MobileNets学习笔记
参考自:
https://www.jianshu.com/p/f33e8f425d5b
https://zhuanlan.zhihu.com/p/92134485
https://zhuanlan.zhihu.com/p/70703846
MobileNets
Mobilenets是Google针对手机的智能型嵌入式设备提出的一种轻量级深度卷积神经网络,该网络的核心为深度可分离卷积,该卷积可以分解为深层卷积(depthwise conv)和点对点卷积(Point conv)。
MobileNetsV1论文地址: https://arxiv.org/abs/1704.04861
MobileNetsV2论文地址:https://arxiv.org/abs/1801.04381
MobileNetsV1/V2代码地址(caffe):https://github.com/shicai/MobileNet-Caffe
MobileNetsV1代码地址(TensorFlow):https://github.com/Zehaos/MobileNet
MobileNetsV2代码地址(Keras):https://github.com/xiaochus/MobileNetV2
1.MobileNetV1
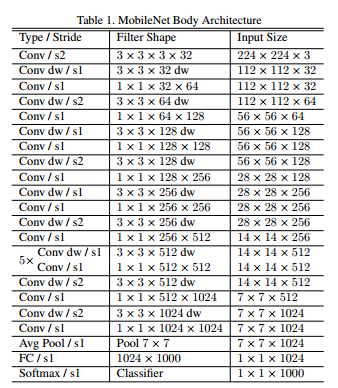
网络结构
其核心就是由深层卷积(depthwise conv)和点对点卷积(Point conv)组成的深度可分离卷积。正是这种结构实现了在不降低网络性能的前提下减少网络参数和计算量。
Depthwised卷积
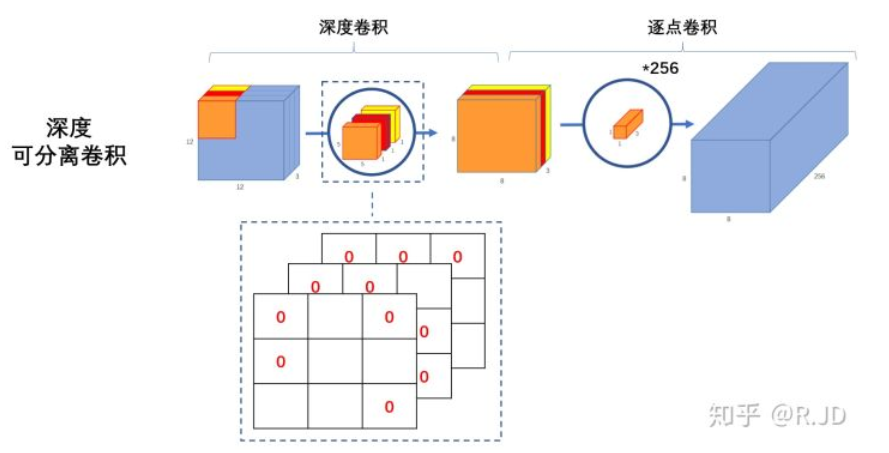
图所示为标准卷积核depthwise卷积的实现对比,我们可以发现两种卷积对于同样的输入图片,最后的输出是一致的。
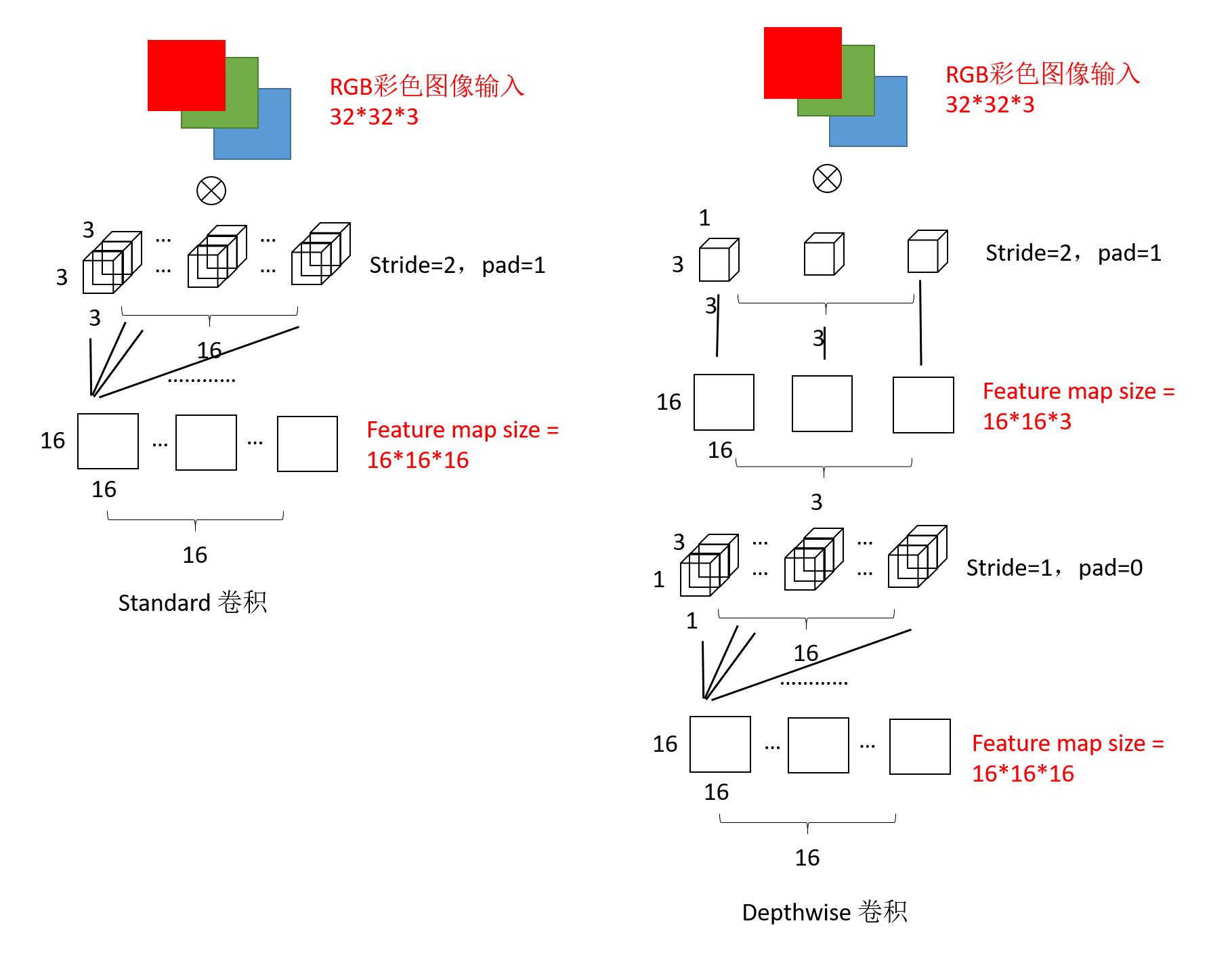
最终卷积的参数量也得到了大大的减少,标准卷积的参数量为\(3\times3\times3\times16\)。而depthwise卷积的参数量为\(3\times3\times1+1\times1\times3\times16\)。
具体解释为:
常规卷积操作:
对于一张5×5像素、三通道(shape为5×5×3),经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4,最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3
卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
\(N_{std} = 4 × 3 × 3 × 3 = 108\)
深度可分离卷积:
-
逐通道卷积
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。
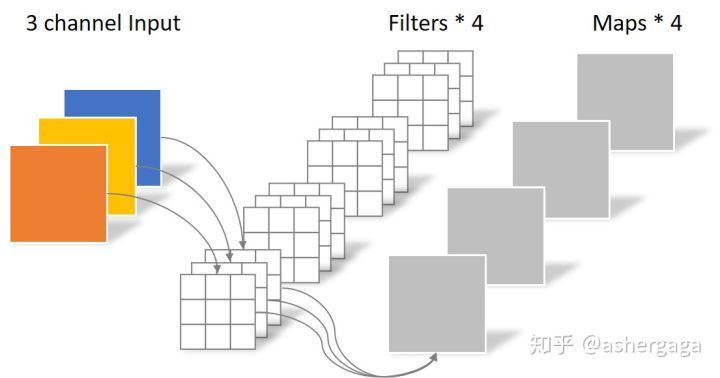
首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5)
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
\(N_{std} = 3 × 3 × 3 = 27\)
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map
-
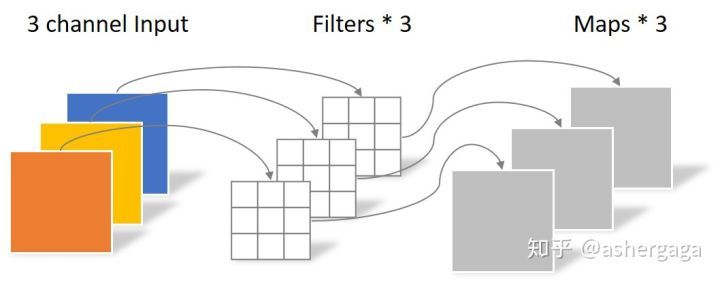
逐点卷积
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map
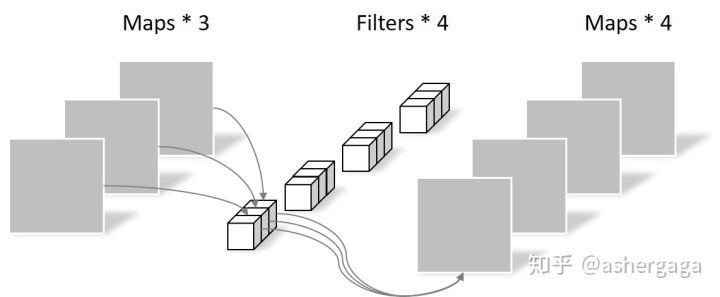
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
\(N_{std} = 1 × 1 × 3 × 4 = 12\)
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同
所以常规卷积的参数个数为:
\(N_{std} = 4 × 3 × 3 × 3 = 108\)
Separable Convolution的参数由两部分相加得到:
\(N_{depthwise} = 3 × 3 × 3 = 27\)
\(N_{pointwise} = 1 × 1 × 3 × 4 = 12\)
\(N_{separable} = N_{depthwise} + N_{pointwise}= 39\)
在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
论文亮点
-
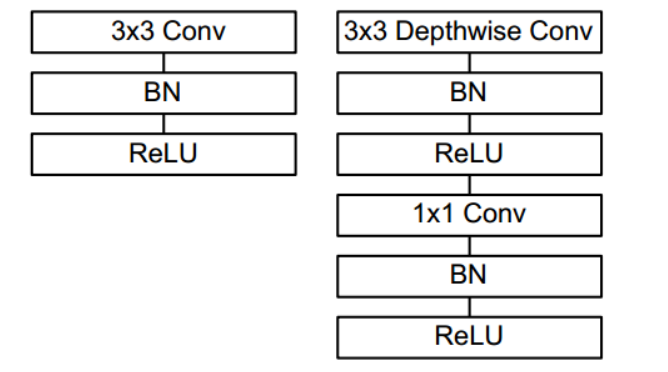
depthwise和pointwise层后接BN层和RELU6。左图是传统卷积,右图是深度可分离卷积。更多的ReLU6,增加了模型的非线性变化,增强了模型的泛化能力。
-
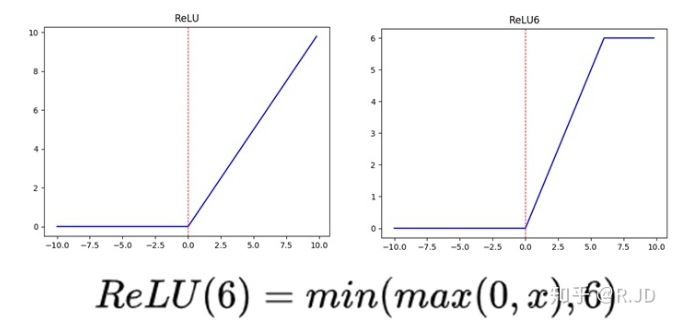
v1中使用了RELU6作为激活函数,这个激活函数在float16/int8的嵌入式设备中效果很好,能较好地保持网络的鲁棒性。
-
v1还给出了2个超参,宽度乘子α和分辨率乘子β,通过这两个超参,可以进一步缩减模型。
实验结论
标准卷积与Depthwise卷积结果对比,从下图中我们可以发现Depthwise策略在不明显损失精度的情况下,其参数为标准卷积策略的1/7。

作者在论文中提出的两个超参数:宽度乘数和分辨率乘数 。
宽度乘数用于改变输入输出通道数,减少特征图数量,让网络变瘦。分辨率乘数用于改变输入图片分辨率,同样也能减少参数。
深瘦型网络与浅胖型网络结果对比,在相同量级的参数下深瘦型网络要比浅胖型网络效果好。
网络越瘦或网络输入分辨率越小,与之对应的结果也越差。
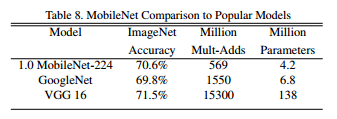
最终Mobilenet网络与Goognet以及VGG16的结果对比,我们可以发现Mobilenet有很好的性能。
2.MobileNet V2
MobileNet V2保留了MobileNet V1中提出的Depthwise卷积,并结合ResNet网络做出了两点改进:Inverted Residual Block;Linear Bottleneck。
Linear Bottleneck
V1核心思想是采用 深度可分离卷积 操作。在相同的权值参数数量的情况下,相较标准卷积操作,可以减少数倍的计算量,从而达到提升网络运算速度的目的。
但是有人在实际使用的时候, 发现深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是空的:
原因是ReLU,我们常用的激活函数ReLU是非线性的,作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,非线性的不如线性的效果好。因此作者ReLU对不同维度输入的信息丢失做了对比。

最终发现,当把原始输入维度增加到15或30后再作为ReLU的输入,输出恢复到原始维度后基本不会丢失太多的输入信息;相比之下如果原始输入维度只增加到2或3后再作为ReLU的输入,输出恢复到原始维度后信息丢失较多。
因此在MobileNet V2中,执行降维的卷积层后面不会接类似ReLU这样的非线性激活层。作者将这个部分称之为linear bottleneck。
Inverted Residual Block
深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道。如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要“扩张”通道。
既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征:

不管输入通道数是多少,经过第一个PW逐点卷积升维之后,深度卷积都是在相对的更高6倍维度上进行工作。
回顾V1的网络结构,我们发现V1很像是一个直筒型的VGG网络。我们想像Resnet一样复用我们的特征,所以我们引入了shortcut结构,这样V2的block就是如下图形式:
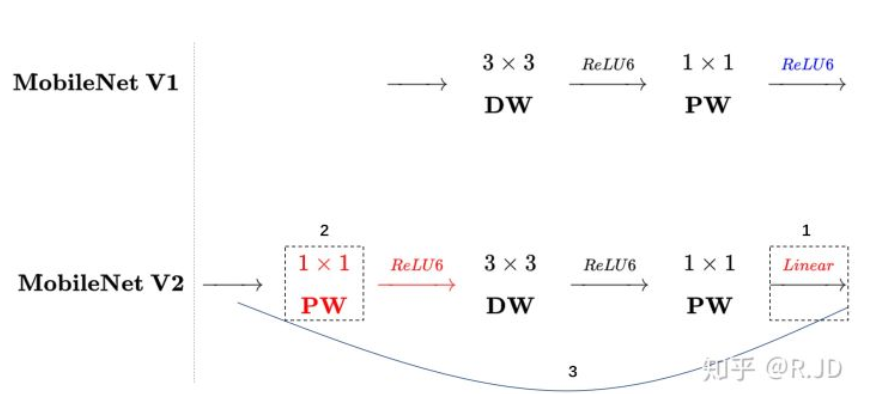
对比V1和V2:
都采用了 1×1 -> 3 ×3 -> 1 × 1 的模式,以及都使用Shortcut结构。
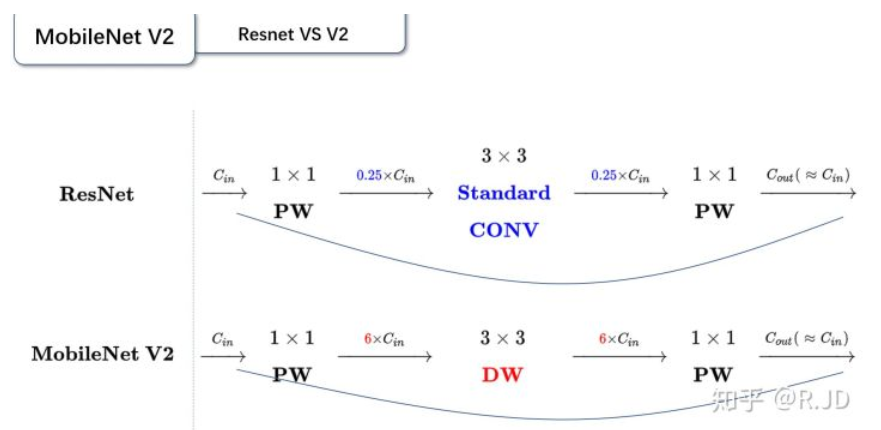
但不同的地方是:
- ResNet 先降维 (0.25倍)、卷积、再升维。
- MobileNetV2 则是 先升维 (6倍)、卷积、再降维。
刚好V2的block刚好与Resnet的block相反,作者将其命名为Inverted residuals。
对比V1和V2的block:
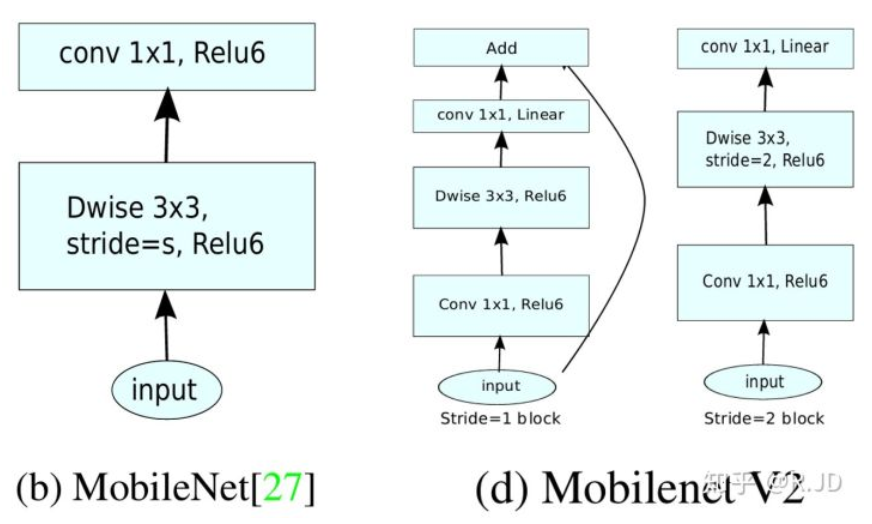
左边是v1的block,没有Shortcut并且带最后的ReLU6。
右边是v2的加入了1×1升维,引入Shortcut并且去掉了最后的ReLU,改为Linear。步长为1时,先进行1×1卷积升维,再进行深度卷积提取特征,再通过Linear的逐点卷积降维。将input与output相加,形成残差结构。步长为2时,因为input与output的尺寸不符,因此不添加shortcut结构,其余均一致。
综上,MobileNetV2 提供了一个非常高效的面向移动设备的模型,可以用作许多视觉识别任务的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号