hadoop面试题总结
1、hadoop常用端口号
|
hadoop2.x
|
Hadoop3.x
|
|
|
访问HDFS端口
|
50070
|
9870
|
|
访问MR执行情况端口
|
8088
|
8088
|
|
历史服务器
|
19888
|
19888
|
|
客户端访问集群端口
|
9000
|
8020
|
2、hadoop集群搭建
hadoop搭建流程概述:
(1)准备三个客户端,master,node1,node2
(2)安装jdk 配置免密 ssh-keygen -t rsa 分发秘钥 ssh-copy-id master ssh-copy-id node1 ssh-copy-id node2
(3)配置环境变量 source 一下
(4)主要有 hadoop环境配置文件:hadoop-env.sh hadoop核心配置文件 core-site.xml yarn配置文件 yarn-site.xml mapreduce核心配置文件 mapred-site.xml hdfs配置文件 hdfs-site.xml
(5)分发集群文件 scp -r /usr/local....... 格式化 hdfs namenode-format 启动集群 start-all.sh 访问hdfs页面查看是否搭建成功
3、环境配置文件主要内容
(1)hadoop-env.sh : Hadoop 环境配置文件 vim hadoop-env.sh 修改JAVA_HOME export JAVA_HOME=/usr/local/soft/jdk1.8.0_171 (2)core-site.xml : hadoop核心配置文件 vim core-site.xml 在configuration中间增加以下内容 <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> (3)hdfs-site.xml : hdfs配置文件 vim hdfs-site.xml 在configuration中间增加以下内容 <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> (4)yarn-site.xml: yarn配置文件 vim yarn-site.xml 在configuration中间增加以下内容 <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>20480</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> (5)mapred-site.xml: mapreduce配置文件 重命名 mv mapred-site.xml.template mapred-site.xml vim mapred-site.xml 在configuration中间增加以下内容 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property>
3、hdfs读写流程
写流程:
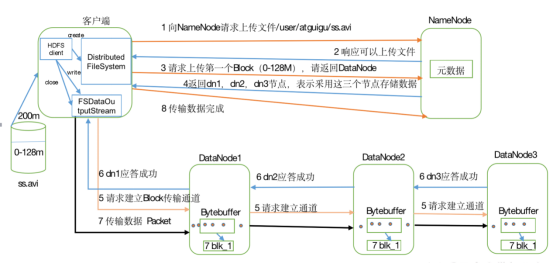
1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
理解过程:
![摘自尚硅谷]()
客户端先向namenode请求上传数据,namenode检查文件是否存在,父目录是否存在,namenode返回是否可以上传。
客户端请求block1上传到哪几个datanode上,客户端返回可以上传的节点
客户端请求dn1上传数据.....建立通信管道
节点逐级应答客户端
客户端开始上传数据 ,block1上传完后,然后接着按上述步骤上传block2
读流程:
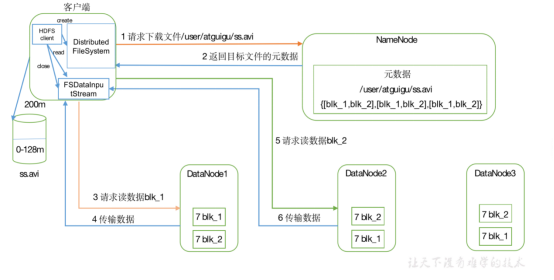
1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
4、HDFS小文件处理
1)会有什么影响
(1)1个文件块,占用namenode多大内存150字节
1亿个小文件*150字节
1 个文件块 * 150字节
128G能存储多少文件块? 128 * 1024*1024*1024byte/150字节 = 9亿文件块
2)怎么解决
(1)采用har归档方式,将小文件归档
(2)采用CombineTextInputFormat
(3)有小文件场景开启JVM重用;如果没有小文件,不要开启JVM重用,因为会一直占用使用到的task卡槽,直到任务完成才释放。
JVM重用可以使得JVM实例在同一个job中重新使用N次,N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间
5、Shuffle过程及优化
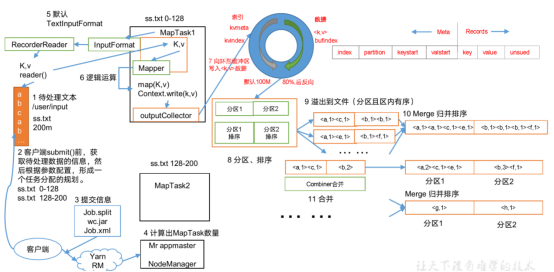

过程:
1.待处理文件 (200M)
2.在submit里面对原始数据进行切片
3.客户端准备三样东西(job.split wc.jar job.xml )像YARN提交
4.YARN会开启Mrappmaster(整个任务运行的老大):读取切片信息,会根据切片个数对应开启map task个数
5.TextInputformat 开始读数据
6.读完数据给Mapper(K.是偏移量 ,v是一行内容)
7.进入OutputCollect(输出收集器):环形缓冲区:就是一块内存 右侧存数据,左侧存索引 环形缓冲区默认大小100M 数据到达80%开始反向溢写
8.分区排序(刚进来的数据要进行分区排序,分区1 进入reduce1 分区2 进入reduce2 )进行溢写前对分区内部数据进行排序(快排)
9.溢写到文件(分区切区内有序)
10.Merge归并排序(对有序的文件进行排序)存储在磁盘上
11.合并
........
Shuffle 过程(Mapper方法之后,reduce方法之前,数据处理过程称为Shuffle)
map方法出来之后 ,先标记数据是哪个分区,然后进入环形缓冲区(默认100M)左侧存索引,右侧存数据。到达80%之后进行反向溢写(到达80%就进行溢写,留出时间不至于等待,可以让环形缓冲区一直高效运转 )在溢写之前要对数据进行排序 (按照字典顺序对k的索引进行快排)排序之后进行溢写,溢写会产生两个文件(spill.index Spill.out ),然后对数据进行归并排序。Combiner为可选流程,然后进行压缩 ,之后卸载磁盘上,然后等待reduce来拉取指定分区的数据 。
调优
1)Map阶段
(1)增大环形缓冲区大小。由100m扩大到200m
(2)增大环形缓冲区溢写的比例。由80%扩大到90%
(3)减少对溢写文件的merge次数。(10个文件,一次20个merge)
(4)不影响实际业务的前提下,采用Combiner提前合并,减少 I/O。
2)Reduce阶段
(1)合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
(2)设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
(3)规避使用Reduce,因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
(4)增加每个Reduce去Map中拿数据的并行数
(5)集群性能可以的前提下,增大Reduce端存储数据内存的大小。
3)IO传输
采用数据压缩的方式,减少网络IO的的时间。安装Snappy和LZOP压缩编码器。
压缩:
(1)map输入端主要考虑数据量大小和切片,支持切片的有Bzip2、LZO。注意:LZO要想支持切片必须创建索引;
(2)map输出端主要考虑速度,速度快的snappy、LZO;
(3)reduce输出端主要看具体需求,例如作为下一个mr输入需要考虑切片,永久保存考虑压缩率比较大的gzip。
4)整体
(1)NodeManager默认内存8G,需要根据服务器实际配置灵活调整,例如128G内存,配置为100G内存左右,yarn.nodemanager.resource.memory-mb。
(2)单任务默认内存8G,需要根据该任务的数据量灵活调整,例如128m数据,配置1G内存,yarn.scheduler.maximum-allocation-mb。
(3)mapreduce.map.memory.mb :控制分配给MapTask内存上限,如果超过会kill掉进程(报:Container is running beyond physical memory limits. Current usage:565MB of512MB physical memory used;Killing Container)。默认内存大小为1G,如果数据量是128m,正常不需要调整内存;如果数据量大于128m,可以增加MapTask内存,最大可以增加到4-5g。
(4)mapreduce.reduce.memory.mb:控制分配给ReduceTask内存上限。默认内存大小为1G,如果数据量是128m,正常不需要调整内存;如果数据量大于128m,可以增加ReduceTask内存大小为4-5g。
(5)mapreduce.map.java.opts:控制MapTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
(6)mapreduce.reduce.java.opts:控制ReduceTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
(7)可以增加MapTask的CPU核数,增加ReduceTask的CPU核数
(8)增加每个Container的CPU核数和内存大小
(9)在hdfs-site.xml文件中配置多目录
(10)NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为10台时,此参数设置为60。
6、Yarn的工作机制
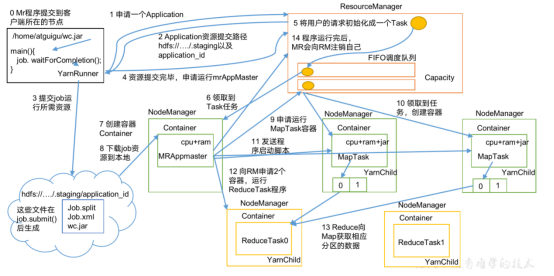
(1)MR 程序提交到客户端所在的节点。
(2)YarnRunner 向 ResourceManager 申请一个 Application。
(3)RM 将该应用程序的资源路径返回给 YarnRunner。
(4)该程序将运行所需资源提交到 HDFS 上。
(5)程序资源提交完毕后,申请运行 mrAppMaster。
(6)RM 将用户的请求初始化成一个 Task。
(7)其中一个 NodeManager 领取到 Task 任务。
(8)该 NodeManager 创建容器 Container,并产生 MRAppmaster。
(9)Container 从 HDFS 上拷贝资源到本地。
(10)MRAppmaster 向 RM 申请运行 MapTask 资源。
(11)RM 将运行 MapTask 任务分配给另外两个 NodeManager,另两个 NodeManager 分别领取任务并创建容器。
(12)MR 向两个接收到任务的 NodeManager 发送程序启动脚本,这两个 NodeManager分别启动 MapTask,MapTask 对数据分区排序。
(13)MrAppMaster 等待所有 MapTask 运行完毕后,向 RM 申请容器,运行 ReduceTask。
(14)ReduceTask 向 MapTask 获取相应分区的数据。
(15)程序运行完毕后,MR 会向 RM 申请注销自己。
7、Yarn调度器
1)Hadoop调度器重要分为三类:
FIFO 、Capacity Scheduler(容量调度器)和Fair Sceduler(公平调度器)。
Apache默认的资源调度器是容量调度器;
CDH默认的资源调度器是公平调度器。
2)区别:
FIFO调度器:支持单队列 、先进先出 生产环境不会用。
容量调度器:支持多队列,保证先进入的任务优先执行。
公平调度器:支持多队列,保证每个任务公平享有队列资源。
3)在生产环境下怎么选择?
大厂:如果对并发度要求比较高,选择公平,要求服务器性能必须OK;
中小公司,集群服务器资源不太充裕选择容量。
4)在生产环境怎么创建队列?
(1)调度器默认就1个default队列,不能满足生产要求。
(2)按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)
(3)按照业务模块:登录注册、购物车、下单、业务部门1、业务部门2
5)创建多队列的好处?
(1)因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。
(2)实现任务的降级使用,特殊时期保证重要的任务队列资源充足。
业务部门1(重要)=》业务部门2(比较重要)=》下单(一般)
8、Hadoop宕机
1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
2)如果写入文件过快造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。例如,可以调整Flume每批次拉取数据量的大小参数batchsize。
9、Hadoop解决数据倾斜方法
1)提前在map进行combine,减少传输的数据量
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。
如果导致数据倾斜的key大量分布在不同的mapper的时候,这种方法就不是很有效了。
2)导致数据倾斜的key 大量分布在不同的mapper
(1)局部聚合加全局聚合。
第一次在map阶段对那些导致了数据倾斜的key 加上1到n的随机前缀,这样本来相同的key 也会被分到多个Reducer中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉key的随机前缀,进行全局聚合。
思想:二次mr,第一次将key随机散列到不同reducer进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原key进行reduce处理。
这个方法进行两次mapreduce,性能稍差。
(2)增加Reducer,提升并行度JobConf.setNumReduceTasks(int)
(3)实现自定义分区
根据数据分布情况,自定义散列函数,将key均匀分配到不同Reducer
10、集群资源分配参数
集群有30台机器,跑mr任务的时候发现5个map任务全都分配到了同一台机器上,这个可能是由于什么原因导致的吗?
解决方案:yarn.scheduler.fair.assignmultiple 这个参数 默认是开的,需要关掉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号