CRIS: CLIP-Driven Referring Image Segmentation论文阅读笔记
摘要
这篇文章要做的任务是RIS(Referring Image Segmentation),就是通过自然的语言表达来分割一个参考物,而整合文本与像素级的特征是非常有挑战性的。作者受到CLIP的启发,设计了一个visual-language decoder以促进两种模态之间的一致性。同时,作者还提出了文本到像素的对比学习。
方法
首先作者使用ResNet和Transformer分别提取图像和文本特征,然后将特征进行融合以获得多模态的特征,之后这些特征和文本特征被送入visual-language decoder,最后使用两个projector(?)来产生最终的预测掩码,并采用文本到像素的对比损失将文本特征与相关的像素级视觉特征对齐。
Image & Text Feature Extraction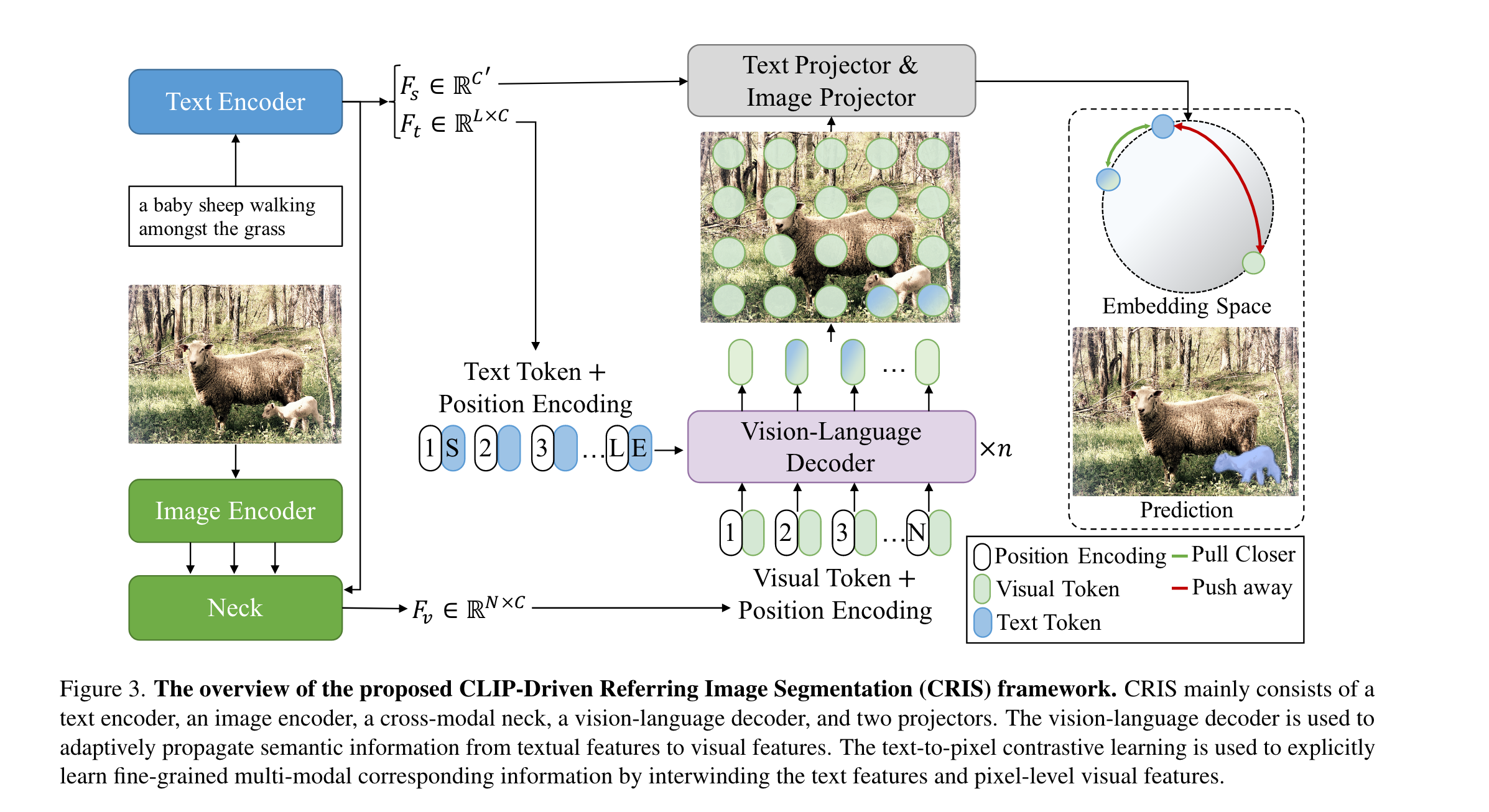
Image Encoder
作者使用四个Stage的ResNet进行特征提取,其中,..,。
Text Encoder
对于输入,通过Transfomer提取到的特征为。全局文本表示。其中是特征维度,是referring expression的长度。
Cross-modal Neck
给定多个视觉特征和全局文本表示,可以通过融合以及得到简单的多模态特征:
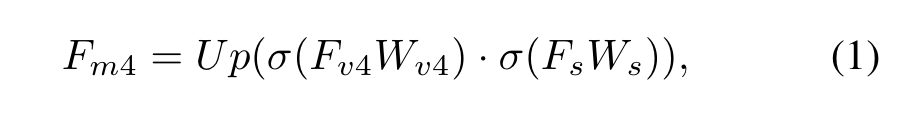
其中Up是上采样两倍,·表示对应元素相乘,表示ReLU,是可学习的变换矩阵,用于将两个模态的特征变换到同一个特征空间。随后的和:
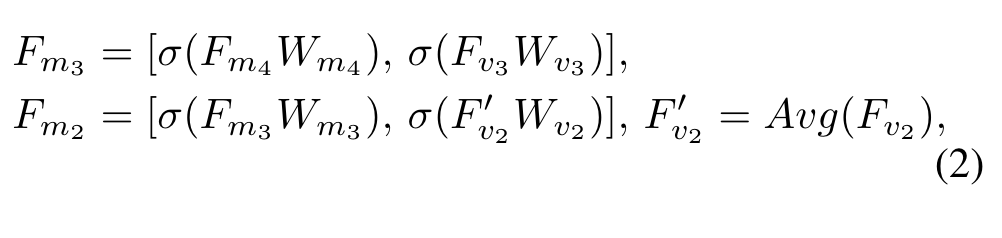
Avg表示核尺寸为(2, 2),步长为2的平均池化,[]表示concat操作。拼接后的特征通过卷积进行聚合得到:
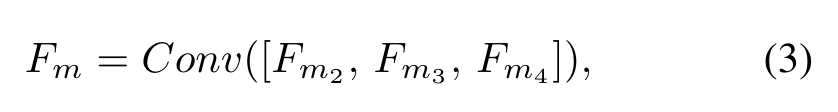
其中。最后,作者将2D的空间坐标特征与拼接并通过卷积进行融合:
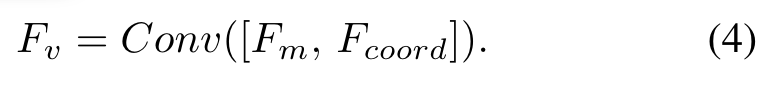
其中。
Vision-Language Decoder
作者设计的视觉语言解码器可以将细粒度的语义信息从文本特征传播到视觉特征。如图3,解码器模块的两个输入分别为以及,其中。为了捕捉到位置信息,作者还加上了正弦位置编码。vision-language decoder由n个layer组成,用于生成多模态特征序列。和标准的Transformer结构类似,每个layer包括一个多头自注意力,一个多头交叉注意力以及前馈网络。在每个decoder layer中:
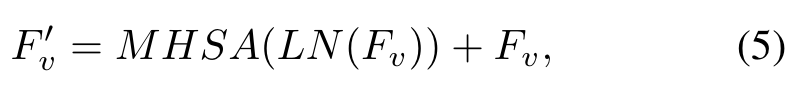
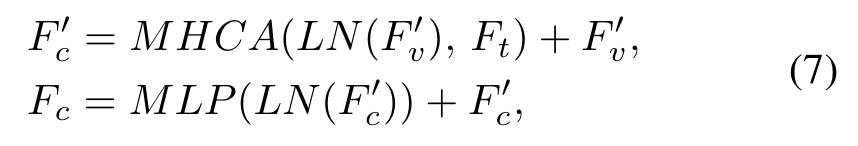
对于MHCA,映射为Q,映射为K和V。得到的被用于最终的分割。
Text-to-Pixel Contrastive Learning
目前学到的知识实际上缺乏精细的视觉概念,这对于分割来说是远远不够的。因此作者还设计了文本-像素对比损失,其将文本特征与相应的像素级视觉特征联系起来。如图3,Text Projector用来转换,Image Projector用来转换:
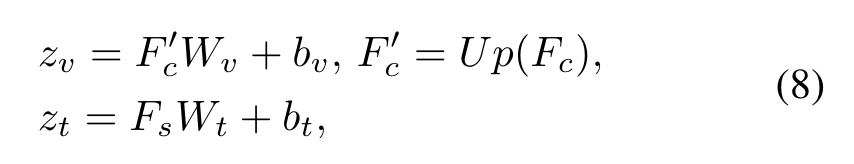
其中。Up表示四倍上采样(为了尽可能恢复原图的分辨率?)。W和b分别是权重以及偏置。
因此,给定变换后的文本特征以及一系列变换后的像素级特征,就可以计算对比loss了,目的是让和与之对应的尽可能相似:
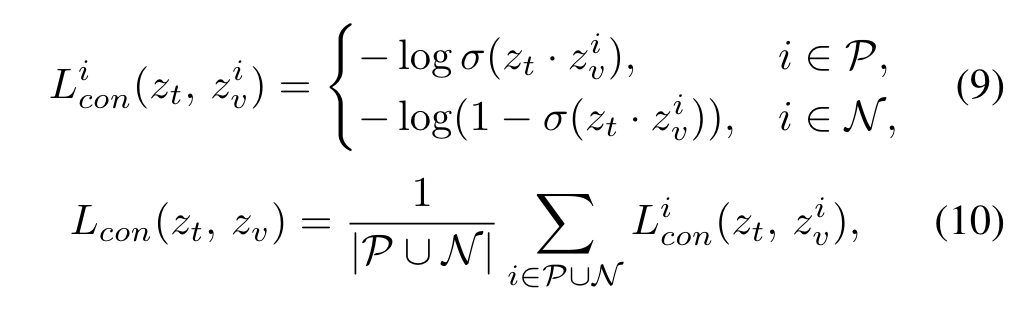
其中和分别表示gt中类别“1”和类别“0”的数量,代表sigmoid函数。为了得到最终的分割结果,作者讲reshape为并上采样为原图大小。时要让和相似度尽可能大,softmax后趋近于1,取负log后趋近于0,即让loss尽可能小;时类似。
实验
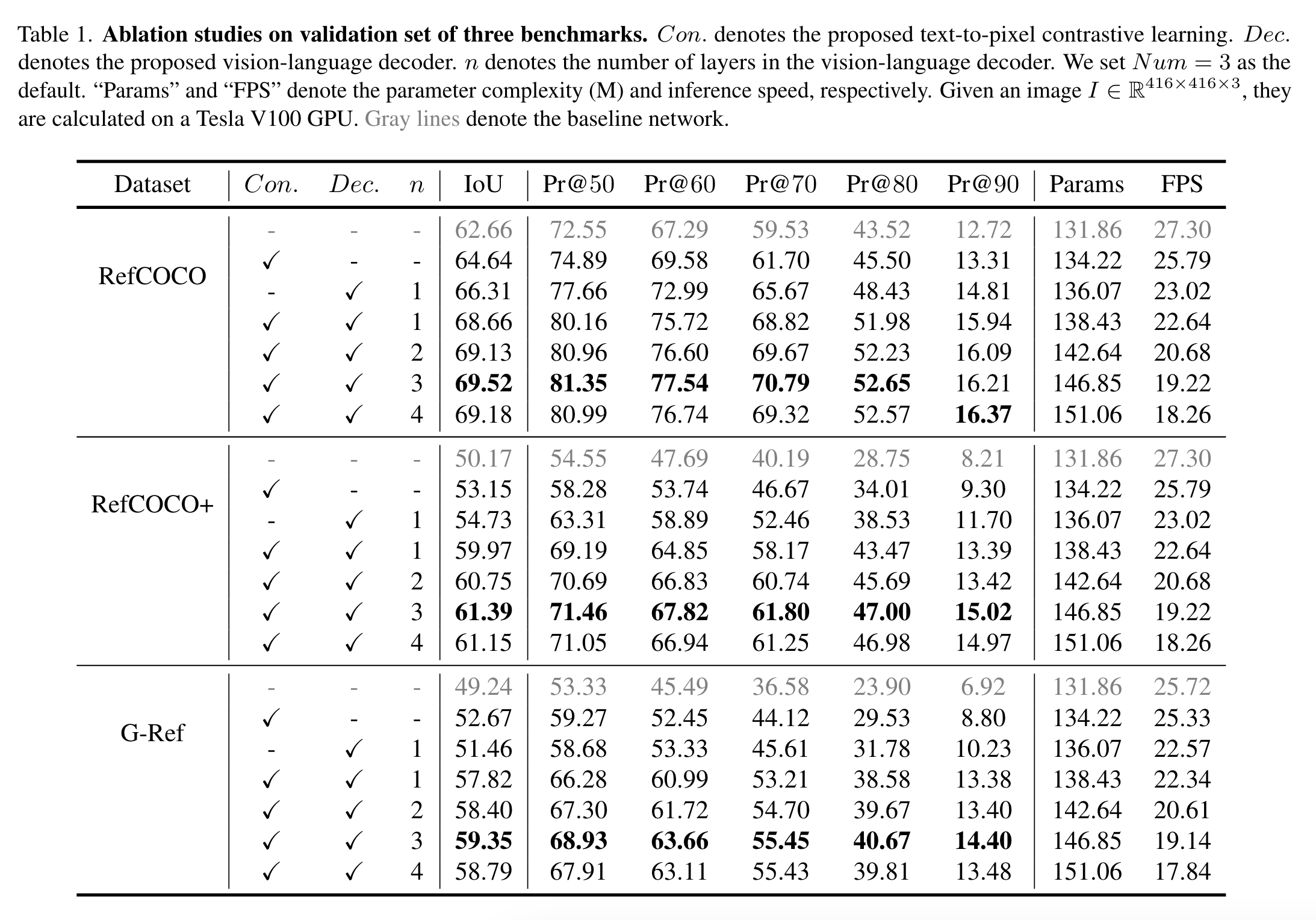
实验结果可以查阅论文原文。作者这里列举了一些例子:

比较有趣的是这些failure case。第一种导致failure的原因是输入的表达具有歧义(左上图),其次是标签标注问题()右上图),最后是遮挡问题(右下图)。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2020-10-19 函数实现复合命题的计算及判断两个命题是否等值——中缀表达式转后缀表达式