第一次作业:深度学习基础
深度学习及pytorch基础小结
视频学习:链接
代码练习:
1、 pytorch基础
-
定义数据(使用torch.Tensor)
import torch x = torch.tensor(666) '''tensor(666)''' x = torch.tensor([1,2,3,4,5,6]) '''tensor([1,2,3,4,5,6])''' x = torch.ones(2,3) ''' tensor([[1., 1., 1.], [1., 1., 1.]]) ''' # 创建随机张量 x = torch.rand(5,3) ''' tensor([[0.7714, 0.6315, 0.1666], [0.4419, 0.3125, 0.9500], [0.3175, 0.9921, 0.0321], [0.8264, 0.1601, 0.0556], [0.6052, 0.3954, 0.5948]]) ''' #创建全0张量,设置类型为long x = torch.zeros(5,3,dtype=torch.long) #基于现在的tensor,创建一个新的tensor,从而利用原来的tensor的dtype,deveice,size等 x = x.new_ones(5,3) #利用原来的tensor大小,但重新定义type z = torch.randn_like(x, dtype=torch.float) -
定义操作
- 基本运算,加减乘除,求幂求余
- 布尔运算,大于小于,最大最小
- 线性运算,矩阵乘法,求模,求行列式
# 返回元素的数量 m.numel() # 创建一个1到4的tensor(注意写作1,5,因为右边是开区间) v = torch.arange(1, 5, dtype = torch.int32) # 点积 m @ v # 转置 m.t() # 使用 transpose 也可以达到相同的效果 # b = a:transpose(m,n)表示将矩阵或者张量a的第m维和第n维交换。 m.transpose(0,1) # 返回一个一维张量,从a到b,步长为s torch.linspace(a, b, s)
2、图像处理基础
-
下载并显示图像
#使用!wget 来下载图像 !wget https://raw.githubusercontent.com/summitgao/ ImageGallery/master/yeast_colony_array.jpg # 导入头文件 import matplotlib import numpy as np import matplotlib.pyplot as plt import skimage from skimage import data from skimage import io # 读取图片 colony = io.imread('yeast_colony_array.jpg') # 绘制子图 #subplot(numbRow , numbCol ,plotNum ) or subplot(numbRow numbCol plotNum) plt.subplot(121) #绘制子图(121的意思是显示为第一行两列中的第一个图) #imshow()接收一张图像,只是画出该图,并不会立刻显示出来。 plt.imshow(colony[:,:,:]) -
读取并改变图像像素值
# 灰度“相机”图像。 camera = data.camera() # 图像某点的像素值 print(camera[10,20]) # 把一个区域变成黑色 camera[30:100, 10:100] = 0 # 把一行变成黑色 camera[:10] = 0 # 寻找像素值小于80的点的集合 mask = camera < 80 # 把集合的点的像素变成白色 camera[mask] = 255 # 把RGB颜色变成BGR颜色 BGR_cat = cat[:, :, ::-1] # 显示灰度图 plt.imshow(camera, 'gray') -
转换图像数据类型
- img_as_float Convert to 64-bit floating point.
- img_as_ubyte Convert to 8-bit uint.
- img_as_uint Convert to 16-bit uint.
- img_as_int Convert to 16-bit int.
-
显示图像直方图
直方图的 x 轴是灰度值(0 到 255),y 轴是图片中具有同一个灰度值的点的数目。通过直方图我们可以对图像的对比度,亮度,灰度分布等有一个直观的认识。
img = data.camera() ''' ravel()将多维数组降至一维数组 bins 条形数 histtype 线条的类型 "bar":方形,"barstacked":柱形,"step":"未填充线条" "stepfilled":"填充线条" color 颜色 ''' plt.hist(img.ravel(), bins=256, histtype='step', color='black')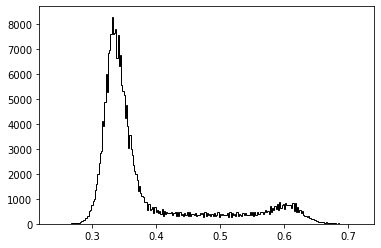
-
图像分割
-
Canny算子边缘检测
from skimage.feature import canny from scipy import ndimage as ndi ''' canny边缘检测的基本思想是:首先对图像选择一定的Gauss滤波器进行平滑滤波,然后采用非极值抑制技术进行处理得到最后的边缘图像。 ''' img_edges = canny(img) # 填充二进制图像矩阵中的孔洞 img_filled = ndi.binary_fill_holes(img_edges)
-
改变对比度
# 对比拉伸 # 计算一个多维数组的任意百分比分位数 p2, p98 = np.percentile(img, (2, 98)) # 在拉伸或收缩强度水平后返回图像 img_rescale = exposure.rescale_intensity(img, in_range=(p2, p98)) # 直方图均衡化 # 在直方图均衡之后返回图像 img_eq = exposure.equalize_hist(img) # 对比度有限自适应直方图均衡化 ''' 对比度有限自适应直方图均衡化(CLAHE)。一种局部对比度增强的算法,该算法使用在图像的不同平铺区域上计算的直方图。 因此,即使在比大多数图像更暗或更轻的区域中,局部细节也可以得到增强。 clip_limit:float,可选的剪切限制,归一化在0和1之间(更高的值给出更多的对比度)。 ''' img_adapteq = exposure.equalize_adapthist(img, clip_limit=0.03)
3.螺旋数据分类
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
# 因为colab支持GPU,所以torch将在GPU上运行
# 在修改-笔记本设置-硬件加速器中选择GPU!!!
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 初始化随机数种子。神经网络的参数都是随机初始化的
# 不同的初始化参数往往导致不同的结果,当得到比较好的结果时我们希望这个结果可以复现
# 因此在pytorch中,通过设置随机数种子也可以达到这个目的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量
初始化 X 和 Y。 X 可以理解为特征矩阵,Y可以理解为样本标签。
结合代码可以看到,X的为一个 NxC 行, D 列的矩阵。
C 类样本,每类样本是 N个,所以是 N*C 行。每个样本的特征维度是2,所以是2列。
在 python 中,调用 zeros 类似的函数,第一个参数是 y方向的,即矩阵的行;第二个参数是 x方向的,即矩阵的列.
# 样本特征初始化
X = torch.zeros(N * C, D).to(device)
Y = torch.zeros(N * C, dtype=torch.long).to(device)
for c in range(C):
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]之间均匀的取10000个数,赋给t
# 下面的代码是根据公式计算出三类样本(可以构成螺旋形)
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在X里
# Y里存储的是样本的类别,分别为[0,1,2]
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]),math.cos(inner_var[index])))
Y[ix] = c
index += 1
print("Shapes:")
print("X:",X.size())
print("Y:",Y.size())
'''
Shapes:
X: torch.Size([3000, 2])
Y: torch.Size([3000])
'''
# 显示图像
plot_data(X, Y)
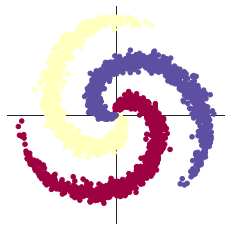
-
构建线性模型分类
什么是交叉熵?
交叉熵主要是用来判定实际的输出与期望的输出的接近程度.它主要刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。
举个例子:在做分类的训练的时候,如果一个样本属于第K类,那么这个类别所对应的的输出节点的输出值应该为1,而其他节点的输出都为0,即[0,0,1,0,….0,0],这个数组也就是样本的Label,是神经网络最期望的输出结果。也就是说用它来衡量网络的输出与标签的差异,利用这种差异经过反向传播去更新网络参数。
# 设置学习率和初始权重 learning_rate = 1e-3 lambda_12 = 1e-5 ''' nn包用来创建线性模型 每一个线性模型都包含weight和bias nn.Sequential:一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。 ''' model = nn.Sequential( # 输入2个输出100个(输入层->隐藏层) nn.Linear(D, H), # 输入100个输出3个(隐藏层->输出层) nn.Linear(H, C) ) model.to(device) # 把模型放到GPU上 # nn包括许多不同的损失函数,这里使用交叉熵损失函数 criterion = torch.nn.CrossEntropyLoss() # 这里使用optim包的SGD方法进行随机梯度下降优化 optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate, weight_decay=lambda_12) #开始训练 for t in range(1000): # 把数据输入模型,得到预测结果 y_pred = model(X) # 计算损失和准确率 loss = criterion(y_pred, Y) """ output = torch.max(input, dim) input是softmax函数输出的一个tensor dim是max函数索引的维度0/1,0是每列的最大值,1是每行的最大值 函数会返回两个tensor,第一个tensor是每行的最大值,softmax的输出中最大的是1, 所以第一个tensor是全1的tensor;第二个tensor是每行最大值的索引。 """ score, predicted = torch.max(y_pred, 1) print(score, predicted) acc = (Y == predicted).sum().float() / len(Y) print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc)) display.clear_output(wait = True) # 反向传播前把梯度置为0 optimizer.zero_grad() # 反向传播优化 loss.backward() # 更新全部参数 optimizer.step() # 显示模型 print(model) plot_model(X, Y, model) 使用 print(y_pred.shape) 可以看到模型的预测结果,为[3000, 3]的矩阵。每个样本的预测结果为3个,保存在 y_pred 的一行里。值最大的一个,即为预测该样本属于的类别 score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中。下面代码把第10行的情况输出,供解释说明 每一次反向传播前,都要把梯度清零。
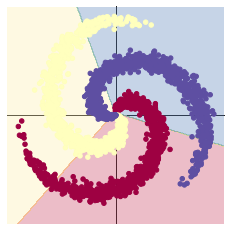
上面使用 print(model) 把模型输出,可以看到有两层:
- 第一层输入为 2(因为特征维度为主2),输出为 100;
- 第二层输入为 100 (上一层的输出),输出为 3(类别数)
从上面图示可以看出,线性模型的准确率最高只能达到 50% 左右,对于这样复杂的一个数据分布,线性模型难以实现准确分类。
-
两层神经网络分类
# 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数 model = nn.Sequential( nn.Linear(D, H), nn.ReLU(), nn.Linear(H, C) ) 其他代码与上面一致。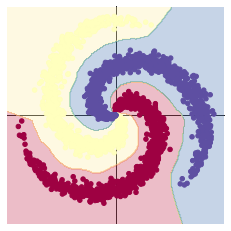
ReLu是神经网络中的一个激活函数,其优于tanh和sigmoid函数。
1.为何引入非线性的激活函数?
如果不用激活函数,在这种情况下每一层输出都是上层输入的线性函数。容易验证,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。因此引入非线性函数作为激活函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
2.引入ReLu的原因
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现 梯度消失 的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
第三,ReLu会使一部分神经元的输出为0,这样就造成了 网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
为什么通常Relu比sigmoid和tanh强,有什么不同?
主要是因为它们gradient特性不同。sigmoid和tanh的gradient在饱和区域非常平缓,接近于0,很容易造成vanishing gradient的问题,减缓收敛速度。vanishing gradient在网络层数多的时候尤其明显,是加深网络结构的主要障碍之一。相反,Relu的gradient大多数情况下是常数,有助于解决深层网络的收敛问题。Relu的另一个优势是在生物上的合理性,它是单边的,相比sigmoid和tanh,更符合生物神经元的特征。
而提出sigmoid和tanh,主要是因为它们全程可导。还有表达区间问题,sigmoid和tanh区间是0到1,或着-1到1,在表达上,尤其是输出层的表达上有优势。
ReLU更容易学习优化。因为其分段线性性质,导致其前传,后传,求导都是分段线性。而传统的sigmoid函数,由于两端饱和,在传播过程中容易丢弃信息。
4. 回归分析
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
from matplotlib import pyplot as plt
# 初始化
set_default()
# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
seed = 1
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 1 # 每个样本的特征维度
C = 1 # 类别数
H = 100 #隐层神经元的数量
# torch.squeeze() 返回一个新的张量,其维数为插入到指定位置的维数。
# 下面的代码意思是返回100个一维的向量
X = torch.unsqueeze(torch.linspace(-1, 1, 100), dim = 1).to(device)
y = X.pow(3) + 0.3 * torch.rand(X.size()).to(device)
# 绘图
# 在坐标系上显示数据
plt.figure(figsize=(6,6))
# 绘制散点图
plt.scatter(X.cpu().numpy(), y.cpu().numpy())
# 让x轴和y轴单位长度相等,即分辨率相等
plt.axis('equal')

-
建立线性模型(两层之间无激活函数)
# 设置学习率和初始权值 learning_rate = 1e-3 lambda_12 = 1e-5 # 建立神经网络模型 model = nn.Sequential( nn.Linear(D, H), nn.Linear(H, C) ) model.to(device) #模型转到GPU # 对于回归问题,使用MSE损失函数 criterion = torch.nn.MSELoss() # 定义优化器,使用SGD optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_12) # 开始训练 for t in range(1000): # 数据输入模型得到预测结果 y_pred = model(X) # 计算MSE损失 loss = criterion(y_pred, y) print("[EPOCH]: %i, [LOSS or MSE]: %.6f" % (t, loss.item())) display.clear_output(wait = True) # 反向传播前,梯度清零 optimizer.zero_grad() # 反向传播 loss.backward() # 更新参数 optimizer.step()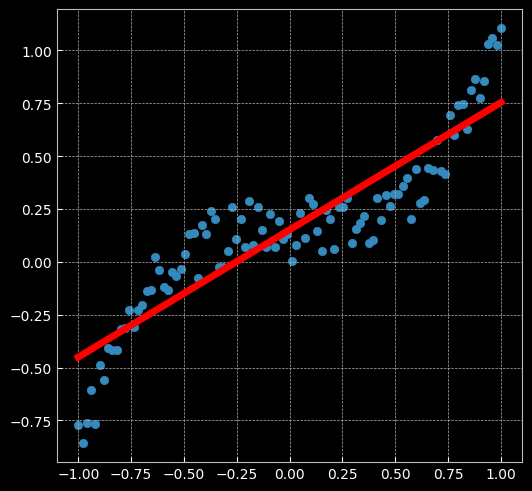
-
两层神经网络
# 这里定义了2个网络,一个 relu_model,一个 tanh_model, # 使用了不同的激活函数 relu_model = nn.Sequential( nn.Linear(D, H), nn.ReLU(), nn.Linear(H, C) ) relu_model.to(device) tanh_model = nn.Sequential( nn.Linear(D, H), nn.Tanh(), nn.Linear(H, C) ) tanh_model.to(device) # MSE损失函数 criterion = torch.nn.MSELoss() # 定义优化器,使用Adam,这里仍使用SGD优化器的效果会比较差 # SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。SGD 因为更新比较频繁,会造成 cost function 有严重的震荡。整体来讲,Adam 是最好的选择。 optimizer_relumodel = torch.optim.Adam(relu_model.parameters(), lr = learning_rate, weight_decay = lambda_12) optimizer_tanhmodel = torch.optim.Adam(tanh_model.parameters(), lr = learning_rate, weight_decay = lambda_12) # 开始训练 for t in range(1000): y_pred_relumodel = relu_model(X) y_pred_tanhmodel = tanh_model(X) # 计算损失与准确率 loss_relumodel = criterion(y_pred_relumodel, y) loss_tanhmodel = criterion(y_pred_tanhmodel, y) print(f"[MODEL]: relu_model, [EPOCH]: {t}, [LOSS]: {loss_relumodel.item():.6f}") print(f"[MODEL]: tanh_model, [EPOCH]: {t}, [LOSS]: {loss_tanhmodel.item():.6f}") display.clear_output(wait = True) optimizer_relumodel.zero_grad() optimizer_tanhmodel.zero_grad() loss_relumodel.backward() loss_tanhmodel.backward() optimizer_relumodel.step() optimizer_tanhmodel.step()plt.figure(figsize=(12,6)) def dense_prediction(model, non_linearity): # 根据是否为ReLU来设置是第一幅图还是第二幅图 plt.subplot(1, 2, 1 if non_linearity == 'ReLU' else 2) # 对X轴(-1,1)上的点的数据的维度进行压缩 X_new = torch.unsqueeze(torch.linspace(-1, 1, 1001), dim = 1).to(device) with torch.no_grad(): y_pred = model(X_new) # 绘制折线图 plt.plot(X_new.cpu().numpy(), y_pred.cpu().numpy(), 'r-', lw=1) # 绘制散点图 plt.scatter(X.cpu().numpy(), y.cpu().numpy(), label = 'data') plt.axis('square') plt.title(non_linearity + 'models') dense_prediction(relu_model, 'ReLU') dense_prediction(tanh_model, 'Tanh')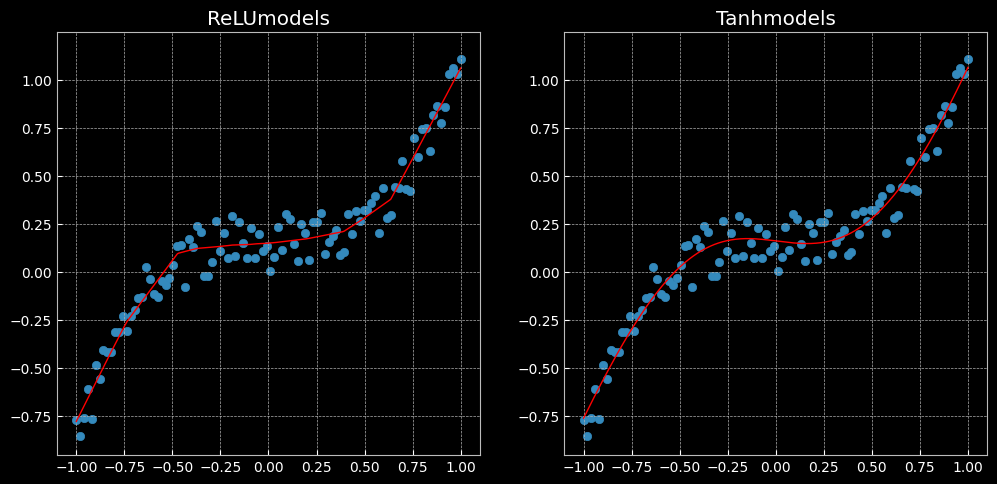
5. 猫狗大战
作为深度学习的初学者,暂时只能对老师提供的代码部分进行一定的理解。等集大成之后一定回来补充完善。

这部分为 Kaggle 于 2013 年举办的猫狗大战竞赛,使用在 ImageNet 上预训练的 VGG 网络进行测试。因为原网络的分类结果是1000类,所以这里进行迁移学习,对原网络进行 fine-tune (即固定前面若干层,作为特征提取器,只重新训练最后两层)。
网站为:https://god.yanxishe.com/41
直接上代码并进行分析
# 准备工作
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models, transforms, datasets
import time
import json
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Using gpu: %s" % torch.cuda.is_available)
# 下载数据并解包
! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip
! unzip dogscats.zip
-
数据处理
datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成 224×224×3 的大小,同时还将进行归一化处理。
torchvision 支持对输入数据进行一些复杂的预处理/变换 (normalization, cropping, flipping, jittering 等)。
''' 为什么Pytorch用mean=[0.485, 0.456, 0.406] and std=[0.229, 0.224, 0.225]来正则化? 这是因为使用了使用ImageNet的均值和标准差。 使用Imagenet的均值和标准差是一种常见的做法。它们是根据数百万张图像计算得出的。如果要在自己的数据集上从头开始训练,则可以计算新的均值和标准差。否则,建议使用Imagenet预设模型及其平均值和标准差。 ''' normalize = transforms.Normalize(mean = [0.485, 0.465, 0.406], std = [0.229, 0.224, 0.225]) vgg_format = transforms.Compose([ transforms.CenterCrop(224),# 将图片从中心裁剪成224*224 transforms.ToTensor(), # 将图片转换为Tensor normalize, # 归一化至[0,1] ]) # 文件路径 data_dir = './dogscats' # 用字典的方式将训练模型和测试模型分别存储 dsets = {x:datasets.ImageFolder(os.path.join(data_dir, x),vgg_format) for x in ['train', 'valid']} # 同样用字典的方式存储数据集的长度 dset_sizes = {x : len(dsets[x]) for x in ['train', 'valid']} # 训练集的类别 dset_classes = dsets['train'].classes # 查看dsets的一些属性 print(dsets['train'].classes) # 根据分的文件夹的名字来确定的类别 ''' ['cats', 'dogs'] ''' print(dsets['train'].class_to_idx) # 按顺序为这些类别定义索引为0,1... ''' {'cats': 0, 'dogs': 1} ''' print(dsets['train'].imgs[:5]) # 返回从所有文件夹中得到的图片的路径以及其类别 ''' [('./dogscats/train/cats/cat.0.jpg', 0), ('./dogscats/train/cats/cat.1.jpg', 0), ('./dogscats/train/cats/cat.10.jpg', 0), ('./dogscats/train/cats/cat.100.jpg', 0), ('./dogscats/train/cats/cat.101.jpg', 0)] ''' print('dset_sizes:', dset_sizes) # 返回数量 ''' dset_sizes: {'train': 1800, 'valid': 2000} '''# 读取数据 # batch_size:每次输入数据的行数,默认为1。这里就是定义每次喂给神经网络多少行数据,如果设置成1,那就是一行一行进行. # shuffle:在每次迭代训练时是否将数据洗牌,默认设置是False。将输入数据的顺序打乱,是为了使数据更有独立性,但如果数据是有序列特征的,就不要设置成True了 # num_workers:工作者数量,默认是0。使用多少个子进程来导入数据。设置为0,就是使用主进程来导入数据。 loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6) loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=5, shuffle=False, num_workers=6) ''' valid 数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出到 400 同时,把第一个 batch 保存到 inputs_try, labels_try,分别查看 ''' count = 1 for data in loader_valid: print(count, end='\n') if count == 1: inputs_try, labels_try = data count += 1 print(labels_try) print(inputs_try.shape) ''' tensor([0, 0, 0, 0, 0]) torch.Size([5, 3, 224, 224]) '''# 显示图片的小程序 def imshow(inp, title = None): # Imshow for Tensor inp = inp.numpy().transpose((1,2,0)) # 矩阵变换 自己试一下 mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) # clip这个函数将将数组中的元素限制在a_min, a_max之间,大于a_max的就使得它等于 a_max,小于a_min,的就使得它等于a_min。 inp = np.clip(std * inp + mean, 0, 1) plt.imshow(inp) if title is not None: plt.title(title) plt.pause(0.001) # pause a bit so that plots are updated # 显示 labels_try 的5张图片,即valid里第一个batch的5张图片 # make_grid的作用是将若干幅图像拼成一幅图像。 out = torchvision.utils.make_grid(inputs_try) imshow(out, title=[dset_classes[x] for x in labels_try])
-
创建VGG Model
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。
直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。
在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。可以看到,识别结果是比较非常准确的。
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.jsonmodel_vgg = models.vgg16(pretrained = True) with open('./imagenet_class_index.json') as f: class_dict = json.load(f) dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))] # 当我们指定了设备之后,就需要将模型加载到相应设备中,此时需要使用model=model.to(device),将模型加载到相应的设备中。 inputs_try, label_try = inputs_try.to(device), labels_try.to(device) model_vgg = model_vgg.to(device) outputs_try = model_vgg(inputs_try) print(outputs_try) print(outputs_try.shape) ''' 可以看到结果为5行,1000列的数据,每一列代表对每一种目标识别的结果。 但是我也可以观察到,结果非常奇葩,有负数,有正数, 为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数 !!!softmax函数将输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。!!! ''' m_softm = nn.Softmax(dim = 1) probs = m_softm(outputs_try) vals_try, pred_try = torch.max(probs, dim = 1) # 求每行的最大索引 print( 'prob sum: ', torch.sum(probs,1)) print( 'vals_try: ', vals_try) print( 'pred_try: ', pred_try) print([dic_imagenet[i] for i in pred_try.data]) imshow(torchvision.utils.make_grid(inputs_try.data.cpu()), title = [dset_classes[x] for x in labels_try.data.cpu()])
参考自:https://www.jianshu.com/p/3ed11362b54f
https://blog.csdn.net/qq_39463274/article/details/105145029
在分类问题中,通常需要使用
max()函数对softmax函数的输出值进行操作,求出预测值索引。torch.max(input, dim) 函数 output = torch.max(input, dim)
输入:
- input 是softmax函数的输出的一个tensor
- dim是max函数索引的维度0/1,0是每列的最大值,1是每行的最大值
输出
- 函数返回两个tensor,第一个tensor是每行的最大值,softmax的输出中最大的值为1,所有第一个tensor是全1的tensor,第二个tensor是每行最大值的索引。
通过简单的实例来理解函数用法
import torch a = torch.tensor([[1,5,62,54], [2,6,2,6], [2,65,2,6]]) print(a) ''' tensor([[ 1, 5, 62, 54], [ 2, 6, 2, 6], [ 2, 65, 2, 6]]) ''' torch.max(a, 1) ''' torch.return_types.max( values=tensor([62, 6, 65]), indices=tensor([2, 3, 1])) '''
torch.sum()对输入的tensor数据的某一维度求和,一共两种用法
1.torch.sum(input, dtype=None)
2.torch.sum(input, list: dim, bool: keepdim=False, dtype=None) → Tensor
input:输入一个tensor
dim:要求和的维度,可以是一个列表
keepdim:求和之后这个dim的元素个数为1,所以要被去掉,如果要保留这个维度,则应当keepdim=True通过简单的实例来理解函数用法
a = torch.ones((2, 3)) print(a): tensor([[1, 1, 1], [1, 1, 1]]) a1 = torch.sum(a) '''tensor(6.)''' a2 = torch.sum(a, dim=0) '''tensor([2., 2., 2.])''' a3 = torch.sum(a, dim=1) '''tensor([3., 3.])'''
-
修改最后一层,冻结前面层的参数
VGG 模型如下图所示,注意该网络由三种元素组成:
-
卷积层(CONV)是发现图像中局部的 pattern
-
全连接层(FC)是在全局上建立特征的关联
-
池化(Pool)是给图像降维以提高特征的 invariance。
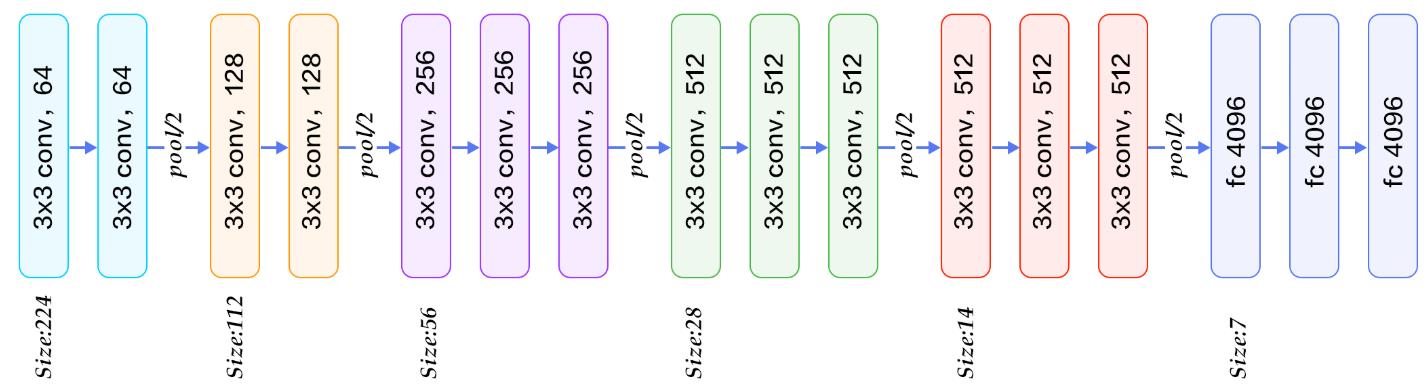
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
print(model_vgg) model_vgg_new = model_vgg; for param in model_vgg_new.parameters(): # 冻结前面层的参数 param.requires_grad = False # 把最后的 nn.Linear 层由1000类,替换为2类 model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2) # 把最后一层改为LogSoftmax model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1) model_vgg_new = model_vgg_new.to(device) print(model_vgg_new.classifier) ''' Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU(inplace=True) (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace=True) (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=2, bias=True) (7): LogSoftmax() ) ''' -
-
训练并测试全连接层
包括三个步骤:第1步,创建损失函数和优化器;第2步,训练模型;第3步,测试模型
''' 第一步:创建损失函数和优化器 损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签. 它不会为我们计算对数概率,适合最后一层是log_softmax()的网络. ''' criterion = nn.NLLLoss() # 学习率 lr = 0.001 # 随机梯度下降 optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(), lr = lr) ''' 第二步:训练模型 ''' def train_model(model, dataloader, size, epochs = 1, optimizer = None): model.train() for epoch in range(epochs): running_loss = 0.0 running_corrects = 0 count = 0 for inputs, classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs, classes) optimizer = optimizer optimizer.zero_grad() loss.backward() optimizer.step() _,preds = torch.max(outputs.data, 1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) count += len(inputs) print('Training: No. ', count, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc)) # 模型训练 train_model(model_vgg_new, loader_train, size = dset_sizes['train'], epochs = 1, optimizer = optimizer_vgg) ''' Loss: 0.0013 Acc: 0.9706 '''# 测试两千个模型的准确率 def test_model(model,dataloader,size): model.eval() predictions = np.zeros(size) all_classes = np.zeros(size) all_proba = np.zeros((size,2)) i = 0 running_loss = 0.0 running_corrects = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) predictions[i:i+len(classes)] = preds.to('cpu').numpy() all_classes[i:i+len(classes)] = classes.to('cpu').numpy() all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy() i += len(classes) print('Testing: No. ', i, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format( epoch_loss, epoch_acc)) return predictions, all_proba, all_classes predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid']) ''' Loss: 0.0092 Acc: 0.9805 '''注:在老师的提示下将SGD替换为了Adam,使最后的准确率上升到了0.98。具体原理等深入学习后进行补充。
