PLOP: Learning without Forgetting for Continual Semantic Segmentation论文阅读笔记
PLOP: Learning without Forgetting for Continual Semantic Segmentation论文阅读笔记
提出了多尺度的局部池化蒸馏和伪标签思想,使用伪标签实现对过去类别的保留,避免背景漂移。
视频讲解:https://www.bilibili.com/video/BV1Na41167aq?spm_id_from=333.337.search-card.all.click
摘要
为了应对灾难性遗忘的问题,作者提出了Local POD—一个多尺度的池化蒸馏方案,在特征层面其能够保持长/短程的空间关系。同时,作者针对旧模型预测的类设计了一个基于熵的背景伪标签,用来处理背景漂移并避免旧类别灾难性遗忘的问题。
PLOP框架
连续语义分割框架
此部分作者指出连续语义分割的两大问题,即灾难性遗忘和背景漂移。然后针对训练过程的第t步,将深度模型看作特征提取器f和分类器g的组合。
使用Local POD进行多尺度局部蒸馏
减轻连续学习中灾难性遗忘的常见方法包括在旧模型和当前模型的预测之间使用蒸馏损失。Pooled Outputs Distillation(POD)可以在不同的特征层面将旧模型与新模型的全局统计数据进行匹配。提取一个POD embedding包括拼接两个tensor:宽度池化切片和高度池化切片。如下图公式:
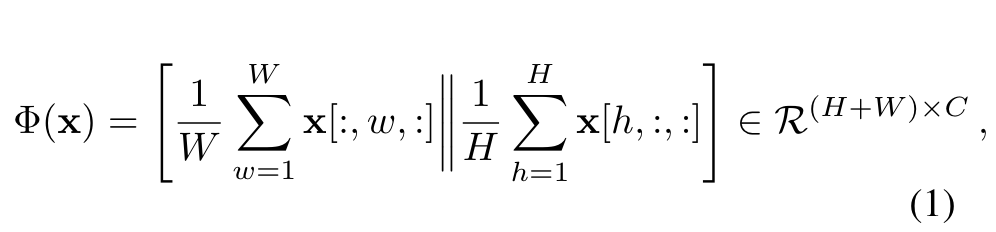
||表示在通道维度进行拼接操作。作者在新/旧模型的若干层进行的计算,通过最小化L2距离保证不会遗忘太多学到的知识: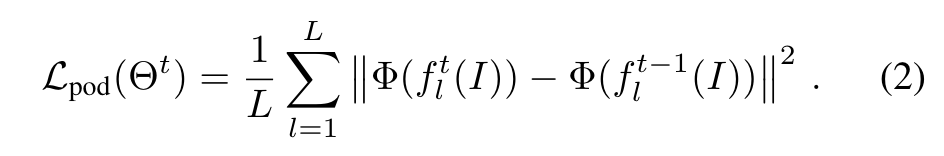
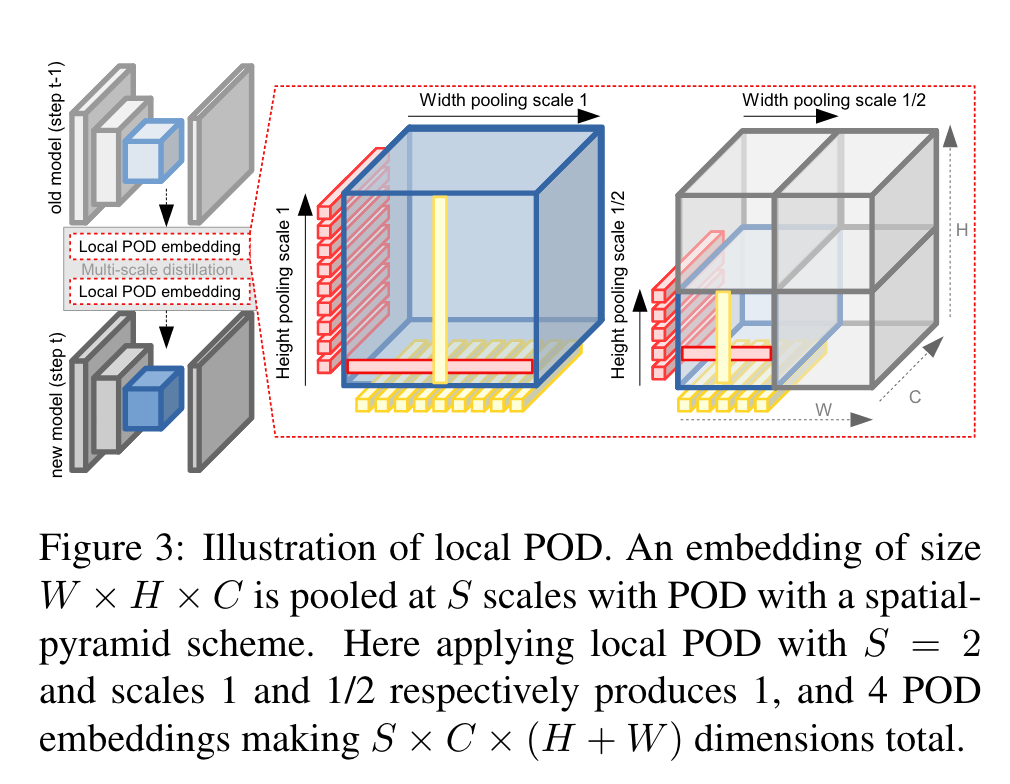
但是,这样的话空间信息在分类的过程中就被丢弃了,而语义分割需要更高的空间精确度。作者受到这种多尺度结构的启发,提出了local POD 特征蒸馏策略,其计算以不同尺度提取的多个区域的宽度和高度池切片,如下图所示:
每一个尺度的计算结果如下:
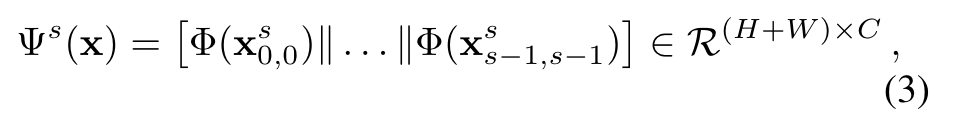
最终结果就是把每一个尺度的结果进行拼接:
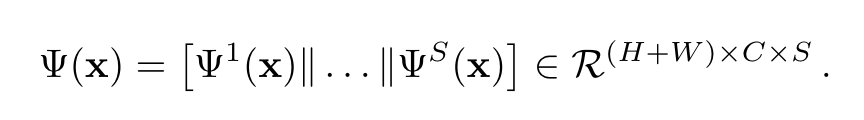
Local POD 损失计算方式如下:
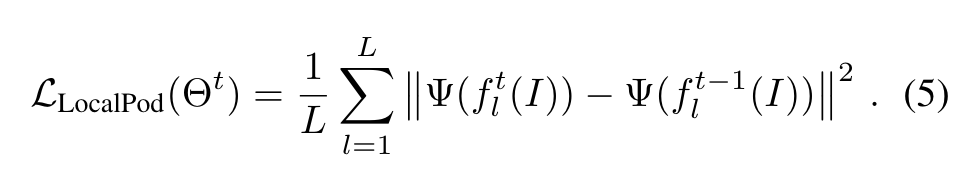
在s = 0的时候,效果等同于POD,模型具有捕捉长程依赖的能力,s = 1, 2...的时候则可以捕捉到短程依赖,这可以限制新模型和旧模型在局部有相似的统计数据。因此,Local POD 允许保留远程和短程空间关系,从而减轻灾难性遗忘。
通过伪标签解决背景漂移
当前step的背景类中混入将来的类/过去的类很可能导致灾难性遗忘的现象更加严重。伪标签被广泛应用于基于领域自适应的语义分割。作者在论文中,对于每一个step,首先用旧模型生成伪标签,与当前的ground truth一起作为target,如下图:

作者用表示当前模型的预测结果,用表示target。用one-hot表示如下:
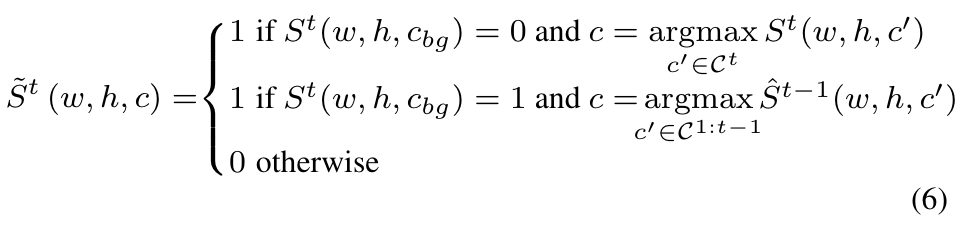
然而, 对所有的背景像素进行伪标记的效果可能不好,原因在于有的像素旧模型实际上不能确定(个人感觉有点零样本学习的意思..?)。因此,作者考虑对上式进行修改,对于背景像素,只有置信度足够高才进行伪标签的分配:
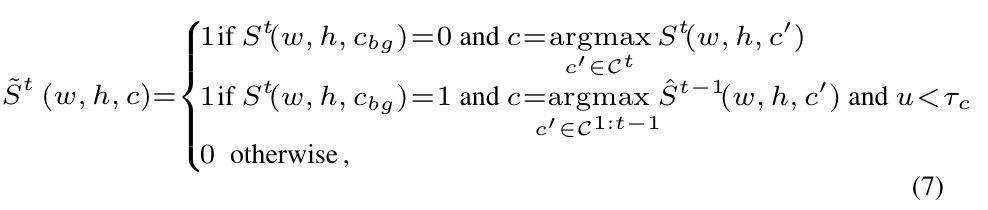
u是像素的不确定度,是特定类别阈值。交叉熵损失函数如下:
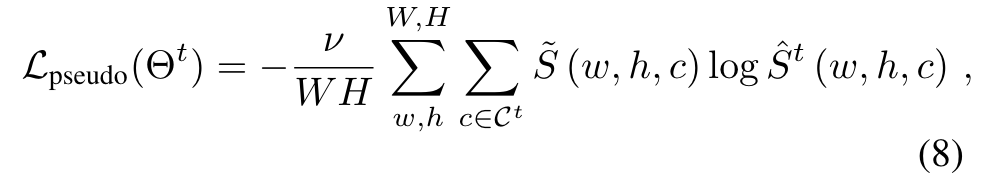
总的损失函数:
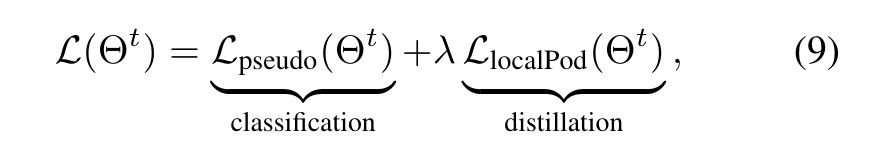
实验
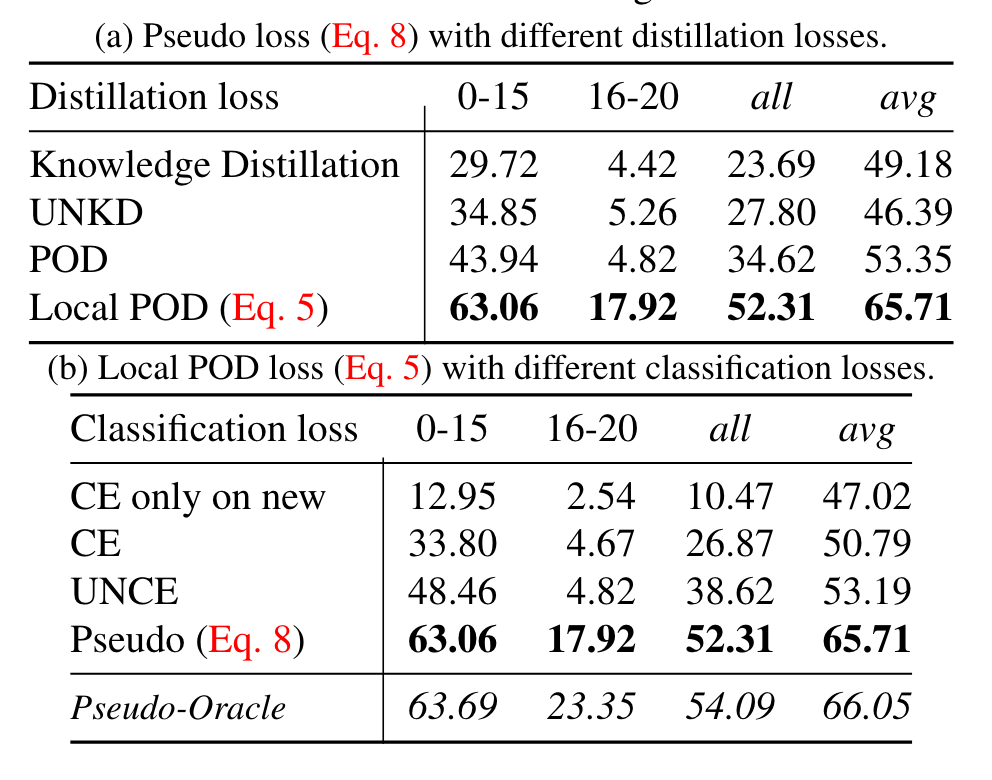
消融实验证明了文章提出的两种策略的有效性。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!