DnCNN学习笔记
参考自:https://www.jianshu.com/p/3687ffed4aa8
论文原文:https://arxiv.org/pdf/1608.03981.pdf
图像降噪
图像降噪,是最简单也是最基础的图像处理逆问题(inverse problem)。
降噪问题(这里只讨论additive noise),用最简单的数学语言一句话就可以描述清楚:
y是你观察到的带噪音的图像,e是噪音,x是干净无噪音的图像。只已知y,外加e的概率分布,降噪问题需要你去寻找最接近真实值的x。
DnCNN
文章重点
- 使用端到端的神经网络模型来进行AWGN的降噪,首次使用残差学习来降噪。
- 调了residual learning(残差学习)和batch normalization(批量标准化)在图像复原中相辅相成的作用,可以在较深的网络的条件下,依然能带来快的收敛和好的性能。
- 文章提出DnCNN,在高斯去噪问题下,用单模型应对不同程度的高斯噪音;甚至可以用单模型应对高斯去噪、超分辨率、JPEG去锁三个领域的问题。
DnCNN网络模型
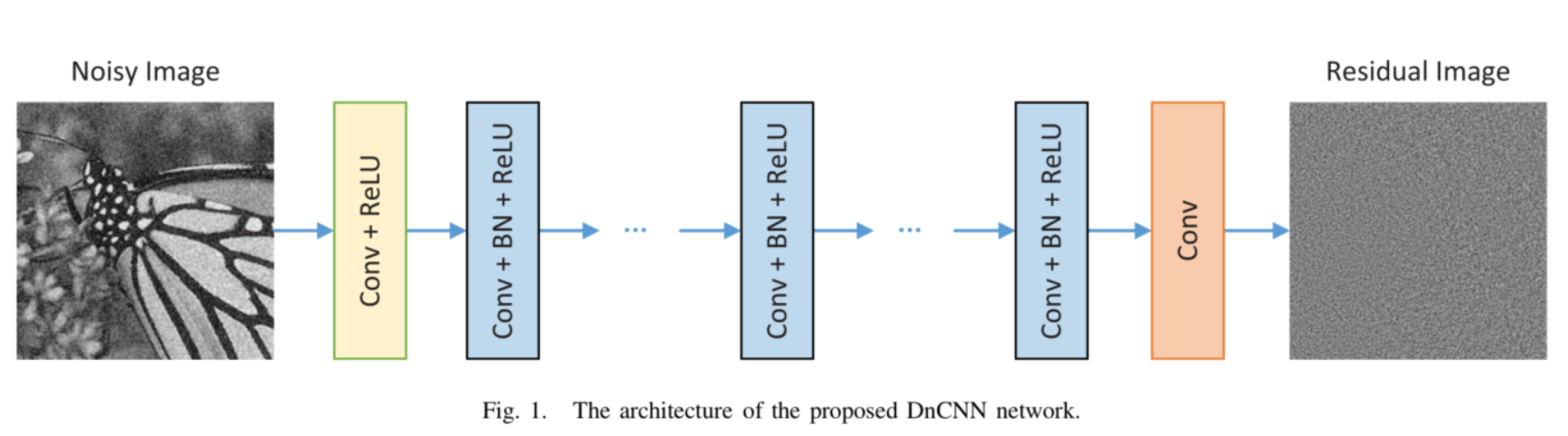
网络结构:
第一部分:Conv(3 * 3 * c * 64) + ReLU(c代表图片通道数)
第二部分:Conv(3 * 3 * 64 * 64) + BN(batch normalization) + ReLU
第三部分:Conv(3 * 3 * 64)
每一层都使用零填充,使得每一层的输入输出尺寸保持一致。以此防止产生人工边界。
第二部分每一层在卷积与ReLU之间都加了批量标准化(batch normalization、BN)。
残差学习
DnCNN结合了ResNet的残差学习,但不同的是,DnCNN并非是每隔两层就加一个shortcut,而是将网络的输出直接改成residual image(残差图片)。
假设纯净图片为x,带噪音图片为y,假设y=x+v,则v是残差图片。
即DnCNN的优化目标不是真实图片与网络输出之间的MSE(均方误差),而是真实残差图片与网络输出之间的MSE(均方误差)。
作者注意到在图像复原领域(尤其是在噪音程度较小的情况下),噪音图片与纯净图片的残差非常小,所以理论上残差学习非常适合运用到图像复原上。
这样的网络设计就是在隐层中将真实的图片x从原噪音图y中消去。在超分领域,低分辨率图片就是高分辨率图片的双三次上采样操作形成的,故超分领域的残差图片和去高斯噪声领域的残差图片是等价的,同理还有JPEG解锁领域的残差图片。
实验
作者做了三种实验:
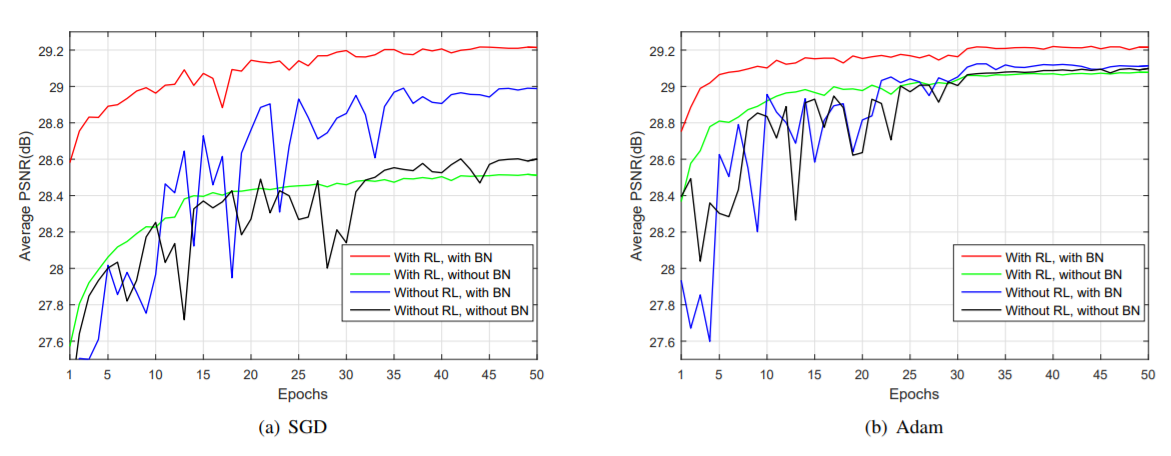
- 对比有无residual learning与batch normalization对复原效果、收敛快慢的影响,最终证明这两是相辅相成的,都利用上时网络各方面性能达到最好。
- 根据特定程度的高斯噪声训练DnCNN-S、根据不定程度的高斯噪声训练DnCNN-B、根据不同程度的噪音(包括不同程度的高斯噪声、不同程度的低分辨率、不同程度的JPEG编码)训练的DnCNN-3来与最前沿的其他算法做对比实验。结论:DnCNN-S有最好的性能,但是DnCNN-B也有优于其他算法的性能,证明了DnCNN-B具有很好的盲去高斯噪声的能力;DnCNN-3则证明了DnCNN-3具有不俗的复原图像的泛化能力。

- 对比了DnCNN与其他前沿去噪算法的运行速度的实验,结论:速度还是不错的,CPU\GPU环境下均属于中上水平。

结论
本文提出了在降噪领域中使用残差学习的方法来进行图像降噪,直接学习图片的噪声,可以更快更好的学习到降噪。并且,这种残差的降噪是比较通用的,可以推广到单图超分、jpeg去块也可以。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号