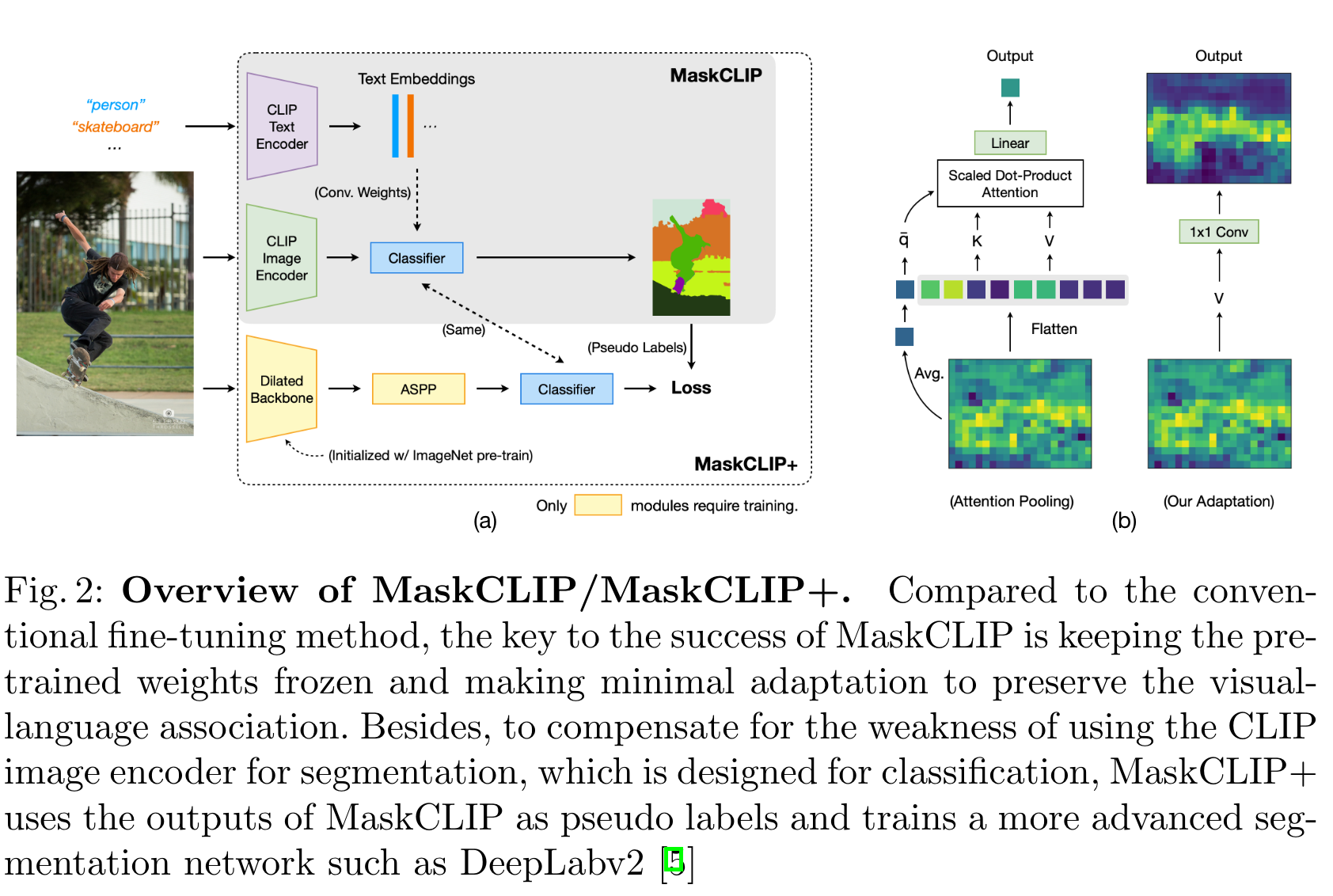
基于这种假设,作者对CLIP的image encoder进行了修改:移除了query和key的embedding层;改造了value的embedding层以及最后一个线性层为卷积,如上图所示。下面是代码:
q = self.q_proj(x)
k = self.k_proj(x)
q = torch.flatten(q, start_dim=2).transpose(-2, -1)
k = torch.flatten(k, start_dim=2).transpose(-2, -1)
v = self.v_proj(x)
feat = self.c_proj(v)
这里有点疑问,送到decoder的tensor的shape是什么样的?有待研究一下mmsegmentation...
text encoder保持不变,同时使用prompt,每个类的text embedding后的结果作为分类器:
def cls_seg(self, feat):
feat = feat / feat.norm(dim=1, keepdim=True)
output = F.conv2d(feat, self.text_embeddings[:, :, None, None])#增加两个大小为1的维度
return output
这里就是利用text feature作为卷积权重,相当于做了输入通道为文本特征长度,输出通道为类别数,kernel_size=1的卷积运算。
最终得到的模型称为MaskCLIP。需要注意的是全局特征的query是,并非。
因为MaskCLIP本身比较简单,作者还提出了两种策略:键平滑和prompt降噪。
原始的CLIP中,虽然参与训练,但最终还是没有使用,但也确实能看作是对对应patch的描述。因此,作者就借助key对预测结果做平滑:
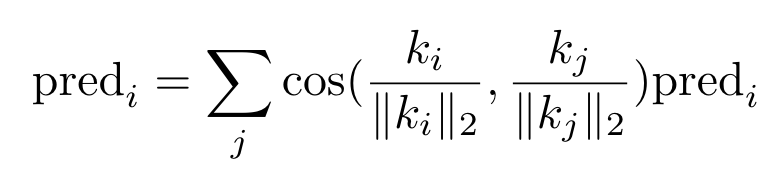
对于这个公式,我个人的理解是,假设一个patch的key与其它patch都不相似,那么这个patch的结果就很不可信,但总感觉有点奇怪...
prompt去噪比较好理解,一张图包含的类别实际上是比较少的,其余的类会分散注意力。所以作者提出了prompt去噪,如果目标类在所有空间位置上的类别置信度都小于阈值t=0.5,就会删除带有目标类的提示。
然后就是MaskCLIP+,实际上就是用MaskCLIP生成伪标签。具体的伪代码如下:

同时,作者还将目标网络的分类器换成了MaskCLIP。借助这样的训练策略,MaskCLIP指导的学习同样适用于zero shot。这里文章分析了一下,部分方法利用CLIP的image-level的视觉特征与当前训练的目标网络做蒸馏,这在进行zero shot的时候可能会导致见过的类和没有见过的类之间的冲突。
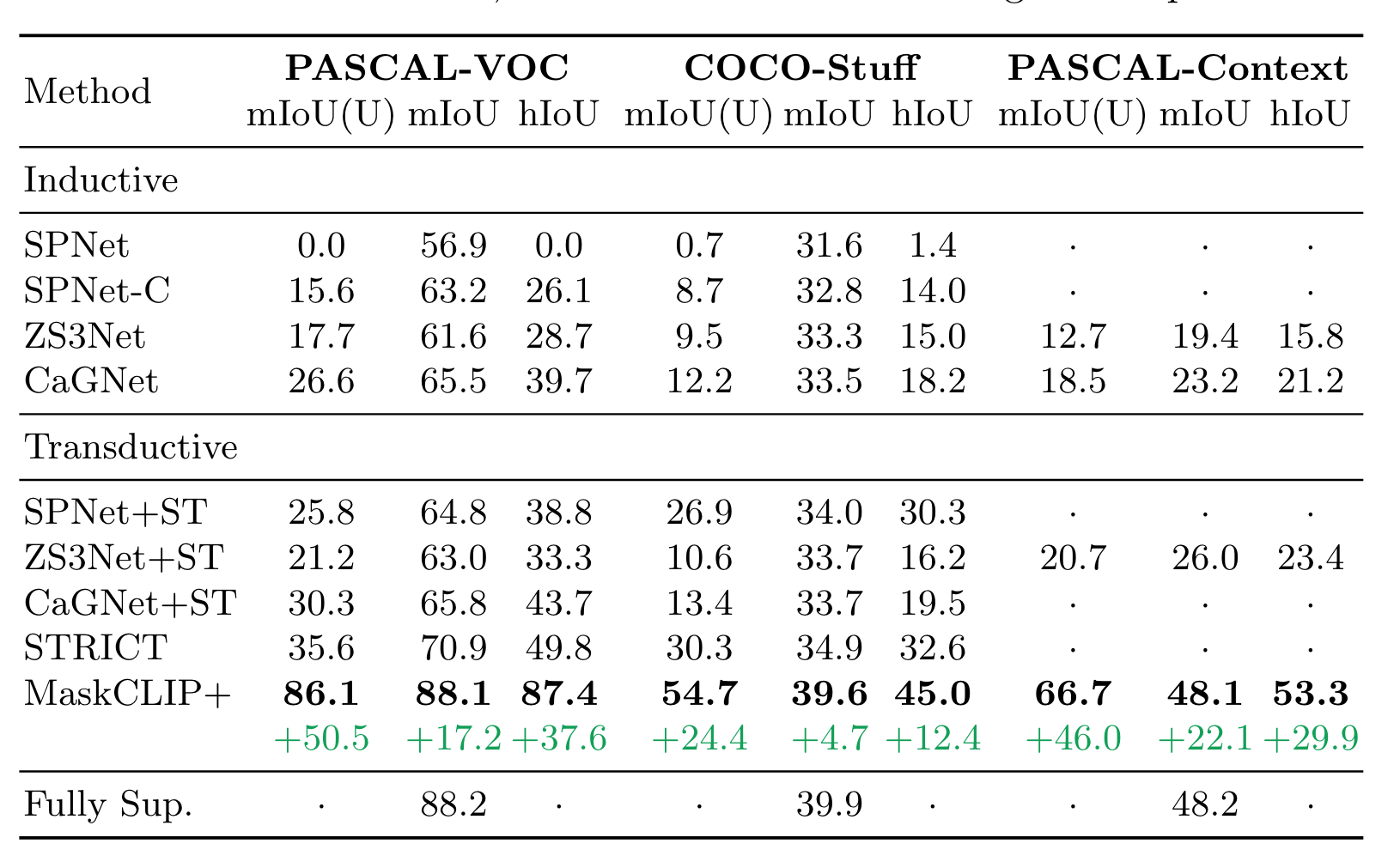
实验
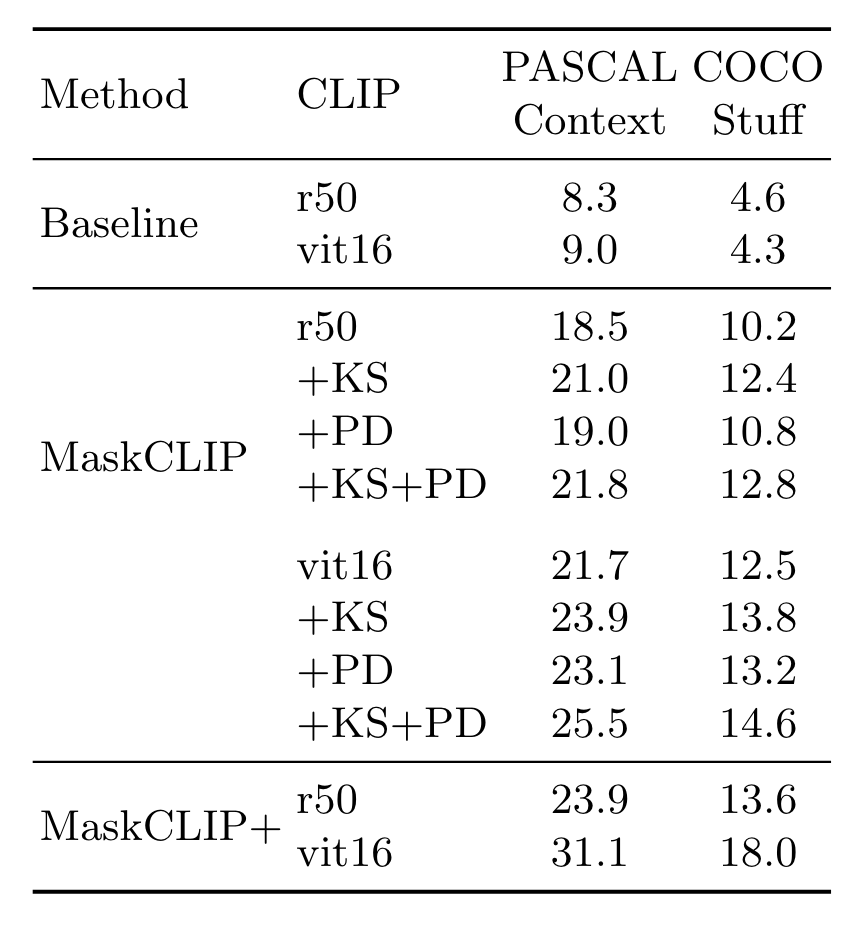
实验部分一个比较有挑战性的setting是Annotation-Free Segmentation,即在训练期间提供的数据都是无标注的。相比于baseline(在最后一层计算attention),直接使用value效果更好:
作者还在从网络抓取的图片上测试了Open-Vocabulary Segmentation,对于一些比较novel的概念也能很好的学习并分割,例如蝙蝠侠和小丑/比尔盖茨和乔布斯/马里奥和路易吉:

不仅是annotation-free segmentation,MaskCLIP+也可以用于zero-shot segmentation。zero-shot的setting感觉和continual seg很契合,做得好了就可以很自然的解决背景漂移的问题。
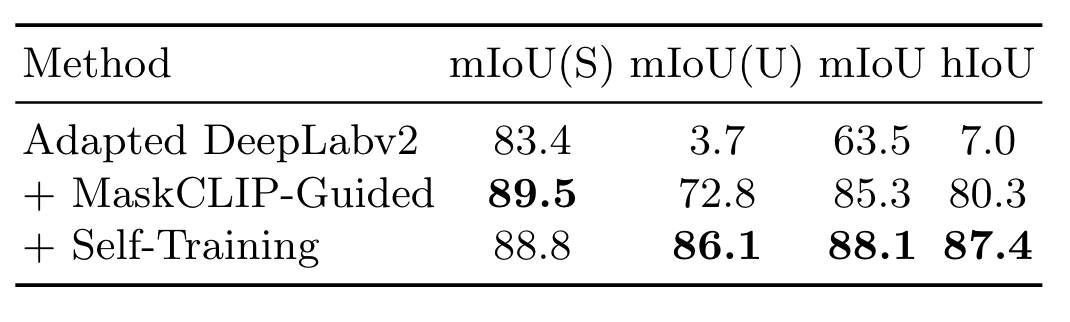
消融实验:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!