
字符串
一、python中字符串的格式
- 如下定义的变量a,存储的是数字类型的值
a = 100
- 如下定义的变量b,存储的是字符串类型的值
b = "hello itcast.cn"
或者
b = 'hello itcast.cn'
- 小总结:双引号或者单引号中的数据,就是字符串
二、字符串输出
demo
name = 'xiaoming'
position = '讲师'
address = '北京市昌平区建材城西路金燕龙办公楼1层'
print('--------------------------------------------------')
print("姓名:%s"%name)
print("职位:%s"%position)
print("公司地址:%s"%address)
print('--------------------------------------------------')
结果
姓名: xiaoming
职位: 讲师
公司地址: 北京市昌平区建材城西路金燕龙办公楼1层
三、字符串的输入
之前在学习input的时候,通过它能够完成从键盘获取数据,然后保存到指定的变量中;
注意:input获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存
demo
userName = input('请输入用户名:')
print("用户名为:%s"%userName)
password = input('请输入密码:')
print("密码为:%s"%password)
结果
请输入用户名:dongGe
用户名为: dongGe
请输入密码:haohaoxuexitiantianxiangshang
密码为: haohaoxuexitiantianxiangshang
四、字符串的常见操作
- 数字 int:python 3里,不管数字有多大,都是int类型;python 2里,数字大,long(长整型)
- int
将字符串转换为数字
a = "123"
print(type(a),a)
b = int(a)
print(type(b),b)
num = "0011"
v = int(num, base=16)
print(v)
- bit_lenght
当前数字的二进制,至少用n位表示
r = age.bit_length()
- 字符串 str
(1)首字母大写
test="alex"
v=test.capitalize()
print(v)
(2)所有变小写:lower() 方法只对ASCII编码,也就是‘A-Z’有效,对于其他语言(非汉语或英文)中把大写转换为小写的情况只能用 casefold() 方法
S1 = "Runoob EXAMPLE....WOW!!!" #英文
S2 = "ß" #德语
print( S1.lower() )
print( S1.casefold() )
print( S2.lower() )
print( S2.casefold() ) #德语的"ß"正确的小写是"ss"
(3)设置宽度 ,并将格式居中 center
# 20 代指总长度 #空白未知填充,一个字符,可有可无
test="alex" v = test.center(20,"中") print(v)
结果

(4)去字符串中寻找,寻找子序列的出现次数 count
test = "aLexalexr"
v = test.count('ex')
print(v)
(5)expandtabs() 方法把字符串中的 tab 符号('\t')转为空格,tab 符号('\t')默认的空格数是 8.
test="1234567\t9"
v=test.expandtabs(4)
print(v)

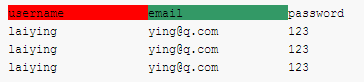
S = "username\temail\tpassword\nlaiying\tying@q.com\t123\nlaiying\tying@q.com\t123\nlaiying\tying@q.com\t123"
v = S.expandtabs(20)
print(v)
输出结果如下:
(6)Python find() 方法从字符串中找出某个子字符串第一个匹配项的索引位置,该方法与 index() 方法一样,只不过如果子字符串不在字符串中不会报异常,而是返回-1。
find() 方法语法:
S.find(sub[,start=0[,end=len(S)]])
参数
- sub -- 指定检索的子字符串
- S -- 父字符串
- start -- 可选参数,开始索引,默认为0。(可单独指定)
- end -- 可选参数,结束索引,默认为字符串的长度。(不能单独指定)
>>>info = 'abca'
>>> print(info.find('a')) # 从下标0开始,查找在字符串里第一个出现的子串,返回结果:0
0
>>> print(info.find('a', 1)) # 从下标1开始,查找在字符串里第一个出现的子串:返回结果3
3
>>> print(info.find('3')) # 查找不到返回-1
-1
>>>
(7)Python index() 方法从字符串中找出某个子字符串第一个匹配项的索引位置,该方法与 find() 方法一样,只不过如果子字符串不在字符串中会报一个异常。
S1 = "Runoob example....wow!!!"
S2 = "exam";
print (S1.index(S2))
print (S1.index(S2, 5))
print (S1.index(S2, 10))
以上实例输出结果如下(未发现的会出现异常信息):
7
7
Traceback (most recent call last):
File "test.py", line 8, in <module>
print (str1.index(str2, 10))
ValueError: substring not found
(8)format()方法:格式化,将一个字符串中的占位符替换为指定的值
test = 'i am {name}, age {a}'
print(test)
v = test.format(name='alex',a=18)
print(v)
其结果为
i am alex,age18
(9)isalnum() 方法检测字符串是否由字母和数字组成
test = "123"
v = test.isalnum()
print(v)
其结果为
True
(10)string.join():Python中有join()和os.path.join()两个函数,具体作用如下:
join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
os.path.join(): 将多个路径组合后返回
- join()函数
语法: 'sep'.join(seq)
参数说明
sep:分隔符。可以为空
seq:要连接的元素序列、字符串、元组、字典
上面的语法即:以sep作为分隔符,将seq所有的元素合并成一个新的字符串返回值:返回一个以分隔符sep连接各个元素后生成的字符串
- os.path.join()函数
语法: os.path.join(path1[,path2[,......]])
返回值:将多个路径组合后返回
注:第一个绝对路径之前的参数将被忽略
#对序列进行操作(分别使用' '与':'作为分隔符)
>>> seq1 = ['hello','good','boy','doiido']
>>> print ' '.join(seq1)
hello good boy doiido
>>> print ':'.join(seq1)
hello:good:boy:doiido
#对字符串进行操作
>>> seq2 = "hello good boy doiido"
>>> print ':'.join(seq2)
h:e:l:l:o: :g:o:o:d: :b:o:y: :d:o:i:i:d:o
#对元组进行操作
>>> seq3 = ('hello','good','boy','doiido')
>>> print ':'.join(seq3)
hello:good:boy:doiido
#对字典进行操作
>>> seq4 = {'hello':1,'good':2,'boy':3,'doiido':4}
>>> print ':'.join(seq4)
boy:good:doiido:hello
#合并目录
>>> import os
>>> os.path.join('/hello/','good/boy/','doiido')
'/hello/good/boy/doiido'
(11)strip(),lstrip(),rstrip()
Python中有三个去除头尾字符、空白符的函数,它们依次为:
strip: 用来去除头尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)
lstrip:用来去除开头字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)
rstrip:用来去除结尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)
注意:这些函数都只会删除头和尾的字符,中间的不会删除。
用法分别为:
string.strip([chars])
string.lstrip([chars])
string.rstrip([chars])
参数chars是可选的,当chars为空,默认删除string头尾的空白符(包括\n、\r、\t、' ')
当chars不为空时,函数会被chars解成一个个的字符,然后将这些字符去掉。
它返回的是去除头尾字符(或空白符)的string副本,string本身不会发生改变。
举例说明如下:
1. 当chars为空时,默认删除空白符(包括'\n', '\r', '\t', ' ')
>>> str = ' abc cdg '
>>> str
' abc cdg '
>>> str.strip() #删除头尾空格
'abc cdg'
>>> str.lstrip() #删除开头空格
'abc cdg '
>>> str.rstrip() #删除结尾空格
' abc cdg'
2.当chars不为空时,函数会被chars解成一个个的字符,然后将这些字符去掉。
>>> str2 = '1a2b12c21'
>>> str2.strip('12') #删除头尾的1和2
'a2b12c'
>>> str2.lstrip('12') #删除开头的1和2
'a2b12c21'
>>> str2.rstrip('12') #删除结尾的1和2
'1a2b12c'

