使用VGG模型做Fine Tune进行猫狗大战
第四次软工作业:使用VGG模型进行猫狗大战
学术界当下使用最广泛的大规模图像数据集为ImageNet,它有超过1,000万的图像和1,000类的物体。但是通常而言我们使用的数据集的规模会小于ImageNet的规模。如果用较小的数据集来训练适用于ImageNet的复杂模型很可能会导致过拟合。解决的方法主要有两种,一种是扩大使用的数据集的规模,但是这无疑会增大开销;另一种方式就是应用迁移学习,将从源数据集学到的知识迁移到目标数据集。源数据集的图像虽然可能与我们的目标数据集不甚类似,但在ImageNet这种较大规模的数据集上训练出来的模型可能会提取到更常规的图像特征,这有助于识别边缘、纹理、形状等,很有可能也能用于目标数据集。以下将使用预训练好的模型来完成猫狗大战的竞赛题目。
代码
1. 上传数据
首先将colab挂载到谷歌云盘。
from google.colab import drive
drive.mount('/content/gdrive')

进入上传了数据集的目录。
!cd gdrive
!cd MyDrive
!cd Colab Notebooks
!cd CatDogData/

对数据集进行解压。
!unzip ./dogscats/test.zip
2. 数据处理
导入常见的包并判断是否使用了GPU。
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
导入数据集。这里不能直接加数据增强, 因为验证集和测试集用的也是这个transform。如果要加的话需要给训练集和测试集分别创建transform。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(30), # 随机旋转
transforms.ToTensor(),
normalize,
])
data_dir = './dogscats'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'valid', 'test']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid', 'test']}
dset_classes = dsets['train'].classes
创建Dataloader。
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=5, shuffle=False, num_workers=6)
loader_test = torch.utils.data.DataLoader(dsets['test'], batch_size=5, shuffle=False, num_workers=6)
'''
valid 数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出到 400
同时,把第一个 batch 保存到 inputs_try, labels_try,分别查看
'''
count = 1
for data in loader_valid:
print(count, end='\n')
if count == 1:
inputs_try,labels_try = data
count +=1
# 显示图片的小程序
def imshow(inp, title=None):
# Imshow for Tensor.
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = np.clip(std * inp + mean, 0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# 显示 labels_try 的5张图片,即valid里第一个batch的5张图片
out = torchvision.utils.make_grid(inputs_try)
imshow(out, title=[dset_classes[x] for x in labels_try])
3. 创建模型
下载ImageNet1000个类的json文件。
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
使用预训练好的 VGG 模型。这里使用的是VGG16。之后对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。
model_vgg = models.vgg16(pretrained=True)with open('./imagenet_class_index.json') as f: class_dict = json.load(f)dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]inputs_try , labels_try = inputs_try.to(device), labels_try.to(device)model_vgg = model_vgg.to(device)outputs_try = model_vgg(inputs_try)print(outputs_try)print(outputs_try.shape)'''可以看到结果为5行,1000列的数据,每一列代表对每一种目标识别的结果。但是我也可以观察到,结果非常奇葩,有负数,有正数,为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数'''m_softm = nn.Softmax(dim=1)probs = m_softm(outputs_try)vals_try,pred_try = torch.max(probs,dim=1)print( 'prob sum: ', torch.sum(probs,1))print( 'vals_try: ', vals_try)print( 'pred_try: ', pred_try)print([dic_imagenet[i] for i in pred_try.data])imshow(torchvision.utils.make_grid(inputs_try.data.cpu()), title=[dset_classes[x] for x in labels_try.data.cpu()])

4. 修改最后一层,冻结前面层的参数
VGG 模型如下图所示
目标是使用预训练好的模型,但训练的模型最后的全连接层输出为1000类(因为是在ImageNet数据集上训练的),因此,需要把最后的 nn.Linear 层由1000类,替换为2类才能符合猫狗二分类的要求。在训练中需要冻结前面层的参数,因为这些参数是已经训练好的,不需要在这个数据集上继续训练了,所以需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
print(model_vgg)model_vgg_new = model_vgg;for param in model_vgg_new.parameters(): param.requires_grad = Falsemodel_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)model_vgg_new = model_vgg_new.to(device)print(model_vgg_new.classifier)
因为使用的NLLoss和CrossEntropyLoss不同,不会自己实现softmax,所以需要在模型最后手动加上LogSoftmax。
5. 训练并测试全连接层
'''第一步:创建损失函数和优化器损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签. 它不会为我们计算对数概率,适合最后一层是log_softmax()的网络. '''criterion = nn.NLLLoss()# 学习率lr = 0.001# 随机梯度下降optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)'''第二步:训练模型'''def train_model(model,dataloader,size,epochs=1,optimizer=None): model.train() for epoch in range(epochs): running_loss = 0.0 running_corrects = 0 count = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) optimizer = optimizer optimizer.zero_grad() loss.backward() optimizer.step() _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) count += len(inputs) print('Training: No. ', count, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format( epoch_loss, epoch_acc)) # 模型训练train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1, optimizer=optimizer_vgg)
def test_model(model,dataloader,size): model.eval() predictions = np.zeros(size) all_classes = np.zeros(size) all_proba = np.zeros((size,2)) i = 0 running_loss = 0.0 running_corrects = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) predictions[i:i+len(classes)] = preds.to('cpu').numpy() all_classes[i:i+len(classes)] = classes.to('cpu').numpy() all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy() i += len(classes) print('Testing: No. ', i, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format( epoch_loss, epoch_acc)) return predictions, all_proba, all_classes predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])
6. 对测试集进行预测,得到结果
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_test,size=dset_sizes['test'])
结果写入CSV文件。
import csvwith open('./dogscats/cats_vs_dogs.csv','w',newline="")as f: writer = csv.writer(f) for index,cls in enumerate(predictions): path = datasets.ImageFolder(os.path.join(data_dir,'test'),vgg_format).imgs[index][0] l = path.split("/") img_name = l[-1] order = int(img_name.split(".")[0]) writer.writerow([order,int(predictions[index])])
7. 上传提交结果
下载得到的CSV文件的第一列标号顺序和要求的不一样(因为是按批预测的),需要全选后右键排序,选择自定义排序后按列A排序。
就可以在平台提交结果啦:

总结
1. 关于VGG模型
长度为4096的向量能够很好地抓住图片的语义信息。如果两个图片的4096向量十分相似的话那么很可能是同一个/同一类物体。VGG最后使用了三个4096全连接层能够得到较好的效果。但是由4096维到输出为2的维度是否跨度有点大?可否再加一个过渡的全连接层?为此我以下文中提到的VGG19优化方案为基础进行了尝试:
首先在网络中添加如下层,取大小为1024的全连接层过渡。
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 1024) model_vgg_new.classifier._modules['7'] = nn.Linear(1024, 2) model_vgg_new.classifier._modules['8'] = torch.nn.LogSoftmax(dim = 1)
然后修改optimizer,可以用如下语法实现传递最后添加的这两个全连接层的参数:
optimizer_vgg = torch.optim.Adam([{'params': model_vgg_new.classifier[6].parameters()}, {'params': model_vgg_new.classifier[7].parameters()}],lr = lr)
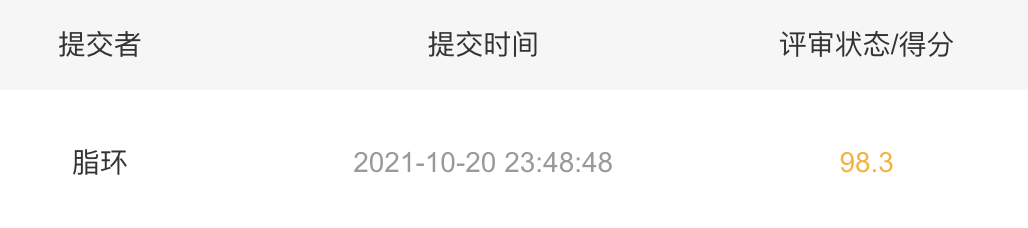
之后训练即可。提交后的分数为:

相比较之前的98.3分来说有所下降,进而验证了4096全连接层的优势。
2. 关于损失函数
这个实验中的损失函数为NLLoss。
官方文档中介绍称: nn.NLLLoss输入是一个对数概率向量和一个目标标签,它与nn.CrossEntropyLoss的关系可以描述为:softmax(x)+log(x)+nn.NLLLoss====>nn.CrossEntropyLoss。
那么问题来了,代码里为什么要在模型里加入Logsoftmax而不是直接使用CrossEntropyLoss呢?
3. 尝试的改进
VGG16替换为VGG19:
model_vgg = models.vgg19(pretrained=True)model_vgg_new = model_vgg;for param in model_vgg_new.parameters(): param.requires_grad = False # 冻结前面层的参数model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2) # 1000类替换为2类(4096为全连接层维度)model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)model_vgg_new = model_vgg_new.to(device)
优化器设置为Adam,修改学习率为3e-4:
(一个总结中提到Adam最优学习率为3e-4)
lr = 0.0003optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!