Modeling the Background for Incremental Learning in Semantic Segmentation论文阅读笔记
Modeling the Background for Incremental Learning in Semantic Segmentation 论文阅读笔记
前置芝士:多分类语义分割的交叉熵损失函数可以参考https://blog.csdn.net/weixin_47142735/article/details/117788476
为了应对灾难性遗忘以及背景漂移,作者提出了两个创新点:1. 新的基于知识蒸馏的框架。2. 新的初始化分类器参数的策略。
方法介绍
问题定义及符号
这部分作者主要是介绍了如何用符号描述连续语义分割这个任务。在增量分类学习(incremental class learning, ICL)中,训练是分为多个阶段实现的,被叫做learning steps,每一步都会引入新的类别来进行学习。同时,对于标准的ICL任务,作者假设在不同的step中获得的标签集是不相交的(除了特殊的void/background类:b)。
基于背景建模的语义分割增量学习
按顺序在每个集合上重新训练模型会导致灾难性遗忘。作者解释说使用当前数据进行训练时不会看到之前的样本,这会使得模型更偏向于新类别集合。通常的方法是给loss耦合上正则项,考虑每个参数对于之前任务的重要性,或者通过通过旧模型的预测结果进行知识蒸馏。作者从后一种解决方法得到启发,来初始化总体目标函数,最小化如下损失函数:
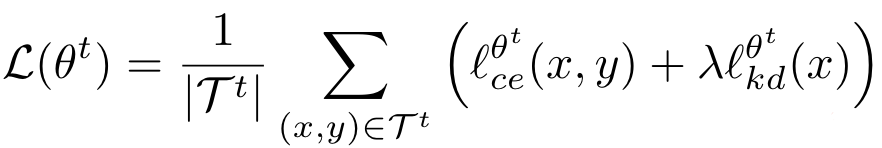
其中是蒸馏损失。和图像分类不同,不同的标签(已经出现的/尚未出现的)可能出现在当前的背景类中。在面,作者将通过重温上式说明如何解释背景类分布中的语义变化。
重温交叉熵损失函数
对于,一种可能的选择是在所有图像像素上计算的标准交叉熵损失:
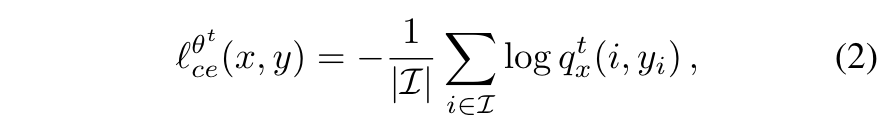
其中是i这个像素的ground truth,表示i这个像素属于这个类的概率。上式的问题是用于训练的数据只包含新类的信息,但是背景类中可能包含属于之前学习过的类别的像素,作者认为这会使灾难性遗忘更加严重。因此,作者考虑让模型去预测背景属于哪个之前学习过的类别,对交叉熵函数进行如下修改:
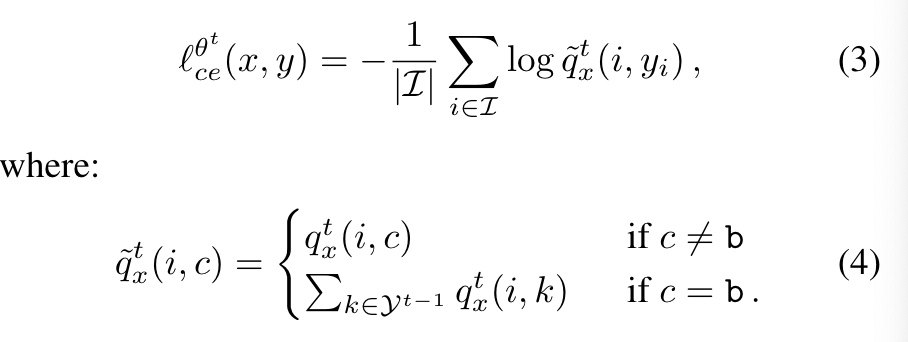
重温蒸馏损失函数
增量学习中,蒸馏损失是一种将旧模型学到的知识迁移到新模型的普遍的方法,可以有效防止灾难性遗忘。下面是一种标准的蒸馏损失:
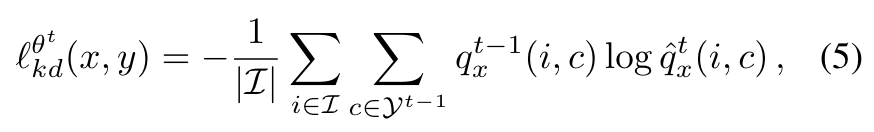
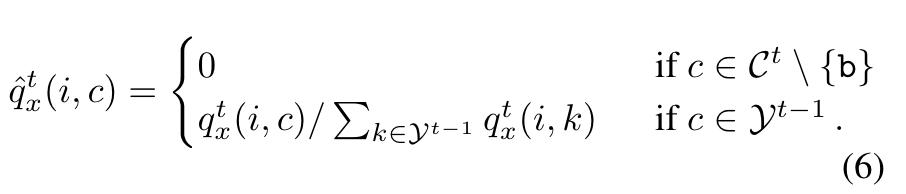
这可以保证模型经过训练后能够保持对属于旧类像素的辨别能力。(这里有一个问题,如果让概率值为0的话,log0不就趋近于无穷了吗?查了一下官方代码是这么说的:resize new output to remove new logits and keep only the old ones)
总之,按照之前的方法设置蒸馏损失尽管有较多的优势,但仍存在一些问题:其忽略了背景类在不同的学习步骤中是共享的这一事实,即在第t步中认作背景的像素很可能属于第s步(s > t)的某一非背景类。因此作者对蒸馏损失进行了优化:
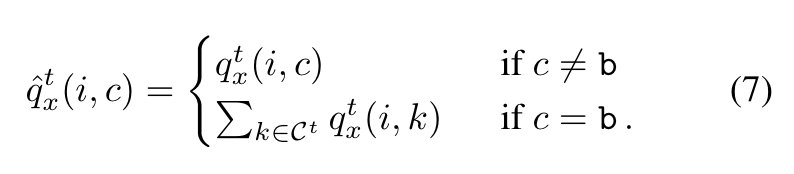
根据论文的图2以及这篇博客(https://blog.csdn.net/qq_39191000/article/details/115697056)总结一下:
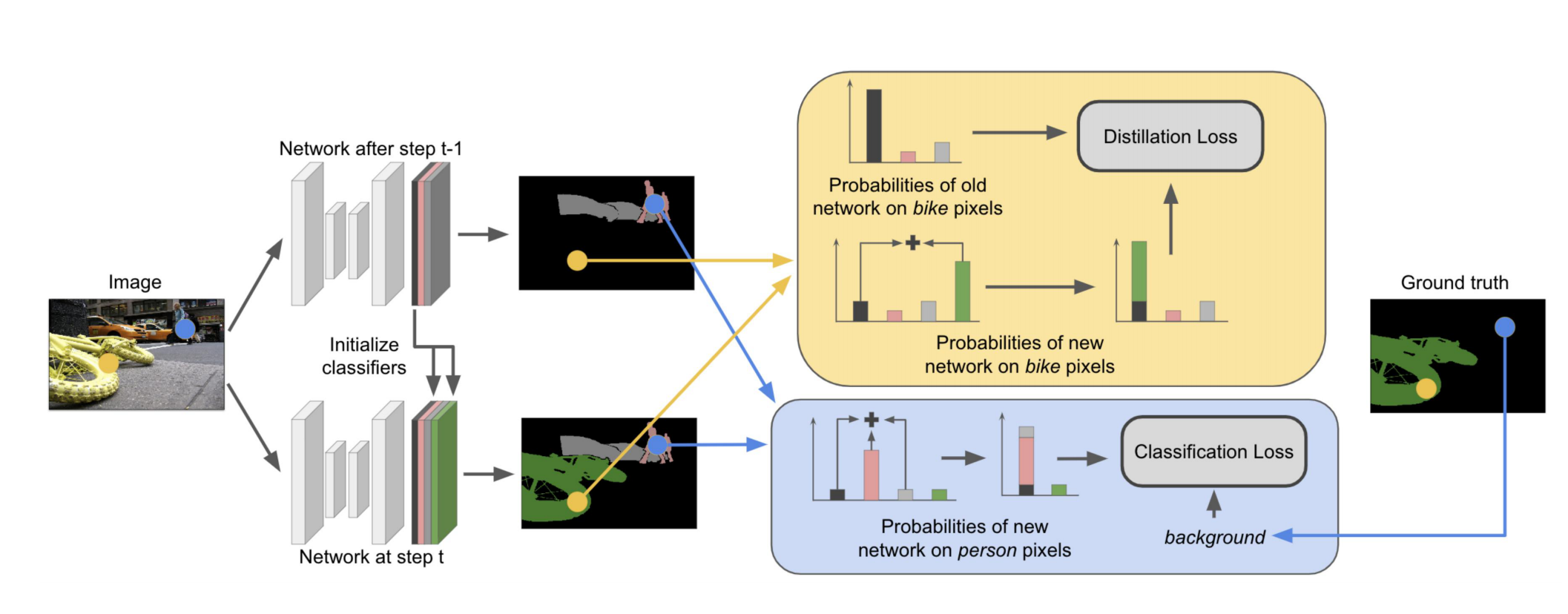
总体思想是对当前类别的学习采用交叉熵loss,同时计算当前类别和过去类别的蒸馏loss避免遗忘。为了解决background的问题,对两个loss进行转换。
对于新类别的交叉熵损失函数计算,背景部分的概率由(背景类别+过去类别)来表示,以此保留模型本身对过去类别的预测能力;
对蒸馏损失函数计算,将背景部分概率表示为(当前新类别+背景类别),故蒸馏旧类别的同时不影响对当前新类别的预测(下图黄色部分,把绿色对应的概率—新类与黑色对应的概率—背景类相加作为学生网络的背景类概率,与教师网络的背景类概率对应计算蒸馏损失,可以解决之前认作背景的像素属于当前新类别带来的问题)。
分类器参数初始化
作者指出,对于新的step,旧的分类器并不认识新的类,因此旧的模型很可能将属于新类的像素认作背景。事实上,随机初始化会导致模型提取的特征与分类器本身的随机参数之间的错位,这可能导致在学习新类时出现训练不稳定的现象,因为网络最初可以将当前类别中高概率的像素分配给背景类别。
因此,作者提出一种新的参数初始化方式,即用上一个step预测当前像素为背景的概率除以当前类别总数作为当前像素属于当前某个类的概率的初始值。考虑全连接层,对于参数,进行如下初始化:
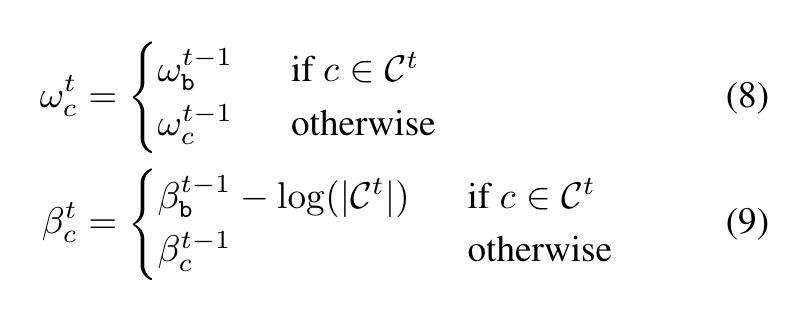
其中是上一步背景分类器的和,这样就能达到想要的效果了,如下图所解释:

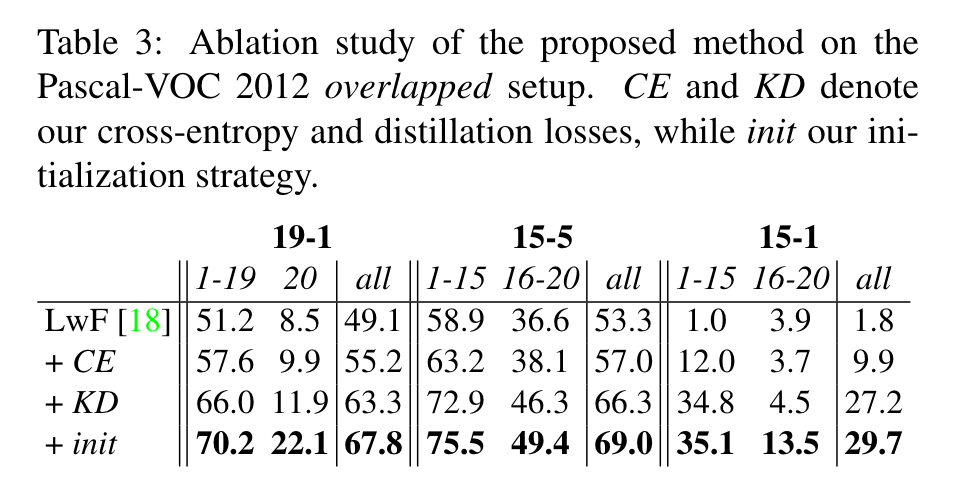
实验
值得关注的就是消融实验部分,证明了提出的策略的有效性。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!