LANGUAGE-DRIVEN SEMANTIC SEGMENTATION论文阅读笔记
LANGUAGE-DRIVEN SEMANTIC SEGMENTATION论文阅读笔记
摘要
文章的主要贡献是提出了一种新的语言驱动的分割模型LSeg,其使用Text encoder编码描述性的输入标签,使用Image encoder计算图像的逐像素的embedding。图像编码器使用的是对比目标训练,目的是将像素的embedding与对应文本标签的embedding进行对齐。text embedding提供了灵活的标签表示,因此本文的模型可以直接进行zero-shot推理。
方法
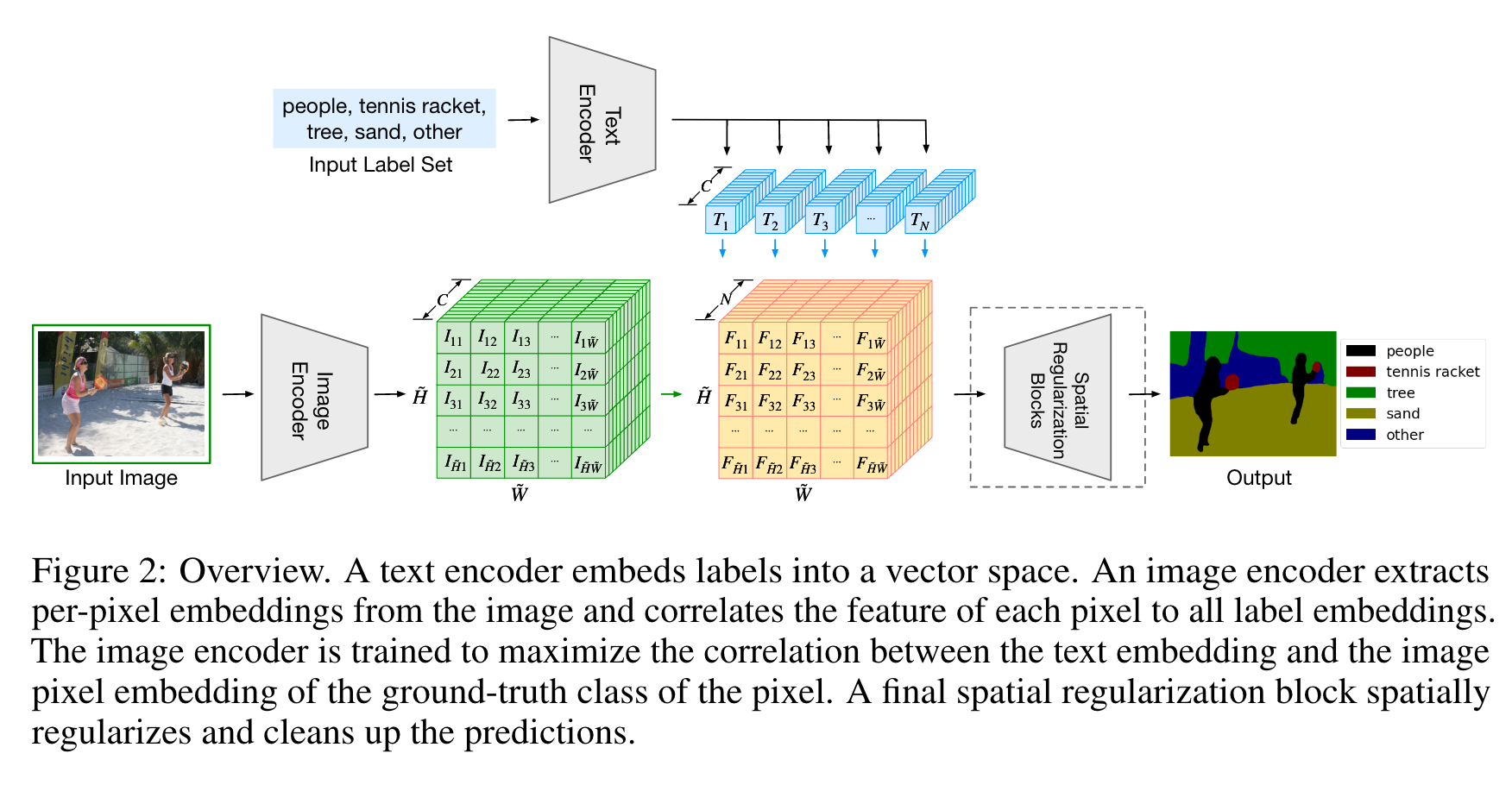
Text encoder
Text encoder对N个标签进行编码,每个标签编码后的长度为C,因此编码后张量大小为。这里作者直接使用了预训练的CLIP的Text encoder。
Image encoder
Image encoder对每个下采样后的像素进行编码。这里使用的基础模型是DPT(dense prediction transformers),设图片大小为,下采样倍率为,则得到的结果大小为,其中,W同理。
Word-pixel correlation tensor
将Text encoder与Image encoder得到的结果相乘得到大小为的张量,之后在N这个维度上做softmax,其中t为温度: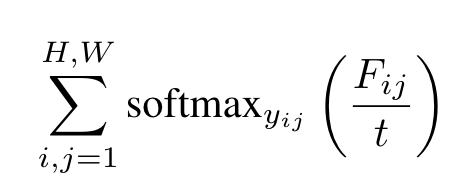
Spatial regularization
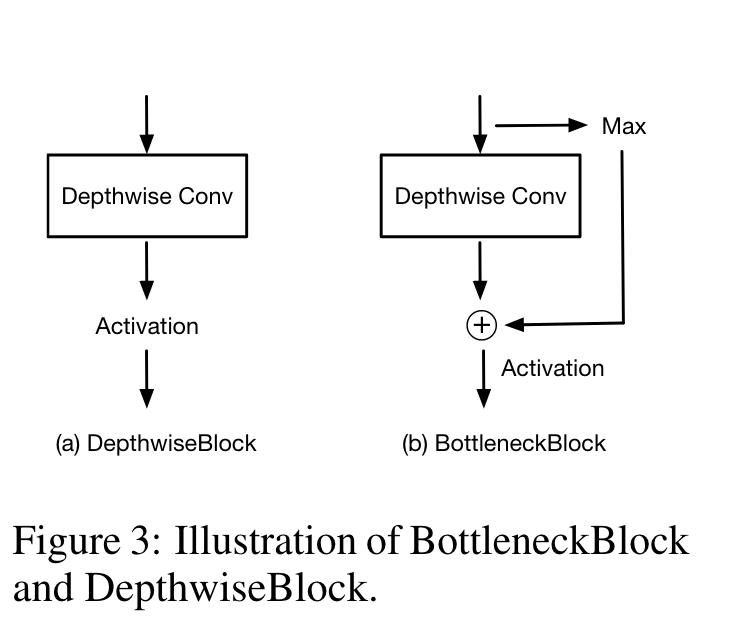
这个模块主要是将预测结果上采样回原图的尺寸。首先通过DepthwiseBlock或者BottleneckBlock进一步学习文本图像融合后的特征,理解文本与图像如何交互,然后通过双线性插值得到原图大小的结果。论文中说输入通道之间不应该有任何相互作用,所以使用的是DW Conv。实验证明这个模块带来的提升比较小,因此可以暂时先不去管。
实验
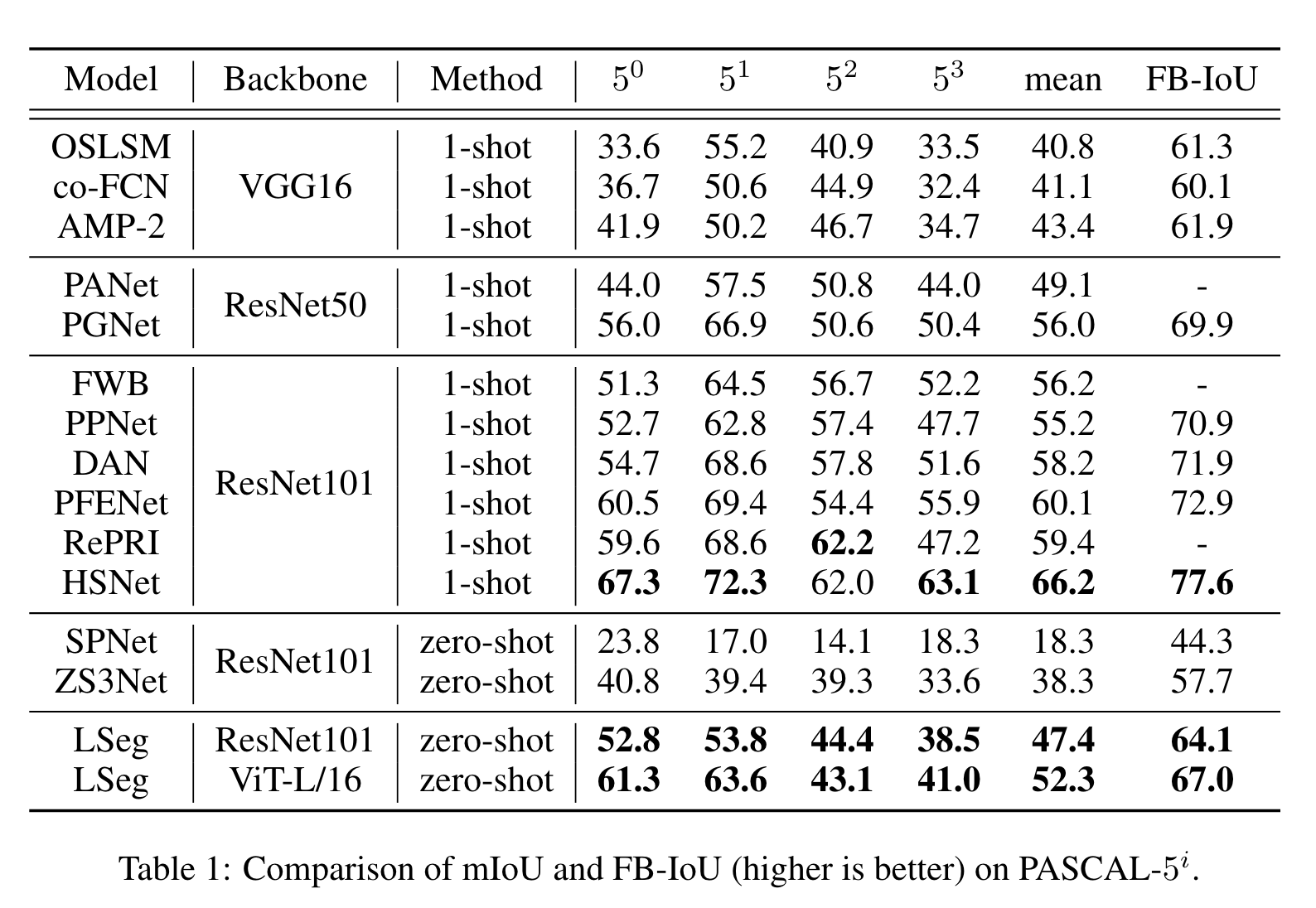
实验结果表明在zero-shot上效果比较好,但是即便是使用ViT-L也比不过one-shot的sota。
补充:文章提出的方法虽然是叫做文本驱动的模型,但是仍然是有监督的,loss是由计算得到的与label算出来的,大概是用的CE。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2021-10-18 理解转置卷积
2020-10-18 转载——vim命令操作