机器学习(李宏毅)——终身学习笔记
Life Long Learning
问题背景
Life long learning通常写为LLL,别名:Continuous Learning、Never Endig Learning以及Incremental(递增的、渐进的) Learning。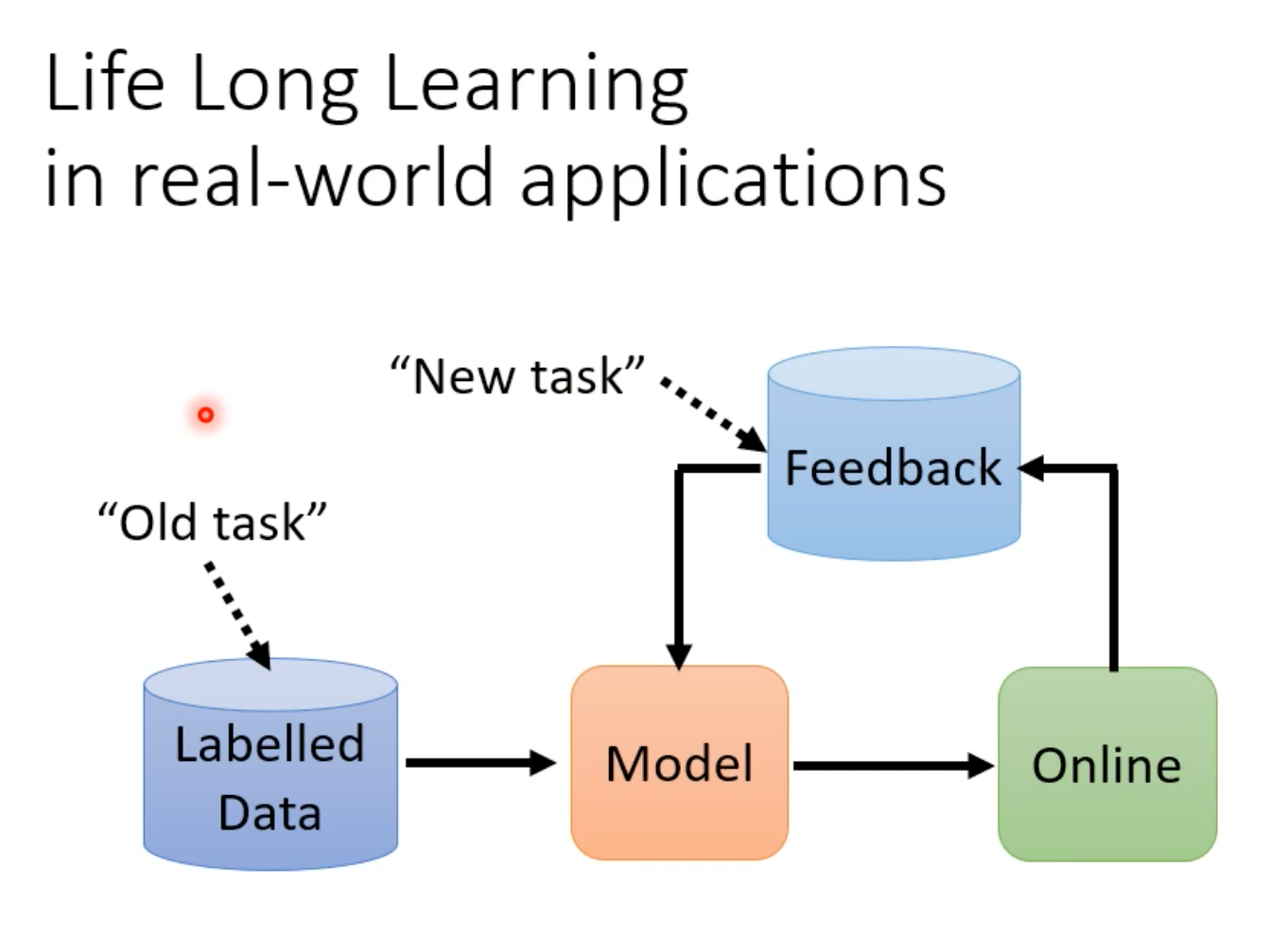
难点: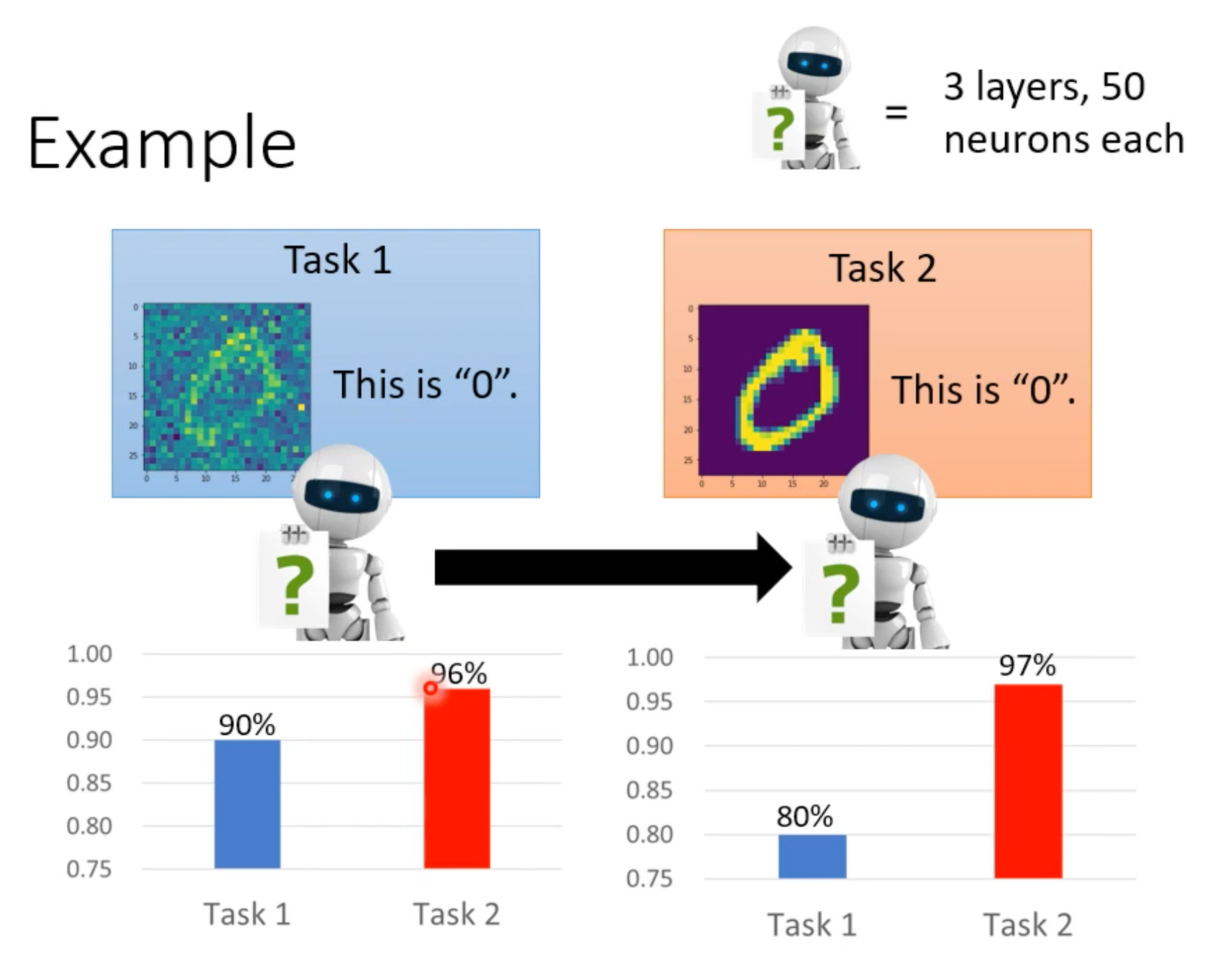
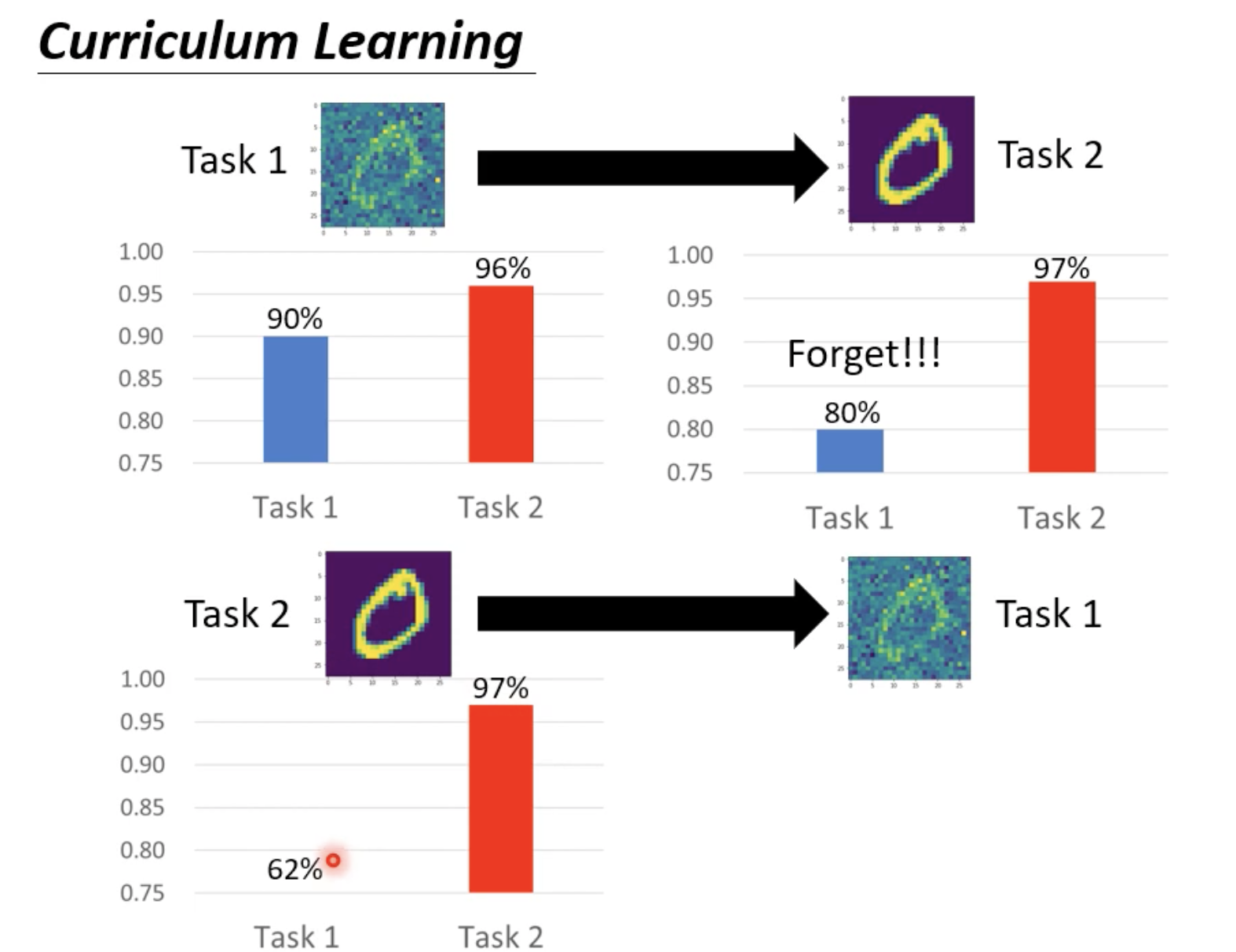
本来学完task1以后即使直接用于task2,其acc也能达到96%,但如果学完后的模型继续用task2的数据去学习,则在task2的测试集上acc固然能提高,但是却会把task1上学习到的知识忘记。
老师又给了一个NLP的例子:

数据集语料较为简单。通常是把20个任务混合在一起,让QA一次去学习,或者20个任务训练20个模型,其各自有不同的技能。
假设按照任务1到20的顺序去学习,在任务5的测试集进行测试,结果如下:
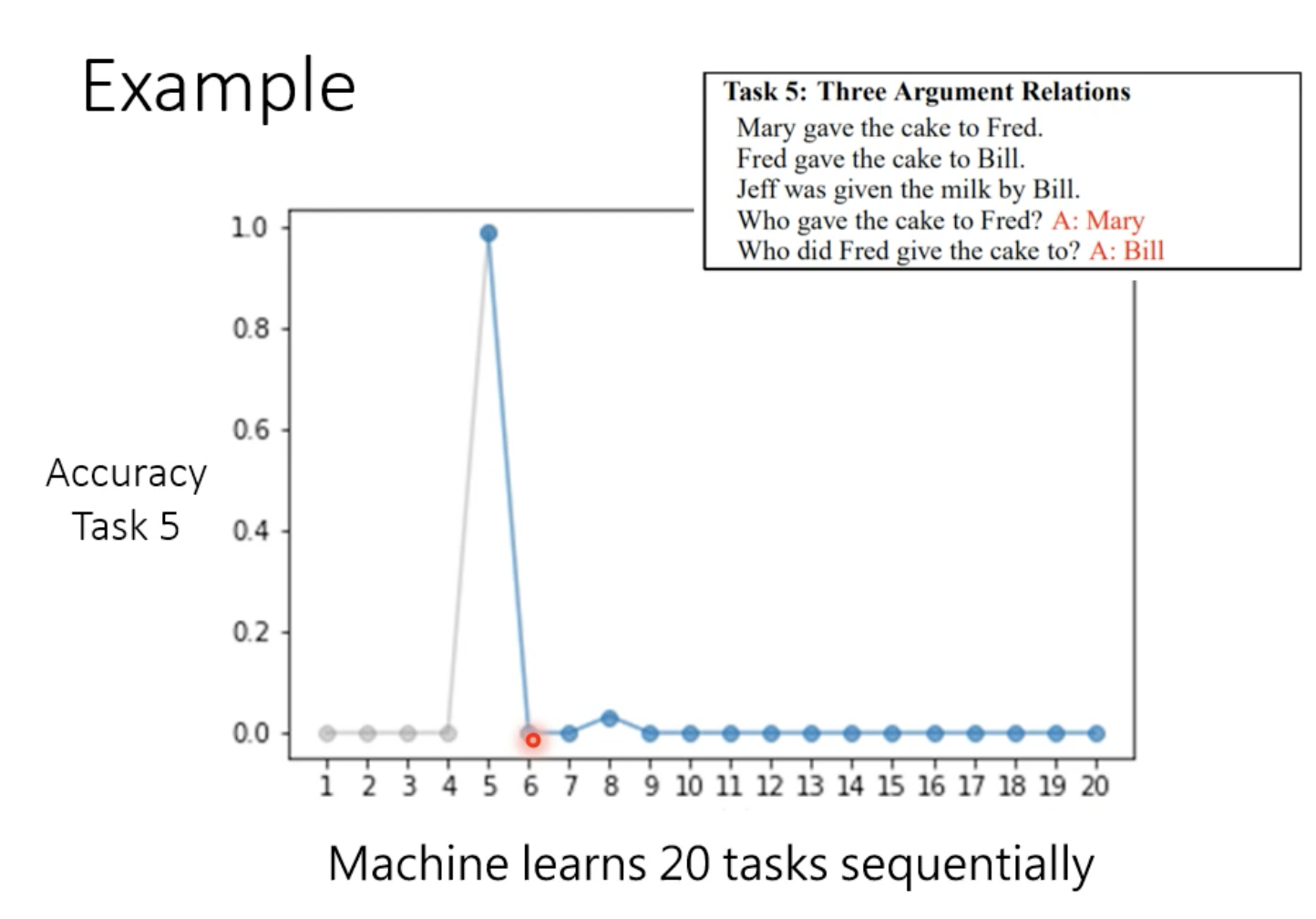
模型只要一学习新的任务,旧的任务就会忘记。但这并不意味着模型无法同时学习多个任务。如果把20个任务的训练数据混合在一起进行训练的话,结果如下:
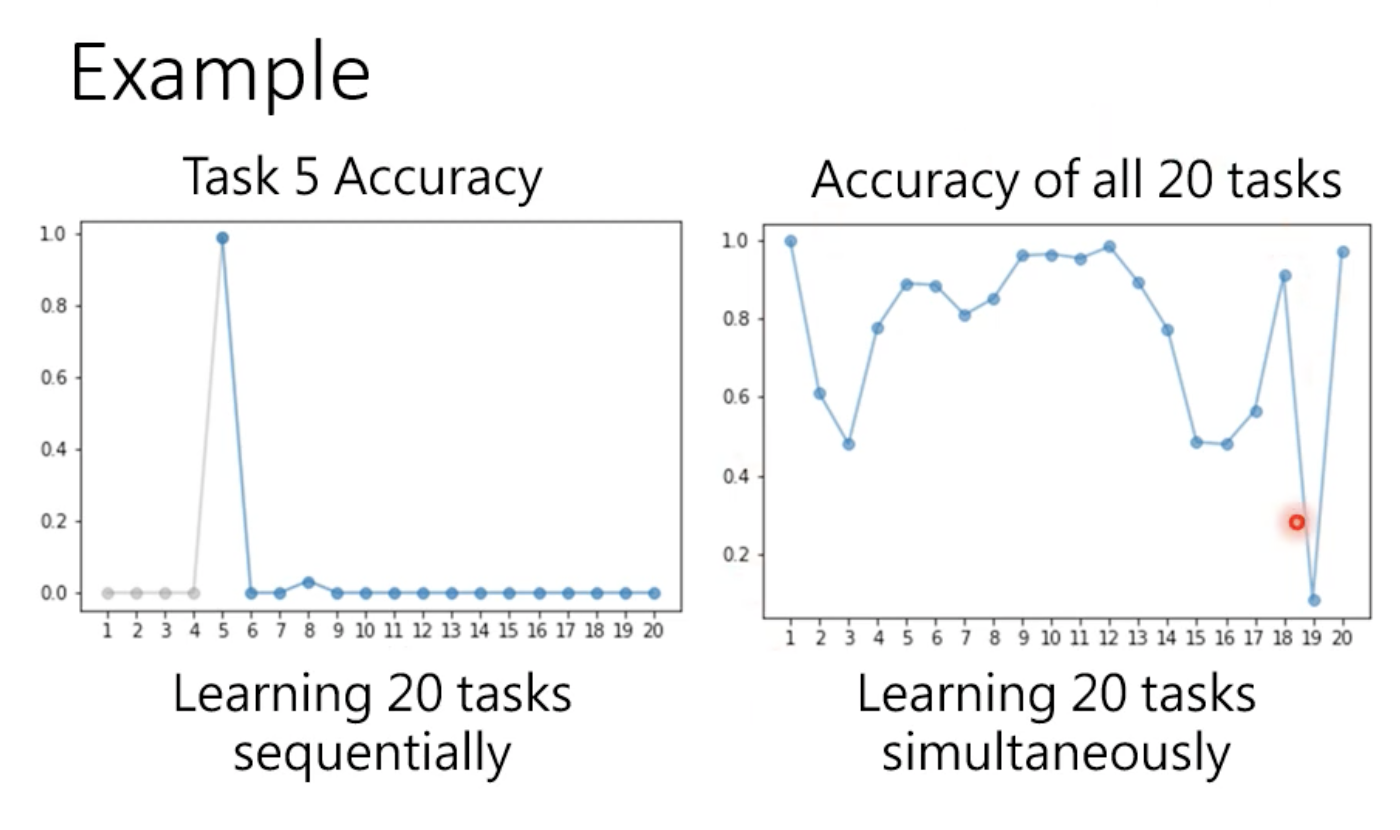
这个现象叫做catastrophic forgetting(灾难性遗忘),因为这种遗忘不是一般的遗忘, 而是学到新知识后几乎会将旧知识全部忘记。
对于同时学习多个任务的方式,叫做multi-task training。即机器在学习第n个任务的时候需要对前面n - 1个任务的资料也进行学习,很可能没有这么大的空间对这些资料进行存储,训练时间可能大幅增加。因此,多任务学习不是解决终身学习的一个好的方式。
终身学习与迁移学习相比,更关注的是旧的任务上效果怎么样(当然新的任务也会关注),迁移学习只关注新任务效果怎么样。

评估:
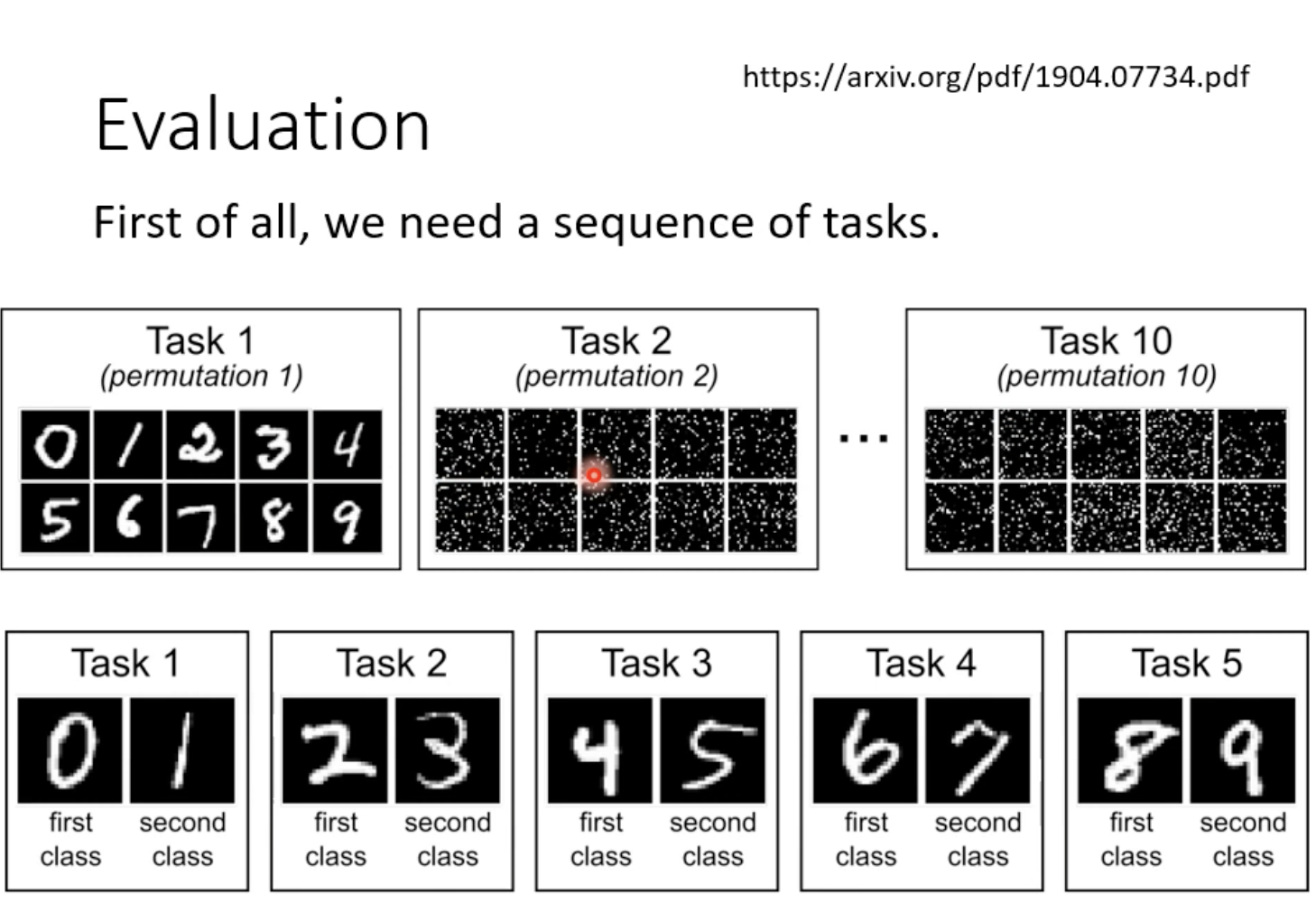
Rij指训练完第i个任务后在第j个任务测试集上的准确率。
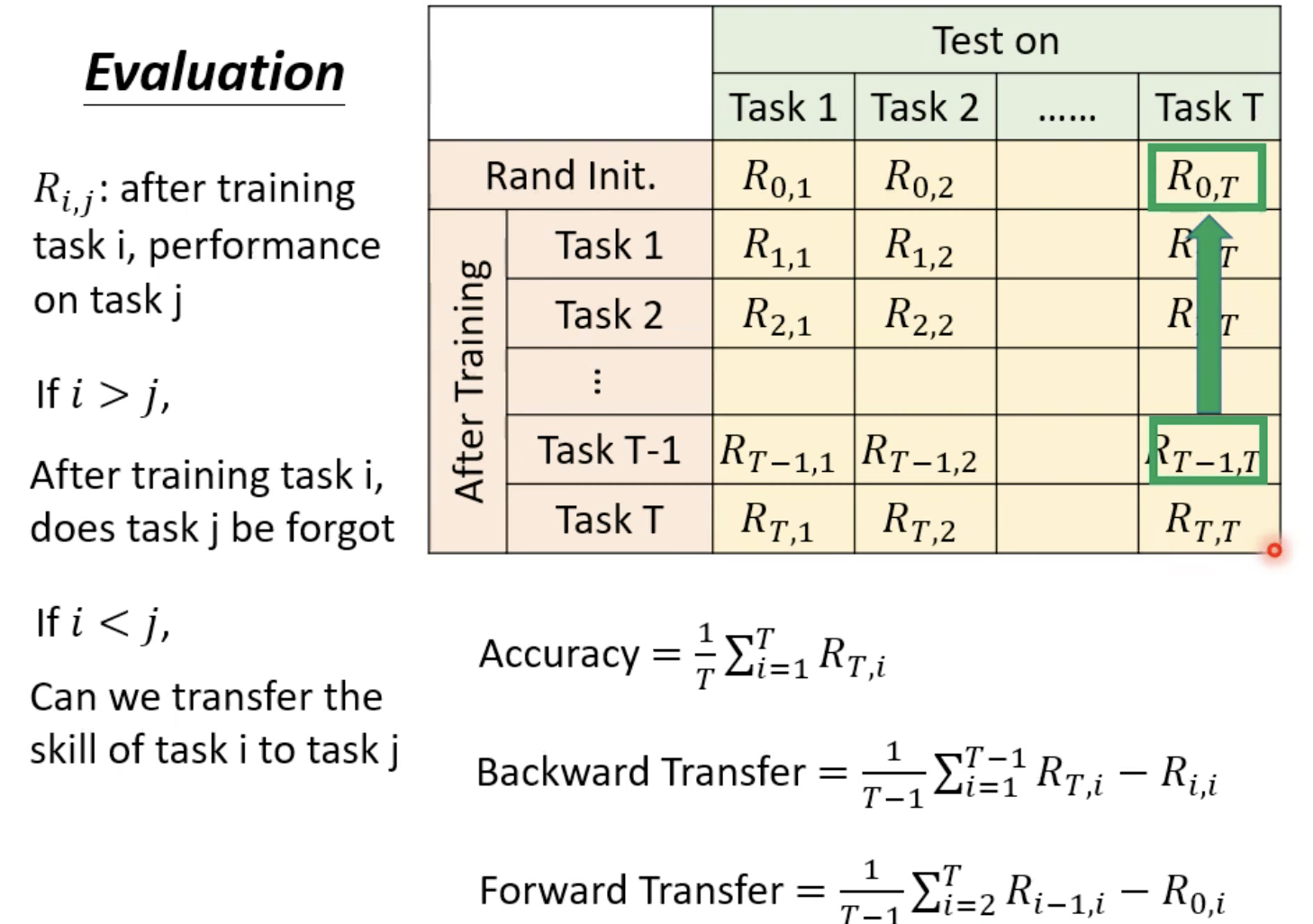
注意Backward Transfer通常是负的,可以衡量学习到新的任务后对于原来任务的遗忘程度。
Forward Transfer可以衡量学习其他任务后对于新任务“无师自通”的能力。
问题解法
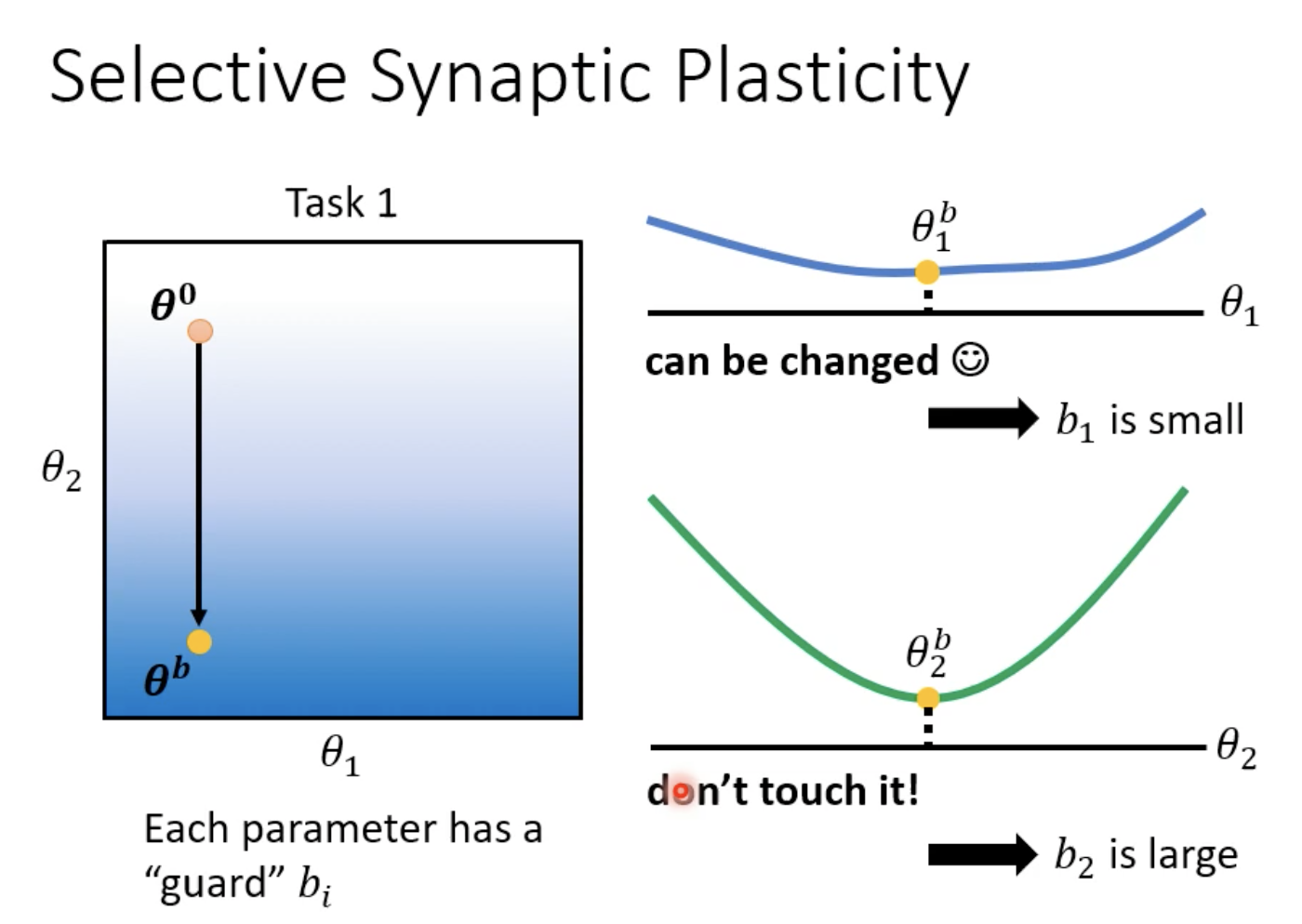
1. Selective Synaptic Plasticity(选择突触可塑性)
让某一些神经元/某一些神经元之间的连接具有可塑性,是一种基于正则化的方法。
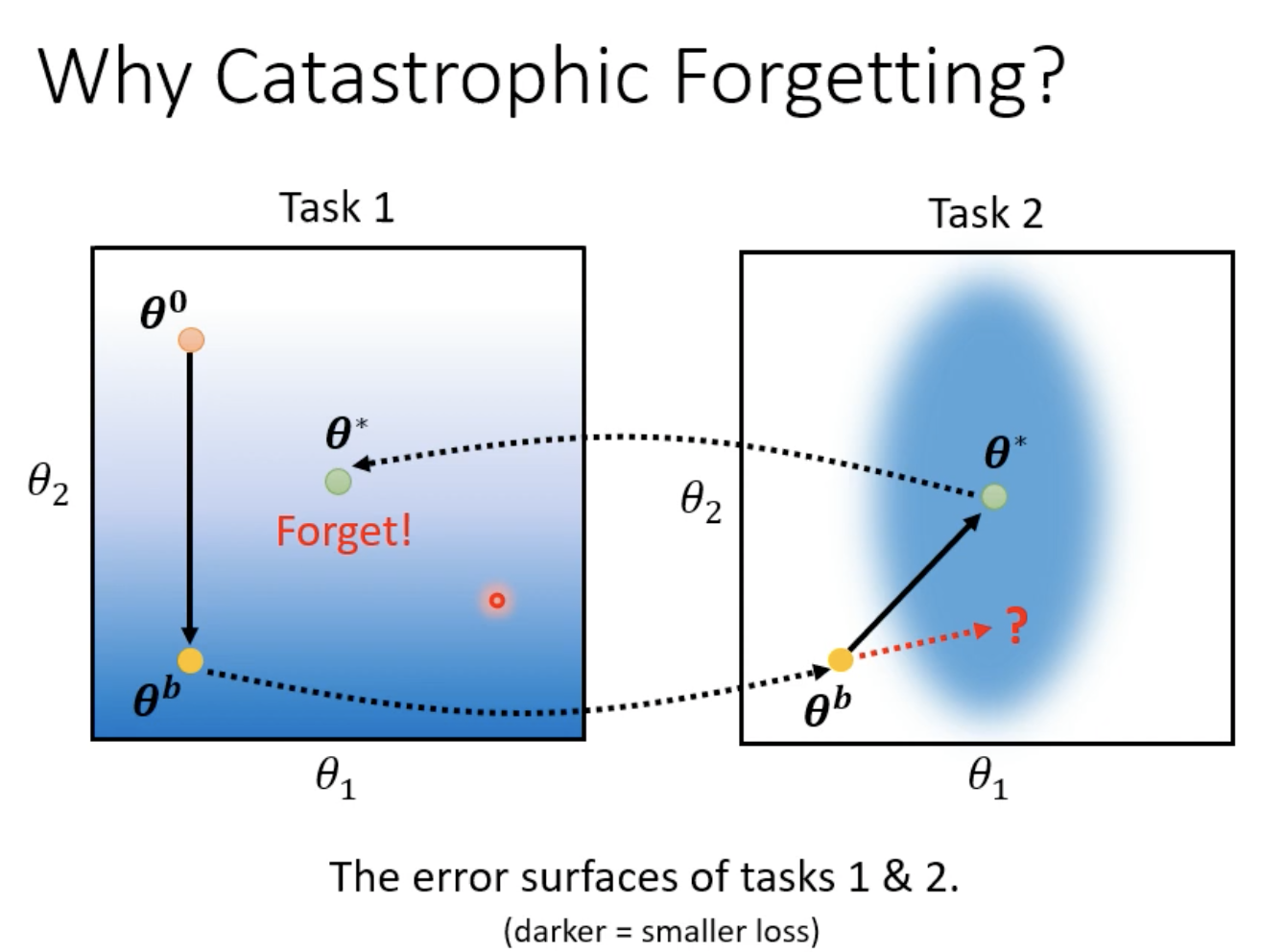
一种可能的思想是,希望在学习新任务的时候,不要去改变模型比较重要的参数,只改变不那么重要的参数。
bi代表这个参数对于过去的任务而言是否重要,是人为设定的超参数(如果是可学习的话会学成0:minimize loss)。

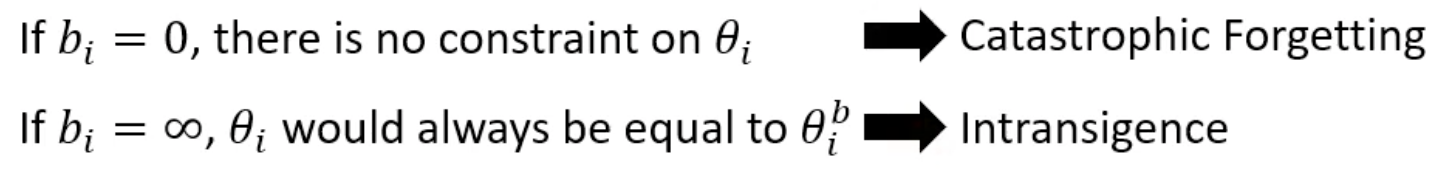
如果所有的bi都设置为非常大的值,则新的参数和旧的参数会非常接近,在旧任务上固然不会遗忘,但新任务也很有可能学的不好。
那么如何判断一个参数对于旧任务是否重要呢?把在方向上做移动,发现对于Loss影响不大,那么这个参数就不那么重要。
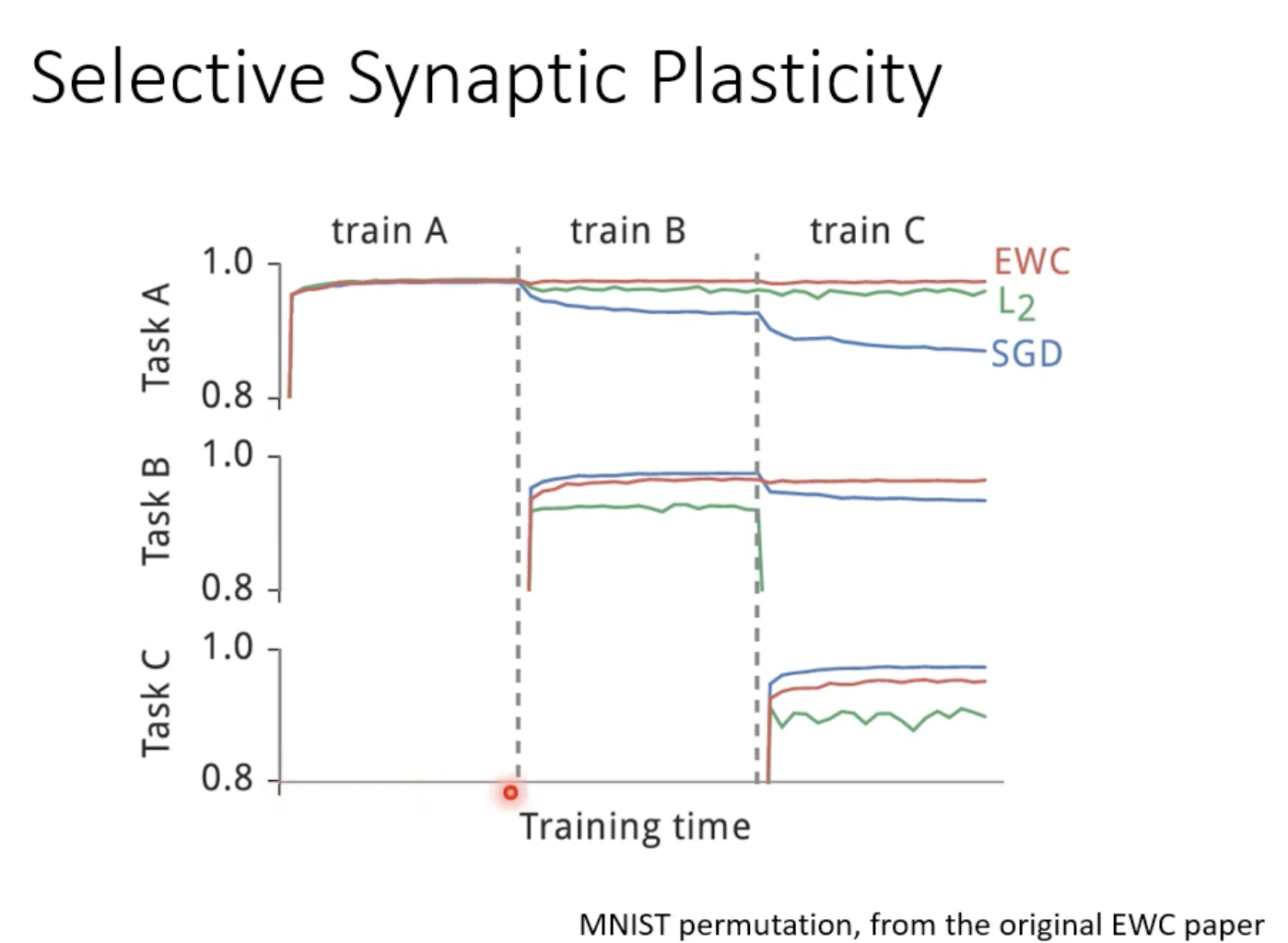
改变训练的任务的顺序对于结果有无影响?有!做实验时作者会穷举任务的顺序。
Gradient Episodic Memory(GEM)
GEM是一种早年的做法,其不是对参数加以限制,而是在梯度的方向上做限制。
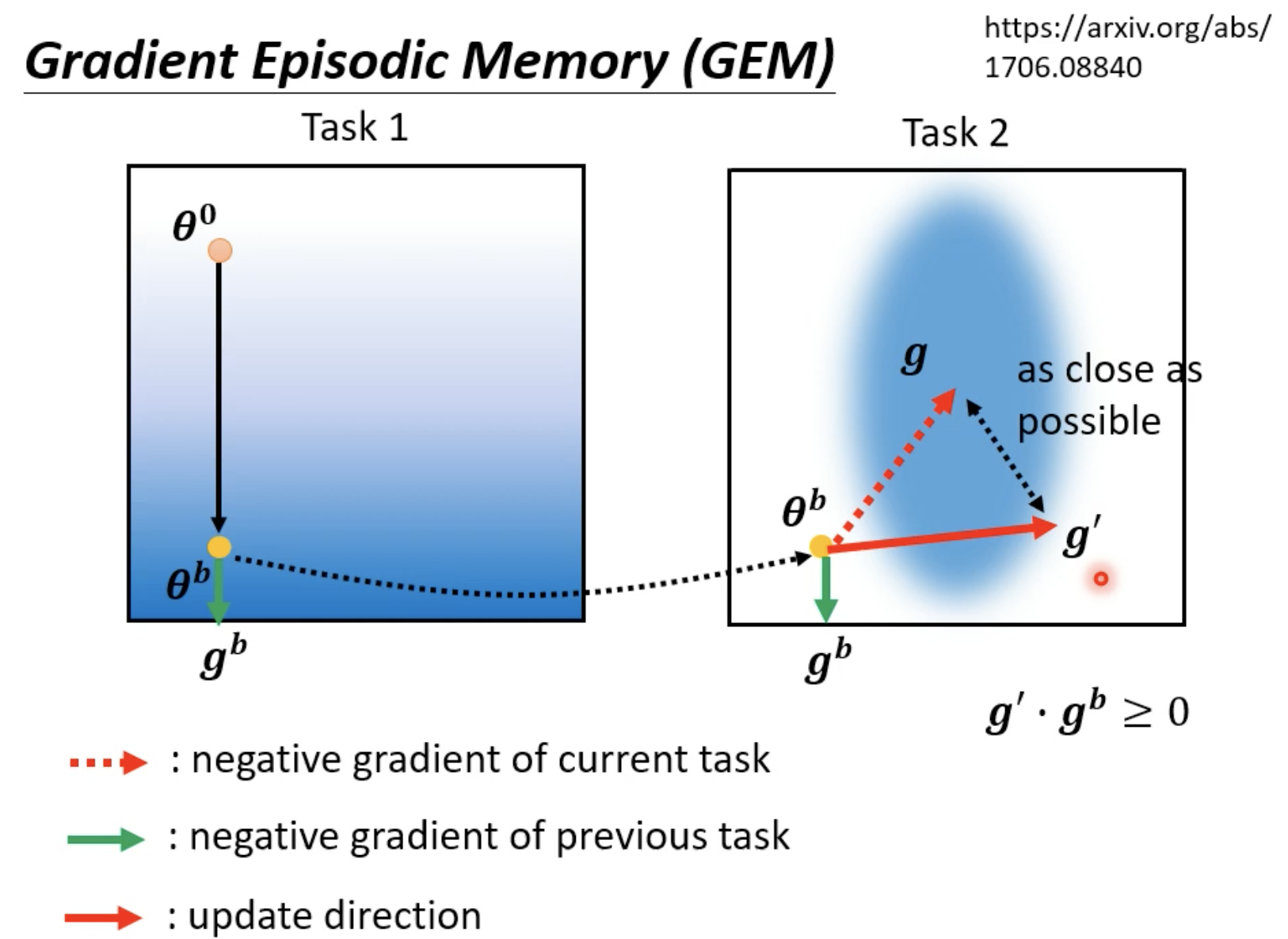
但这样就有一个劣势,就是需要所有任务的资料(用以确定梯度的方向)。但实际上gb仅仅是去修改g的方向,确定gb仅需要存储一点资料。
2. Additional Neural Resource Allocation
改变一下使用在每个任务里的Neural的resource。
每次训练新的任务时,之前任务的参数就不要去修改了,而是增下一部分新的参数。但这样每次训练需要额外的空间去产生新的Neural,
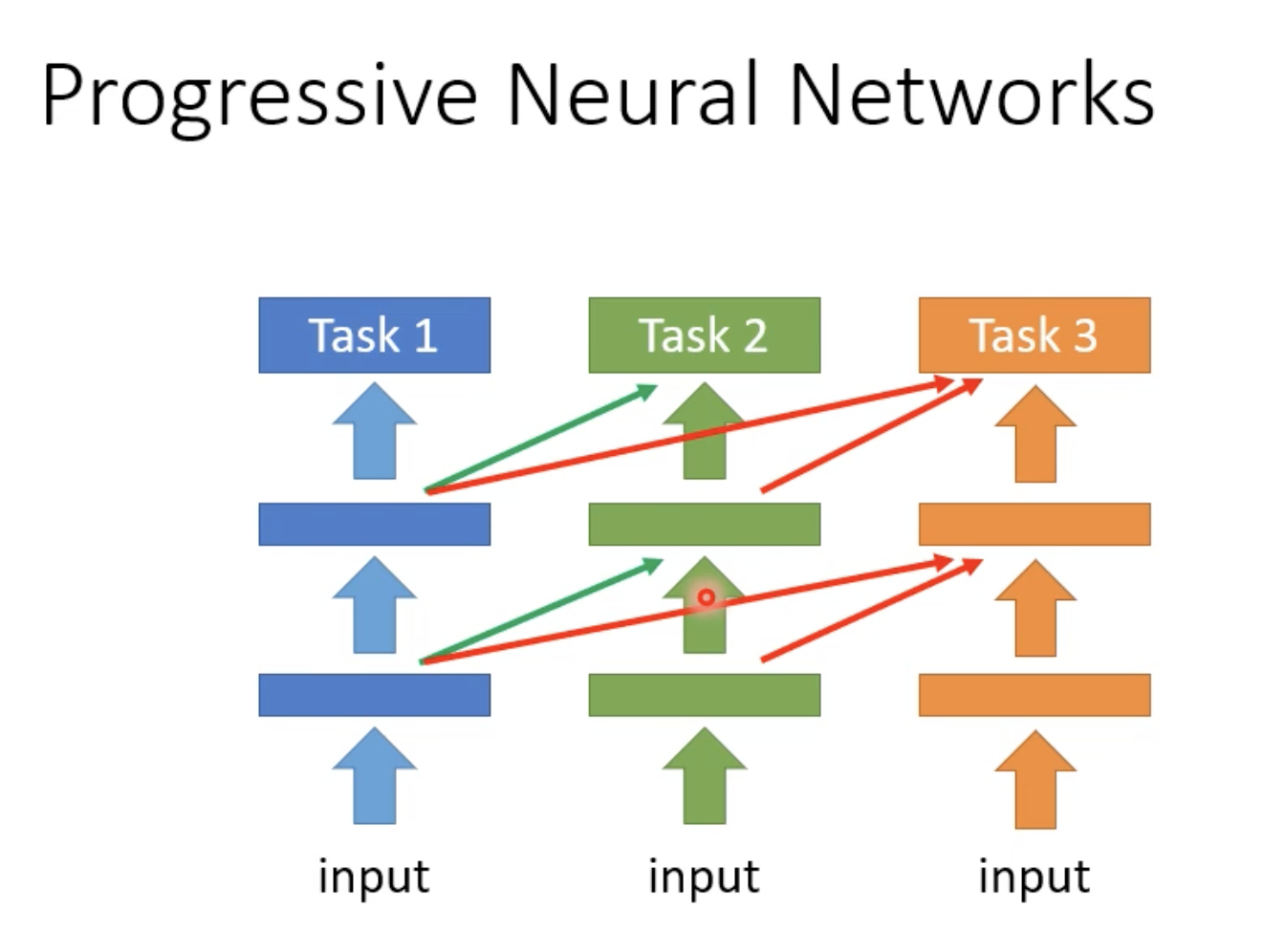
一个相反的思想是PackNet。每次先开一个比较大的模型,每次用其中一部分参数去训练当前任务。
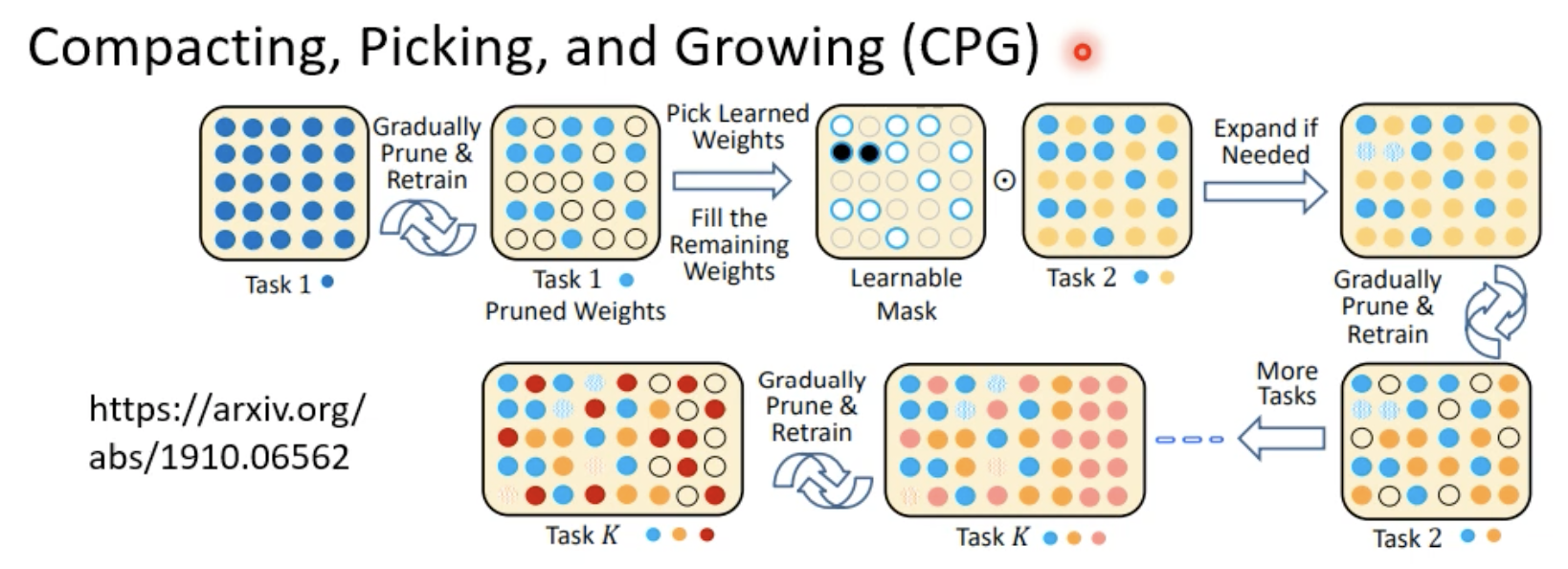
CPG将前面两种方法结合了起来:
3. Memory Reply
用Generator产生之前任务的资料,拿过来参与新任务的训练。如果存储Generator的空间比直接存储旧的信息所需要的空间小,那么这个方法就是合适的。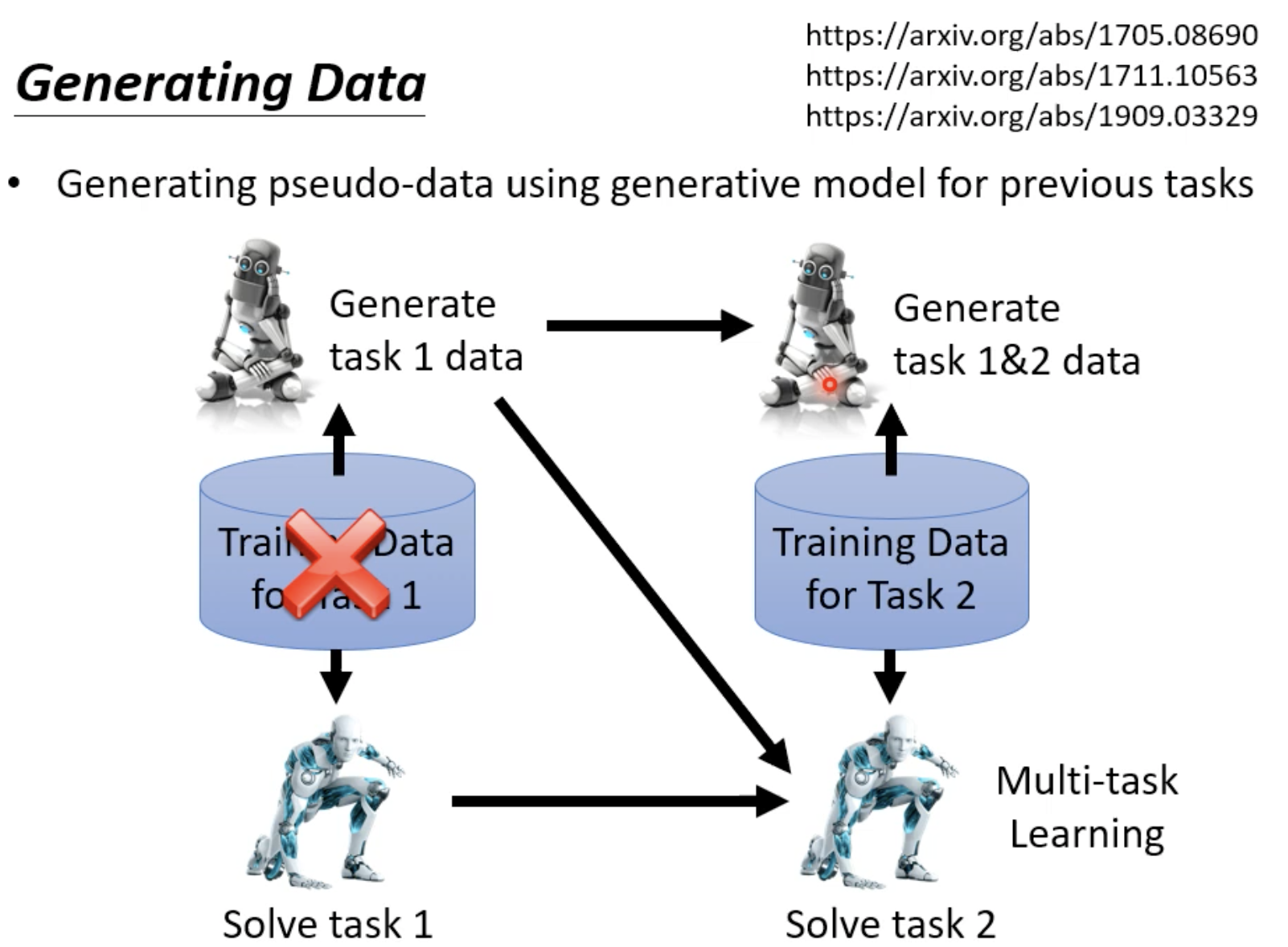
如果任务的class数目不一样的话应该怎么解决?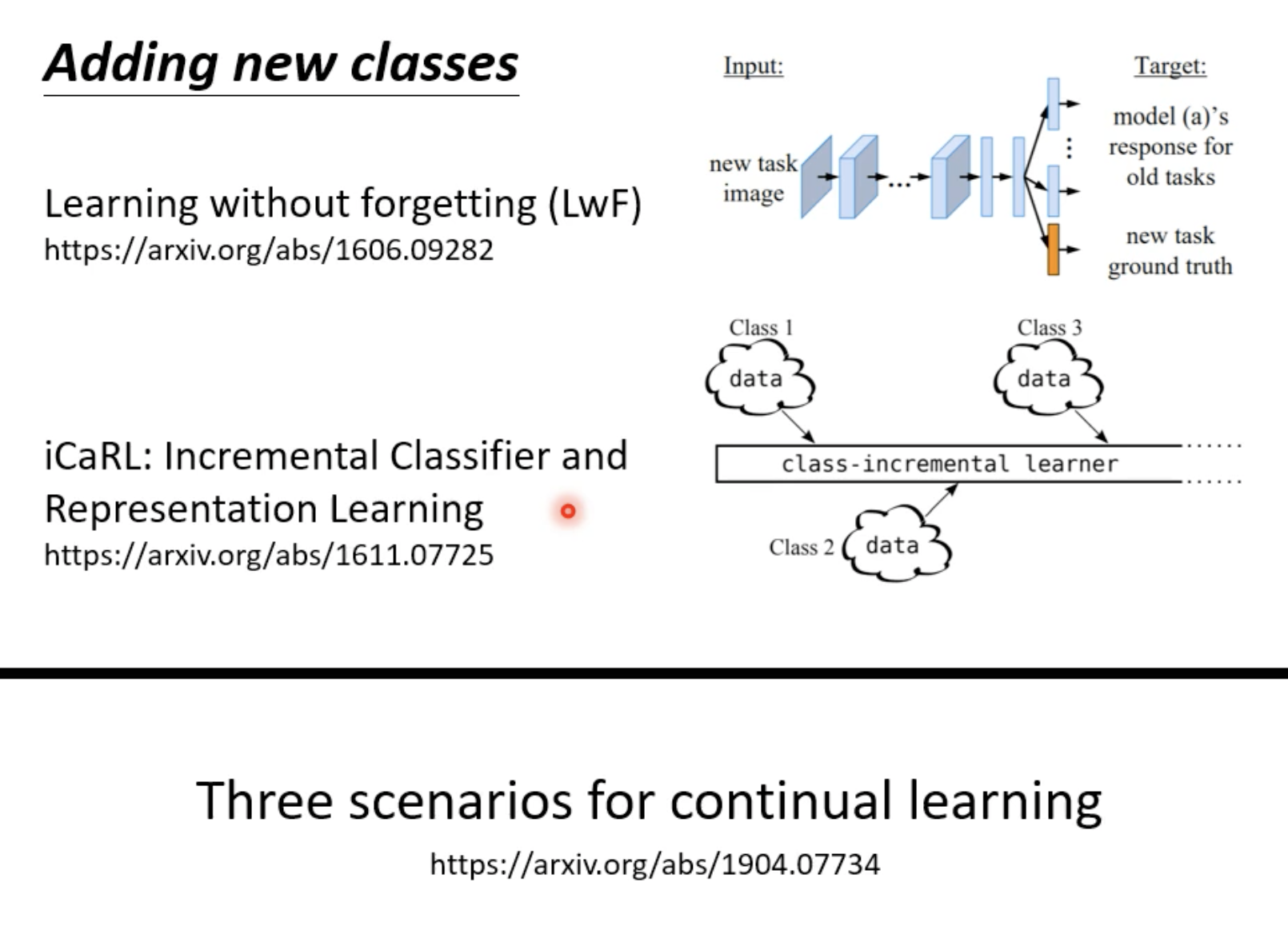
4. Curriculum Learning
研究什么样的学习顺序是有效的
question
如果不同任务的训练数据不平衡,应该如何处理?



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!