

缓存学习一 大致了解
1,缓存种类或者类型
1. LocalCache(独立式): 例如Ehcache、BigMemory Go
(1) 缓存和应用在一个JVM中。
(2) 缓存间是不通信的,独立的。
(3) 弱一致性。
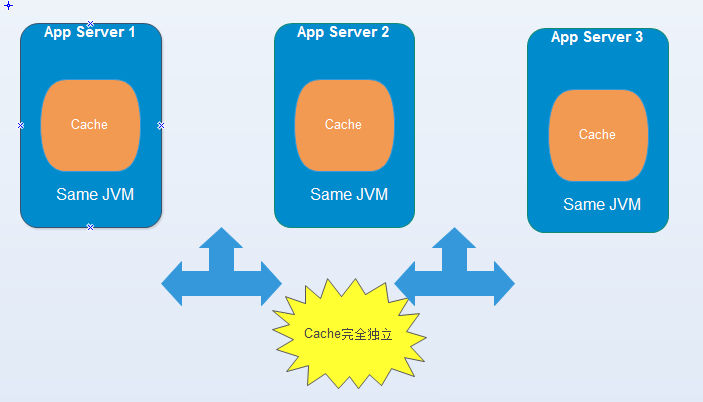
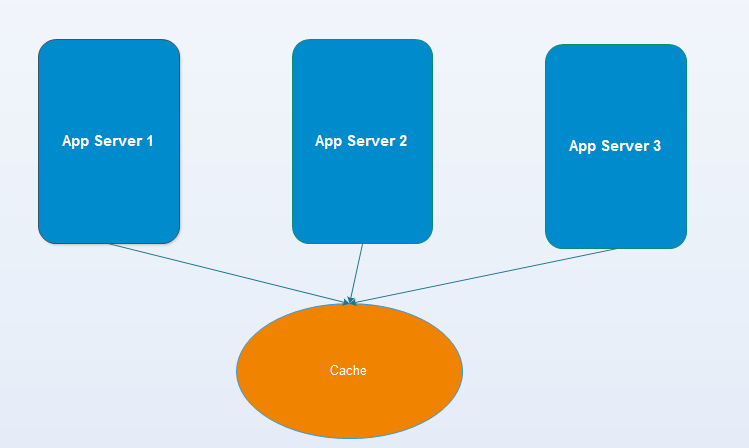
2. Standalone(单机):
(1) 缓存和应用是独立部署的。
(2) 缓存可以是单台。(例如memcache/redis单机等等)
(3) 强一致性
(4) 无高可用、无分布式。
(5) 跨进程、跨网络![]()
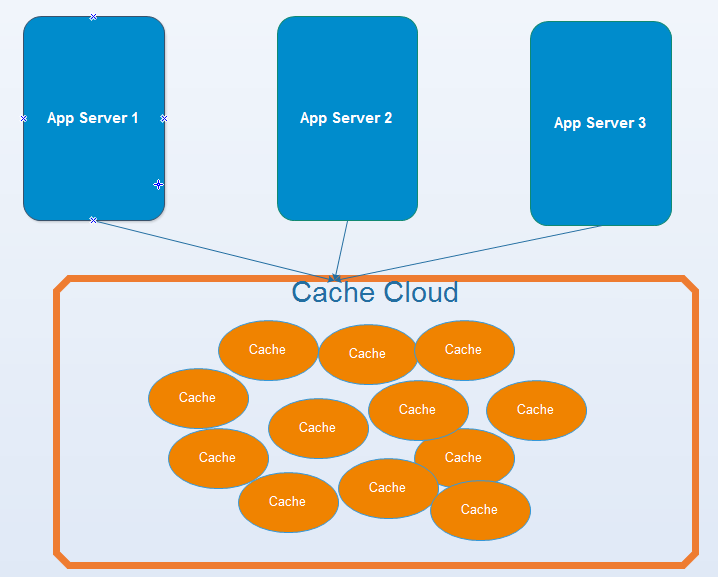
3. Distributed(分布式):例如Redis-Cluster, memcache集群等等
(1) 缓存和应用是独立部署的。
(2) 多个实例。(例如memcache/redis等等)
(3) 强一致性或者最终一致性
(4) 支持Scale Out、高可用。(5) 跨进程、跨网络 ![]()
2,缓存的更新维护策略
超时剔除就是缓存设置超时时间,超过时间了直接删掉,重新load,数据一致性肯定会有问题。但是基本代码不用管就行了。
主动更新的话, 就是你在对db进行更新的时候,也要有一个机制来更新缓存里的,数据一致性比较强,但是代码维护比较高。
当缓存达到最大量的时候,根据一些算法来淘汰掉一些缓存释放空间。常用的以下几种
1)FIFO:First In First Out,先进先出
2)LRU:Least Recently Used,缓存对象按照最后一次被访问的时间排序,淘汰掉最后的一些数据。
3)LFU:Least Frequently Used,缓存对象按照一定时间内被访问的次数进行排序,淘汰掉最后的一些数据。
3,缓存的几个问题考虑
缓存穿透问题
缓存穿透是指查询一个一定不存在的数据,由于缓存不命中,并且出于容错考虑, 如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。解决的话可以将这个key也存贮一个空,下次再查询的话就直接返回空即可,等db确实有数据了再通过其他机制来更新缓存。防止增加db压力。
缓存雪崩问题
正常情况下,大量的请求,被缓存阻挡一部分,db再处理一部分,稳定运行,如果突然缓存机制down掉了,那么依一下子所有的请求都到db了,这时候可能db就会down掉。处理这样的情况就是要尽量保证cache不会down掉,可以不适用单机的缓存,而是用集群或者其他方法保证cache的高可用性。
热点key数据失效问题
如果一些非常热的key到了时间了,失效后,大量的请求同事到db,并且同时开始加载缓存,也容易造成一系列问题。可以使用机制将热点key的过期时间适当修改,或者利用锁只让一个线程访问db构建缓存之类的方法。

